实验目标
(1)掌握函数调用时的栈帧结构
(2)利用输入缓冲区的溢出漏洞,将攻击代码嵌入当前程序的栈帧中,使得程序执行我们所期望的过程
实验代码
(1)makecookie:生成cookie 例:./makecookie SA22225284 生成cookie
(2)Bufbomb:可执行程序-攻击对象
(3)Sendstring: 字符格式转换
bufbomb程序
Bufbomb中包含一个getbuf函数,该函数实现如下
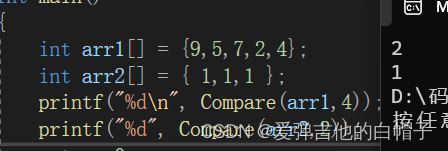
int getbuf()
{
char buf[12];
gets(buf);
return 1;
}
对buf没有越界检查(常见c编程错误),超过11个字符将溢出
溢出
溢出的字符将覆盖栈帧上的数据
- 特别的,会覆盖程序调用的返回地址
- 赋予我们控制程序流程的能力
通过构造溢出字符串,程序将“返回”至我们想要的代码上

字符构造
计算机系统中,字符以ASCII码表示/存储,例如,输入’1’,存储为’0x31’ ,本实验也需要扩展的ASCII码(128~255)
为了构造所需要的地址或其他数据,我们需要逆反“字符->ASCII码”的过程
采用代码包给出的 sendstring工具。 使用方法:
./sendstring < exploit.txt > exploit-raw.txt其中exploit.txt保存目标数据(即空格分隔的ASCII码),exploit-raw.txt为逆向出的字符串
字符串输入
前述方法构造出的字符串按如下方式输入:
./bufbomb -t SA22225284 < exploit-raw.txt从标准输入设备输入,方式如下:
ALT+ASC码的十进制数(小键盘输入) 注意,最后一个数字按下后与ALT键同时放开。例,输入字符“1”为ALT+49
实验完成后提交exploit.txt文件
运行时栈
C语言过程调用机制的一个关键特性(大多数其他语言也是如此)在于使用了栈数据结构提供的后进先出的内存管理原则。在过程Р调用过程Q的例子中,可以看到当Q在执行时,P以及所有在向上追溯到P的调用链中的过程,都是暂时被挂起的。当Q运行时,它只需要为局部变量分配新的存储空间,或者设置到另一个过程的调用。另一方面,当Q返回时,任何它所分配的局部存储空间都可以被释放。因此,程序可以用栈来管理它的过程所需要的存储空间,栈和程序寄存器存放着传递控制和数据、分配内存所需要的信息。当Р调用Q时,控制和数据信息添加到栈尾。当P返回时,这些信息会释放掉。
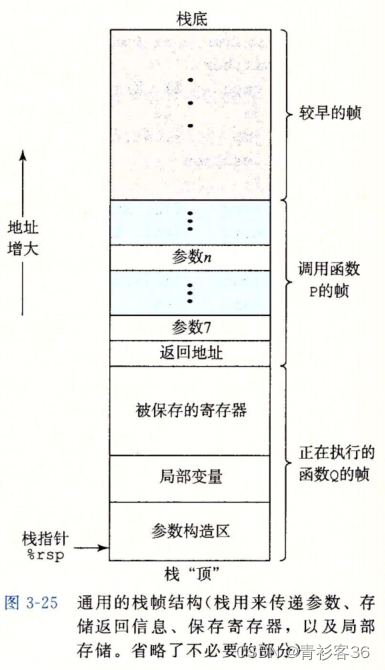
x86-64的栈向低地址方向增长,而栈指针%rsp指向栈顶元素。可以用pushq和popq指令将数据存入栈中或是从栈中取出。将栈指针减小一个适当的量可以为没有指定初始值的数据在栈上分配空间。类似地,可以通过增加栈指针来释放空间。
当x86-64过程需要的存储空间超出寄存器能够存放的大小时,就会在栈上分配空间。这个部分称为过程的栈帧(stack fram)。
下图给出了运行时栈的通用结构,包括把它划分为栈帧。当前正在执行的过程的帧总是在栈顶。当过程Р调用过程Q时,会把返回地址压入栈中,指明当Q返回时,要从Р程序的哪个位置继续执行。我们把这个返回地址当做Р的栈帧的一部分,因为它存放的是与Р相关的状态。Q的代码会扩展当前栈的边界,分配它的栈帧所需的空间。在这个空间中,它可以保存寄存器的值,分配局部变量空间,为它调用的过程设置参数。大多数过程的栈帧都是定长的,在过程的开始就分配好了。但是有些过程需要变长的帧。通过寄存器,过程Р可以传递最多6个整数值(也就是指针和整数),但是如果需要更多的参数,P可以在调用Q之前在自己的栈帧里存储好这些参数。
为了提高空间和时间效率,x86-64过程只分配自己所需要的栈帧部分。例如,许多过程有6个或者更少的参数,那么所有的参数都可以通过寄存器传递。因此,下图画出的某些栈帧部分可以省略。实际上,许多函数甚至根本不需要栈帧。当所有的局部变量都可以保存在寄存器中,而且该函数不会调用任何其他函数(有时称之为叶子过程,此时把过程调用看做树结构)时,就可以这样处理。
Level 0: Candle
主体函数

getbuf函数在test中被调用,当getbuf返回时继续执行第八行
Bufbomb中一个正常情况下不会被执行的函数
void smoke()
{
entry_check(0); /* Make sure entered this function properly */
printf("Smoke!: You called smoke()\n");
validate(0);
exit(0);
}
我们的目标:在getbuf返回时跳到smoke函数执行
老师提供的实验思路:
- 通过调试得到我们输入的字符串首地址,并打印出该字符串作验证x/s $ebp-0xc
- 找到函数smoke的地址 p/x &smoke
- 用smoke函数的地址覆盖getbuf的返回地址
构造一个攻击字符串作为bufbomb的输入,在getbuf()中造成缓冲区溢出,使得getbuf()返回时不是返回到test函数,而是转到smoke函数处执行。所以我们需要:
在bufbomb的反汇编源代码中找到smoke函数,记下它的起始地址

同样在bufbomb的反汇编源代码中找到getbuf()函数,观察它的栈帧结构

如以上图所示,我们可以看到getbuf()的栈帧是0x18+4个字节,而buf缓冲区的大小是0xc(12个字节)。
构造攻击字符串覆盖返回地址
攻击字符串的功能是用来覆盖getbuf函数内的数组buf(缓冲区),进而溢出并覆盖ebp和ebp上面的返回地址,所以攻击字符串的大小应该是0xc+4+4=20个字节。并且其最后4个字节应是smoke函数的地址,正好覆盖ebp上方的正常返回地址。这样再从getbuf返回时,取出的根据攻击字符串设置的地址,就可实现控制转移。
所以,这样的攻击字符串为:
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 20 8e 04 08
总共20个字节,并且前面16个字节可以为任意值,对程序的执行没有任何影响,只要最后四个字节正确地设置为smoke的起始地址<0x08048e20>即可,对应内存写入20 8e 04 08(小端格式)。

Level 1: Sparkler
另一函数

目标:“返回”到该函数并传送参数cookie
Cookie必须为自己学号生成,格式示例如下: SA22225284使用以下指令生成
./makecookie SA22225284
通过观察栈帧结构可以发现只需要在smoke攻击字串后面再继续覆盖调用栈帧的参数。我们知道在执行完ret指令后栈顶指针 %esp 会自动增加4以还原栈帧。
通过查找fizz()得知:
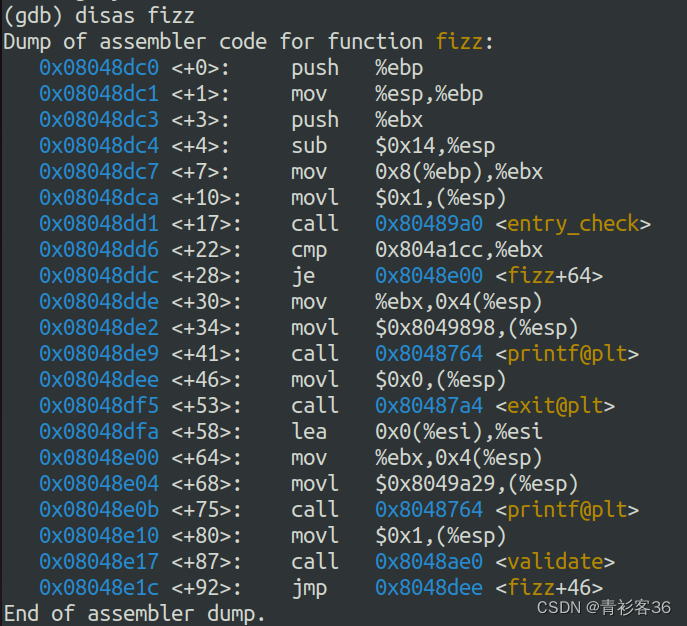
fizz()函数的起始地址为 <0x08048dc0> 。与smoke相同,ebp+4为栈帧返回地址。执行完ret指令后栈顶指针 %esp 会自动增加4以还原栈帧。在fizz汇编代码段,cmp指令是将存放cookie的变量与%ebp+0x8处的值相比,此时参数地址也就是旧的ebp+4+8。我们只需要将自己的cookie放置在该位置即可。
所以构造攻击文件fizz.txt如下:
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 c0 8d 04 08 00 00 00 00 76 9f 6b 30
其中,<0x08048dc0>为fizz函数起始地址,<0x306b9f76>为自己的cookie,通过参数传递给fizz。
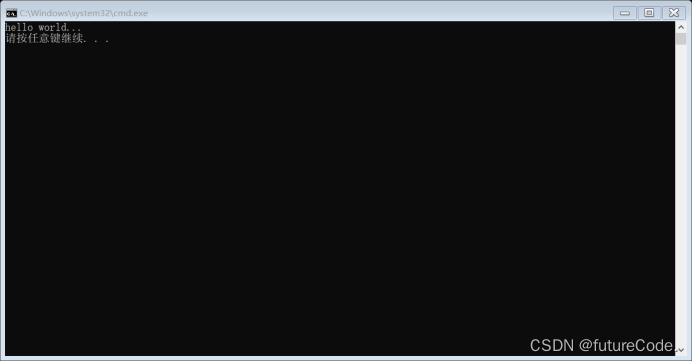
最后执行测试结果如下:

由于下周有三门考试,所以剩下的两个选做实验就暂时不做了hh~

![[Java基础练习-002]综合应用(基础进阶)](https://img-blog.csdnimg.cn/022445a7ea4b4549aaed79cf7a92ecc4.png)