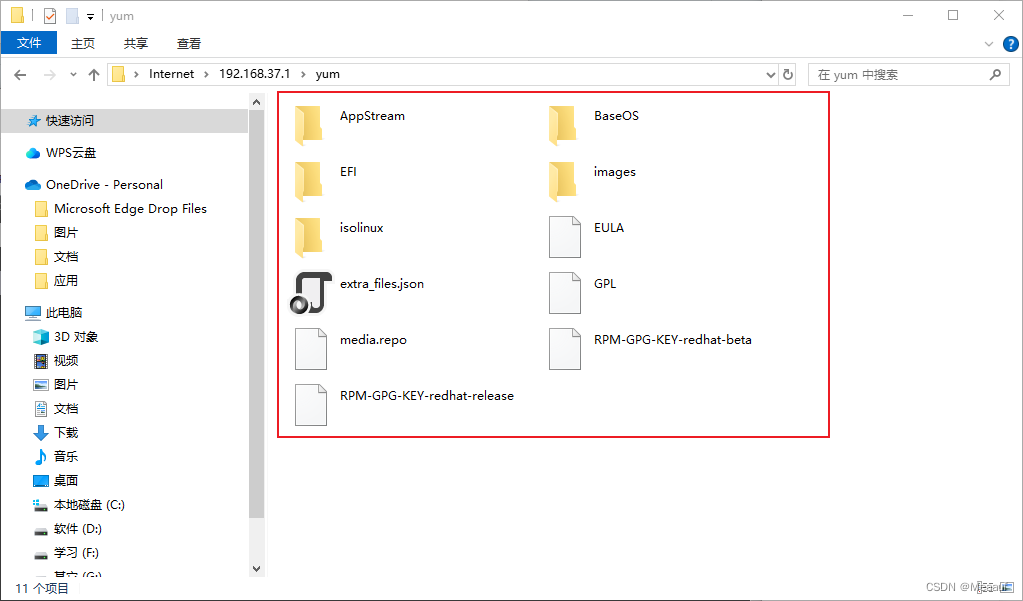
- easy-rl PDF版本 笔记整理 P4、P9
- joyrl 比对 补充 P9 - P10
- 相关 代码 整理

最新版PDF下载
地址:https://github.com/datawhalechina/easy-rl/releases
国内地址(推荐国内读者使用):
链接: https://pan.baidu.com/s/1isqQnpVRWbb3yh83Vs0kbw 提取码: us6a
easy-rl 在线版本链接 (用于 copy 代码)
参考链接 2:https://datawhalechina.github.io/joyrl-book/
其它:
【勘误记录 链接】
——————
5、深度强化学习基础 ⭐️
开源内容:https://linklearner.com/learn/summary/11
——————————
随机性策略
输入: 状态
输出: 动作的概率分布
高维 或 连续动作空间 的问题
环境 和 奖励函数 无法控制
调 策略
神经网络的输入: 智能体 看到的东西
输出神经元的个数 和 动作数 一样
1、添加基线。 让奖励有正有负
2、分配合适的分数。
3、优势函数 1 + 2
REINFORCE 算法: 策略梯度、回合更新、蒙特卡洛。
P9:
actor-critic: 策略梯度 + 时序差分学习
异步优势演员-评论员算法 (asynchronous advantage actor-critic,A3C)
优势演员-评论员(advantage actor-critic,A2C)算法

joyrl:
基于 价值函数 的 RL 算法 的 3 个不足:
1、无法处理 具有连续动作空间 的问题
2、高方差。影响算法收敛性。
3、探索与利用的平衡 仍有改进空间
Asynchronous Advantage Actor Critic (A3C)
Advantage Actor Critic (A2C)
~~~~~
No Asynchronous !!!
——————————————————
A2C VS A3C
OpenAI 关于 A2C 的博文链接
A2CVSA3C
A2C is a synchronous, deterministic variant of Asynchronous Advantage Actor Critic (A3C) which we’ve found gives equal performance.
A2C 是 A3C 的同步、确定性变体,其性能和 A3C 的性能相当。
——————————
Asynchronous Advantage Actor Critic method (A3C) 的 3 个关键思想:
1、一种对固定长度的经验片段(例如,20个时间步)进行操作的更新方案,并使用这些片段来计算 returns 和优势函数的估计。
2、在 策略 和 值函数 之间共享层的架构。
3、异步更新。
——————————
After reading the paper, AI researchers wondered whether the asynchrony led to improved performance (e.g. “perhaps the added noise would provide some regularization or exploration?”), or if it was just an implementation detail that allowed for faster training with a CPU-based implementation.
在阅读了关于 A3C 的论文后,AI 研究人员想知道异步是否会提高性能 (例如,“也许增加的 noise 会提供一些正则化或探索?”),或者这只是一个实现细节,允许使用基于 CPU 的实现进行更快的训练。
As an alternative to the asynchronous implementation, researchers found you can write a synchronous, deterministic implementation that waits for each actor to finish its segment of experience before performing an update, averaging over all of the actors. One advantage of this method is that it can more effectively use of GPUs, which perform best with large batch sizes. This algorithm is naturally calledA2C, short foradvantage actor critic.
作为异步实现的替代方案,研究人员发现 可以编写一个同步的、确定性的实现,在执行更新之前等待每个 actor 完成它的体验片段,对所有 actors 进行平均。
这种方法的一个优点是它可以更有效地使用 GPUs,这在大批量处理时表现最佳。
Our synchronous A2C implementation performs better than our asynchronous implementations—we have not seen any evidence that the noise introduced by asynchrony provides any performance benefit. This A2C implementation is more cost-effective than A3C when using single-GPU machines, and is faster than a CPU-only A3C implementation when using larger policies.
我们的同步 A2C 实现比异步实现性能更好——我们没有看到任何证据表明异步引入的 noise 提供了任何性能优势。
在使用单 GPU 机器时,这种 A2C 实现比 A3C 更具成本效益,在使用更大的策略时,比仅使用 CPU 的 A3C 实现更快。
——————————————————
A3C_2016_谷歌 DeepMind PDF 链接:Asynchronous Methods for Deep Reinforcement Learning
A3C 算法伪码

算法: Asynchronous Advantage Actor Critic (A3C) ~~~~~ 每一个 actor 学习者线程
// 设 全局共享参数向量 θ \theta θ 和 θ v \theta_v θv,全局共享计数 T = 0 T=0 T=0
//设 线程特定参数向量 θ ′ \theta^\prime θ′ 和 θ v ′ \theta^\prime_v θv′
初始化 线程步数计数 t ← 1 t\leftarrow1 t←1
重复以下步骤:
~~~~~~ 重置梯度: d θ ← 0 d\theta\leftarrow0 dθ←0, d θ v ← 0 d\theta_v\leftarrow0 dθv←0
~~~~~~ 同步线程特定参数 θ ′ = θ \theta^\prime=\theta θ′=θ 和 θ v ′ = θ v \theta^\prime_v=\theta_v θv′=θv
~~~~~~ t s t a r t = t t_{\rm start}=t tstart=t
~~~~~~ 获取 状态 s t s_t st
~~~~~~ 重复以下步骤:
~~~~~~~~~~~~ 根据策略 π ( a t ∣ s t ; θ ′ ) \pi(a_t|s_t;\theta^\prime) π(at∣st;θ′) 执行动作 a t a_t at
~~~~~~~~~~~~ 得到 奖励 r t r_t rt 和 新的状态 s t + 1 s_{t+1} st+1
~~~~~~~~~~~~ t ← t + 1 t\leftarrow t+1 t←t+1
~~~~~~~~~~~~ T ← T + 1 T\leftarrow T+1 T←T+1
~~~~~~ 直到 s t s_t st 为终止状态 或 t − t s t a r t = = t max t-t_{\rm start}==t_{\max} t−tstart==tmax
~~~~~~ R = { 0 终止状态 s t V ( s t , θ v ′ ) 非终止状态 s t / / 最后一个状态 B o o t s t r a p R=\left\{\begin{aligned} &0 ~~~~~~~~~~~~~~~~~~~终止状态~ s_t\\ &V(s_t,\theta_v^\prime)~~~~~非终止状态 ~s_t~~//最后一个状态 ~{\rm Bootstrap}\end{aligned}\right. R={0 终止状态 stV(st,θv′) 非终止状态 st //最后一个状态 Bootstrap
~~~~~~ 对于 i ∈ { t − 1 , ⋯ , t s t a r t } i\in\{t-1,\cdots,t_{\rm start}\} i∈{t−1,⋯,tstart}:
~~~~~~~~~~~~ R ← r i + γ R R\leftarrow r_i+\gamma R R←ri+γR
~~~~~~~~~~~~ 关于 θ ′ \theta^\prime θ′ 的累积梯度: d θ ← d θ + ∇ θ ′ log π ( a i ∣ s i ; θ ′ ) ( R − V ( s i ; θ v ′ ) ) d\theta\leftarrow d\theta+\nabla_{\theta^\prime}\log\pi(a_i|s_i;\theta^\prime)(R-V(s_i;\theta_v^\prime)) dθ←dθ+∇θ′logπ(ai∣si;θ′)(R−V(si;θv′))
~~~~~~~~~~~~ 关于 θ v ′ \theta^\prime_v θv′ 的累积梯度: d θ v ← d θ v + ∂ ( R − V ( s i ; θ v ′ ) ) 2 ∂ θ v ′ d\theta_v\leftarrow d\theta_v+\frac{\partial(R-V(s_i;\theta_v^\prime))^2}{\partial\theta_v^\prime} dθv←dθv+∂θv′∂(R−V(si;θv′))2
~~~~~~ 用 d θ dθ dθ 异步更新 θ θ θ,用 d θ v dθ_v dθv 异步更新 θ v θ_v θv
直到 T > T max ~T>T_{\max} T>Tmax
参考链接 1: https://github.com/datawhalechina/joyrl-book/tree/main/notebooks
参考链接 2: https://github.com/datawhalechina/easy-rl/tree/master/notebooks
- A2C 代码实现