1、Terms Set 检索简介
Terms Set查询是Elasticsearch中一种强大的查询类型,主要用于处理多值字段中的文档匹配。
其核心功能在于,它可以检索至少匹配一定数量给定词项的文档,其中匹配的数量可以是固定值,也可以是基于另一个字段的动态值。这种查询方式在处理具有多个属性、分类或标签的复杂数据时非常有用。
2、Terms Set 检索产生背景
Terms Set查询是Elasticsearch 6.1版本中引入的新功能。在6.1版本之前,Elasticsearch提供了多种查询类型,但在处理多值字段时,用户可能需要编写更复杂的查询或使用脚本来实现特定的匹配条件。
引入Terms Set查询的主要目的是为了简化这类场景下的查询处理。使用Terms Set查询,用户可以轻松地找到至少匹配一定数量给定词项的文档,同时支持基于其他字段或脚本动态计算匹配数量。这种查询方式在处理具有多个属性、分类或标签的复杂数据时非常有用。
3、Terms Set 检索应用场景
Terms Set查询在处理多值字段和特定匹配条件时非常有用。
以下是一些常见的应用场景:
标签系统
在具有标签系统的应用中,如博客、社交媒体或新闻网站,用户可能会为内容(如文章、帖子或产品)分配多个标签。使用Terms Set查询,可以找到至少具有一定数量给定标签的内容。这对于筛选和推荐功能非常有用。
搜索引擎
在搜索引擎中,用户可能会输入多个关键词来查找相关内容。使用Terms Set查询,可以根据文档与给定关键词的匹配程度对结果进行排序。例如,可以找到至少匹配用户输入关键词一半数量的文档。
电子商务
在电子商务应用中,产品可能具有多个属性,如颜色、尺寸或品牌。使用Terms Set查询,可以找到同时满足多个属性条件的产品。例如,可以找到至少具有2个指定颜色和3个指定尺寸的产品。
文档管理系统
在文档管理系统中,文档可能具有多个分类或标签。使用Terms Set查询,可以根据文档的分类或标签匹配程度进行筛选。例如,可以找到与给定分类或标签至少匹配一定数量的文档。
技能匹配
在招聘或求职应用中,候选人可能具有多个技能。使用Terms Set查询,可以找到至少具有一定数量给定技能的候选人。这对于筛选和推荐合适的候选人非常有用。总之,Terms Set查询在处理具有多个属性、分类或标签的复杂数据时非常有用。通过灵活地设置匹配数量条件,可以轻松地找到满足特定要求的文档。
4、Terms Set 检索的工作原理
Terms Set查询的基本语法如下:
{
"query": {
"terms_set": {
"<字段名>": {
"terms": ["<词项1>", "<词项2>", ...],
"minimum_should_match_field": "<匹配数量字段名>",
"minimum_should_match_script": {
"source": "<脚本>"
}
}
}
}
}Terms Set查询的工作原理可以分为以下几个步骤:
指定要查询的字段名,这个字段通常是一个多值字段,如数组或集合。
提供一组词项,用于在指定字段中进行匹配。
设置匹配数量的条件,可以有两种方式(二者不可兼得,只能选择其中一个):
通过 minimum_should_match_field 参数指定一个包含匹配数量的字段名。
使用 minimum_should_match_script 参数提供一个脚本,该脚本可以动态计算匹配数量。
Elasticsearch会检索匹配给定词项数量要求的文档,并将它们作为查询结果返回。
5、Terms Set 检索应用示例
假设我们有一个电影数据库,每部电影都有多个标签。现在,我们希望找到同时具有一定数量给定标签的电影。
以下是一个使用Terms Set查询的例子:
5.1 数据准备
首先,创建一个名为movies的索引:
PUT movies
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"tags": {
"type": "keyword"
},
"tags_count": {
"type": "integer"
}
}
}
}然后,向索引中添加一些电影数据:
POST /movies/_bulk
{"index":{"_id":1}}
{"title":"电影1","tags":["喜剧","动作","科幻"],"tags_count":3}
{"index":{"_id":2}}
{"title":"电影2","tags":["喜剧","爱情","家庭"],"tags_count":3}
{"index":{"_id":3}}
{"title":"电影3","tags":["动作","科幻","喜剧"],"tags_count":3}5.2 使用Terms Set 检索电影
现在,我们希望找到至少具有2个给定标签("喜剧"、"动作"和"科幻")的电影。我们可以使用Terms Set查询来实现这个需求:
基于minimum_should_match_field 检索
GET /movies/_search
{
"query": {
"terms_set": {
"tags": {
"terms": ["喜剧", "动作", "科幻"],
"minimum_should_match_field": "tags_count"
}
}
}
}上述代码使用 terms_set 查询,在名为 movies 的索引中检索满足动态匹配数量要求的电影,匹配数量由 tags_count 字段决定,查询标签包括"喜剧"、"动作"和"科幻"。返回结果如下,文档1被召回。

再看如下的检索。
基于minimum_should_match_script 检索
GET /movies/_search
{
"query": {
"terms_set": {
"tags": {
"terms": [
"喜剧",
"动作",
"科幻"
],
"minimum_should_match_script": {
"source": "doc['tags_count'].value * 0.7"
}
}
}
}
}如上检索从名为 movies 的索引中检索至少匹配给定标签("喜剧"、"动作"和"科幻")总数70%数量要求的电影,匹配数量由自定义脚本doc['tags_count'].value * 0.7动态计算。“_id”为1和“_id”为3的两个文档被召回。
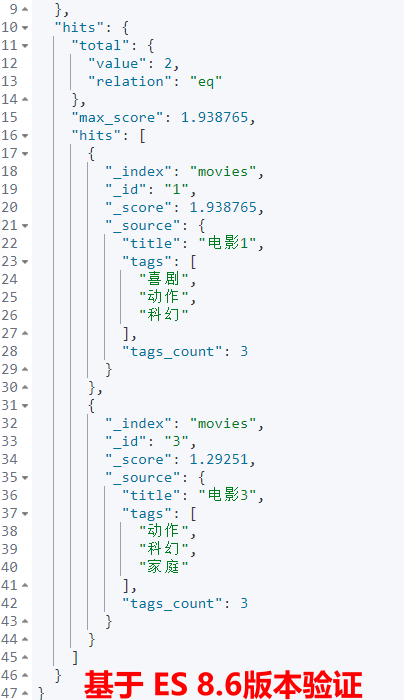
6、小结
Terms Set查询是Elasticsearch中一种非常强大的查询方式,适用于处理具有多个属性、分类或标签的复杂数据。
通过灵活地设置匹配数量条件,我们可以轻松地找到满足特定要求的文档。
然而,需要注意的是,使用Terms Set查询时可能会遇到性能问题,特别是在处理大量数据时。为了提高查询性能,可以考虑对数据进行预处理,例如使用聚类算法将标签分组,然后根据分组查询文档。
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

抢先一步学习进阶干货!