目录
🌟一、数据库约束
🌈1、Null约束:创建表时,可以指定某列不能为空。
🌈2、Unique约束:唯一约束
🌈3、Default约束:默认值约束
🌈4、Primary Key:主键约束(不能为空且要唯一)
🌈5、foreign key:外键约束(主外键关系是两个表之间的。)
🌈6、Check约束(了解):MySQL使用时不报错,但忽略该约束。
🌟二、表的设计
🌟三、新增
🌈1、插入查询结果:将一个表的查询结果直接插入到另一个表中。
🌟四、查询
聚合查询
🌈1、聚合函数
🌈2、Group By子句
🌈3、Having:如果要对group by后分组的结果做过滤,必须要用having做过滤。
联合查询 (关键)
🌈1、内连接
🌈2、外连接
🌈3、自连接
🌈4、子查询
🌈5、合并查询
🌟一、数据库约束
| 类型 | 描述 |
| Not Null | 表示某列值不能为Null |
| Unique | 保证某行的值在改列中是唯一的 |
| Default | 在没有赋值时使用的是默认值 |
| Primary Key | 是Not Null与Unique的结合。也就是既不能为空,且该值在列中是唯一的。保证某列或者多个列有唯一标识,有利于快速找到表中的唯一记录。 |
| Foreign Key | 保证一个表中的数据匹配另一个表中的参照完整性。 |
| Check | 保证列中的值符合指定的条件。 |
我们来具体演示一下~
🌈1、Null约束:创建表时,可以指定某列不能为空。
设计一个学生表,指定id不能为空。

🌈2、Unique约束:唯一约束
指定sn学号列为唯一的,不重复的。

🌈3、Default约束:默认值约束
创建student表的时候,默认name名为'无名氏'。

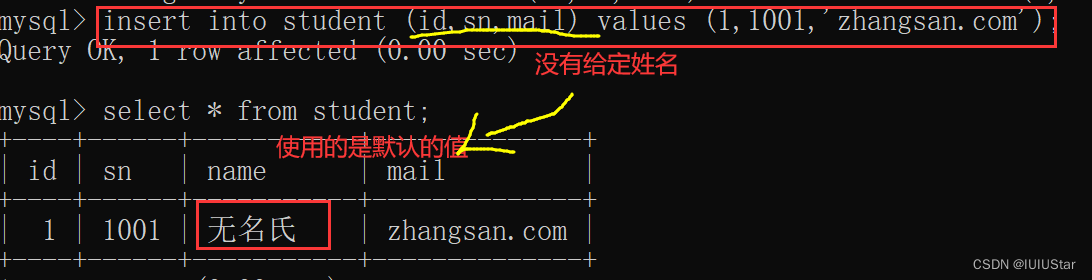
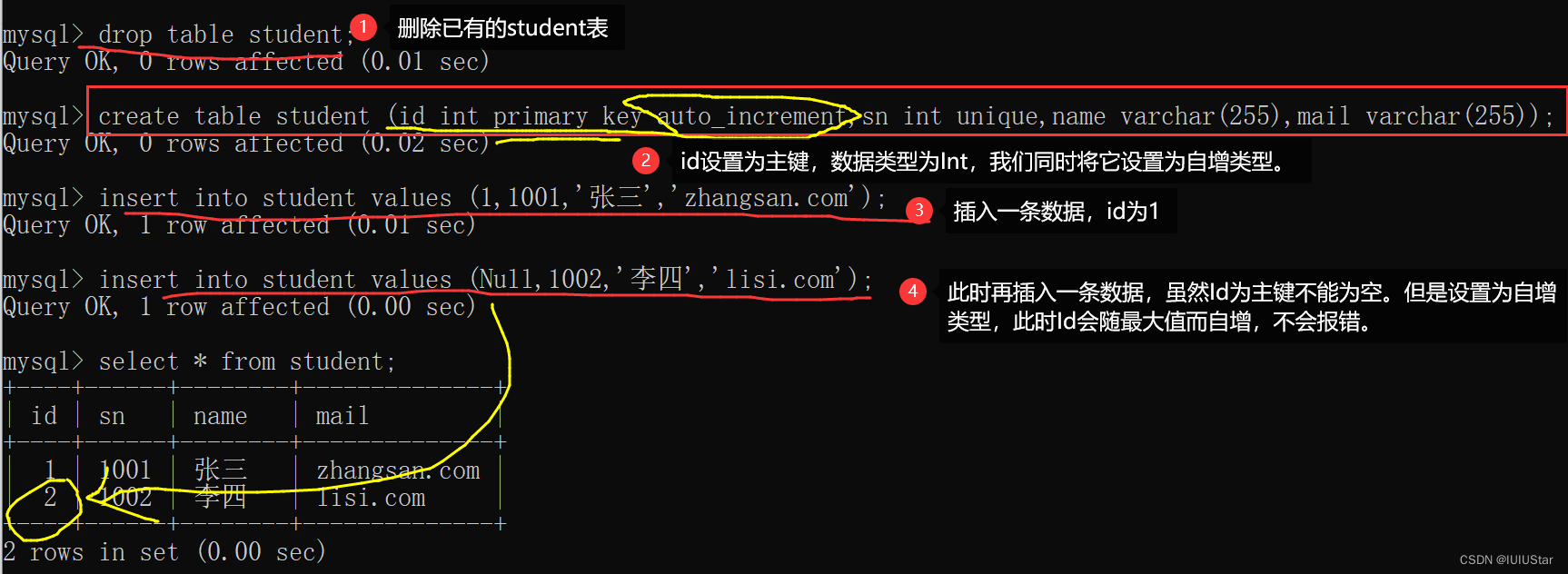
🌈4、Primary Key:主键约束(不能为空且要唯一)
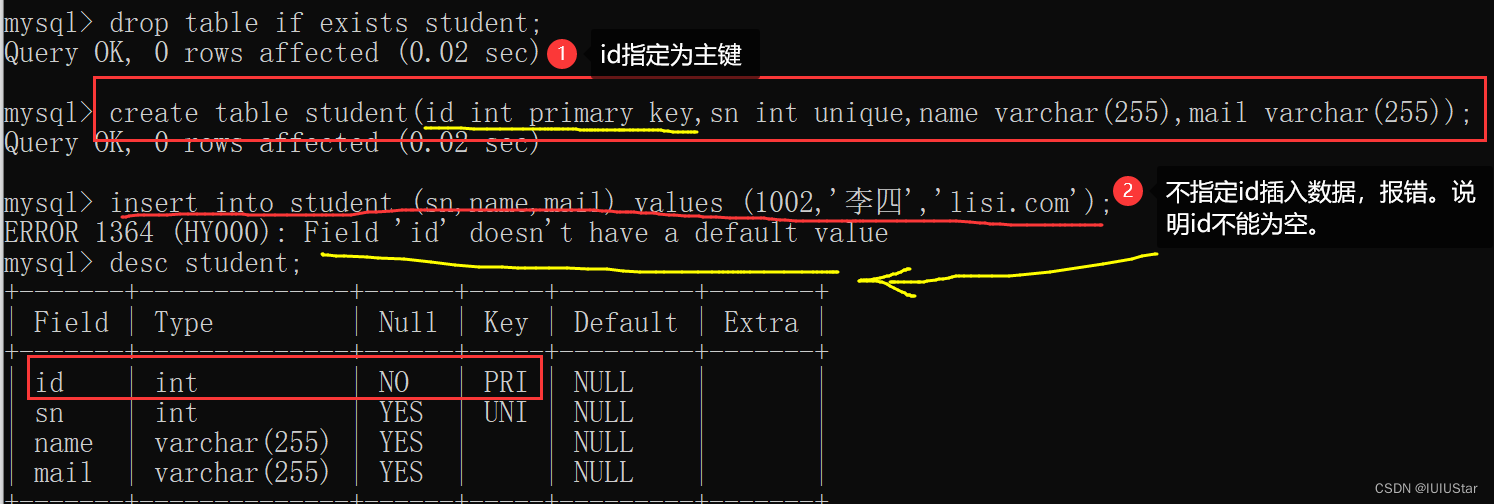
创建student表,指定id是主键约束。
字段名id设置为主键为空报错:
字段名id设置为重复的值报错: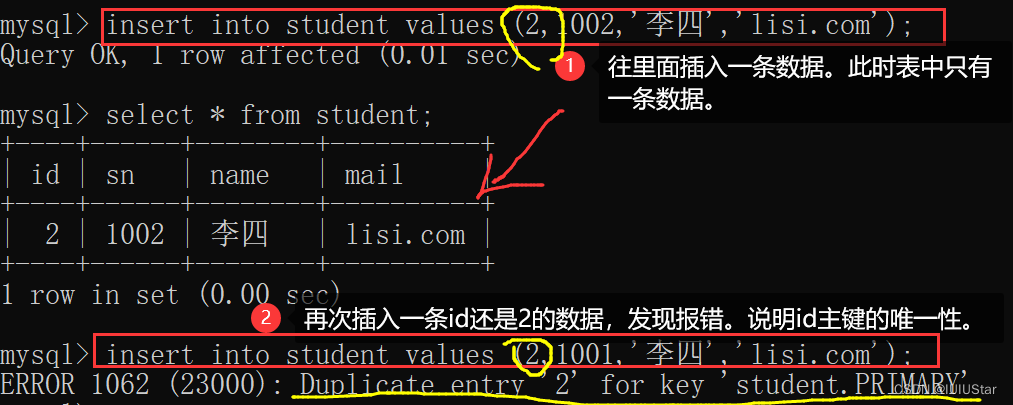
注意:如果字段名为整数类型,设置主键的时候一般搭配auto_increment自增长来使用。当插入数据对应字段不给值的时候,会使用最大值+1。
🌈5、foreign key:外键约束(主外键关系是两个表之间的。)
外键约束用于关联其他表的主键或者唯一键。其中负责约束的一方,称为父表。被约束的一方,称为子表。其中foreign key(字段名) 填写的是本表(子表)的外键, references 主表列) 填写的是父表的主键
foreign key (字段名) references 主表(列);🌰创建班级表classes,id为主键。创建学生表student,学生表中除了有自身的id之外,还关联着班级表classes_id。一个学生对应一个班级,一个班级对应多个学生。
(1)创建班级表和学生表
 (2)父表对子表的约束:往学生表中插入数据
(2)父表对子表的约束:往学生表中插入数据
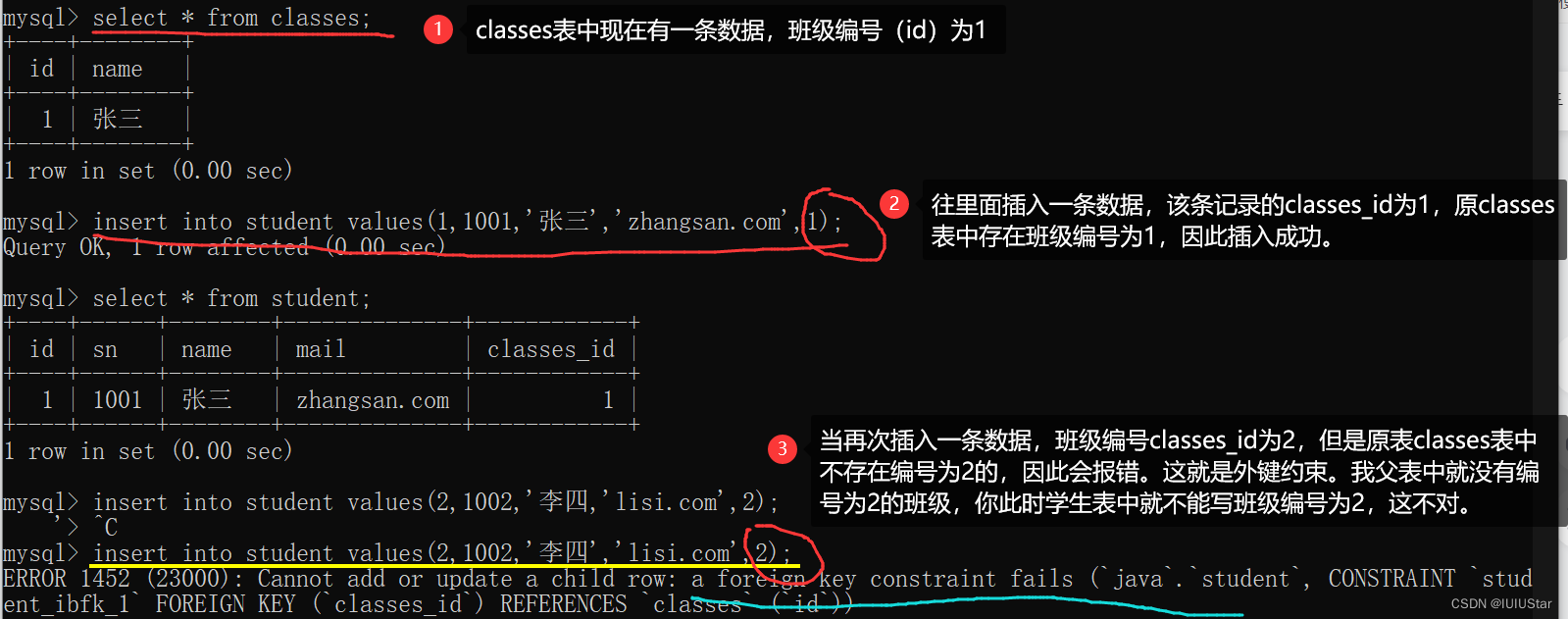
(3)子表对父表的限制:如果要删除classes表中的一条编号是id的数据,那就要先删除student表中对应classes_id的记录。原因就是:如果classes表中现在的id一共有3个,表示1班2班和3班,然后你直接删除classes班级表中id=3的记录,那么此时班级只剩下2个了,但是学生表中还有之前classes_id班级编号为3的学生存在呀,你这让他们一下子“无处可归”了😅。
错误操作: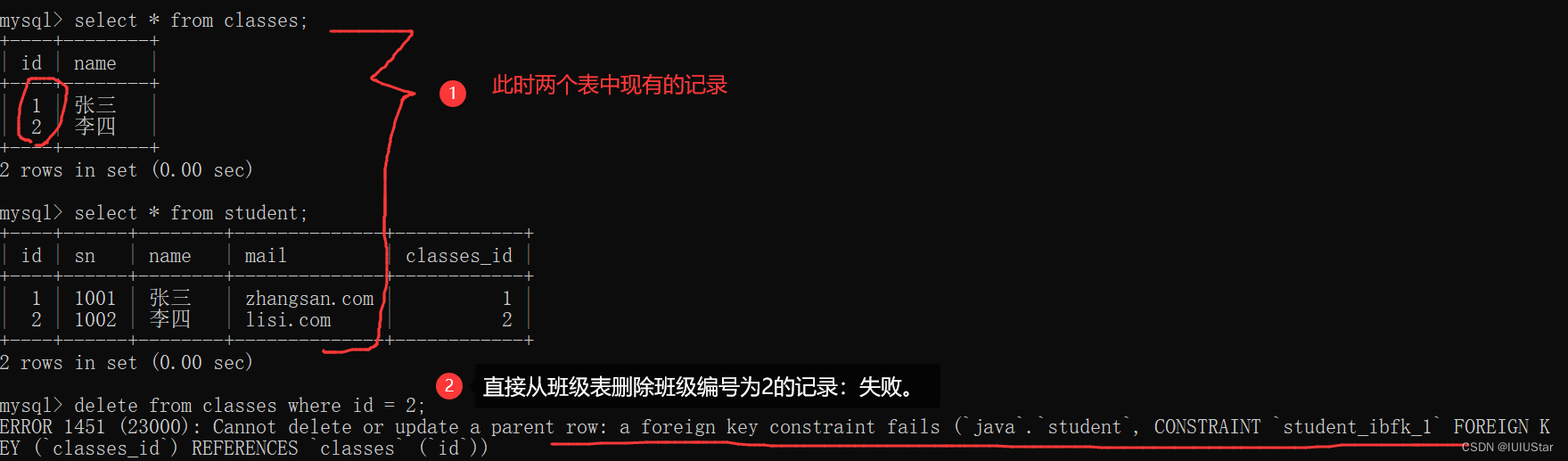
正确演示: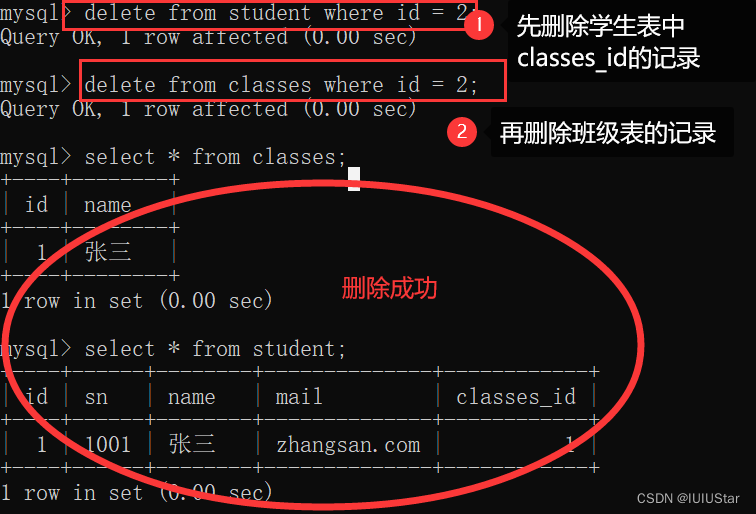
🌈6、Check约束(了解):MySQL使用时不报错,但忽略该约束。
在一些情况下,我们需要字段在指定范围的输入,例如:性别只能输入 '男'或者'女'。我们除了在程序上控制以外,我们还能使用 CHECK 约束 来规范数据。

🌟二、表的设计
根据需求文档或者现实世界中的实体或类转化为具体的一张张表。表对应到Java中的类,表中的字段名对应Java类中的属性。
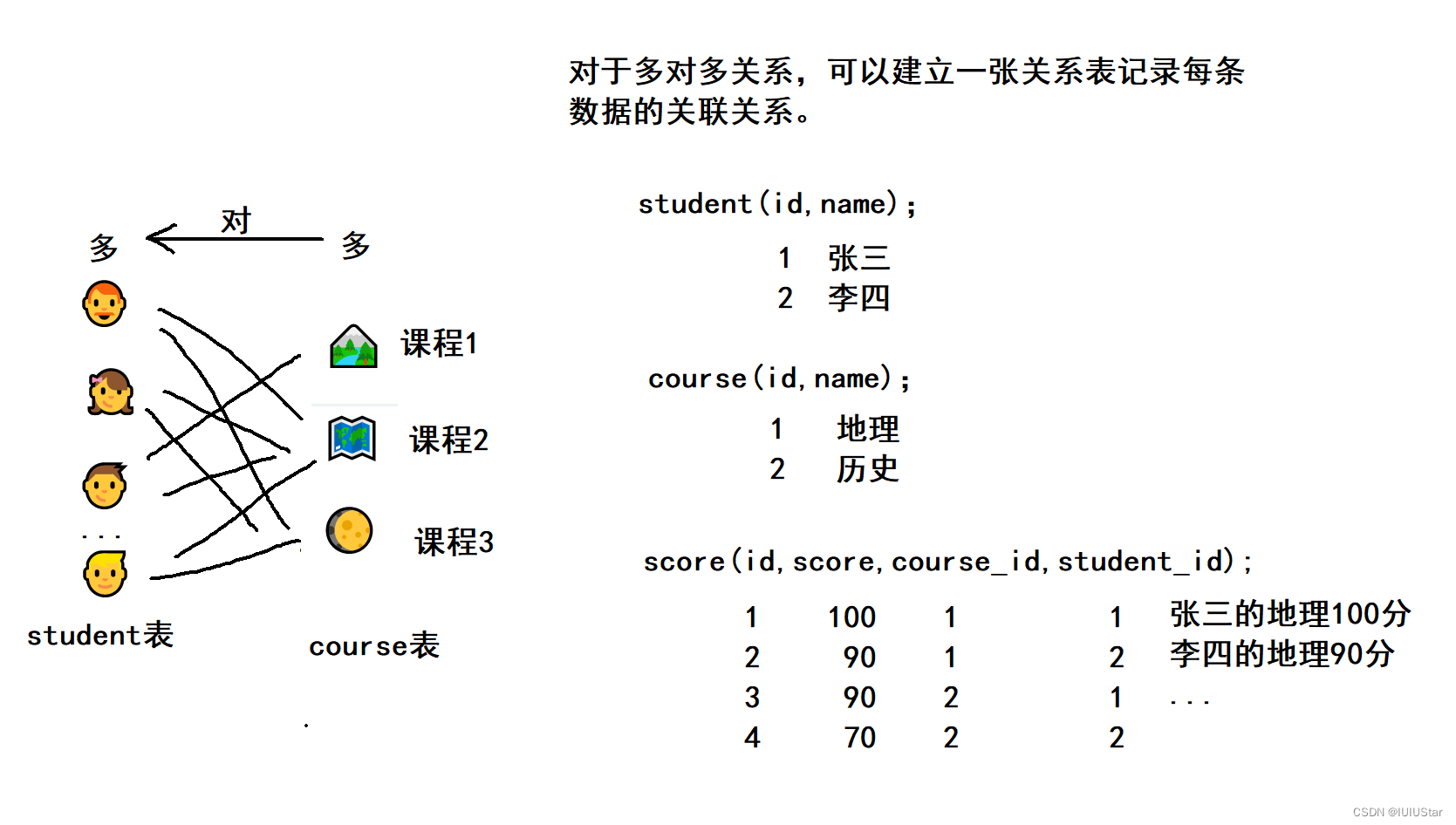
在设计数据库的时候主要有以下四种关系:(1)没有关系;(2)一对一关系;(3)一对多关系;(4)多对多关系。后三者又称为表设计的三大范式。
1、一对一:每个人只有一个身份证号。

2、一对多:一个学生只能有一个班级,一个班级可以有很多学生。

3、多对多:一个学生可以选多门课程,一门课程可以有很多学生选择。
🌟三、新增
🌈1、插入查询结果:将一个表的查询结果直接插入到另一个表中。
指定的列名必须要和查询的列名顺序保持一致。
insert into 表名 (指定的列名) select ...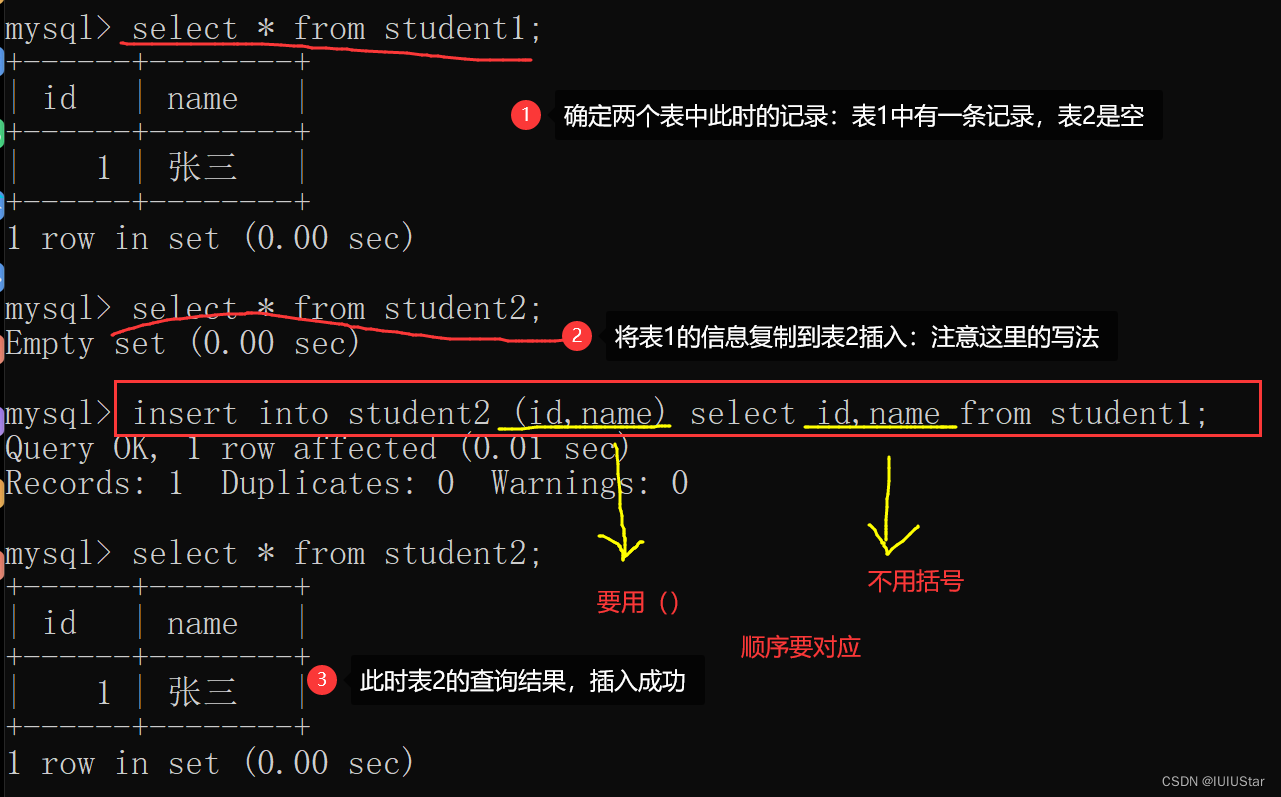
🌟四、查询
聚合查询
🌈1、聚合函数

(1)统计班级共有多少学生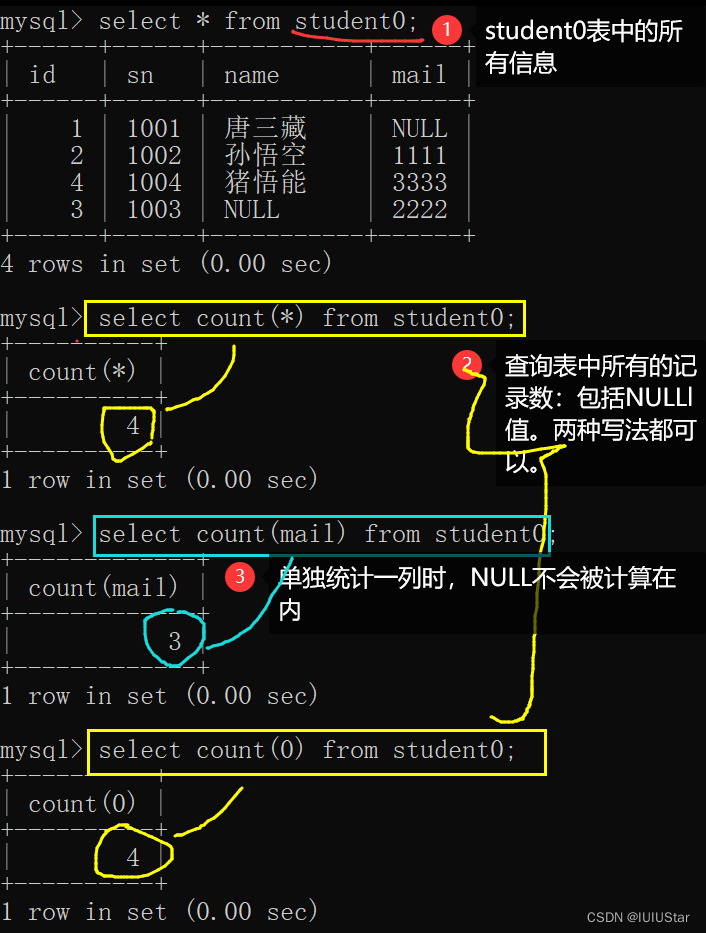
(2)统计英语成绩总分
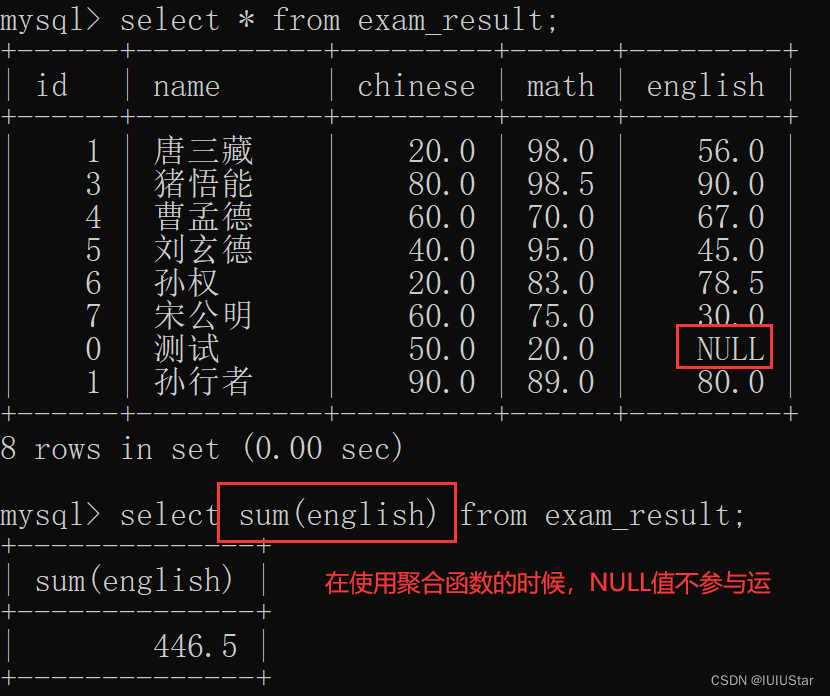
(3)求语数英的平均分
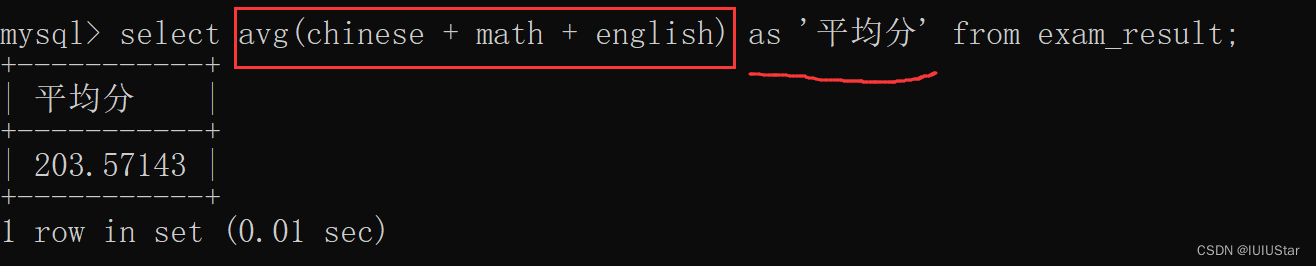
(4)返回语文的最高分和数学的最低分

🌈2、Group By子句
select 中使用 Group By 子句可以对指定列进行分组查询。需要满足:使用 Group By进行分组查询时,select 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
select 要分组的字段, sum(分组后要做的操作,以sum为例) from 表名 (where) group by 要分组的字段 having (对group by后的结果做过滤);测试表emp信息如下:
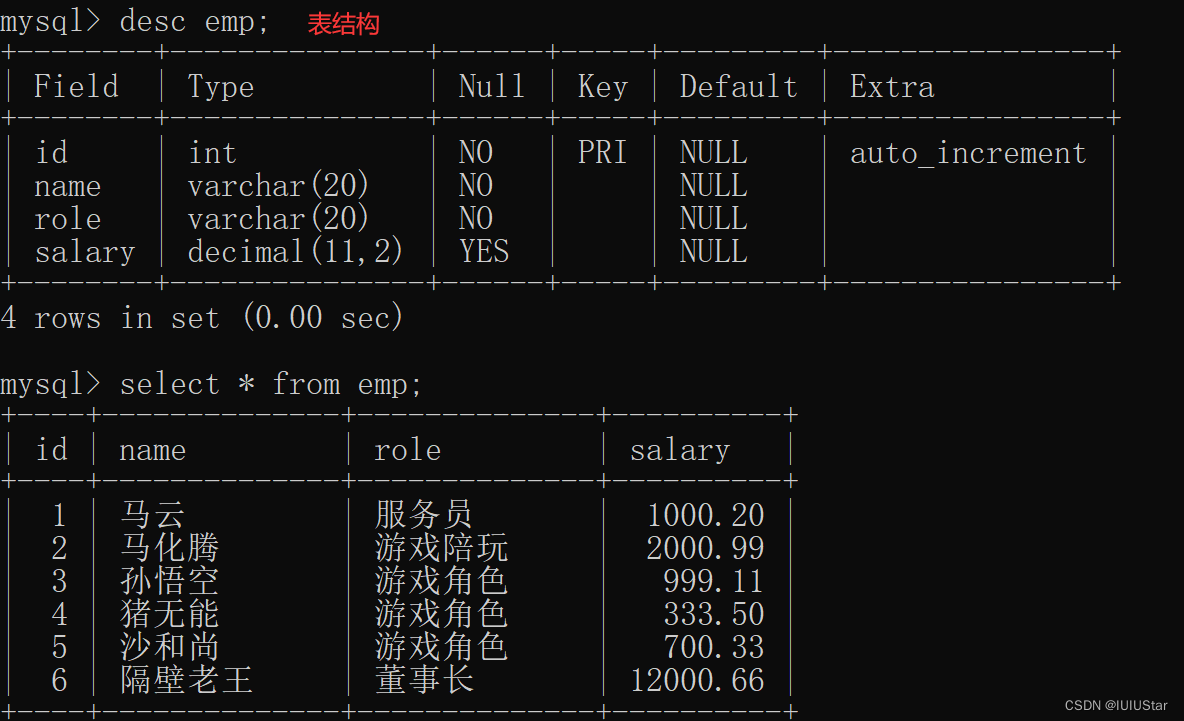
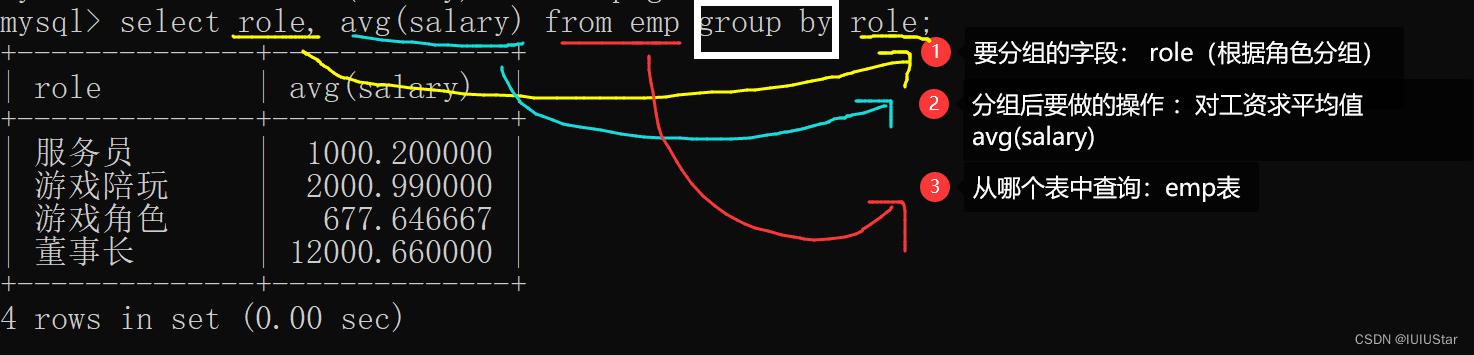
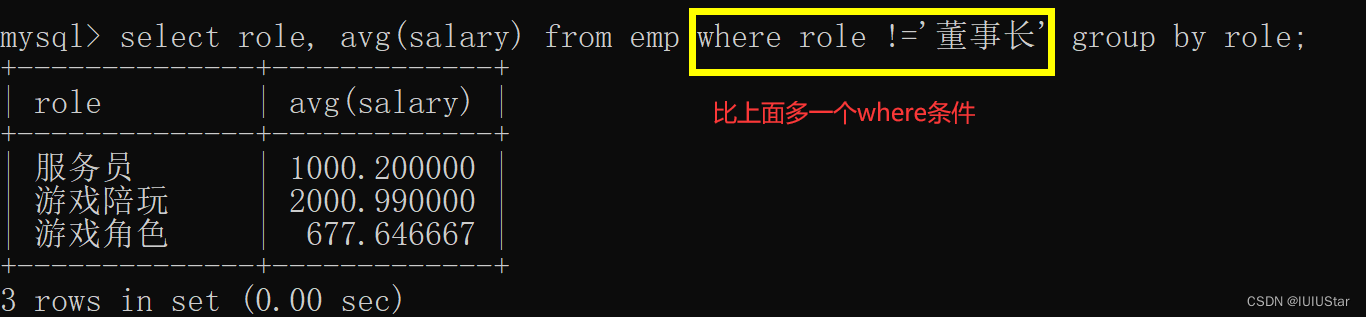
(1)求不同角色下的平均工资
(2)求不同角色下的平均工资但是不包含董事长这个角色

🌈3、Having:如果要对group by后分组的结果做过滤,必须要用having做过滤。
注意区分:
SQL执行的顺序是From —> where ——> select —— > group by
where是对表中的数据整体做过滤,跟在from表名后面。
having是对分组后的结果做过滤,要跟在group by子句后面。
(1)过滤掉平均工资小于800的角色,且角色不为董事长。

联合查询 (关键)
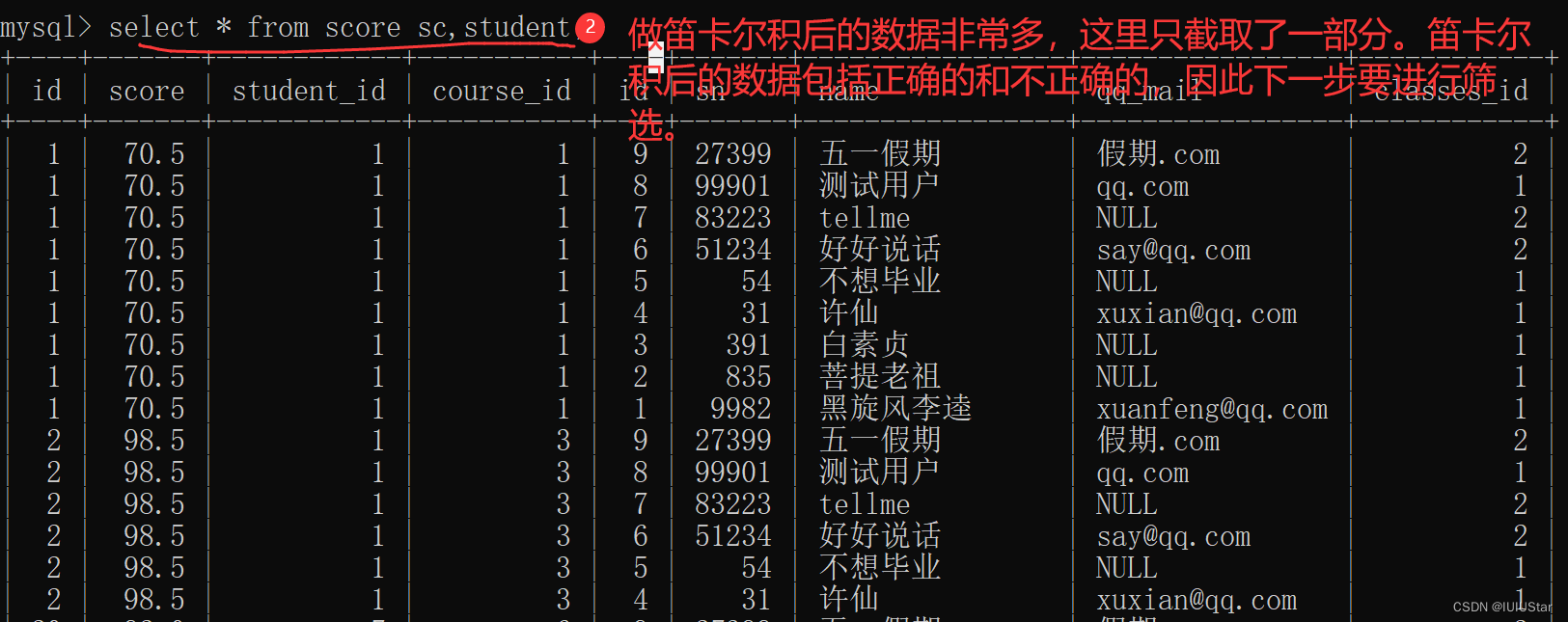
为什么要用联合查询?在实际生活中,数据通常来自于不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积。什么是笛卡尔积?就是对表中的所有记录做一个全排列。在联合查询的过程中可以为表起别名。
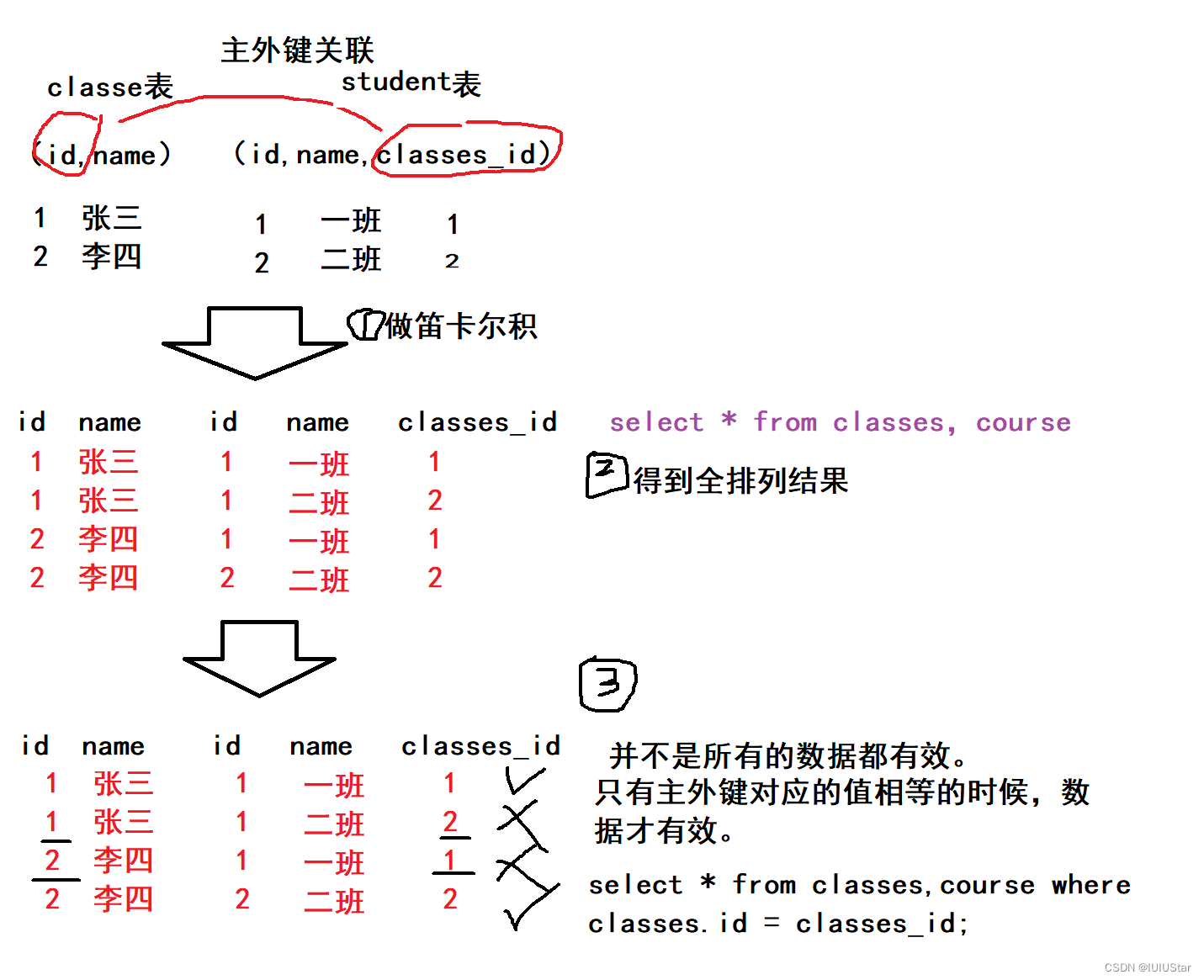
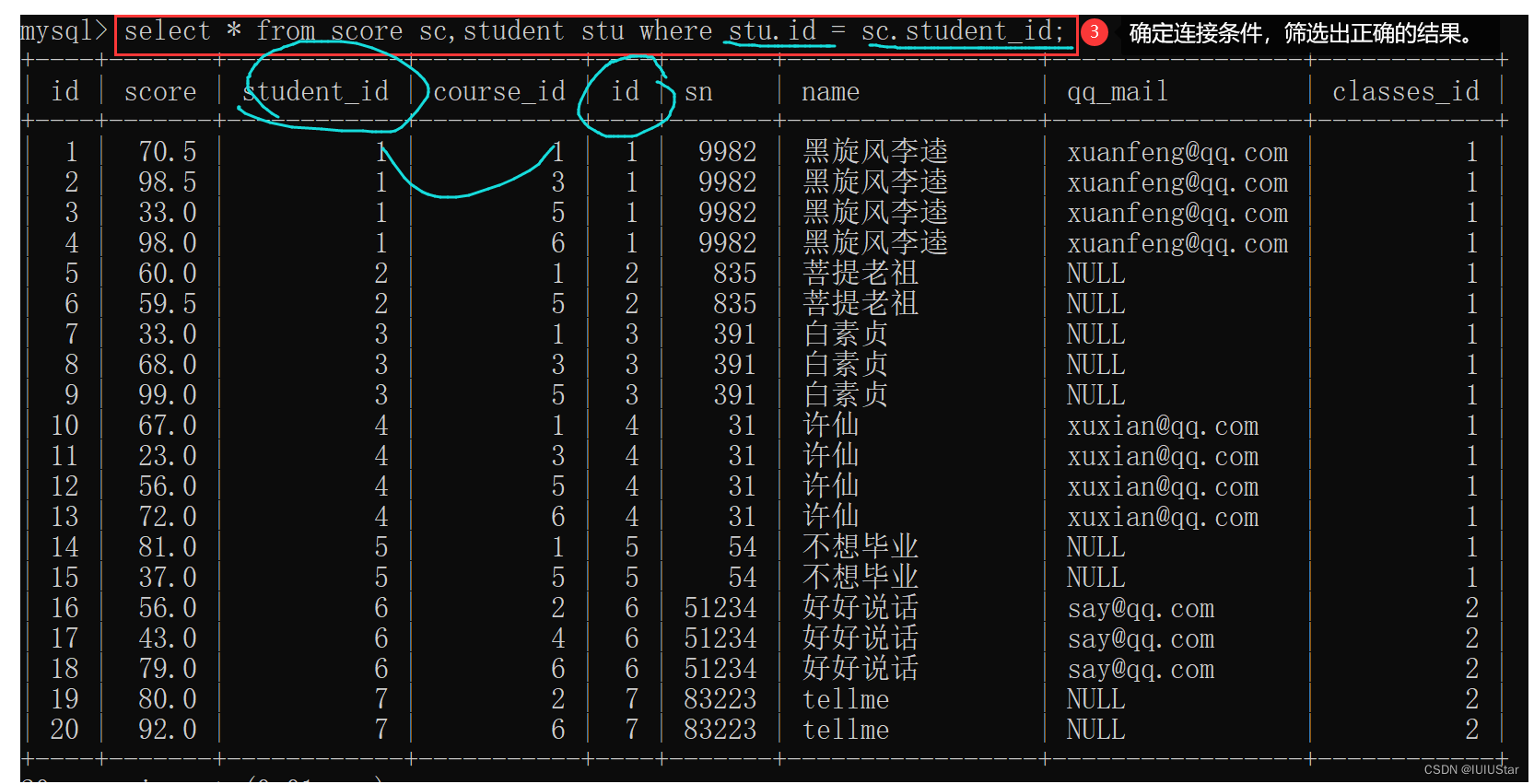
🌈1、内连接
select 字段 from 表1 别名1 (inner) join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1, 表2 别名2 where 连接条件 and 其他条件;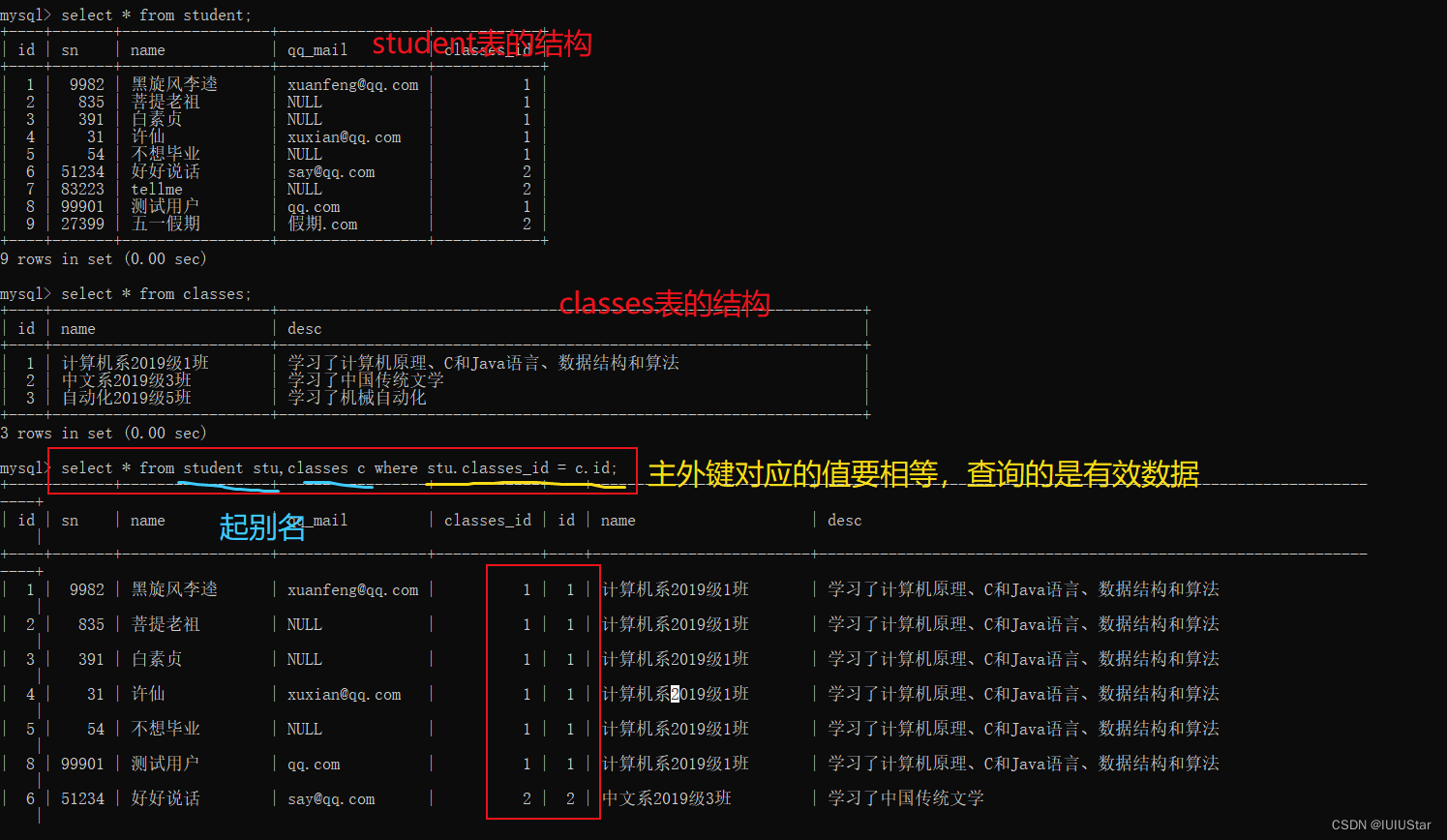
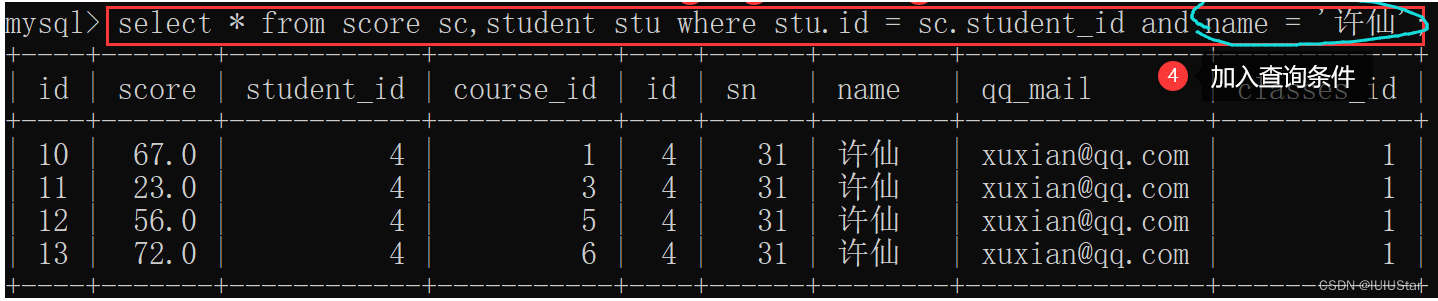
(1) 查询许仙同学的成绩

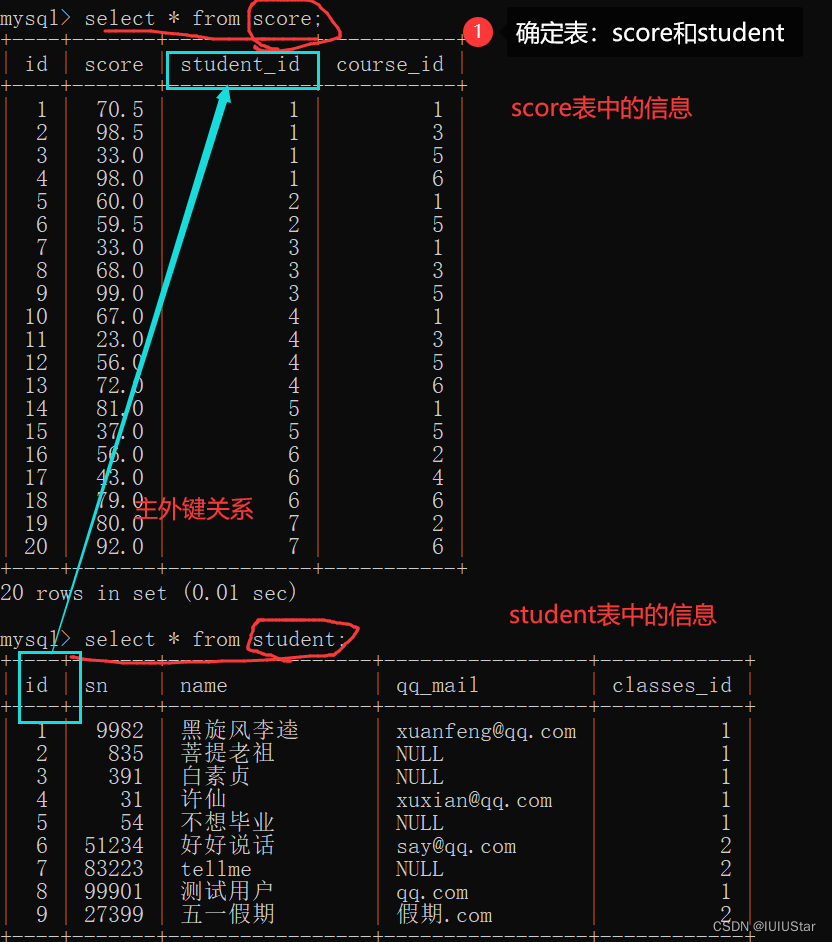

(2)查询所有同学的总成绩以及同学们的姓名。

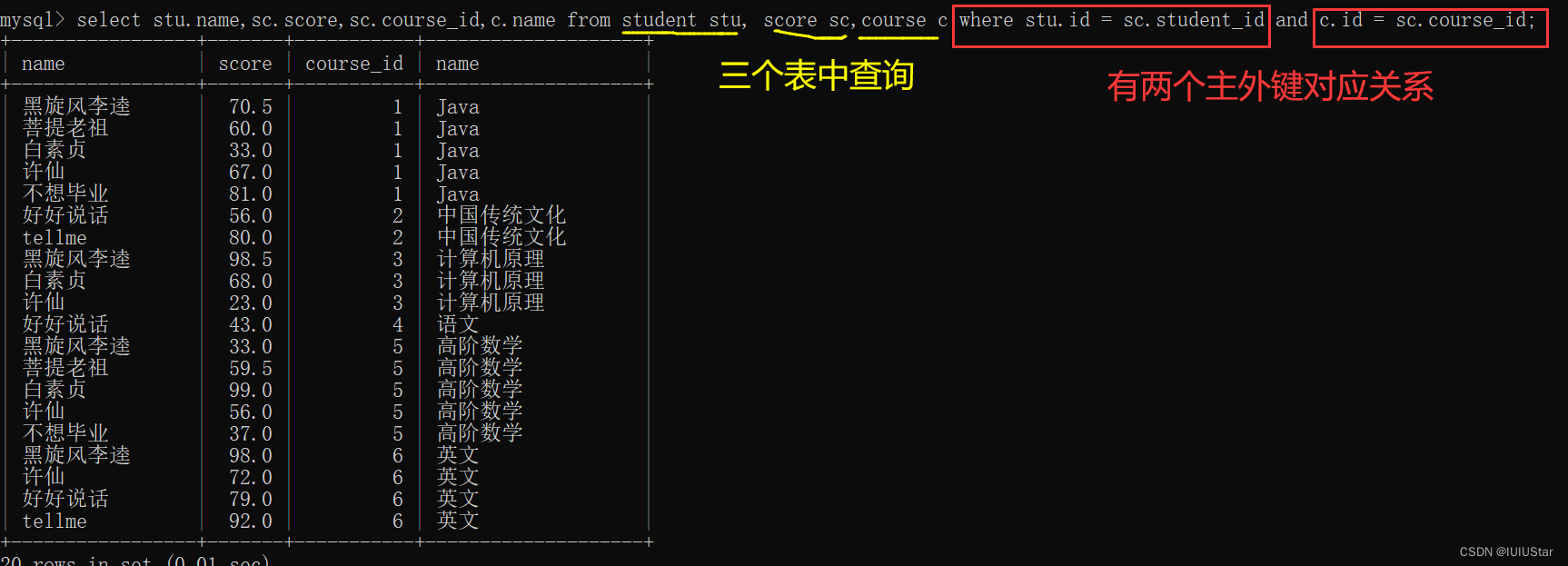
(3)查询所有同学每门课的成绩以及姓名。
🌈2、外连接
外连接分为左外连接和右外连接。左外连接就是左表完全显示,右边如果没有匹配到数据,就以NULL来填充当前行。右外连接就是右表信息完全显示。
-- 左外连接:表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件:
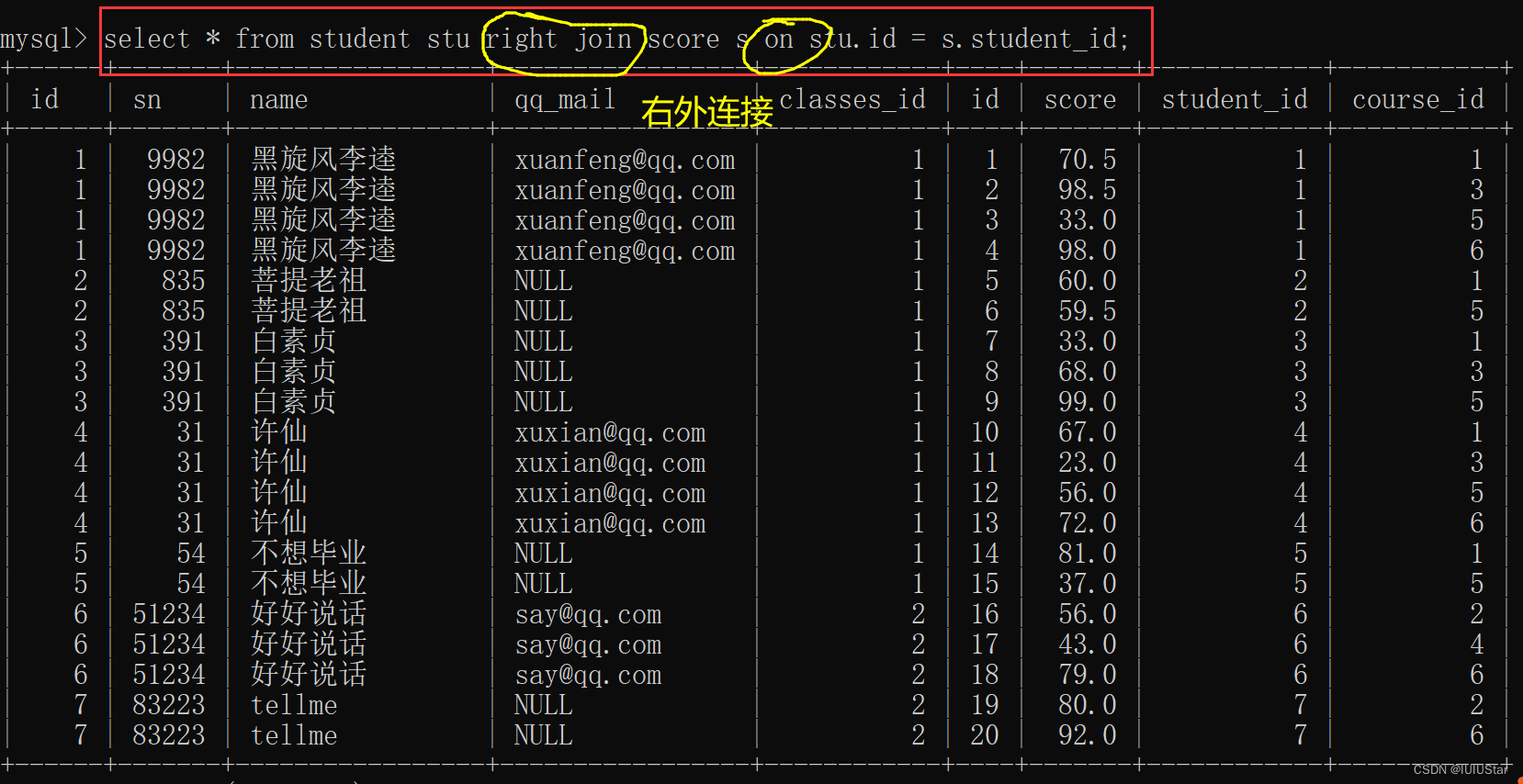
-- 右外连接:表2完全显示
select 字段名 from 表名1 right join 表名2 on 连接条件: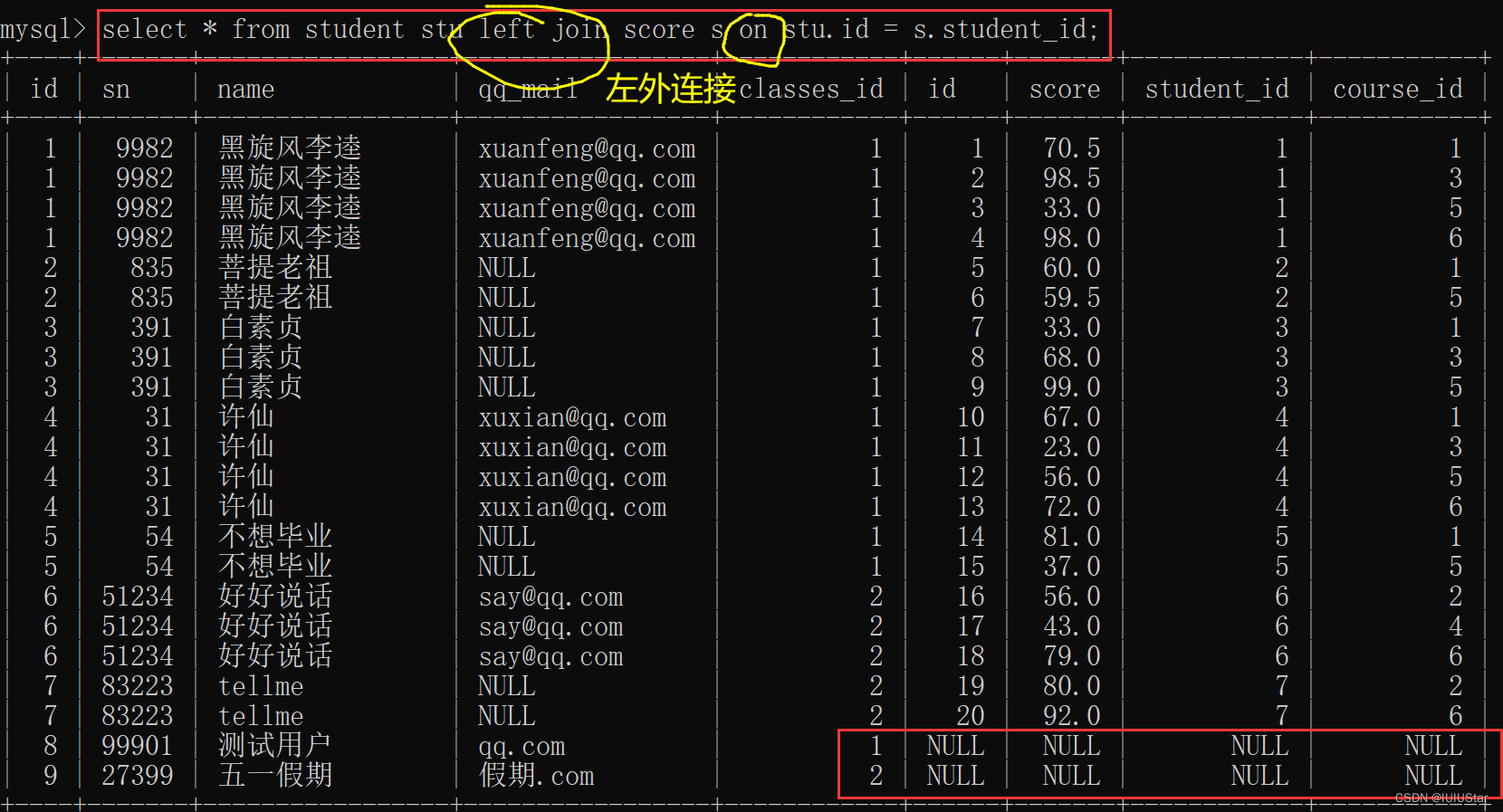
🌈3、自连接
自连接连接的是同一张表。实质是将列转化为行,从而实现行与行之间的计算。在同一张表自连接两次,会显示不能重复使用表名,因此要起别名。
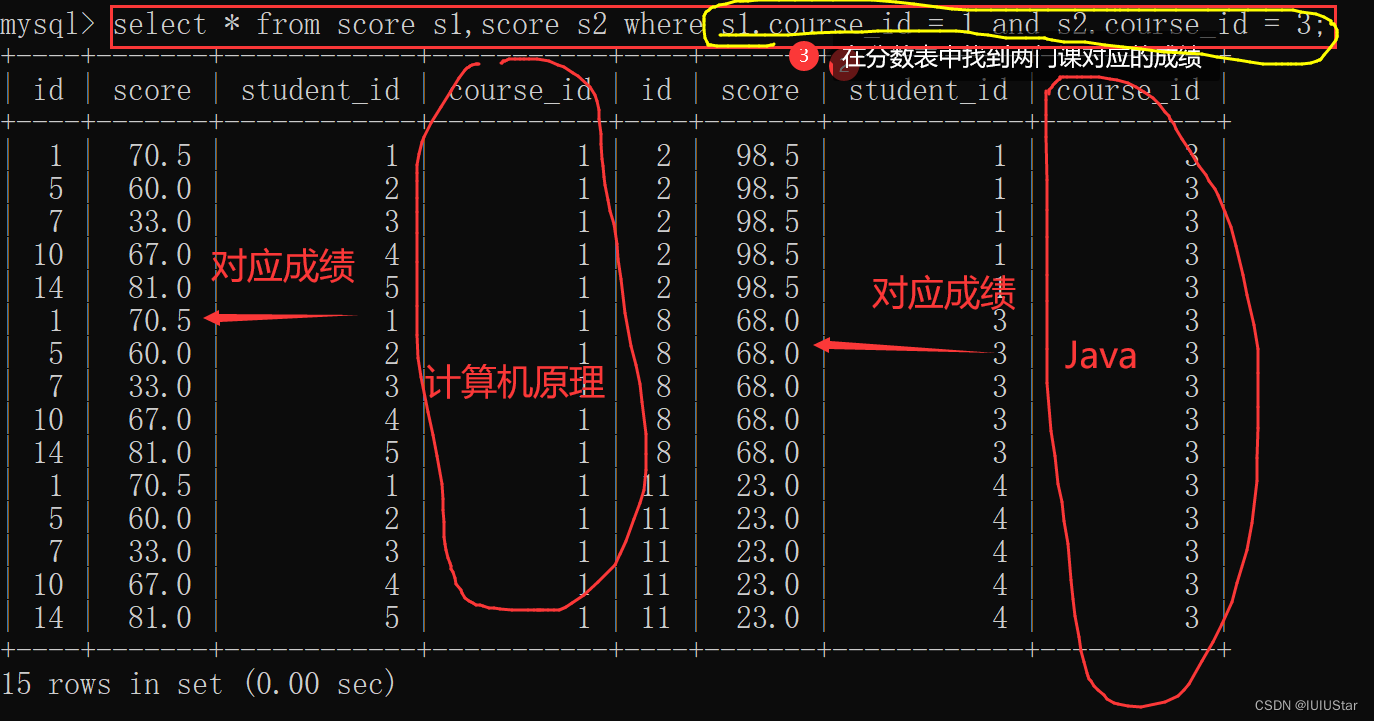
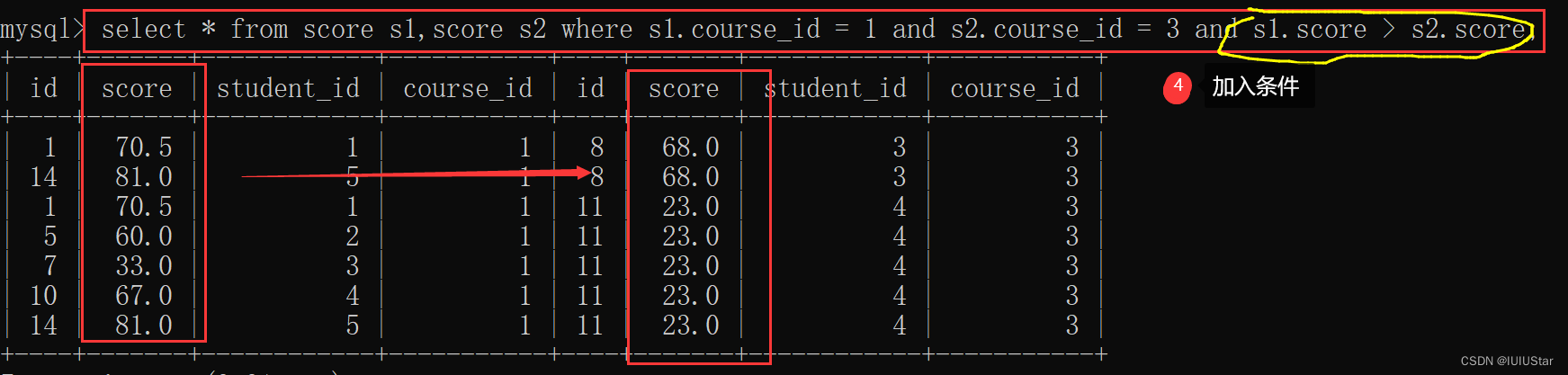
(1)找出所有“计算机原理”比“Java”成绩高的成绩信息。
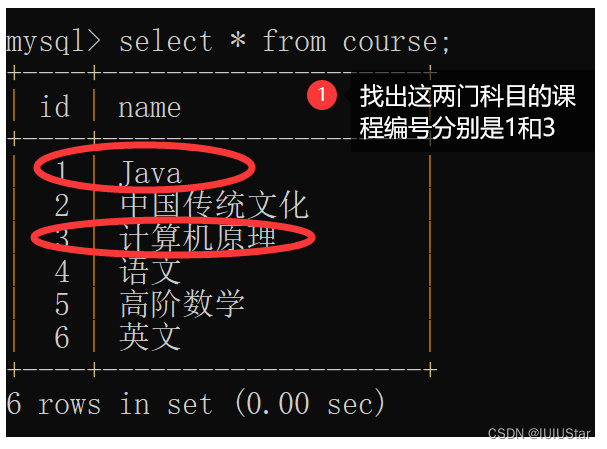
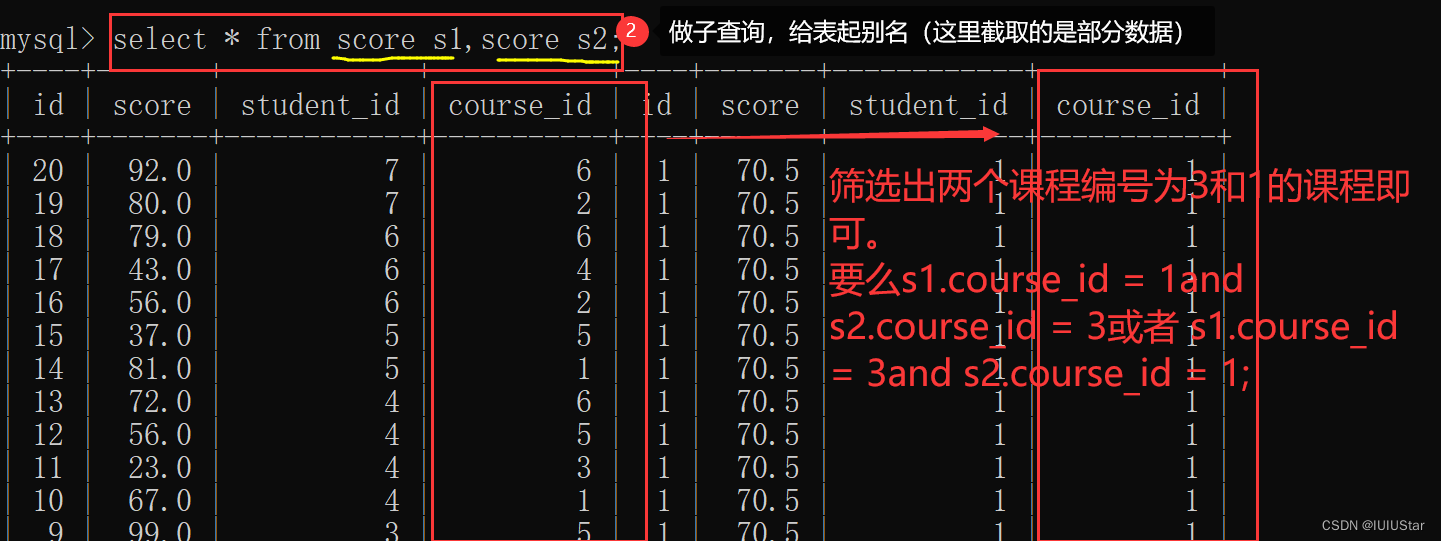
🌈4、子查询
子查询指的是嵌入在其他sql语句中的select语句,也叫作嵌套查询。简而言之,就是一条查询的条件依赖另一个的查询结果。
(1)查询“不想毕业”同学的同班同学。
之前的做法:
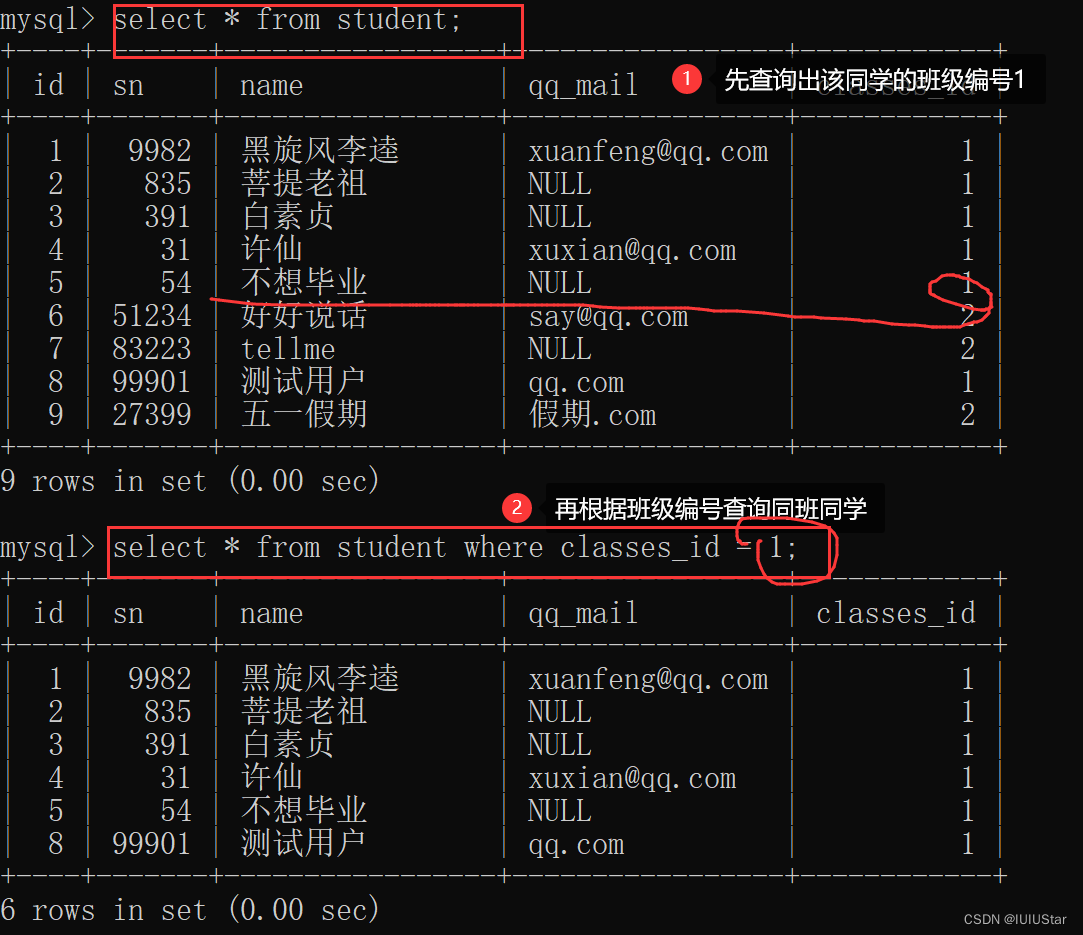
使用子查询:
 (2)使用多行子查询的例子
(2)使用多行子查询的例子

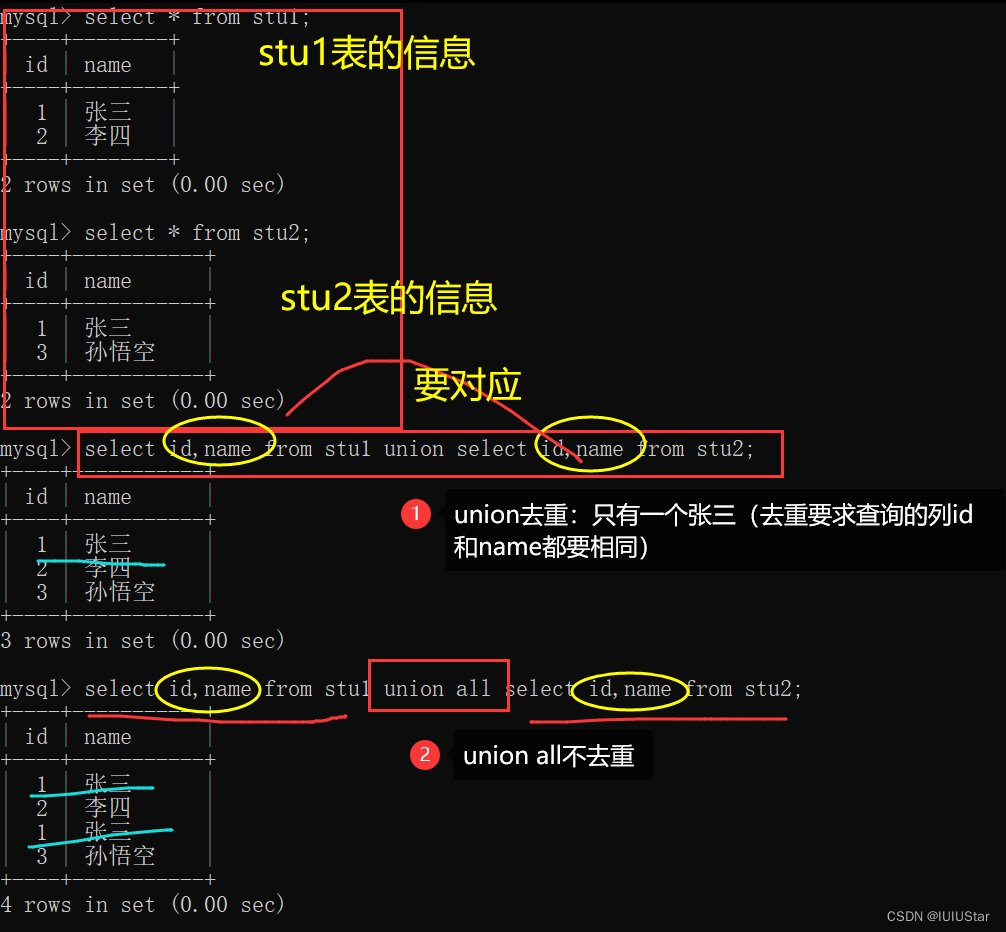
🌈5、合并查询
union和union all。两者都是用于取得两个结果集的并集,在使用的时候,前后查询的结果集中,要求字段必须保持一致。区别是 union去重,union all不去重。当使用union 时,会自动去除掉结果集中的重复集。这里的重复行指的是必须所有的行都是重复的。

(1)union将两个表中不同的数据合并到一个查询结果集中。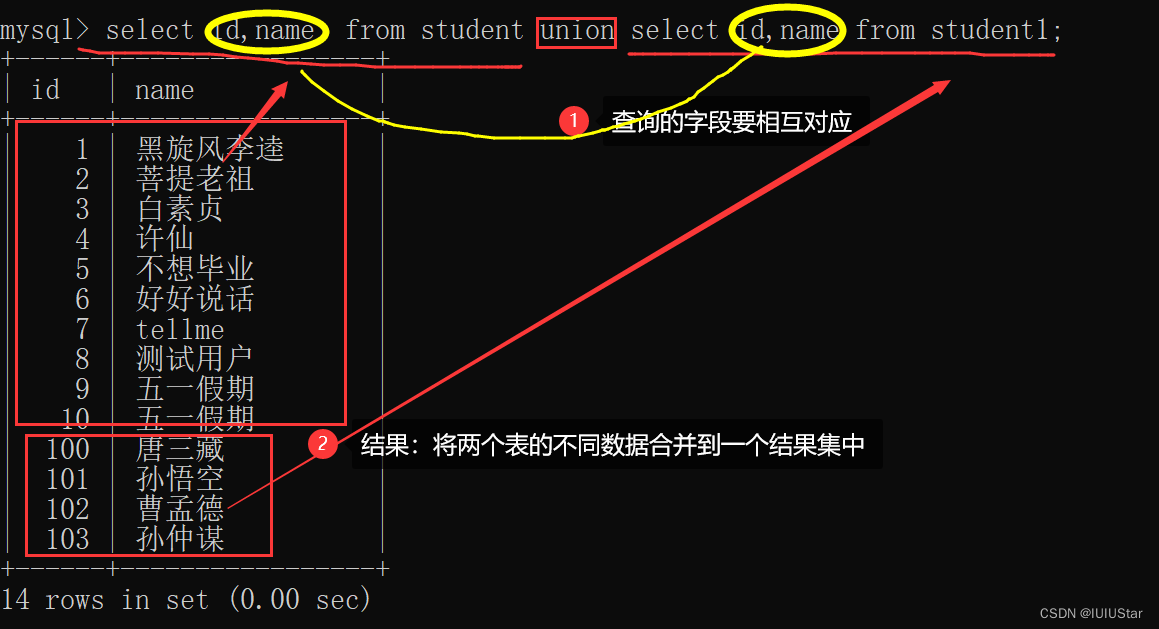
(2)union和union all的区别