一、背景
大数据情景下,需要巨量的读写数据,即良好的IO效率。传统的B树以及其变种无法满足,因为它的读写在物理上是随机的,这样IO的效率就不高。于是便有了LSM(log_structed_merge_tree) 合并日志树这个设计思想或者说存储结构。他在大数据的存储上广泛引用(HBase,Kudu,Clickhouse的MergeTree等),它的处理情景是将随机读写操作变成顺序读写操作,从而提高IO效率。
二、设计思想
LSM是通过顺序读写来提高IO 效率,所以它的存储数据结构就是要保证有序。
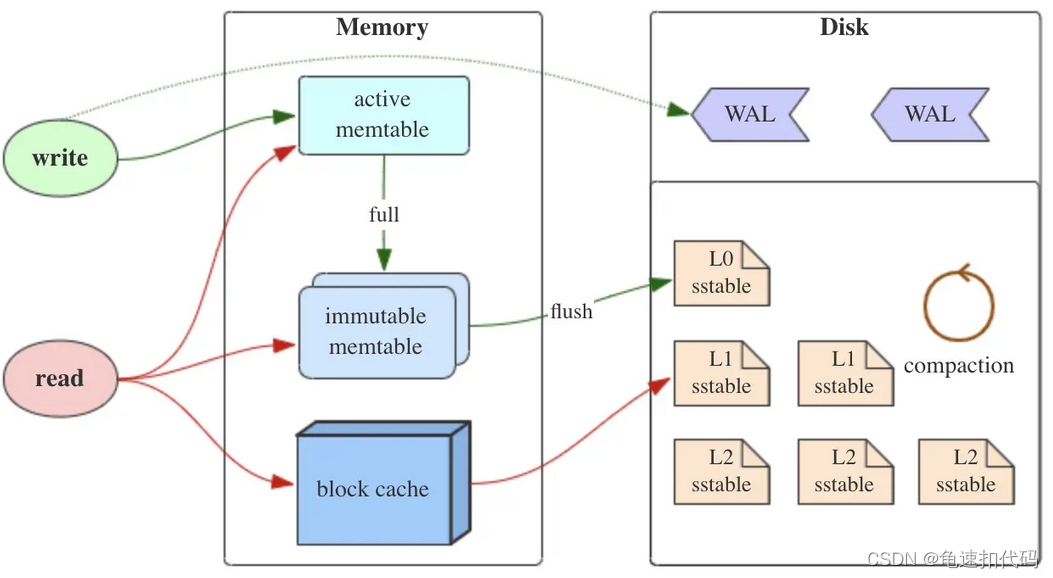
如图所示,LSM的存储是分层的(内存和磁盘),主要有4个角色
1:memTable
按照Key有序的组织数据,用于保存最新的数据。常用的数据结构有:map,红黑树,跳表。因为是在内存,为了防止断电丢失数据,所以有磁盘的备份,预写式日志WAL(write-ahead-logging)
2: immutable memtable
当memTable达到阈值后,会溢写到immutable memtable(不可改变内存表),然后再flush到磁盘中
3: SStable ( Sorted String Table ) , 有序字符表
这里因为数据量大,且可能存在冗余数据(一个key不同的值),所以为了保证读取的是正确的有效的,需要顺序读取所有的数据,从memTable开始。所以查询策略上是有做优化的,常见的有建立key的所以或者布隆过滤器。 明显读取的性能是收到影响的
4: BlockCache
缓存读取的SSTable数据,用于加快读取的速度。
这里现在 合并结构化日志树的 结构化是体现了,数据都是键值形式,那么日志是体现在哪里?
传统的数据库B树是直接在原有的数据所在处直接修改值,而LSM为了顺序写,他的数据更新是日志式的,即记录的数据是操作日志,记录的方式是append。
这样的记录方式肯定是会有数据冗余,例如插入一条数据,后续有更改,那么在不同的SStable中会有两条数据,怎么办? 这就体现在 合并上
LSM会将SStable进行合并,不同的合并策略有不同的优缺点。
合并结构化日志树的数则是体现在数据结构
在 memTable和 SSTable都是采用了树。 memTable是map,红黑树,跳表。
SSTable则是类似B树。
三、增删改查
1:增和该记录
在memTable和WAL增加记录,然后等待后续的flush和compact。最后增加和修改磁盘的数据
2:删除记录
在memTable和WAL增加记录,然后在需要删除的数据上打一个标签(tombstone),最后等待compact操作将数据从磁盘中删除。
3: 查操作
从memTable 开始查询,如果命中了则返回,没有则继续顺序查询直至查到。可见如果运气不好可能需要查询所有的数据,因此这里有不同的优化策略,给key做索引和布隆过滤器。
四、总结
LSM树是牺牲了部分的读取性能来换取写入性能。
参考:
最容易理解的LSM树--以示例讲解合并查找过程_lsm树 例子_土豆西瓜大芝麻的博客-CSDN博客
LSM Tree-Based存储引擎的compaction策略(feat. RocksDB) - 简书
LSM树详解 - 知乎