目录
SparkSQL Shuffle 分区数目
SparkSQL 数据清洗API
dropDuplicates
dropna
fillna
SparkSQL函数定义(UDF函数)
SparkSQL 使用窗口函数
SparkSQL运行流程
SparkSQL的自动优化
Catalyst优化器
SparkSQL Shuffle 分区数目
在SparkSQL中,当Job产生Shuffle的时候,默认的分区数(spark.sql.shuffle.partitions)为200;
在实际的项目中应进行合理的配置:
①在spark-defaults.conf 中设置;
②客户端提交的时候设置:--conf "spark.sql.shuffle.partitions=100"
③在创建sparksession的时候设置:
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
config("spark.sql.shuffle.partitions","100").\
getOrCreate()
在集群中,可以根据集群的cpu核心数设定(可以设置为总核心数的2/4/8...等,也受到其他因素的影响);在本地模式下分区数200会带来很大压力,一般设置为2/4/8/10个
SparkSQL 数据清洗API
dropDuplicates
功能:数据去重
语法:
# 无参数时整体去重
df.dropDuplicates().show()
# 有参数时根据列值进行去重
df.dropDuplicates(['age', 'job']).show()
dropna
功能:删除有缺失值的数据
语法:
# 无参数使用,只有有列值为null,就进行删除
df.dropna().show()
# thresh=3表示至少满足三个有效列
df.dropna(thresh=3).show()
# 在subset规定的列中,至少要有2个有效列,否则删除
df.dropna(thresh=2, subset=['name', 'age']).show()
fillna
功能:填充缺失值
语法:
# 将所有的空值按照给定的值进行填充
df.fillna("loss").show()
# 指定列进行填充
df.fillna("N/A", subset=['job']).show()
# 设定一个字典, 对所有的列 提供填充规则
df.fillna({"name": "未知姓名", "age": 1, "job": "worker"}).show()
SparkSQL函数定义(UDF函数)
目前SparkSQL只支持UDF和UDAF,而pyspark只支持UDF
①sparksession.udf.register(参数1,参数2,参数3)
参数1:UDF名称,可用于SQL风格
参数2:被注册成UDF的方法名
参数3:声明UDF的返回值类型
返回值是一个udf对象,可用于DSL风格
示例:
# UDF
def num_ride_10(num):
return num * 10
udf2 = spark.udf.register("udf1", num_ride_10, IntegerType())
# 在SQL风格中使用:
df.selectExpr("udf1(num)").show() # selectExpr方法可以接受SQL语句表达式
# 在DSL风格中使用
df.select(udf2(df['num'])).show()
②使用pyspark.sql.functions:pyspark.sql.functions.udf(参数1,参数2)
参数1:被注册成UDF的方法名
参数2:声明UDF的返回值类型
返回值:是一个UDF对象,可用于DSL风格
示例:
from pyspark.sql import functions as F
udf3 = F.udf(num_ride_10, IntegerType())
df.select(udf3(df['num'])).show()
spark在注册UDF的时候需要注意:返回值需要有合适的类型来声明:

SparkSQL 使用窗口函数

SparkSQL运行流程
SparkSQL的自动优化
为什么SparkSQL可以自动优化而RDD不可以?
因为DataFrame是二维表结构,结构固定,而RDD中可以存储多种不同类型结构的数据
Catalyst优化器
使用优化器的执行架构:

- spark通过API接受SQL语句
- 将SQL语句交给Catalyst优化器,优化器负责解析SQL,生成执行计划
- 优化器的输出是RDD的执行计划
- 最终交由集群执行
具体流程:
1、解析SQL,生成抽象语法树(AST)
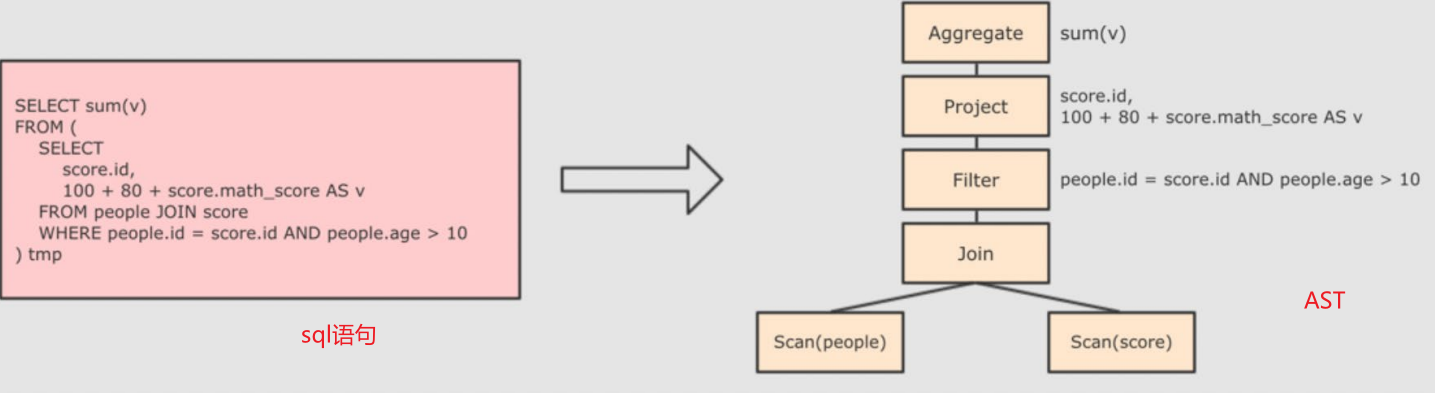
此时还未进行优化
2、在AST中添加元数据信息

元数据的含义:

3、对已经加入元数据的AST输入到优化器中开始优化
①断言下推,例如先filter在join:

这样可以减少join的数据量
②列值裁剪:在断言下推之后进行列值裁剪,将用不到的列裁剪掉,减少处理的数据量
SQL的一般执行顺序:
FROM
WHERE
GROUP BY
HAVING
SELECT
ORDER BY
LIMIT
可以看到,select执行起来是比较靠后的,因此可以通过列值裁剪,减少之前的步骤的数据量
4、经过优化生成了逻辑计划,根据逻辑计划生成物理计划,从而生成RDD来运行
在生成物理计划的时候,会根据”成本模型“对整棵树再次进行优化,选择一个更好的计划
可以通过queryExecution来查看逻辑计划,通过explain来查看物理计划
示例:
if __name__ == '__main__':
spark = SparkSession.builder.\
appName("test").\
config("spark.sql.shuffle.partitions", 100).\
getOrCreate()
sc = spark.sparkContext
rdd = sc.textFile("hdfs://10.245.150.47:8020/user/wuhaoyi/input/sql/people.txt").\
map(lambda x: x.split(",")).\
map(lambda x: (x[0], int(x[1])))
df = spark.createDataFrame(rdd, schema=['name', 'age'])
df.createOrReplaceTempView("people")
spark.sql("SELECT * FROM people WHERE age < 30").explain()
如图:

通过explain(True)可以查看更多执行计划: