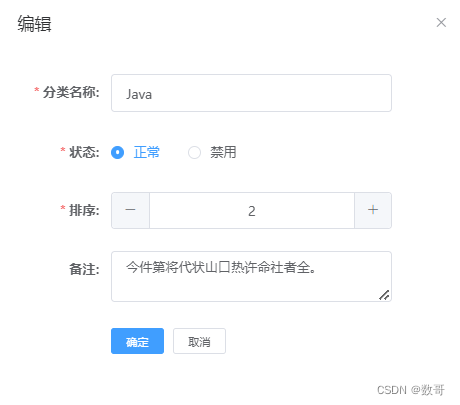
前端009_类别模块_修改功能
news2026/2/14 22:45:43

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/506789.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

PySpark基础入门(8):Spark SQL(内容补充)
目录
SparkSQL Shuffle 分区数目
SparkSQL 数据清洗API
dropDuplicates
dropna
fillna
SparkSQL函数定义(UDF函数)
SparkSQL 使用窗口函数
SparkSQL运行流程
SparkSQL的自动优化
Catalyst优化器 SparkSQL Shuffle 分区数目
在SparkSQL中&…
无魔法插件 - ChatGPT Sidebar with GPT-4
文章目录 1.介绍2.功能一览2.1 唤醒方式2.2 聊天功能2.3 快捷模板2.4 单独聊天界面2.5 ChatPDF2.6 任意位置快捷使用模板2.7 手机 APP 3.GPT-3.0 还是 GPT-3.5?4.免费 or 收费?5.安装 Sidebar 创作不易,如果本文对你有帮助,胖友记…
SpringCloud(22):Sentinel对Feign的支持
Sentinel 适配了 Feign组件。如果想使用,除了引入 spring-cloud-starter-alibaba-sentinel 的依赖外还需要 2个步骤:
配置文件打开 Sentinel 对 Feign 的支持:feign.sentinel.enabledtrue加入 spring-cloud-starter-openfeign 依赖使 Sentin…
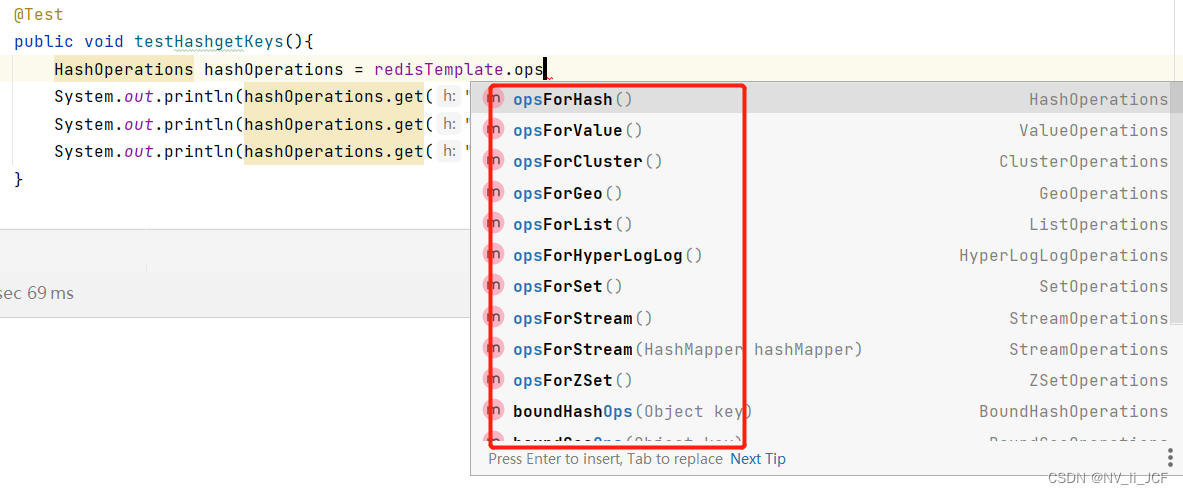
springboot 整合redis
第一步:pom.xml文件导入坐标
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><version>2.5.4</version>
</dependency
第二步:appli…

【iOS】—— NSProxy类
NSProxy 文章目录 NSProxyNSProxy简介NSProxy模拟多继承NSProxy 避免NSTimer循环引用 在学消息转发的时候看到过这个类,本来没打算细看,后来看学长博客循环引用的时候也看到了这个类,就来细看看。 NSProxy简介
NSProxy 是一个实现了 NSObjec…

在线病毒分析工具评测试用
总览
1 区分在线杀毒引擎与在线沙盒
在线杀毒引擎用的大多是国际上出名的杀毒厂商的引擎作为底层,对文件进行扫描,结论通常会反馈“无毒”或者杀毒引擎自己的代码。
在线沙盒用云端的机器跑一次程序,然后收集程序的相关信息。
两者各有与…
MongoDB 聚合操作Map-Reduce
这此之前已经对MongoDB中的一些聚合操作进行了详细的介绍,主要介绍了聚合方法和聚合管道;如果您想对聚合方法和聚合管道进行了解,可以参考:
MongoDB 数据库操作汇总https://blog.csdn.net/m1729339749/article/details/130086022…

ClickHouse为何能超越Elasticsearch?
背景
Elasticsearch是一个强大的分布式全文检索和数据分析引擎,也是日志分析系统经常使用的一种实现方案,但近年来随着ClickHouse的发展,Elasticsearch在日志分析领域的地位逐渐被取代,许多公司已经将自己的日志分析解决方案从ES…
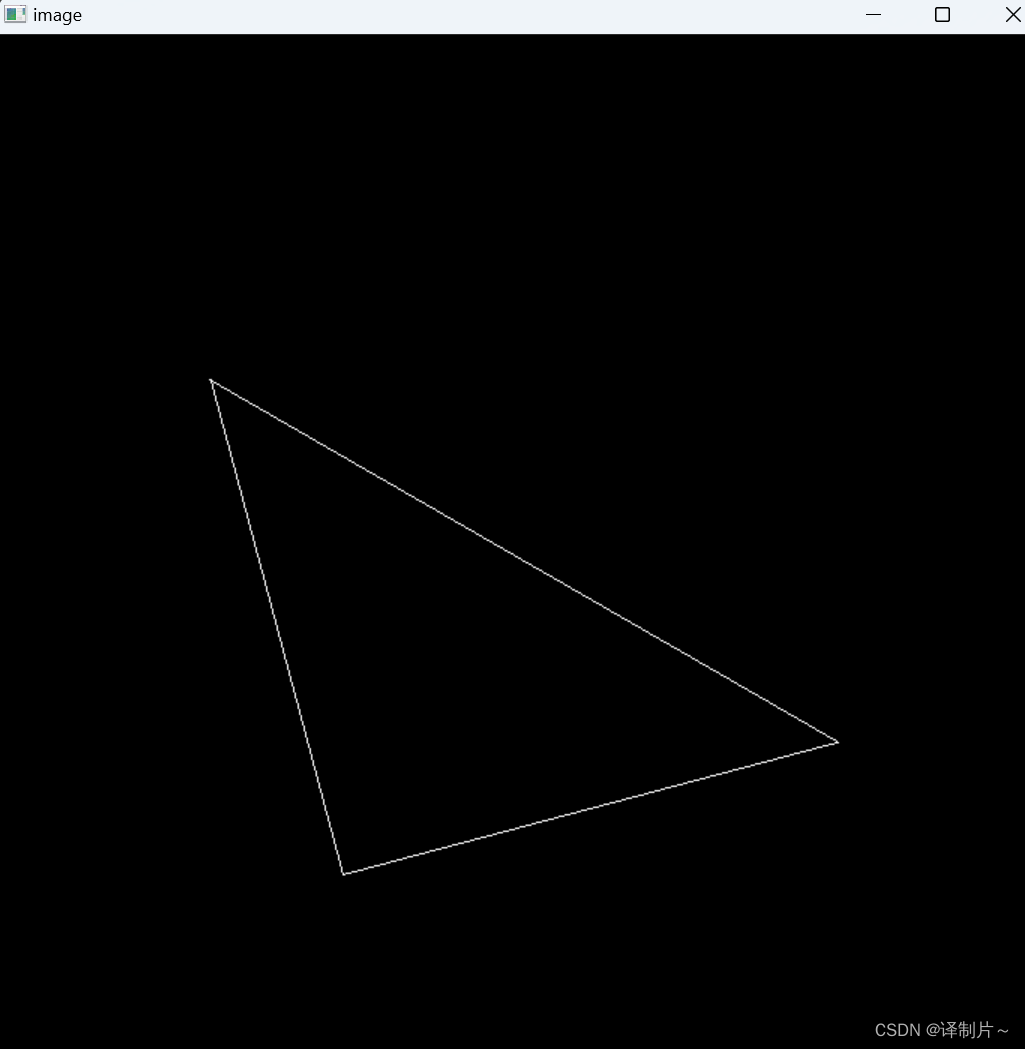
games101作业1
作业1的大致要求就是让我们实现如下两个函数,一个是返回在三维空间中绕着Z轴旋转的矩阵,另一个是返回投影矩阵。正确完成这两个函数之后,运行代码你就会在窗口中看到一个三角形,并且按a键和d键会发生旋转。 首先来实现get_model_m…

RuleApp1.4.0 文章社区客户端
简介:
可以打包成安卓,苹果,h5,小程序,全新的版本增加了私聊和群聊,动态模块等,还有自动和手动封禁机制。[滑稽][滑稽]主要模块:用户模块,文章模块,动态模块…
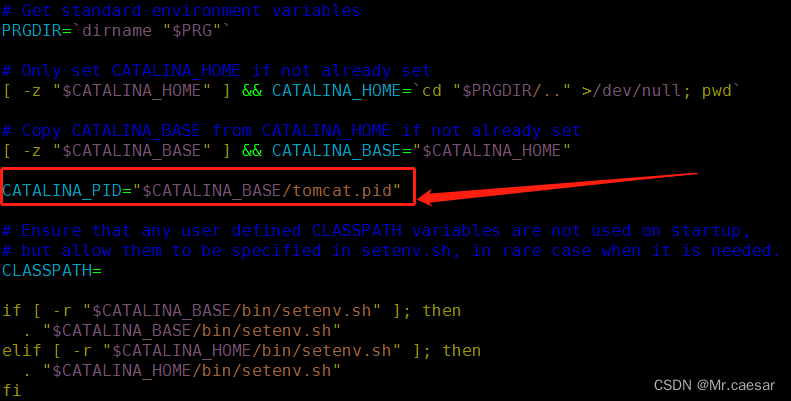
国产服务器tomcat开机自启
目录结构 前言方法一方法二方法三参考连接 前言 国产服务器配置tomcat开机自启动;目前测试两种服务器
银河麒麟(Linux localhost.localdomain 4.19.90-52.22.v2207.ky10.x86_64 #1 SMP Tue Mar 14 12:19:10 CST 2023 x86_64 x86_64 x86_64 GNU/Linux&am…
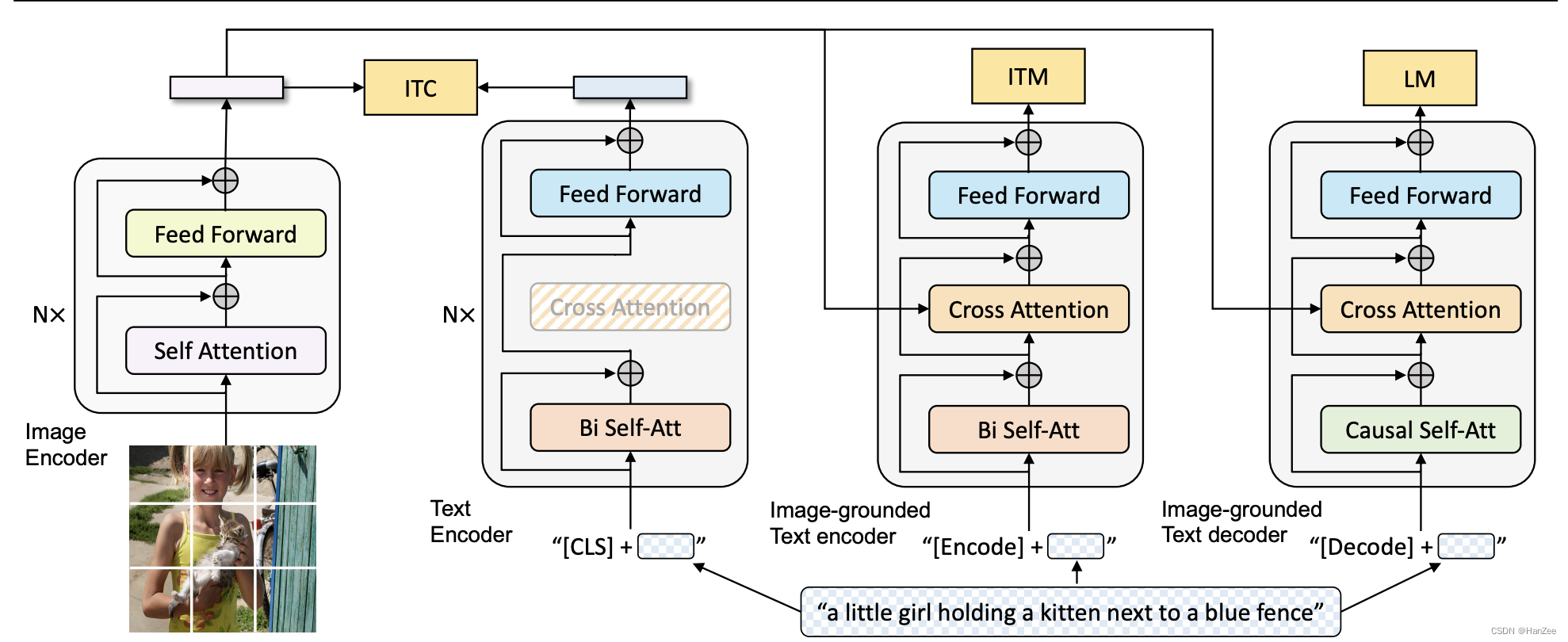
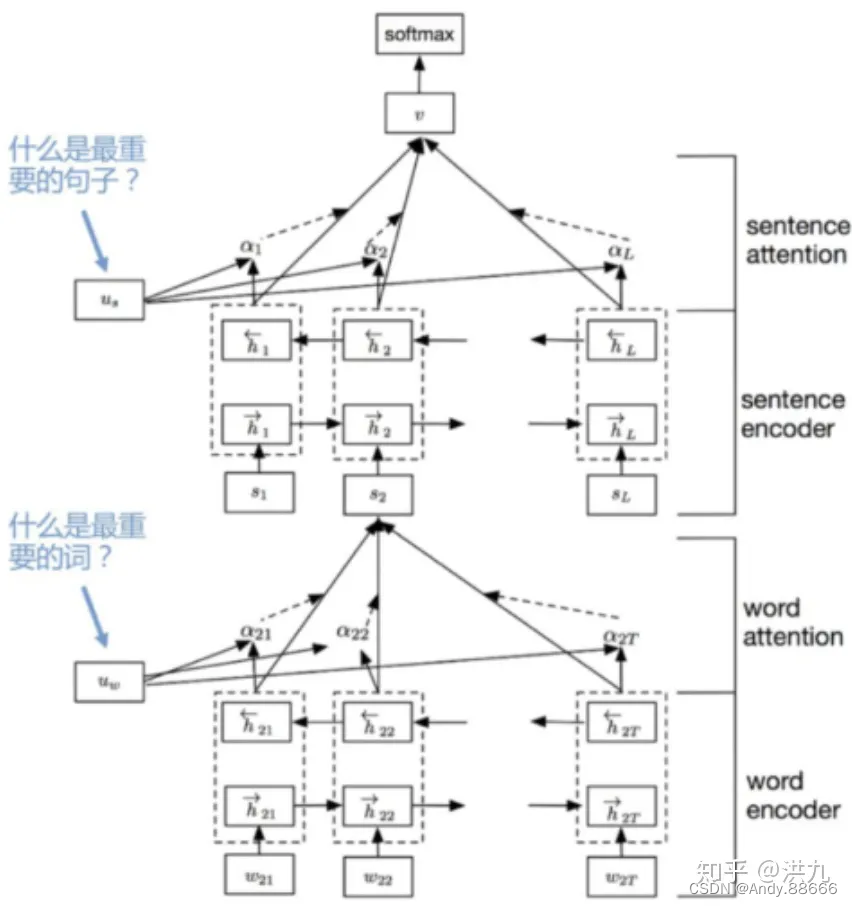
多模态速读:ViLT、ALBEF、VLMO、BLIP
ViLT : Vision-and-Language Transformer Without Convolution or Region Supervision ViLT : Vision-and-Language Transformer Without Convolution or Region SupervisionIntroductionApproach参考 ALBEF: Vision and LanguageRepresentation Learning with Momentum Distil…
如何在香港服务器上进行网站迁移?五个主要步骤
服务器迁移是将大量关键信息从一台服务器移动到另一台服务器的过程,同时确保新服务器已正确配置以承载这些新信息。对于业务涉及中国大陆、香港及亚太区地区往来的用户,您可能需要将网站迁移到香港服务器上,来更好地发展业务。香港服务…

【c语言】字符串常用函数组件化封装 | 字符串总结
创作不易,本篇文章如果帮助到了你,还请点赞 关注支持一下♡>𖥦<)!! 主页专栏有更多知识,如有疑问欢迎大家指正讨论,共同进步! 🔥c语言系列专栏:c语言之路重点知识整合 &#x…

【JavaScript】9.事件
事件
1. 注册事件(绑定事件)
给元素添加事件,称为注册事件或者绑定事件
1.1 注册事件两种方式 传统注册方式(onclick) 传统方式注册事件特点: 注册事件的唯一性同一个元素同一个事件只能设置一个处理函数…

离了大谱,公司测试岗却新来了个00后卷王,3个月薪资干到20K.....
最近聊到软件测试的行业内卷,越来越多的转行和大学生进入测试行业。想要获得更好的待遇和机会,不断提升自己的技能栈成了测试老人迫在眉睫的问题。
不论是面试哪个级别的测试工程师,面试官都会问一句“会编程吗?有没有自动化测试…
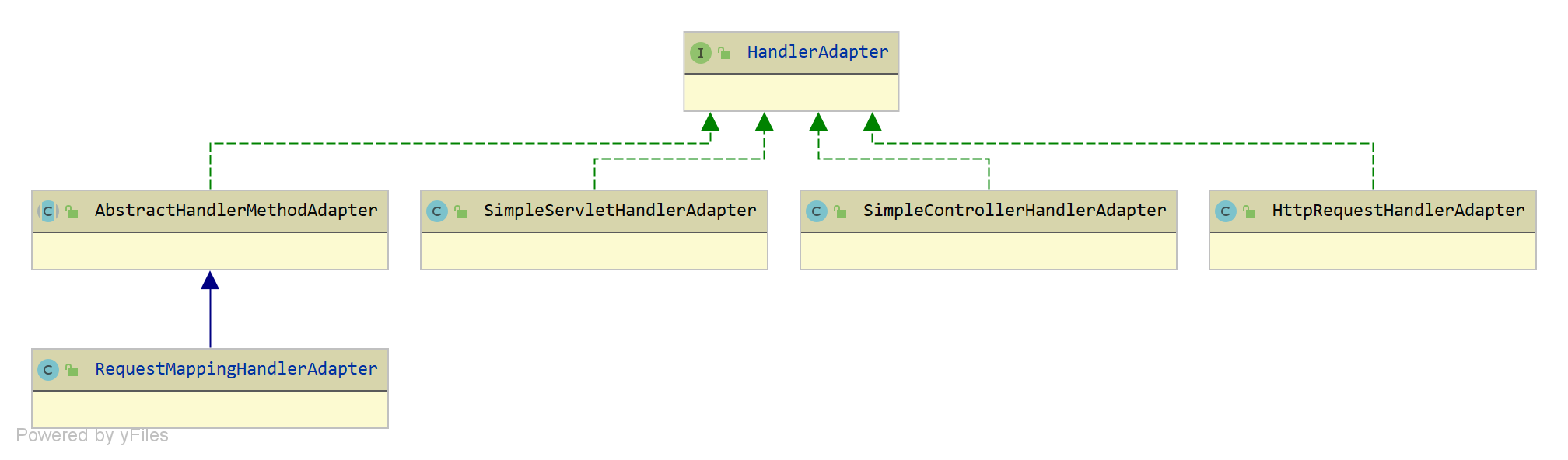
spring-web HandlerAdapter 源码分析
说明
本文基于 jdk 8, spring-framework 5.2.x 编写。author JellyfishMIX - github / blog.jellyfishmix.comLICENSE GPL-2.0
HandlerAdapter 接口
提供作为处理器适配器的能力。
supports 方法判断是否支持该 handler。
public interface HandlerAdapter {/*** 判断是否…
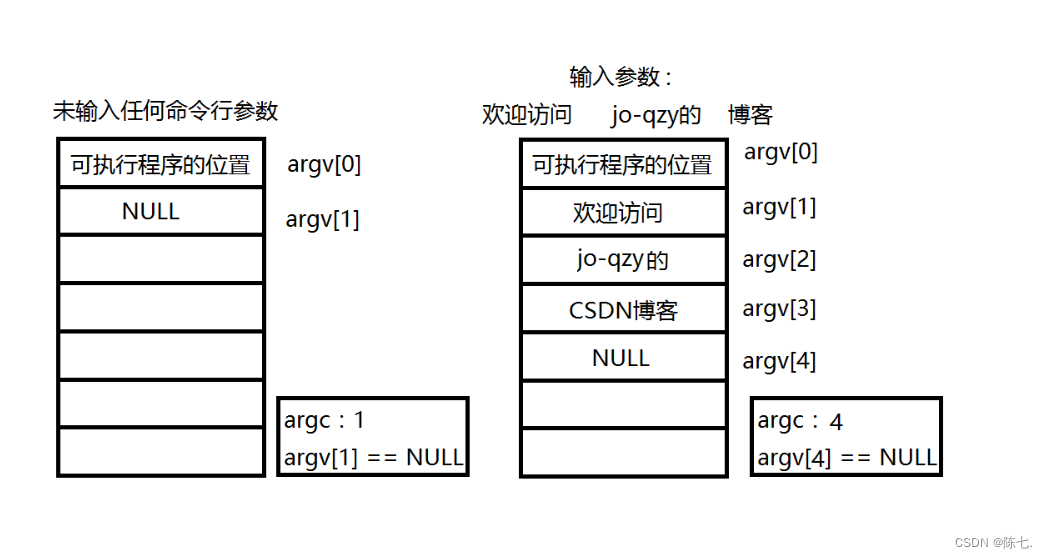
【跟着陈七一起学C语言】今天总结:初识C语言
友情链接:专栏地址 知识总结顺序参考C Primer Plus(第六版)和谭浩强老师的C程序设计(第五版)等,内容以书中为标准,同时参考其它各类书籍以及优质文章,以至减少知识点上的错误&#x…