全连接层分析
对于神经网络为什么都能产生很好的效果虽然其是一个黑盒,但是我们也可以对其中的一些数学推导有一定的了解。
数学背景
目标函数为 f = ∣ ∣ m a x ( X W , 0 ) − Y ∣ ∣ F 2 ,求 ∂ f ∂ W , ∂ f ∂ X , ∂ f ∂ Y 目标函数为f = ||max(XW,0)-Y||^{2}_{F},求\frac{\partial f}{\partial W},\frac{\partial f}{\partial X},\frac{\partial f}{\partial Y} 目标函数为f=∣∣max(XW,0)−Y∣∣F2,求∂W∂f,∂X∂f,∂Y∂f
公式证明
解: 首先我们假设替换变量 f = ∣ ∣ S − Y ∣ ∣ F 2 S = m a x ( Z , 0 ) Z = X W 根据假设变量,易得: ∂ f ∂ S = ∂ f ∂ Y = 2 ( S − Y ) ( 1 ) 要求 Z 分量的偏导: ∂ f = t r ( ( ∂ f ∂ S ) T d S ) = t r ( ( ∂ f ∂ S ) T d m a x ( Z , 0 ) ) = t r ( ( ∂ f ∂ S ) T ⊙ m a x ′ ( Z , 0 ) d Z ) 所以: ∂ f ∂ Z = m a x ′ ( Z , 0 ) T ⊙ ∂ f ∂ S = 2 ∗ m a x ′ ( Z , 0 ) ⊙ ( S − Y ) = 2 ∗ m a x ′ ( Z , 0 ) ⊙ ( m a x ( Z , 0 ) − Y ) ( 2 ) 要求 W 分量的偏导 : ∂ f = t r ( ( ∂ f ∂ Z T d Z ) = t r ( ( ∂ f ∂ Z ) T d ( X W ) ) = t r ( ( X T f Z ) d W ) 所以: ∂ f ∂ W = X T ∂ f ∂ Z = 2 ∗ X T m a x ′ ( Z , 0 ) ⊙ ( m a x ( Z , 0 ) − Y ) ( 3 ) 要求 X 分量的偏导 : ∂ f = t r ( ( ∂ f ∂ Z T d Z ) = t r ( ( ∂ f ∂ Z ) T d ( X W ) ) = t r ( ( f Z ) W T d X ) 所以: ∂ f ∂ X = W T ∂ f ∂ Z = 2 m a x ′ ( Z , 0 ) ⊙ ( m a x ( Z , 0 ) − Y ) W T \begin{align} 解:&首先我们假设替换变量 \\ &f=||S-Y||^{2}_{F} \\ &S=max(Z,0) \\ &Z=XW \\ &根据假设变量,易得: \\ \frac{\partial f}{\partial S} &=\frac{\partial f}{\partial Y}= 2(S-Y) \\\\ &(1)要求Z分量的偏导: \\ \partial f&=tr((\frac{\partial f}{\partial S})^{T}dS) \\ &=tr((\frac{\partial f}{\partial S})^{T}dmax(Z,0))\\ &=tr((\frac{\partial f}{\partial S})^{T}\odot max\prime(Z,0)dZ) \\ &所以:\\ \frac{\partial f}{\partial Z}&=max\prime(Z,0)^{T}\odot \frac{\partial f}{\partial S} \\ &=2*max\prime(Z,0)\odot(S-Y) \\ &=2*max\prime(Z,0)\odot(max(Z,0)-Y) \\ \\ &(2)要求W分量的偏导:\\ \partial f&=tr((\frac{\partial f}{\partial Z}^{T}dZ) \\ &=tr((\frac{\partial f}{\partial Z})^{T}d(XW)) \\ &=tr((X^{T}\frac{f}{Z})dW) \\ &所以:\\ \frac{\partial f}{\partial W}&=X^{T}\frac{\partial f}{\partial Z}\\ &=2*X^{T}max\prime(Z,0)\odot(max(Z,0)-Y)\\ \\ &(3)要求X分量的偏导:\\ \partial f&=tr((\frac{\partial f}{\partial Z}^{T}dZ) \\ &=tr((\frac{\partial f}{\partial Z})^{T}d(XW)) \\ &=tr((\frac{f}{Z})W^{T}dX) \\ &所以:\\ \frac{\partial f}{\partial X}&=W^{T}\frac{\partial f}{\partial Z}\\ &=2max\prime(Z,0)\odot(max(Z,0)-Y)W^{T} \end{align} 解:∂S∂f∂f∂Z∂f∂f∂W∂f∂f∂X∂f首先我们假设替换变量f=∣∣S−Y∣∣F2S=max(Z,0)Z=XW根据假设变量,易得:=∂Y∂f=2(S−Y)(1)要求Z分量的偏导:=tr((∂S∂f)TdS)=tr((∂S∂f)Tdmax(Z,0))=tr((∂S∂f)T⊙max′(Z,0)dZ)所以:=max′(Z,0)T⊙∂S∂f=2∗max′(Z,0)⊙(S−Y)=2∗max′(Z,0)⊙(max(Z,0)−Y)(2)要求W分量的偏导:=tr((∂Z∂fTdZ)=tr((∂Z∂f)Td(XW))=tr((XTZf)dW)所以:=XT∂Z∂f=2∗XTmax′(Z,0)⊙(max(Z,0)−Y)(3)要求X分量的偏导:=tr((∂Z∂fTdZ)=tr((∂Z∂f)Td(XW))=tr((Zf)WTdX)所以:=WT∂Z∂f=2max′(Z,0)⊙(max(Z,0)−Y)WT
全连接ReLU
公式推导
首先一个全连接ReLU神经网络,一个隐藏层,没有bias,用来从x预测y,使用L2 Loss。
h
=
X
W
1
h
relu
=
max
(
0
,
h
)
Y
pred
=
h
relu
W
2
f
=
∥
Y
−
Y
pred
∥
F
2
\begin{array}{l} h=X W_{1} \\ h_{\text {relu }}=\max (0, h) \\ Y_{\text {pred }}=h_{\text {relu }} W_{2} \\ f=\left\|Y-Y_{\text {pred }}\right\|_{F}^{2} \end{array}
h=XW1hrelu =max(0,h)Ypred =hrelu W2f=∥Y−Ypred ∥F2
其网络连接示意图如下所示:
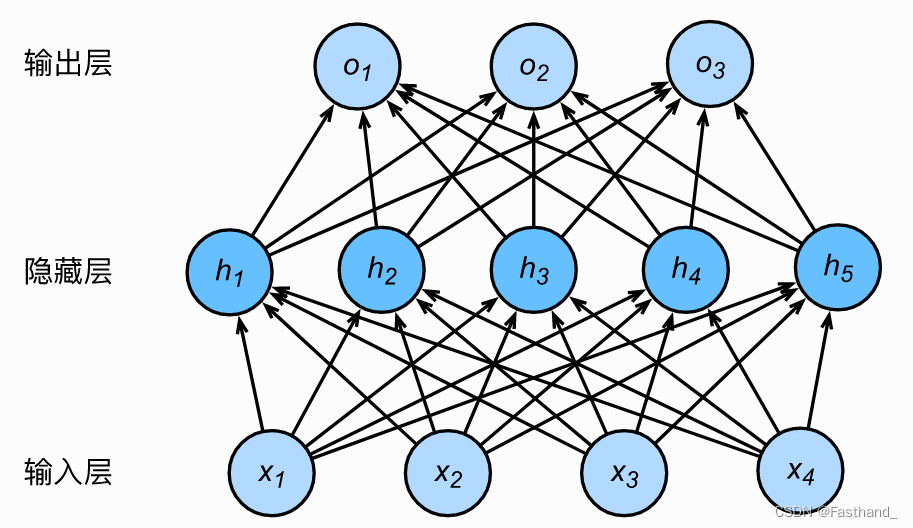
对于
W
1
W_1
W1、
W
2
W_2
W2的偏导,由上数学背景易得为:
∂
f
∂
Y
p
r
e
d
=
2
(
Y
−
Y
p
r
e
d
)
∂
f
∂
W
2
=
h
r
e
l
u
T
.
2
(
Y
−
Y
p
r
e
d
)
∂
f
∂
h
r
e
l
u
=
∂
f
∂
Y
p
r
e
(
W
2
T
)
∂
f
∂
h
=
m
a
x
′
(
0
,
h
)
∂
f
∂
h
r
e
l
u
∂
f
∂
W
1
=
X
T
∂
f
∂
h
\begin{align} \frac{\partial f}{\partial Y_{pred}}&=2(Y-Y_{pred}) \\ \frac{\partial f}{\partial W_{2}} &= h_{relu}^T.2(Y-Y_{pred}) \\ \frac{\partial f}{\partial h_{relu}}&= \frac{\partial f}{\partial Y_{pre}}(W_2^T)\\ \frac{\partial f}{\partial h}&= max\prime(0,h)\frac{\partial f}{\partial h_{relu}}\\ \frac{\partial f}{\partial W_{1}} &= X^{T}\frac{\partial f}{\partial h} \end{align}
∂Ypred∂f∂W2∂f∂hrelu∂f∂h∂f∂W1∂f=2(Y−Ypred)=hreluT.2(Y−Ypred)=∂Ypre∂f(W2T)=max′(0,h)∂hrelu∂f=XT∂h∂f
Numpy实现
import numpy as np
import torch
N,D_in,H,D_out = 64,1000,100,10
#随机数据
x = np.random.randn(N,D_in)
y = np.random.randn(N,D_out)
w1= np.random.randn(D_in,H)
w2= np.random.randn(H,D_out)
#学习率
learning_rate = 1e-6
for it in range(501):
#Forward pass
h = x.dot(w1) #N*H
h_relu = np.maximum(h,0) #N*H
Y_pred = h_relu.dot(w2) #N*D_out
#compute loss
#numpy.square()函数返回一个新数组,该数组的元素值为源数组元素的平方。 源阵列保持不变。
loss = np.square(y-Y_pred).sum()
#print(loss)
if it%50==0:
print(it,loss)
#Backward pass
#compute the gradient
grad_Y_pre = 2.0*(Y_pred - y)
grad_w2 = h_relu.T.dot(grad_Y_pre)
grad_h_relu = grad_Y_pre.dot(w2.T)
grad_h = grad_h_relu.copy()
grad_h[h<0] = 0
grad_w1 = x.T.dot(grad_h)
#update weights of w1 and w2
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
全连接层练习2
h
=
X
W
1
+
b
1
h
sigmoid
=
sigmoid
(
h
)
Y
pred
=
h
sigmoid
W
2
+
b
2
f
=
∥
Y
−
Y
pred
∥
F
2
\begin{array}{l} h=X W_{1}+b_{1} \\ h_{\text {sigmoid }}=\operatorname{sigmoid}(h) \\ Y_{\text {pred }}=h_{\text {sigmoid }} W_{2}+b_{2} \\ f=\left\|Y-Y_{\text {pred }}\right\|_{F}^{2} \end{array}
h=XW1+b1hsigmoid =sigmoid(h)Ypred =hsigmoid W2+b2f=∥Y−Ypred ∥F2
![[激活函数#sigmoid函数]]
由上公式易得:
∂
f
∂
Y
p
r
e
d
=
2
(
Y
−
Y
p
r
e
d
)
∂
f
∂
h
s
i
g
m
o
i
d
=
∂
f
∂
Y
p
r
e
d
W
2
T
∂
f
∂
h
=
∂
f
∂
h
s
i
g
m
o
i
d
s
i
g
m
o
i
d
′
(
x
)
=
∂
f
∂
h
s
i
g
m
o
i
d
s
i
g
m
o
i
d
(
x
)
(
1
−
s
i
g
m
o
i
d
(
x
)
)
∂
f
∂
W
2
=
h
s
i
g
m
o
i
d
T
∂
f
∂
Y
p
r
e
d
∂
f
∂
b
2
=
∂
f
∂
Y
p
r
e
d
∂
f
∂
W
1
=
X
T
∂
f
∂
h
s
i
g
m
o
i
d
∂
f
∂
b
1
=
∂
f
∂
h
\begin{align} \frac{\partial f}{\partial Y_{pred}} &=2(Y-Y_{pred}) \\ \frac{\partial f}{\partial h_{sigmoid}}&=\frac{\partial f}{\partial Y_{pred}}W_2^{T} \\ \frac{\partial f}{\partial h}&=\frac{\partial f}{\partial h_{sigmoid}}sigmoid\prime(x) \\ &=\frac{\partial f}{\partial h_{sigmoid}}sigmoid(x)(1-sigmoid(x)) \\ \frac{\partial f}{\partial W_2}&=h_{sigmoid}^{T}\frac{\partial f}{\partial Y_{pred}} \\ \frac{\partial f}{\partial b_{2}}&=\frac{\partial f}{\partial Y_{pred}}\\ \frac{\partial f}{\partial W_1}&=X^{T}\frac{\partial f}{\partial h_{sigmoid}}\\ \frac{\partial f}{\partial b_1}&=\frac{\partial f}{\partial h} \end{align}
∂Ypred∂f∂hsigmoid∂f∂h∂f∂W2∂f∂b2∂f∂W1∂f∂b1∂f=2(Y−Ypred)=∂Ypred∂fW2T=∂hsigmoid∂fsigmoid′(x)=∂hsigmoid∂fsigmoid(x)(1−sigmoid(x))=hsigmoidT∂Ypred∂f=∂Ypred∂f=XT∂hsigmoid∂f=∂h∂f
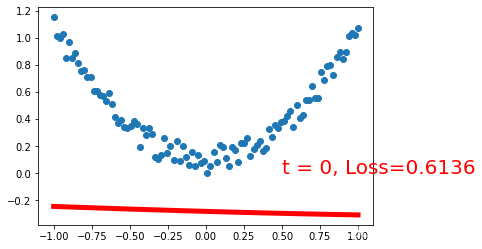
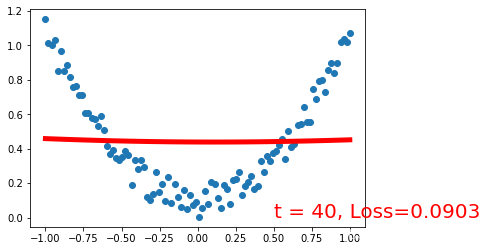
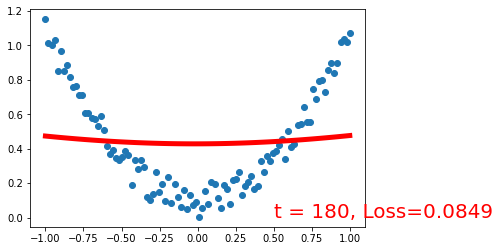
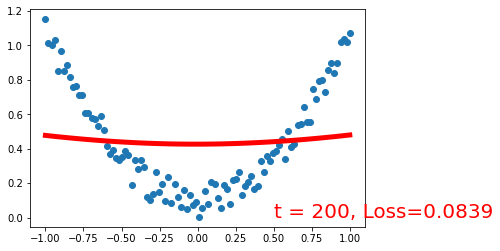
%matplotlib inline
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
torch.manual_seed(1) # reproducible
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
y = x.pow(2) + 0.2*torch.rand(x.size())
plt.scatter(x.numpy(), y.numpy())
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.linear1 = torch.nn.Linear(n_feature,n_hidden,bias=True)
self.linear2 = torch.nn.Linear(n_hidden,n_output,bias=True)
def forward(self, x):
y_pred = self.linear2(torch.sigmoid(self.linear1(x)))
return y_pred
net = Net(n_feature=1, n_hidden=20, n_output=1) # define the network
print(net) # net architecture
optimizer = torch.optim.SGD(net.parameters(), lr=0.2)
loss_func = torch.nn.MSELoss() # this is for regression mean squared loss
plt.ion() # something about plotting
for t in range(201):
prediction = net(x) # input x and predict based on x
loss = loss_func(prediction, y) # must be (1. nn output, 2. target)
optimizer.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if t % 20 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.numpy(), y.numpy())
plt.plot(x.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 't = %d, Loss=%.4f' % (t, loss.data.numpy()), fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.show()
plt.ioff()
plt.show()