许多机器人操作算法都需要 实时目标姿态估计。然而,最先进的目标姿态估计方法是针对一组特定的对象进行训练的;因此,这些方法需要 重新训练 以估计每个新对象的姿势。
本文提出了 OSSID 框架,利用 慢速零样本 姿态估计器 来 自监督快速检测算法的训练。然后可以使用这个快速检测器来过滤姿势估计器的输入,从而大大提高其推理速度。这种自监督训练在两个广泛使用的 目标姿态估计 和 检测数据集上超过了现有 零样本检测方法 的性能,无需任何人工注释。此外,由于 能够过滤掉大部分图像,因此所得到的姿势估计方法具有明显更快的推理速度。
因此,本文的 检测器自监督在线学习方法(使用来自慢速姿态估计器的伪标签进行训练)可以 实时进行准确的姿态估计,而无需人工注释。
目标实例检测 和 姿态估计 对于许多机器人操作任务至关重要。与检测 给定语义目标类别(例如人、汽车或自行车)的 所有实例 的标准计算机视觉任务不同,对于机器人操作,机器人需要 检测特定的目标实例。
当我们想将检测器和姿态估计器应用于新目标时,需要 收集新数据,并且需要在这些新目标实例上 重新训练或 微调网络。耗时耗力
为了解决这个问题,已经开发了许多 zero-shot 零样本姿势估计器。然而,大多数零样本姿态估计器只评估稀疏、整洁的场景,在杂乱环境中对此类方法的评估表明,即使添加了真实边界框或真实翻译作为输入,此类方法也无法提供合理的性能。太慢,实时性不够好。
本文探索了如何 将 零样本目标检测器 与 零样本姿态估计器 结合,以提高性能,而不会损失准确性。零样本目标检测器将姿态估计 集中在 检测到的边界框内 图像的较小区域上,而不是处理整个图像。
使用 零样本姿态估计器 使 检测器 适应新物体和看不见的环境。
零样本姿态估计的慢速方法 为 训练 快速目标检测器 提供了免费和高质量的伪真值。
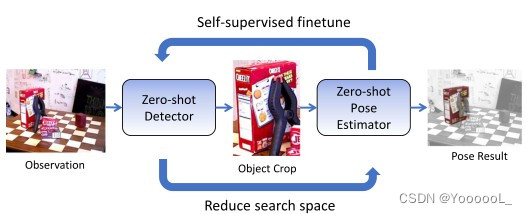
OSSID,这是一种 通过姿态估计 进行目标实例检测的 自监督学习流程。零样本姿态估计网络的结果 用于在线微调零样本检测器。然后检测结果 反过来 提供目标边界框 并 减少姿势估计的搜索空间。无需任何手动注释,检测器和姿态估计器都变得更好更快。
本文提出了 OSSID,一种 在线自监督实例检测框架,使用零样本姿态估计流程 在测试环境中生成伪真值检测和分割标签。在执行自监督在线学习之后,所得到的目标实例检测和姿态估计方法在速度和准确度上都大大优于基线。我们假设目标对象的 3D 网格模型可用;使用 3D 重建软件 [10]-[14] 可以轻松获得 3D 目标网格模型,只需几分钟的开销。
结果表明,使用零样本姿态估计器的在线自监督学习 可以帮助检测器 快速适应新物体和新环境。此外,检测器减少了 6D 姿势的搜索空间,并显着提高了姿势估计的推理速度。
• 零样本姿态估计:基于手工特征的经典方法 不执行学习,因此对不同的目标实例 本质上是零样本的。基于 PPF 的方法的推理速度比深度学习方法慢得多(通常慢一个数量级),并且不再匹配最近深度学习方法的准确性。
尽管用于 6D 姿态估计的深度学习方法已经取得了非常准确的结果,但大多数此类方法都是 针对特定目标 进行训练的,并且不会在没有重新训练的情况下泛化到看不见的对象,这可能需要数十个 GPU 天。
本文使用 自监督的在线学习 来训练 零样本检测器 来过滤 ZePHyR 的输入,从而显着提高其性能,而无需任何人工注释。
• 零样本目标检测:在零样本或少样本目标检测上的 大部分工作都集中在 类级别的语义目标检测上。然而,机器人代理通常 需要在杂乱的环境中 定位特定的目标实例。传统方法使用手工制作的特征和模板匹配来解决这个问题。本文的自监督学习流程 可以显着提高检测性能。可以通过 减少目标模板数量 来实现更快的推理速度,同时保持同等或更好的检测精度。
• 目标检测的域自适应:我们专注于 目标实例检测(而不是类级别检测),并且我们从零样本姿态估计中获得伪标签。
Mitash 等人[44] 提出了一种 使用物理模拟和多视图姿态估计 进行目标检测的自监督在线学习系统。然而,这种方法 依赖于大型合成数据集,并且它们的系统 不能泛化 到合成训练集中不存在的目标。假设环境是干净的桌面或预定义的架子,从而限制了它们的应用范围。
本文的方法 能够适应 看不见的物体,随着测试环境的更多场景被处理,改进了初始零样本检测器。OSSID 已被证明可以 在杂乱的环境中工作,并且能够适应最初训练的目标和 环境之外的目标和环境。
本文的目标是 在不需要任何人工注释 或 长时间训练 的情况下 训练快速准确的姿势估计器。
OSSID:在线自监督实例检测,使用 慢速零样本姿态估计器(ZePHyR [9])通过 在线自监督 训练 快速目标实例检测器。然后可以使用这个目标实例检测器来 过滤我们的姿态估计器的输入空间,在不降低整个系统精度的情况下提高推理速度。
• 零样本姿态估计:将非学习姿势假设生成 与 深度学习的拟合函数 相结合,可以对训练时 从未见过的目标 产生高度准确的姿势估计。这种方法虽然能够在不需要重新训练的情况下推广到任意目标,但需要很长的推理时间才能在整个图像空间中生成潜在的假设。
对于目标姿态估计,本文采用 ZePHyR [9],一种 零样本姿态评分算法,无需额外标记或重新训练 即可推广到看不见的物体。在 [9] 之后,我们使用 PPF点对特征 [15] 和 SIFT 特征匹配 [45] 来生成 6D 对象姿态假设。
本文 使用 目标检测器 来 过滤 姿势搜索空间,去除输入中不太可能的区域。使用 学习的目标实例检测器 裁剪输入场景,仅使用裁剪区域内的点生成假设。不会在此边界框之外生成假设 减少了 ZePHyR 将评估的假设数量,从而减少了推理时间。不会为检测器边界框之外的区域生成特征,减少了运行时间。显着提高推理速度。
• 零样本检测:本文希望获得一个可以在新目标上 快速工作的姿态估计系统,这要求用于过滤假设的检测系统也必须快速训练。
用于 目标实例检测的 零样本方法(例如 DTOID [33])专门设计用于 将目标模板与对场景的观察 进行比较以找到目标对象。对于 DTOID 检测新目标,它只需要目标对象的模板图像。这些模板图像可以通过 渲染目标网格模型的图像 来生成。
如果不适应看不见的测试域,网络对分布外测试示例的 泛化能力很差。
本文提出了一种用于目标实例检测的在线自监督微调方法。具体来说,我们在目标环境的先前帧上 评估零样本姿态估计器。然后,我们 将这些姿势估计用作自监督的伪标签。给定这些伪标签,我们可以微调目标实例检测器,提高其在目标环境中的性能。然后,这种自监督检测器的集成将通过 过滤姿势估计器的假设来提高整个系统的速度。
• 在线自监督训练:OSSID,一种自监督学习框架,用于在看不见的测试环境中 在线调整 目标检测器以适应新目标,如图 1 所示。
6D 姿态估计器可以预测 刚性目标的 完整状态;因此,零样本姿态估计器可以为训练目标检测器提供免费监督。由于姿势估计器 仅用于训练,因此即使是慢速姿势估计方法也可以使用,因为速度在训练时不太相关。一旦自监督微调完成,目标检测器就会为姿态估计器 提供一个目标区域,从而提高姿态估计器的速度和准确性。
本文过滤掉分数小于 20 的姿势假设;我们将得分至少为 20 的姿势假设视为训练目标检测器的伪真值。请注意,我们只考虑给定图像中得分最高的姿势假设,而 忽略了 从场景中同一目标的 多个潜在实例进行训练的可能性。
通过将目标模型投影到图像帧中,可以轻松地将 6D 姿势结果转换为 检测边界框 和 分割掩码。因此,姿势估计为训练检测网络(边界框或分割掩码)提供了完全监督,无需任何人工注释。
图3:目标检测结果用于过滤姿势估计器的输入,从而提高其推理速度。零样本姿态估计器生成的 高分pose被用作伪真值来 自监督检测网络,这有助于检测器适应并获得更好的性能,而无需任何手动标签。在这个过程中,零样本姿态估计器的权重没有改变。
实验:本文假设 目标网格模型是可用的,但我们不需要任何手动注释或合成数据生成来进行自监督学习。
本文的目标是 设计一个 无需大量训练数据集 即可 快速训练 的检测和姿态估计系统。因此,我们分别选择 DTOID [33] 和 ZePHyR [9] 作为目标检测和姿态估计的基线方法。
对于本文的 网络在线学习方法,减少模板数量 对检测网络的性能影响不大,但大大提高了推理速度。当模板数量减少时,原始 DTOID 网络在分割平均 IOU 指标上的性能下降很大。
如果检测分数低于定义的阈值,则将 使用完整图像 I 进行姿态估计。这种置信度过滤 将拒绝这种低置信度检测,而是 在整个观察中 运行姿态估计器。这导致平均推理速度较慢,但性能更好,
使用伪真值和真正的 真值之间仍然存在差距。然而,标记如此高质量的真值 需要大量的人力。相比之下,我们的自监督学习流程 展示了一种无需手动标记 即可改进检测的方法。
目标特定,非零样本的方法需要大规模的手动数据注释或合成数据生成来处理新目标,数据生成和训练时间长,而我们的方法可以快速在线适应新目标。此外,我们的方法可以 以自监督的方式 直接在真实数据上进行训练,而不需要手动注释或合成数据集生成。
本文设计了一个 transductive 转导学习流程 [54],其中检测器进行自监督训练,然后在同一组测试图像上进行测试(没有任何注释)。在 离线训练阶段,零样本姿态估计器首先在所有测试图像上运行,然后零样本检测器对姿态估计结果进行自监督训练。
尽管此设置可能 无法用于实时姿态估计,但它可用于从 固定数据集 中估计目标的姿态。此外,它提供了我们方法的上限性能,允许我们的方法 从过去和未来的帧中学习(而不是只从过去的帧中学习)。
零样本姿态估计的显着加速是由于 将姿态搜索空间 从完整观察图像 缩小到 仅检测器得分最高的边界框内的区域。
随着网络接收到的场景图像越多,检测的准确率越高。结果表明,通过自监督,实例检测器 使用新的观察结果 逐渐适应 新的目标和环境,而不需要注释。这开辟了将这种方法应用于感知系统需要适应新环境的机器人操作任务的未来方向。
Conslusion:本文提出了一种新方法OSSID,它使用 慢速零样本姿态估计器 来训练 快速检测算法,无需任何注释。以这种自监督方式训练的 检测器 显示出对新目标和新环境的 适应能力,并且 在杂乱环境中 超过了类似的 零样本方法的准确性。
该检测器可用于过滤 零样本姿势估计器的 搜索空间。这大大减少了姿势估计系统的推理时间,同时保持了良好的精度。
本文的方法显示了 在线自监督学习的好处,从而产生了一个可以在 6 分钟内训练的 高性能实时姿态估计系统(对于 LM-O 数据集)。