在之前的文章中,我们回顾了 ClickHouse 中可用的 SQL JOIN 类型。提醒一下:ClickHouse 附带完整的 SQL 连接支持。
在本文中,我们将探索 ClickHouse 中联接执行的内部结构,以便您可以优化应用程序使用的查询的联接。在这里,您将看到 ClickHouse 如何将这些经典的连接算法集成到其查询管道中,以便尽可能快地执行连接类型。
▌查询管道
ClickHouse 的设计速度很快。ClickHouse 中的查询以高度并行的方式处理,占用当前服务器上可用的所有必要资源,并且在许多情况下,利用硬件达到其理论极限。服务器拥有的 CPU 内核和主内存越多,并行执行查询的性能提升就越大。
查询管道确定每个查询执行阶段的并行级别。
下图显示了 ClickHouse 查询管道如何在具有四个 CPU 内核的服务器上处理查询:

查询的表数据动态分布在四个独立的并行流阶段,这些阶段将数据按块流式传输到 ClickHouse。
由于服务器有四个 CPU 核心,查询管道中的大部分查询处理阶段都由四个线程并行执行。使用的线程数量取决于max_threads设置,默认设置为 ClickHouse 在其运行的机器上看到的 CPU 核心数。
对于所有查询(包括连接),查询管道确保以高度并行和可扩展的方式处理表数据。
▌Join算法的内部实现
为了确保资源的最大利用率,ClickHouse开发了六种不同的连接算法。这些算法决定了连接查询的规划和执行方式。ClickHouse可以被配置为在运行时自适应地选择最佳的连接算法,并动态地改变使用的算法(取决于资源的可用性和使用情况)。但是,ClickHouse也允许用户自己指定所需的连接算法。
本文将详细描述并比较基于内存哈希表的三种ClickHouse连接算法:
- 哈希连接
- 并行哈希连接
- Grace哈希连接
在本文中,我们将探讨哈希连接算法的速度最快且最通用。并行哈希连接算法可以在右表很大的情况下更快,但需要更多的内存。哈希连接和并行哈希连接都是内存限制的。而Grace哈希连接是一种非内存限制的版本,它会将数据临时溢出到磁盘上。Grace哈希连接不需要对数据进行排序,因此克服了其他连接算法(如(部分)合并连接算法)的性能挑战,这些算法将数据溢出到磁盘上(我们将在第二部分中介绍这一点)。
在后续的文章中,我们将看看剩下的三个连接算法:
- 完全排序合并连接
- 部分合并连接
- 直接连接
▌测试数据和资源
对于所有示例查询,我们将使用前一篇文章中介绍的规范化IMDB数据集中的两个表:
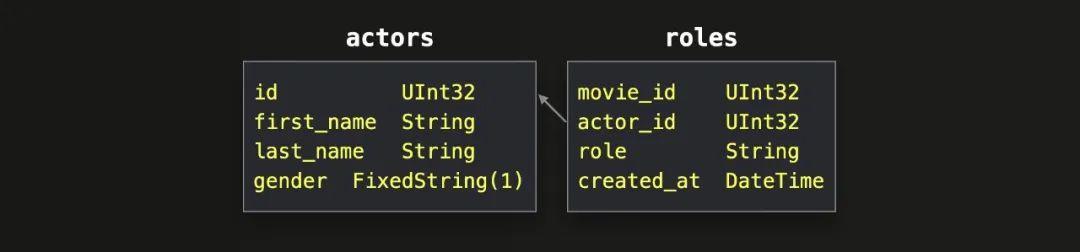
为了拥有可观的数据进行测试,我们在新数据库 imdb_large 中 生成了这些表的大型版本。此查询列出示例表中的行数和未压缩数据量:
SELECT
table,
formatReadableQuantity(sum(rows)) AS rows,
formatReadableSize(sum(data_uncompressed_bytes)) AS data_uncompressed
FROM system.parts
WHERE (database = 'imdb_large') AND active
GROUP BY table
ORDER BY table ASC;
┌─table──┬─rows───────────┬─data_uncompressed─┐
│ actors │ 1.00 million │ 21.81 MiB │
│ roles │ 100.00 million │ 2.63 GiB │
└────────┴────────────────┴───────────────────┘
为了保持可读性和简洁性,在所有的可视化中,我们人为地将ClickHouse查询管道中使用的并行级别限制为max_threads = 2。
然而,在所有的示例查询运行中,我们使用默认的max_threads设置。如上所述,默认情况下,max_threads设置为ClickHouse在运行的机器上看到的CPU核心数。这些示例使用ClickHouse Cloud服务,其中单个节点具有30个CPU核心:
SELECT getSetting('max_threads');
┌─getSetting('max_threads')─┐
│ 30 │
└───────────────────────────┘
在本节中,我们将开始探索ClickHouse连接算法。我们从最通用的哈希连接算法开始。
▌Hash Join哈希连接
1、描述
一个内存中的哈希表可以每秒处理2.5亿个完全随机的请求(如果它适合CPU缓存,则可以处理10亿个以上)。
这种非常快速的查找能力使内存中的哈希表成为ClickHouse中实现连接的自然通用选择,特别是在无法或不可行利用表排序的情况下。哈希连接算法是ClickHouse中可用的连接实现中最通用的。
我们下面展示了集成到ClickHouse查询管道中的哈希连接算法:
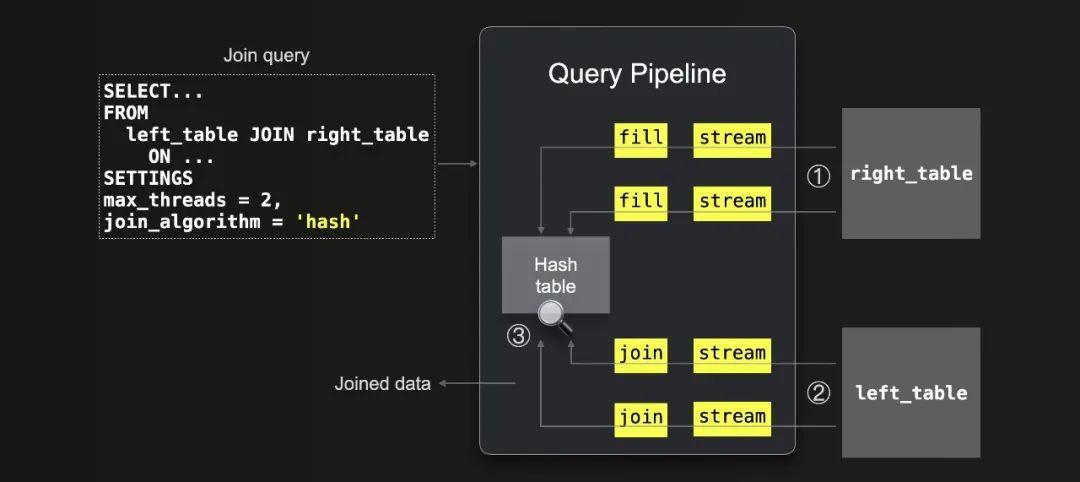
可以看到:
① 右侧表格的所有数据被流式传输(通过2个线程并行处理,因为max_threads = 2)到内存中,然后ClickHouse使用这些数据填充内存中的哈希表。
② 数据从左侧表格流式传输(通过2个线程并行处理,因为max_threads = 2),并且通过在哈希表中查找进行了③ 连接。
请注意,因为ClickHouse会针对右侧表格并在RAM中创建一个哈希表,所以将较小的表格放在JOIN的右侧更节省内存。我们将在下面演示这一点。此外,请注意,哈希表是ClickHouse中的一个关键数据结构。基于每个特定的查询,尤其是基于连接键列类型和连接严格性,ClickHouse会自动选择30多种变体之一。
2、支持的连接类型
支持所有连接类型和严格性设置。此外,目前仅哈希连接支持在ON子句中使用OR组合多个连接键。对于想深入了解的读者,源代码包含了如何通过哈希连接算法实现这些类型和设置的非常详细的描述。
3、示例
我们通过两个查询运行演示哈希连接算法。右边的表更小:
SELECT *
FROM roles AS r
JOIN actors AS a ON r.actor_id = a.id
FORMAT `Null`
SETTINGS join_algorithm = 'hash';
0 rows in set. Elapsed: 0.817 sec. Processed 101.00 million rows, 3.67 GB (123.57 million rows/s., 4.49 GB/s.)
较大的表位于右侧:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'hash';
0 rows in set. Elapsed: 5.063 sec. Processed 101.00 million rows, 3.67 GB (19.95 million rows/s., 724.03 MB/s.)
我们可以查询query_log系统表,以便检查最后两个查询运行的运行时统计信息:
SELECT
query,
formatReadableTimeDelta(query_duration_ms / 1000) AS query_duration,
formatReadableSize(memory_usage) AS memory_usage,
formatReadableQuantity(read_rows) AS read_rows,
formatReadableSize(read_bytes) AS read_data
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND hasAll(tables, ['imdb_large.actors', 'imdb_large.roles'])
ORDER BY initial_query_start_time DESC
LIMIT 2
FORMAT Vertical;
Row 1:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'hash'
query_duration: 5 seconds
memory_usage: 8.95 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
Row 2:
──────
query: SELECT *
FROM roles AS r
JOIN actors AS a ON r.actor_id = a.id
FORMAT `Null`
SETTINGS join_algorithm = 'hash'
query_duration: 0 seconds
memory_usage: 716.44 MiB
read_rows: 101.00 million
read_data: 3.41 GiB
正如预期的那样,右侧较小的演员表的连接查询比右侧较大的角色表的连接查询使用的内存少得多。
请注意,指示的峰值内存使用量为 8.95 GiB 和 716.44 MiB,比两个查询运行所用的右侧表的未压缩大小 2.63 GiB 和 21.81 MiB 要大得多。原因是哈希表大小最初是基于连接键列的类型和特定内部哈希表缓冲区大小的倍数选择并动态增加的。memory_usage 指标计算了为哈希表保留的整体内存,尽管它可能没有完全填满。
对于两个查询的执行,ClickHouse 读取相同数量的总行数(和数据):100 百万行来自角色表 + 1 百万行来自演员表。但是右侧是角色表的连接查询比较右侧是演员表的连接查询慢五倍。这是因为默认的哈希连接不是线程安全的,无法将右表的行插入到哈希表中。因此,哈希表的填充阶段在单个线程中运行。我们可以通过内省实际的查询流水线来进行双重检查。
4、查询流水线
我们可以使用ClickHouse命令行客户端(快速安装说明在这里)对哈希连接查询进行内省。我们使用EXPLAIN语句来打印以DOT图描述的查询流水线,并使用Graphviz dot将图形呈现为PDF格式:
./clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors a
JOIN roles r ON a.id = r.actor_id
SETTINGS max_threads = 2, join_algorithm = 'hash';" | dot -Tpdf > pipeline.pdf
我们已经注释了流程管道,使用了与上面的抽象图相同的编号,并稍微简化了主要阶段的名称,并添加了两个连接的表以对齐两个图表:
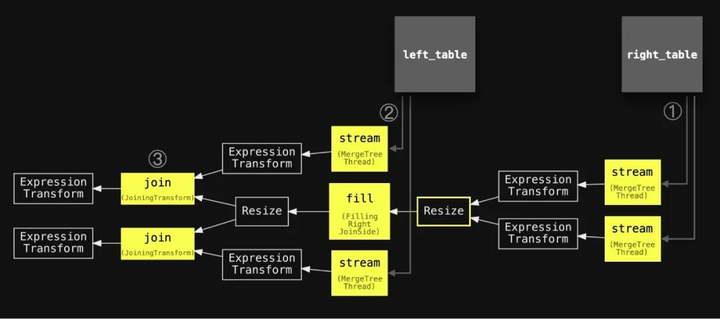
我们可以看到查询流水线 ① 开始于两个并行的流式处理阶段(因为 max_threads 设置为 2),用于从右侧表中流式处理数据,然后是一个单一的填充阶段,用于填充哈希表。另外,还使用了两个并行的流式处理阶段 ② 和两个并行的连接阶段 ③,用于从左侧表中流式处理和连接数据。
如上所述,默认哈希连接算法不是线程安全的,无法将右侧表的行插入哈希表中。因此,在流水线中使用了一个调整大小的阶段,将从右侧表中流式处理数据的两个线程缩减为单线程的填充阶段。这可能会成为查询运行时间的瓶颈。如果右侧表很大,如上面的两个查询运行,其中右侧表为 roles 的查询比另一个查询慢了五倍。
然而,自 ClickHouse 22.7版本起,可以通过使用并行哈希算法显著加快从右侧表中构建哈希表的速度,以处理大型表。
▌Parallel Hash Join
1、描述
并行哈希连接算法是哈希连接的一种变体,它分割输入数据并发构建多个哈希表,以提高连接速度,代价是更高的内存开销。我们在下面描述这个算法:
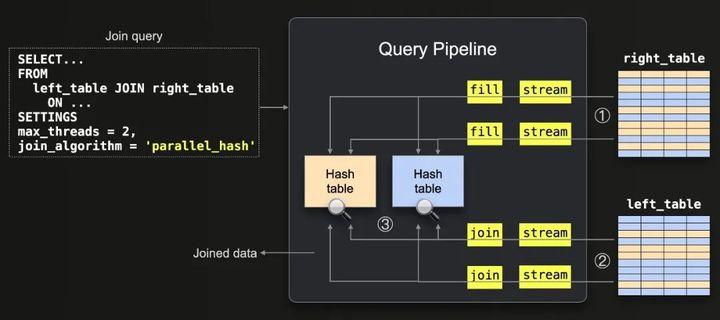
上图显示了以下内容:
① 所有来自右表的数据都被流式传输(由于max_threads = 2而在2个线程中并行),并以块的形式流式传输。每个流式块的行都通过对每个行的连接键应用哈希函数来分成2个存储桶(max_threads = 2)。在并行中,每个存储桶使用单个线程填充一个内存哈希表。请注意,用于将行拆分为存储桶的哈希函数与内部使用的哈希表中使用的哈希函数不同。
② 数据从左表流式传输(由于max_threads = 2而在2个线程中并行),并且将步骤①中的相同存储桶哈希函数应用于每行的连接键,以确定相应的哈希表,然后通过查找相应的哈希表来 ③加入。
请注意,max_threads设置确定并发哈希表的数量。我们稍后将通过检查具体的查询管道来演示它。
2、支持的连接类型
支持INNER和LEFT连接类型和除ASOF之外的所有严格性设置。
3、示例
我们将比较相同查询的哈希和并行哈希算法的运行时间和峰值内存消耗。右侧有一个较大表的哈希连接:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'hash';
0 rows in set. Elapsed: 5.385 sec. Processed 101.00 million rows, 3.67 GB (18.76 million rows/s., 680.77 MB/s.)
在右侧的较大表上使用并行哈希连接:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'parallel_hash';
0 rows in set. Elapsed: 2.639 sec. Processed 101.00 million rows, 3.67 GB (38.28 million rows/s., 1.39 GB/s.)
我们检查最后两次查询运行时的统计信息:
SELECT
query,
formatReadableTimeDelta(query_duration_ms / 1000) AS query_duration,
formatReadableSize(memory_usage) AS memory_usage,
formatReadableQuantity(read_rows) AS read_rows,
formatReadableSize(read_bytes) AS read_data
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND hasAll(tables, ['imdb_large.actors', 'imdb_large.roles'])
ORDER BY initial_query_start_time DESC
LIMIT 2
FORMAT Vertical;
Row 1:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'parallel_hash'
query_duration: 2 seconds
memory_usage: 18.29 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
Row 2:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'hash'
query_duration: 5 seconds
memory_usage: 8.86 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
并行哈希连接比标准哈希连接大约快100%,但峰值内存消耗超过了两倍,尽管两个查询都读取了相同数量的行和数据,右侧表的大小也相同。
造成更高内存消耗的原因是该查询在一个具有30个CPU核心的节点上运行,因此max_threads设置为30。这意味着,如下所示,使用了30个并发哈希表。
正如之前提到的,每个哈希表的大小最初根据连接键列的类型和某个内部哈希表缓冲区大小的倍数选择并动态增加。哈希表很可能没有完全填充,但是memory_usage指标计算的是为哈希表保留的总内存。
4、查询管道
我们提到max_threads设置确定了并发哈希表的数量。我们可以通过内省具体的查询管道来验证这一点。首先,我们内省了max_threads设置为2的并行哈希连接查询的查询管道:
./clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors a
JOIN roles r ON a.id = r.actor_id
SETTINGS max_threads = 2, join_algorithm = 'parallel_hash';" | dot -Tpdf > pipeline.pdf
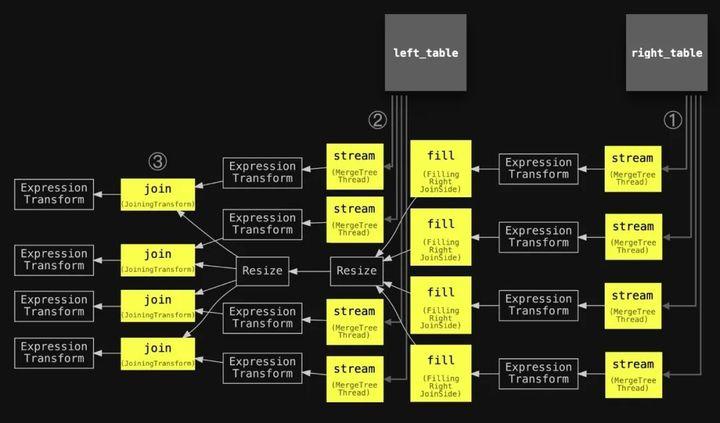
像往常一样,我们在管道中注释了与上面抽象图中使用的相同的数字,稍微简化了主要阶段的名称,并添加了两个连接的表,以便对齐这两个图。

我们可以看到,有四个并发的填充阶段用于并行地填充四个哈希表,每个哈希表都是使用右侧表的数据填充的。此外,有四个并发的连接阶段用于连接(通过哈希表查找)左侧表的数据。
请注意,查询管道中使用了调整大小阶段,以在所有填充阶段和所有连接阶段之间定义明确的连接:所有连接阶段应等待所有填充阶段完成。
接下来,我们检查 max_threads 设置为四的并行哈希连接查询的查询管道:
./clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors a
JOIN roles r ON a.id = r.actor_id
SETTINGS max_threads = 4, join_algorithm = 'parallel_hash';" | dot -Tpdf > pipeline.pdf
▌Grace Hash Join
1、描述
上面介绍的哈希联接算法和并行哈希联接算法都快速而且内存受限。如果右侧表格不能适应主内存,ClickHouse将引发OOM异常。在这种情况下,ClickHouse用户可以牺牲性能并使用(部分)合并算法(在下一篇文章中描述),将表格数据(部分)排序到外部存储中,然后再合并。幸运的是,ClickHouse 22.12引入了另一种称为“grace hash”的联接算法,它不受内存限制但基于哈希表,因此不需要对数据进行排序。这克服了(部分)合并算法的一些性能挑战。该算法利用两阶段方法来联接数据。我们的实现略有不同,以适应我们的查询管道。下面的图显示了第一阶段:
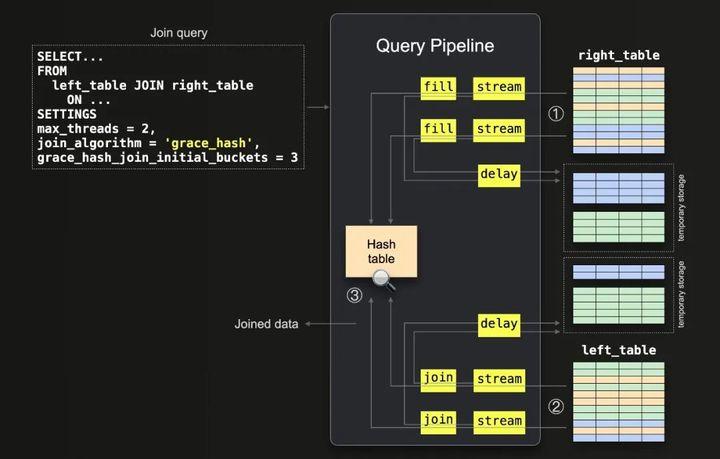
① 右表的所有数据以块为单位被流式传输到内存中(由于max_threads = 2,因此由两个线程并行传输)。从每个流式传输的块中提取的行通过将哈希函数应用于每行的连接键而被分成三个桶(因为grace_hash_join_initial_buckets = 3)。在内存中填充了一个哈希表,其中包含第一个(橙色)桶中的行。来自右侧表的其他两个桶(绿色和蓝色)的连接被延迟,通过将它们保存到临时存储器中。请注意,如果内存中的哈希表增长超过了内存限制(由max_bytes_in_join设置),ClickHouse会动态增加桶的数量并重新计算每行的分配桶。不属于当前桶的任何行都将被冲洗并重新分配。
此外,请注意,ClickHouse始终将grace_hash_join_initial_buckets的设置值向最接近的2的幂舍入。
因此,将3舍入为4,使用4个初始桶。出于可读性的考虑,我们在图中使用了3个桶,但与使用4个桶没有实质性的区别。
② 数据从左表以2个线程的方式并行流式传输(max_threads = 2),并且应用了与步骤①相同的哈希桶函数来确定相应的桶。与第一个桶对应的行被连接(因为相应的哈希表在内存中)。将其余的桶的连接通过将它们保存到临时存储器中而被延迟。
步骤①和②的关键在于哈希桶函数将值一致地分配到相同的桶中,从而有效地对数据进行分区并通过分解解决问题。在第二阶段,ClickHouse在磁盘上处理其余的桶。其余的桶按顺序处理。
以下两个图表展示了这一点。第一个图表展示了如何首先处理蓝色桶。第二个图表展示了最后一个绿色桶的处理。


① ClickHouse从右表数据中为每个桶建立哈希表。同样,如果ClickHouse内存不足,它会动态增加桶的数量。
② 从右表的相应桶建立哈希表后,ClickHouse从相应的左表桶中流式传输数据,然后③ 完成此对的连接。
请注意,在此阶段期间,可能存在一些属于当前存储桶以外桶的行,因为它们在桶的数量动态增加之前被保存到临时存储中。
在这种情况下,ClickHouse会将它们保存到新的实际桶中并进一步处理它们。
这个过程重复进行,直到处理所有剩余的桶为止。
2、支持的连接类型
支持INNER和LEFT连接类型以及除ASOF之外的所有严格性设置。
3、示例
以下我们将使用哈希连接和Grace Hash连接算法运行相同的连接查询,并比较运行时间和峰值内存使用情况。右侧有较大表的哈希连接:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 3;
0 rows in set. Elapsed: 13.117 sec. Processed 101.00 million rows, 3.67 GB (7.70 million rows/s., 279.48 MB/s.)
使用Grace Hash Join进行右表大的连接查询:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 3;
0 rows in set. Elapsed: 13.117 sec. Processed 101.00 million rows, 3.67 GB (7.70 million rows/s., 279.48 MB/s.)
我们获取了最后两个查询运行的运行时统计信息:
SELECT
query,
formatReadableTimeDelta(query_duration_ms / 1000) AS query_duration,
formatReadableSize(memory_usage) AS memory_usage,
formatReadableQuantity(read_rows) AS read_rows,
formatReadableSize(read_bytes) AS read_data
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND hasAll(tables, ['imdb_large.actors', 'imdb_large.roles'])
ORDER BY initial_query_start_time DESC
LIMIT 2
FORMAT Vertical;
Row 1:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 3
query_duration: 13 seconds
memory_usage: 3.72 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
Row 2:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'hash'
query_duration: 5 seconds
memory_usage: 8.96 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
正如预期的那样,哈希连接更快。然而,优美哈希连接只使用了一半的峰值主内存。
通过增加 grace_hash_join_initial_buckets 设置的值,可以进一步降低优美哈希连接的主内存消耗。我们通过将 grace_hash_join_initial_buckets 设置的值改为 8 并重新运行查询来演示这一点:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 8;
0 rows in set. Elapsed: 16.366 sec. Processed 101.00 million rows, 3.67 GB (6.17 million rows/s., 224.00 MB/s.)
让我们检查一下最后两个查询运行的运行时统计信息:
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 8;
0 rows in set. Elapsed: 16.366 sec. Processed 101.00 million rows, 3.67 GB (6.17 million rows/s., 224.00 MB/s.)
Let’s check runtime statistics for the last two query runs:
SELECT
query,
formatReadableTimeDelta(query_duration_ms / 1000) AS query_duration,
formatReadableSize(memory_usage) AS memory_usage,
formatReadableQuantity(read_rows) AS read_rows,
formatReadableSize(read_bytes) AS read_data
FROM clusterAllReplicas(default, system.query_log)
WHERE (type = 'QueryFinish') AND hasAll(tables, ['imdb_large.actors', 'imdb_large.roles'])
ORDER BY initial_query_start_time DESC
LIMIT 2
FORMAT Vertical;
Row 1:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 8
query_duration: 16 seconds
memory_usage: 2.10 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
Row 2:
──────
query: SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 3
query_duration: 13 seconds
memory_usage: 3.72 GiB
read_rows: 101.00 million
read_data: 3.41 GiB
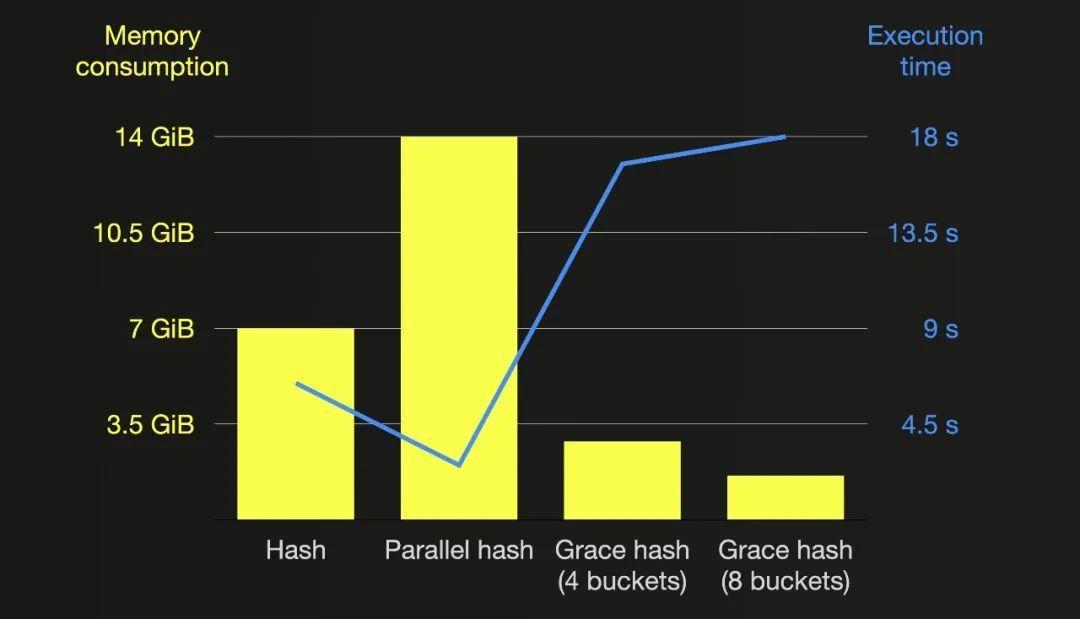
以上运行结果表明,初始桶数为8的grace hash join消耗的主内存大约比初始桶数为3的grace hash join少70%。通过增加桶的数量,可以相对线性地减少内存消耗,但会牺牲执行时间。
请注意,如前所述并在下面演示,ClickHouse总是将设置的“grace_hash_join_initial_buckets”值四舍五入到最接近的2的幂次方。因此,将“grace_hash_join_initial_buckets”设置为3的查询运行实际上使用了4个初始桶。
4、查询管道
我们对一个具有max_threads设置为2和grace_hash_join_initial_buckets设置为3的grace hash join查询管道进行了内部检查:
./clickhouse client --host ekyyw56ard.us-west-2.aws.clickhouse.cloud --secure --port 9440 --password <PASSWORD> --database=imdb_large --query "
EXPLAIN pipeline graph=1, compact=0
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT `Null`
SETTINGS max_threads = 2, join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 3';" | dot -Tpdf > pipeline.pdf
添加了圆圈编号和稍微简化了主要阶段的名称,还添加了两个连接的表,以与下面的抽象图对齐:
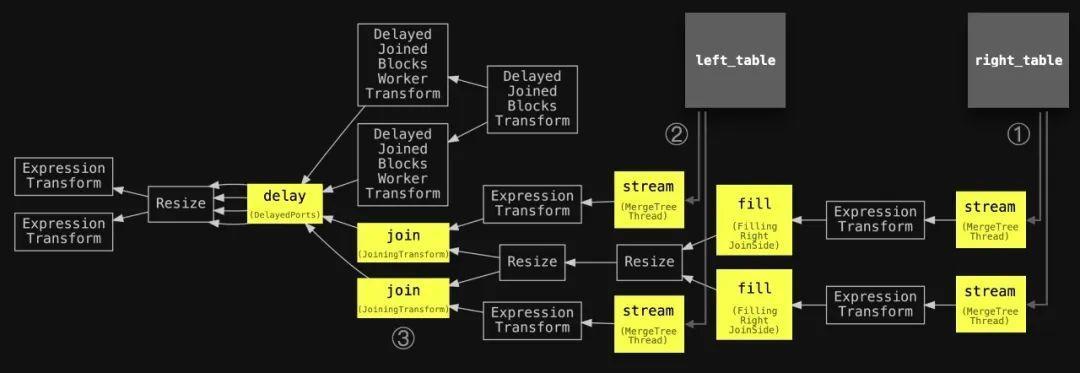
我们可以看到,在步骤①中使用了两个并行流程阶段(max_threads=2),将右表的数据流式传输到内存中。我们还看到使用了两个并行填充阶段来填充内存中的哈希表。在步骤②中,使用了两个并行流程阶段和两个并行连接阶段来流式传输和连接左侧表的数据。延迟阶段表示一些连接阶段被延迟了。
但是,我们无法在查询流水线中看到桶的数量,因为桶的创建是动态的,并且取决于内存压力,ClickHouse会根据需要动态增加数量。所有的桶都在延迟…转换阶段中处理。为了检查已创建和已处理的桶的数量,我们需要通过要求ClickHouse在执行期间向ClickHouse命令行客户端发送跟踪级别的日志来内省实际执行grace hash join查询。
我们使用max_threads设置为2和grace_hash_join_initial_buckets值为3执行grace hash join查询(注意send_logs_level='trace’设置):
./clickhouse client --host ea3kq2u4fm.eu-west-1.aws.clickhouse.cloud --secure --password <PASSWORD> --database=imdb_large --send_logs_level='trace' --query "
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT Null
SETTINGS max_threads = 2, join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 3;"
...
... GraceHashJoin: Initialize 4 buckets
... GraceHashJoin: Joining file bucket 0
...
... imdb_large.actors ...: Reading approx. 1000000 rows with 2 streams
...
... imdb_large.roles ...: Reading approx. 100000000 rows with 2 streams
...
... GraceHashJoin: Joining file bucket 1
... GraceHashJoin: Loaded bucket 1 with 250000(/25000823) rows
...
... GraceHashJoin: Joining file bucket 2
... GraceHashJoin: Loaded bucket 2 with 250000(/24996460) rows
...
... GraceHashJoin: Joining file bucket 3
... GraceHashJoin: Loaded bucket 3 with 250000(/25000742) rows
...
... GraceHashJoin: Finished loading all 4 buckets
...
我们现在可以看到,创建了四个(而不是三个)初始存储桶。
因为,如前所述,ClickHouse总是将设置为grace_hash_join_initial_buckets的值四舍五入为最接近的2的幂次方。
我们还可以看到,每个表都使用了两个并行流阶段来读取表的行。两个表中的第一个对应存储桶(上述跟踪日志消息中的bucket 0)会立即连接。
其它3个桶被写入磁盘,稍后按顺序加载以进行连接。我们可以看到,来自两个表的100万和1亿行被均匀分割 - 每个存储桶分别有25万行和大约2500万行。
为了进行比较,我们使用最大线程数设置为4和grace_hash_join_initial_buckets设置为8来执行grace hash join查询(注意send_logs_level ='trace’设置):
./clickhouse client --host ea3kq2u4fm.eu-west-1.aws.clickhouse.cloud --secure --password <PASSWORD> --database=imdb_large --send_logs_level='trace' --query "
SELECT *
FROM actors AS a
JOIN roles AS r ON a.id = r.actor_id
FORMAT Null
SETTINGS max_threads = 4, join_algorithm = 'grace_hash', grace_hash_join_initial_buckets = 8;"
...
... GraceHashJoin: Initialize 8 buckets
... GraceHashJoin: Joining file bucket 0
...
... imdb_large.actors ...: Reading approx. 1000000 rows with 4 streams
...
... imdb_large.roles ...: Reading approx. 100000000 rows with 4 streams
...
... GraceHashJoin: Joining file bucket 1
... GraceHashJoin: Loaded bucket 1 with 125000(/12502068) rows
...
... GraceHashJoin: Joining file bucket 2
... GraceHashJoin: Loaded bucket 2 with 125000(/12498406) rows
...
... GraceHashJoin: Joining file bucket 3
... GraceHashJoin: Loaded bucket 3 with 125000(/12502699) rows
...
... GraceHashJoin: Joining file bucket 4
... GraceHashJoin: Loaded bucket 4 with 125000(/12498074) rows
...
... GraceHashJoin: Joining file bucket 5
... GraceHashJoin: Loaded bucket 5 with 125000(/12498755) rows
...
... GraceHashJoin: Joining file bucket 6
... GraceHashJoin: Loaded bucket 6 with 125000(/12498054) rows
...
... GraceHashJoin: Joining file bucket 7
... GraceHashJoin: Loaded bucket 7 with 125000(/12498043) rows
...
... GraceHashJoin: Finished loading all 8 buckets
...
我们可以看到创建了八个初始桶,并且每个表使用了 4 个并行流阶段来读取表中的行。
▌总结
本文详细介绍并比较了 ClickHouse 中基于内存哈希表的三种连接算法。哈希连接算法快速,是支持所有连接类型和严格性设置的最通用算法,但是创建内存哈希表是单线程的,如果右侧表非常大,可能会成为瓶颈。并行哈希连接算法通过同时构建多个哈希表,可以更快地处理具有大右侧表的查询,但需要更多的内存。
Grace 哈希连接算法是一种非内存绑定版本,将输入数据分成多个 bucket,其中一些 bucket 在在处理之前会被暂存在磁盘上,然后在内存中按顺序处理。
以下图表总结了本文中所有连接查询运行的内存消耗和执行时间(将 max_threads 设置为 20,右侧表更大):
作者:Tom Schreiber
更多技术干货请关注公号“云原生数据库”