目录
- 前言
- 算法题(LeetCode刷题349两个数组的交集)—(保姆级别讲解)
- 分析题目:
- 什么是哈希表?
- 什么是冲突?
- 常见的三种哈希结构
- 选择正确的哈希结构
- 算法思想(画图展示):
- 算法思想(使用数组实现哈希表):
- 算法思想(使用unordered_set实现哈希表):
- 结束语
前言
本文章一部分内容参考于《代码随想录》----如有侵权请联系作者删除即可,撰写本文章主要目的在于记录自己学习体会并分享给大家,全篇并不仅仅是复制粘贴,更多的是加入了自己的思考,希望读完此篇文章能真正帮助到您!!!
算法题(LeetCode刷题349两个数组的交集)—(保姆级别讲解)
力扣题目链接
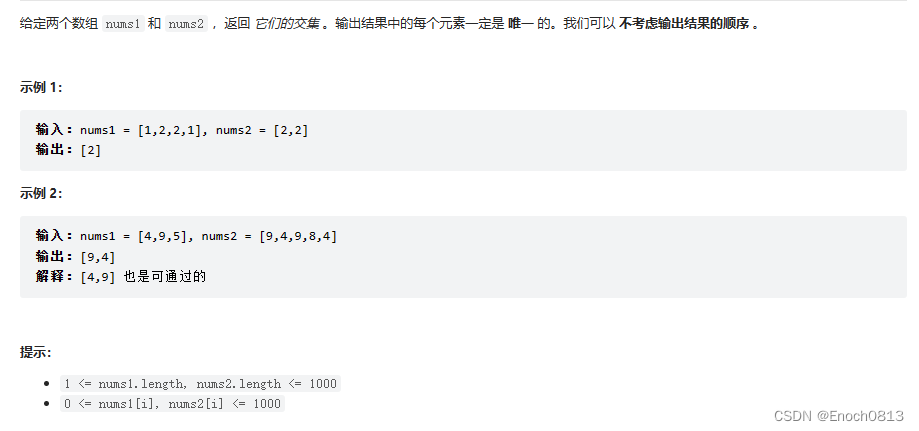
分析题目:
什么是哈希表?
在线性表和树表的查找中,记录在表中的位置与记录的关键字之间不存在确定关系,因此,在这些表中查找记录时需要进行一系列的关键字比较。这类查找方法建立在”比较“的基础上,查找的效率取决于比较的次数。
那么怎么来解决这个问题,提高检索效率呢?
这里我们就需要使用到散列函数,它是一个把查找表中的关键字映射成该关键字对应的地址的函数,记为Hash(key) = Addr(这里的地址可以为数组下标、索引或者是内存地址等)
所以我们这里会使用到一种全新的数据结构叫做散列表也叫做哈希表,它能根据关键字而直接访问数据结构,也就是说,哈希表建立了关键字和存储地址之间的一种直接映射关系。
什么是冲突?
散列函数可能会把两个或两个以上的不同关键字映射到同一地址,称这种情况为冲突,这些发生冲突的不同关键字称为同义词。一方面要设计好的散列函数来尽可能的减少这样的冲突,另一方面,由于这样的冲突总是不可避免的,所以还要设计好处理冲突的方法。
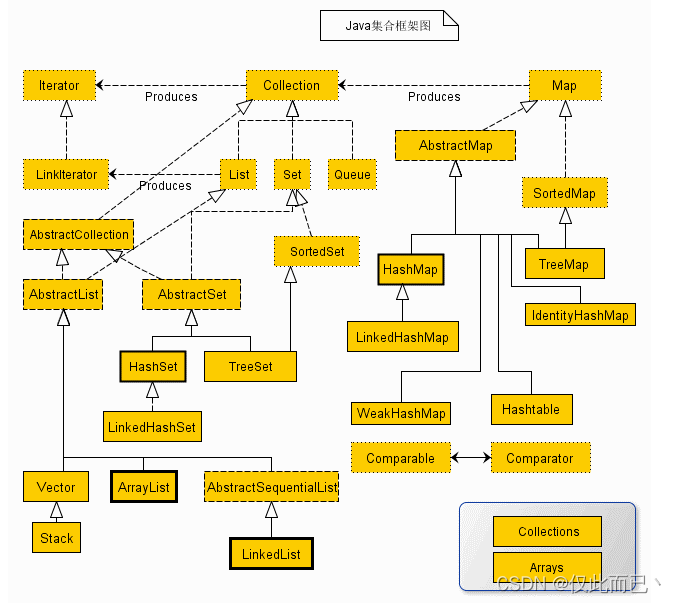
常见的三种哈希结构
当我们想使用哈希法来解决问题的时候,我们一般会选择如下三种数据结构。
- 数组
- set (集合)
- map(映射)
这里数组就没啥可说的了,我们来看一下set。
在C++中,set 和 map 分别提供以下三种数据结构,其底层实现以及优劣如下表所示:
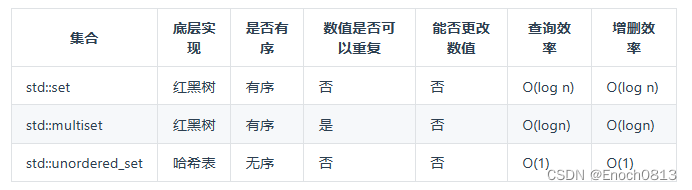
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
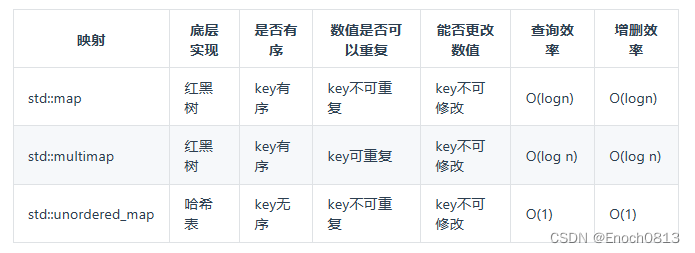
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)。
选择正确的哈希结构
当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset。
那么再来看一下map ,在map 是一个key value 的数据结构,map中,对key是有限制,对value没有限制的,因为key的存储方式使用红黑树实现的。
由于在本题目中要求输出结果中的每一个元素一定是唯一的,所以也就说输出的结果是去重的,同时不考虑输出结果的顺序,所以我们直接选择unordered_set这个数据结构。
同时因为在本题中力扣官方增加了两个条件

由上图可知,对数组大小和数组元素的大小做出了限制,正是因为有这两个限制,我们还可以使用数组来实现哈希表,即在本文章中我们会有两个版本实现。
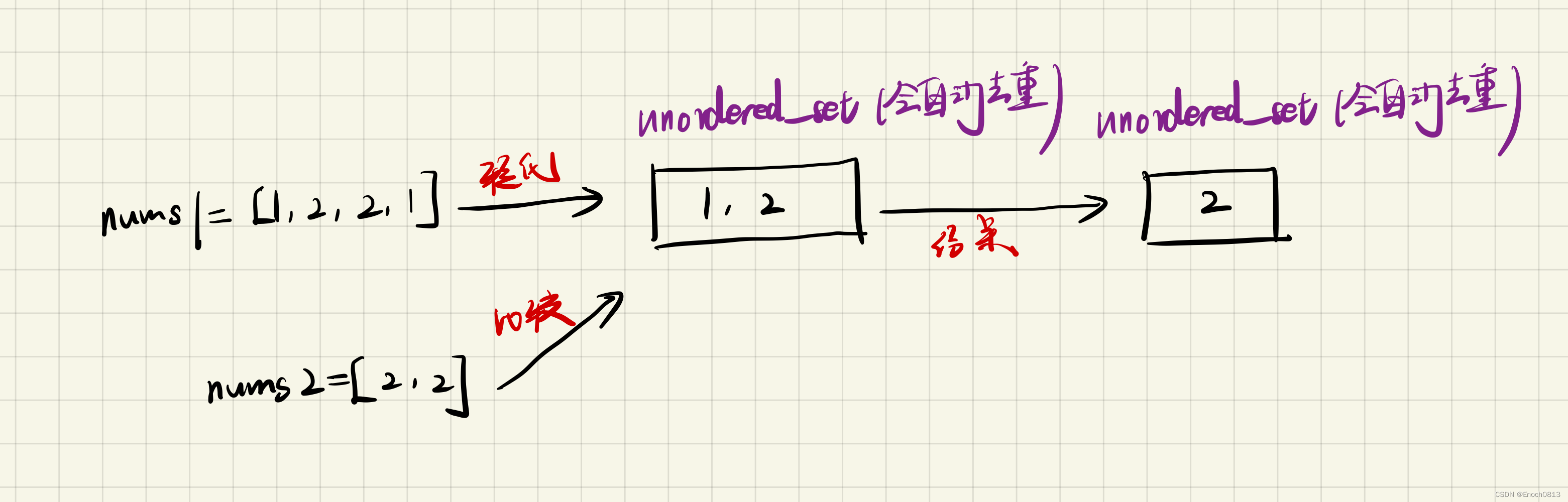
算法思想(画图展示):
为了更能让大家了解该算法的算法思想,作者特意画了一张图供大家观看!!!
算法思想(使用数组实现哈希表):
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set;
int hash[1005] = {0};
for (int num : nums1) {
hash[num] = 1;
}
for (int num : nums2) {
if (hash[num] == 1) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
好!按照老样子,接下来开始详细讲解每行代码的用处,以及为什么这样写
unordered_set<int> result_set;
声明一个unordered_set类型的数组,名称为result_set,用于存放我们最终的两个数组交集。之所以选择使用unordered_set,是因为自动会去重。不需要我们手动去重。
int hash[1005] = {0};
由于本例中,数组大小限制在1000以内,所以我们可以提前声明一个1005的大小的数组,并且初始化赋值为0。同时,也可以是1004、1003等等,只需要大于1000即可。
for (int num : nums1) {
hash[num] = 1;
}
遍历nums1数组,根据nums1中的元素,则会对应的hash数组的下标里赋值1,例如nums1数组里有元素{2,5},则会在下标为2和下标为5的位置赋值1,方便比较nums2时使用。
for (int num : nums2) {
if (hash[num] == 1) {
result_set.insert(num);
}
}
遍历nums2数组,根据nums2中的元素,去遍历hash数组,如果nums2中的元素对应于哈希表下标的值为1,则代表nums1和nums2中的对应元素比较一致,即代表nums1中有nums2的元素。如果比较一致,则将该下标插入到unordered_set类型的result_set,以此类推。
return vector<int>(result_set.begin(), result_set.end());
最终返回unordered_set类型的result_set。
算法思想(使用unordered_set实现哈希表):
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> result_set;
unordered_set<int> nums_set(nums1.begin(), nums1.end());
for (int num : nums2) {
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};
好!按照老样子,接下来开始详细讲解每行代码的用处,以及为什么这样写
unordered_set<int> result_set;
声明一个unordered_set类型的数组,名称为result_set,用于存放我们最终的两个数组交集。之所以选择使用unordered_set,是因为自动会去重。不需要我们手动去重。
unordered_set<int> nums_set(nums1.begin(), nums1.end());
将其nums1数组转换为unordered_set类型的哈希表,并且该哈希表为nums_set。
for (int num : nums2) {
if (nums_set.find(num) != nums_set.end()) {
result_set.insert(num);
}
}
遍历nums2数组,如果发现nums2中的元素在nums_set中出现,则将对应的元素添加到unordered_set类型的 result_set中,代表两个数组中的交集元素。
unordered_set::find()函数是C++ STL中的内置函数,用于在容器中搜索元素。如果找到指定元素,它返回元素的迭代器,如果找不到指定元素,则返回指向unordered_set::end()的迭代器。所以判断与nums_set.end()是否相等即可。
return vector<int>(result_set.begin(), result_set.end());
最终返回unordered_set类型的result_set。
结束语
如果觉得这篇文章还不错的话,记得点赞 ,支持下!!!

![[论文笔记]SimMIM:a Simple Framework for Masked Image Modeling](https://img-blog.csdnimg.cn/d8775c50461f401e962e16833c5b9d0a.png)