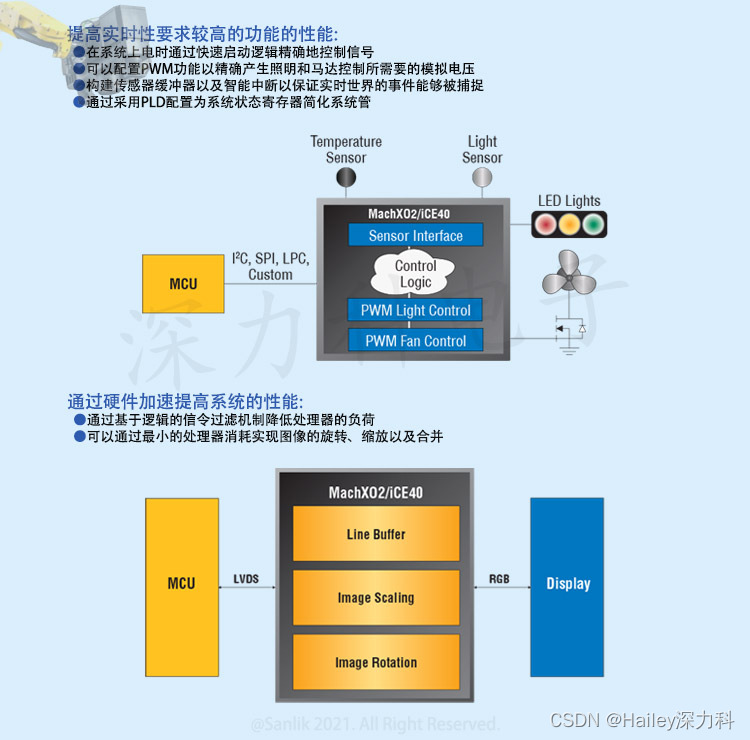
摘要:MySQL在充分利用多核计算资源方面比较欠缺,无法同时满足在线业务和分析型业务的客户需求,而单独部署一套专用的分析型数据库意味着额外的成本和复杂的数据链路。本次主题将介绍腾讯云数据库为满足此类场景而在HTAP for MySQL产品方面进行的尝试。
2023首届云数据库技术沙龙 MySQL x ClickHouse 专场,在杭州市海智中心成功举办。本次沙龙由NineData、菜根发展、良仓太炎共创联合主办。本次,腾讯TEG数据库产品部高级技术专家陆洪勇,为大家分享一下《HTAP for MySQL 在腾讯云数据库的演进》的一些技术内容。
本文内容根据演讲录音以及PPT整理而成。

陆洪勇,腾讯TEG数据库产品部高级技术专家,曾在 SAP 做过多年HANA数据库内核的设计与研发,阿里云 Polardb 数据库内核的设计与研发。目前在腾讯云数据库做 HTAP for MySQL 相关产品的设计与开发。

今天我来讲一下,HTAP for MySQL 在腾讯云数据库的演进。主要介绍的内容如下:首先介绍一下产品背景,然后会介绍产品的两个重要功能,第一个是并行查询,第二个是列存索引,这也是MySQL能力提升的最重要的两个方面。

这个产品实际上是我们所提到的公有云,公有云的概念大家都比较熟悉。其中一个产品是 Tencent DB for MySQL,这是一个基于 MySQL 开源的托管产品。类似的产品还有阿里云的 RDS。这是一个典型的、传统的 MySQL 主从复制架构,通过 binlog 进行数据复制。每个节点都有自己的日志和数据。
另一个产品是我们的云原生数据库产品 TDSQL-C,它有两个基本特点:资源池化和极致弹性。在这个产品中,我们使用了分布式共享存储来存储数据,而 CPU 和内存等资源也将实现相应的池化,后续我们还会陆续推出相应的产品。极致弹性能力在于使用了共享存储,所以我们每一个只读节点,可以很容易的挂载上来。同时,共享存储也很容易进行扩容和缩容,这是我们产品的基本背景介绍。

首先,我们通过对大量重点客户在大盘上的分析,发现客户存在两大痛点。其中,第一个痛点极其重要,即稳定性问题。第二个痛点是慢查询,这是一个非常令人头疼的事情。慢查询的原因有很多,比如用户没有为某些查询创建索引或者索引未命中。另一个更为普遍的原因是MySQL单核处理能力在数据量较大时的瓶颈。
针对这些问题,业界提出了几种解决方案。第一种是提高多核处理能力,包括多节点并行查询和MPP。第二种是提高指令执行效率,其中一种方法是向量化执行,包括SIMD指令,另一种方法是JIT编译,目前在一些商业数据库用的还比较多一点。第三种是提高信息密度,由于行存数据库中数据之间的相似性较低,因此需要进行一些压缩或批量处理是比较难的,另一个解决方案是使用列式存储。
在业界中,部署模式也存在类似的三种。其中一种是中间键模式,即在MySQL集群中构建一个中间件,通过中间件进行分布式查询分析和并发执行,最终的执行片段会下压到每一个的MySQL节点上去,这样MySQL能够把分析型能力能够解决,其中阿里云Polardb-X产品就是比较典型的例子。另一种是专有的AP系统,该系统建立在MySQL之外单独建立一个分析型系统,包括ClickHouse是比较好的一个方案,通过 binlog 或者其他的形式进行日志同步,相当于提供专用的日志分析,将正常数据或TP数据通过MySQL,分析的话就通过AP进行处理。我们的产品其实是想在MySQL本身构建并行查询和AP能力,使用户能够无需感知我们的底层操作,不会对业务造成侵入,同时获得非常大的性能提升。

首先,在上面的这个过程中,我们进行了并行查询的演进,而下面一排是关于列式存储和引擎的演化。这两个功能是独立开发的。然后,在去年的六七月份,我们将这两个技术融合,使得我们的公有云产品上,MySQL和云原生产品具有了并行查询和列存框架。这样一来,用户可以享受到极大的执行效率提升。
这个框架的融合之后,我们的两个团队可以持续扩展各自的能力,所以后面的扩展很容易被整合进这个框架里面。例如,我们在列存做的向量化处理和delta store等,都可以很容易地被吸收到这个执行框架中。只要将这些功能合入到框架中,用户就可以充分体验到这些带来的性能优势。
在2021年底,我们做了一个列存索引的功能,相当于创建了一个 InnoDB的索引,数据可以通过异步传输同步到列存中,以实现数据及时同步。后面我们会有一个具体框架,可以看下我们是怎么做的。

首先,我们来介绍一下并行查询, 我们举了一个示例,从TPCH中选取了一个简单的查询语句进行测试。在MySQL普通执行下,该查询需要约64秒的时间。而在使用并发查询后,四个DOP、四个worker只需要16秒的时间。可以看到并行查询的效率提升是线性的,达到了四倍。这是MySQL原有的执行计划,我们可以看到每个worker线程都有一个sender节点,用于数据发送。最终数据会在gather层进行汇总。这是一个典型的并行执行计划。下面是并发查询的状态,可以通过 show process 进行查看。

这里我们介绍一个具体的实现方案。在MySQL中,有一个比较困难的方案需要计划切分,这是因为在传统的数据库中,如我之前从事的HANA数据库,生成的计划与数据是分离的,因此plan在传输到其他worker线程时很容易实现。但是MySQL是比较难的,主要在于传统开发模式导致了计划和数据的耦合,使得直接进行plan拷贝非常困难。后面我们简单介绍下包括业界常用的三种方案。然后我们看一下这样简单的一个plan,举个例子,比如我们table scan上有一个聚合数据的表,经过计划切分后,我们会在worker线程上添加一个并行执行的节点,然后再上层添加一个receiver节点来汇聚结果。如果有更多的worker,切分的数量也会相应增加。
第一个方案是将来自SQL的逻辑计划和物理计划依次生成,然后将物理计划拷贝到并行worker现场上。这需要对每一个MySQL执行计划里面涉及的数据结构全部做克隆操作,且工作量巨大,据我们了解,当前公有云上TOP厂商中,至少有两家采用了这种方案。不过这种方案存在一些问题,其中厂商投入了大量人力和物力,而另外对MySQL的代码进行了大量的入侵。在后期,你很难跟上社区的,因为社区在不断做代码重构。
第二种方案实际上是一种更常见的商业数据库方案。当SQL语句到达时,它将生成一个逻辑计划,并通过拷贝一些环境数据到worker线程,从而生成一个执行计划。这是一个很自然而然的操作。我们目前采用了这种方案,并通过它实现了比其他友商更好的效果,而且只用了他们1/4的人力和时间。这并不是吹牛,如果有机会大家可以试一试。我们之所以能够采用这种方案,而其他友商采用了其他的方案,一方面是因为我们从社区中获得了一些经验和技术红利,另一方面是因为我们参与了社区的构建。社区在不断重构SQL构层,将逻辑计划和物理计划分离,通过 iterator机制拆分得更清晰,这为我们提供了基础,使我们能够完成这项工作。
第三种方案使用较少。当SQL生成逻辑计划并生成执行计划时,对于需要执行不同的物理计划片段,该方案通过反向编写成SQL语句的方式来实现。然后,将SQL语句发送到不同的worker线程上,这些线程可能是ClickHouse。由于ClickHouse无法直接执行MySQL执行计划,因此将SQL语句发送过去,就能够执行了。我们之前也曾经尝试过使用反写SQL的方式,但是与第一个方案相比,工作量并不见得小,因为基本上必须要把整个执行计划反向一遍。因此,我们采用第二种方案实现了非常好的效果。

我们可以看一下,在TPCH 100G上的性能表现。在DoP为16的情况下,我们基本上有十倍以上的性能提升。我们还有一些能力暂时不支持,因此没有进一步提升。但是,基本上能够达到线性提升,因为现在是16DoP,我们有大约十倍的性能提升,这样的效果非常明显。

经过我们的并行查询的介绍后,我们想简要提一下我们投入最大的产品——列存索引,我们期望这个产品未来能够为用户带来更好的效果和使用体验。在列存索引的友商市场上,我们进行了分析比较了Oracle、SQL Server、 TiFlash、MySQL HeatWave等多款产品,综合各家之长,并结合我们自身技术,我们成功设计了列层索引架构。

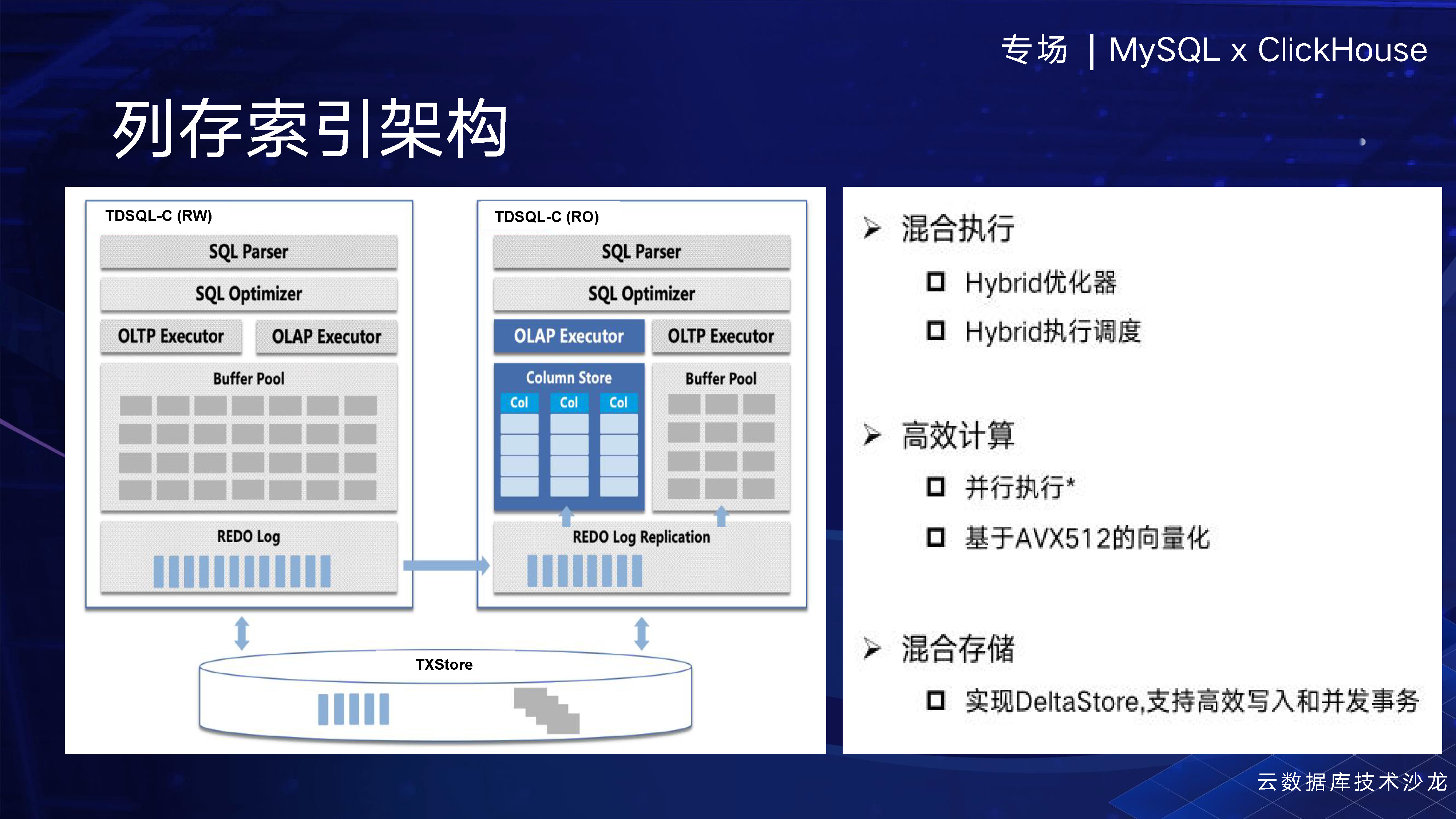
列层索引架构,相当于这是一个RW节点,这是一个只读节点,在只读节点上为每张表创建了一个列存的索引,但是我们知道 InnoDB 一个索引最多只支持16个列。相比之下,我们的索引扩展性非常强,支持最多256列。我们也意识到,在分析型数据处理过程中,大宽表是常态,因此在未来可能需要支持更多的列。
当数据插入时,我们会通过一个redo log以物理复制的方式将数据同步(同步和异步均可)到列存索引中。然后,我们通过Delta Store进行并行的回放,实现高效的数据插入。
在这个框架中,我们有一个OLAP执行器,这个就是MySQL自身的执行器,但是我们使用的是统一的优化器,可以调度执行计划,使得哪一部分在列存执行,哪一部分在行存执行。由于列存索引不断演进,其功能可能会不断扩展,因此当整个的plan过来的时候,不能完全在我们的列存执行,那我们就有一些需要在行存执行,所以当前我们需要混合的执行框架,以实现更好的效果。
在计算过程中,我们也会用到并行计算,刚刚提到的并行计算是MySQL本身,那我们在列存内部的话,我们也在构建这样的一个能力。在未来,我期望能够通过们的优化器对查询语句进行整体优化,在我们这里执行整个分析过程,以提高效率和准确性。此外,我们还将引入AVX512向量化执行,进一步提高性能。
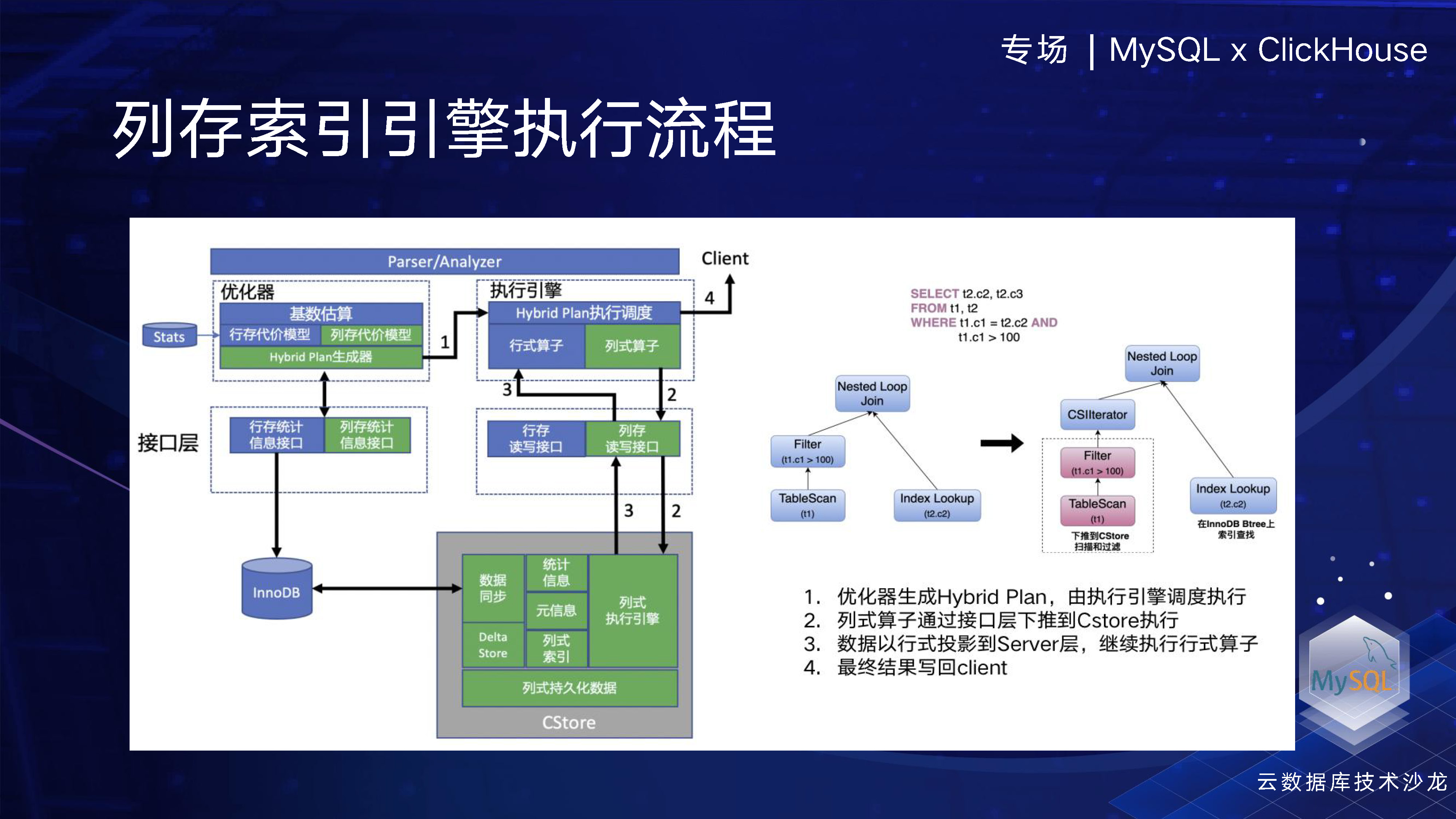
这是简单过一下语句例子,比如说这是一个 Nested Loop Join,假如现在只有这个第一条语句table scan和filter能到列层里面去执行,那我们这个执行框架是怎么做的呢?首先一条语句来了之后,它会通过这个优化器会生成混合的一个执行计划。执行计划就会把这个精细化,放到这个执行调度里边去。然后会把其中涉及到列存执行的plan,通过这个下压接口层下压到Cstore的执行器,执行器里面我们会并行执行,也会进行一些原数据。例如索引数据和粗糙索引,以过滤掉一些大数据块,从而提升效率。此外,我们还有SIMD 的指令的执行,最终会把结果返回到行存,从而会得到最终的结果。从这里我们可以看出,我们是一个混合的执行框架。
在我们的执行引擎框架中,我们使用了SIMD指令,即单指令多数据,这是引擎中一个非常重要的部分。我们有两张图,第一张图显示了我们采用了SIMD指令和没有采用SIMD指令但采用了批处理 (即一次处理4096行数据)的性能比较。我们从TPCH中抽取了一部分数据,大概可以看到我们提升了 5 倍左右的性能,这说明SIMD指令的效果非常明显。SIMD使用的是英特尔自己的指令集,例如对于一个INT8类型的计算,如果使用普通的指令,一条指令只能执行 INT8 加 INT8。但是如果使用英特尔512的AVX512指令,一条指令就可以计算64行数据,因此效率提升是非常高的。

另外一点,就是我们不采用SIMD的指令,采用了批处理方式一次处理4096行数据,另一种对比方式就是一行一行的执行,我们发现采用批处理方式可以使性能提升约五倍左右。两者再结合的话,性能提升将更为明显,预计至少可以提升25倍以上。上面的测试,我们在TPCH 100G的测试场景下进行。

接下来,看下通过结合列存索引和并行查询的plan情况,这是TPCH Q3一个语句。在这个计划中上面是一个聚合层(协调者),底下是有多个 worker 线程。最底下是列存执行的一个计划,而上面则是行存执行的计划。这个计划非常好地体现了我们将行列存储的优点相结合,并加入了并行查询的能力。这样做的结果就是我们具备了整合多方优点的能力。

我们在列存中有一个非常重要的一点,那就是Delta Store。为什么我们需要Delta Store呢?当你进行一个并行回放的时候,数据是通过REDO Log同步到列存中的。而Delta Store能够提供高效的数据插入,因为它可以在内存中不断地open only将数据往后插入。这样做的好处是,它能够提高行级并发,同时我们还有一个insert / delete mask,这使得我们在列存中具备了MVCC的能力。结合我们在MySQL上的SCN机制,我们就能够提供完整的事务视图,从而实现完整性的事务查询。当数据插满后,我们会将其冻结并把它download到磁盘上去进行压缩,当一些数据会永久的被被删掉了,或者说这个数据永远所有人都能看到了,我们会进行一些空洞的compaction。然后再 merge到 main store里面去,其实有点像 LSMtree 的架构。

现在我再讲一下,我们这个产品中并行查询部分已经上线了,在公有云上已经可以使用。而列存索引这部分目前正在内部灰度和一些大客户的试用中,取得了非常好的效果。尽管还没有正式推出,但我们在PQ查询的基础上,我们又有至少三倍以上的性能提升,这是在还没有完全加入向量化的情况下。而如果在向量化加持之后,我们期望会有更大的性能提升。

目前这个阶段的话,我们正在做一些工作,例如并行查询在MySQL这一部分,我们可能会做MPP。列存的话,我们有可能会开发自己的MPP,以及包括支持大型的存储。最后,我想重点谈谈我们的统一内核的技术空间,因为我们知道,公有云和私有云是不同的技术架构。公有云使用共享存储,而私有云使用分布式存储。但是我们已经将并行查询扩展到了私有云上,这意味着我们公有云和私有云都使用了同一个并行框架。接下来,我们会将列存能力扩展到私有云上。这意味着我们一套能力可以在两个系统上完全复用。目前来看,我们可能是友商中第一个实现这种统一内核的机制。

本次大会围绕“技术进化,让数据更智能”为主题,汇聚字节跳动、阿里云、玖章算术、华为云、腾讯云、百度的6位数据库领域专家,深入 MySQL x ClickHouse 的实践经验和技术趋势,结合企业级的真实场景落地案例,与广大技术爱好者一起交流分享。