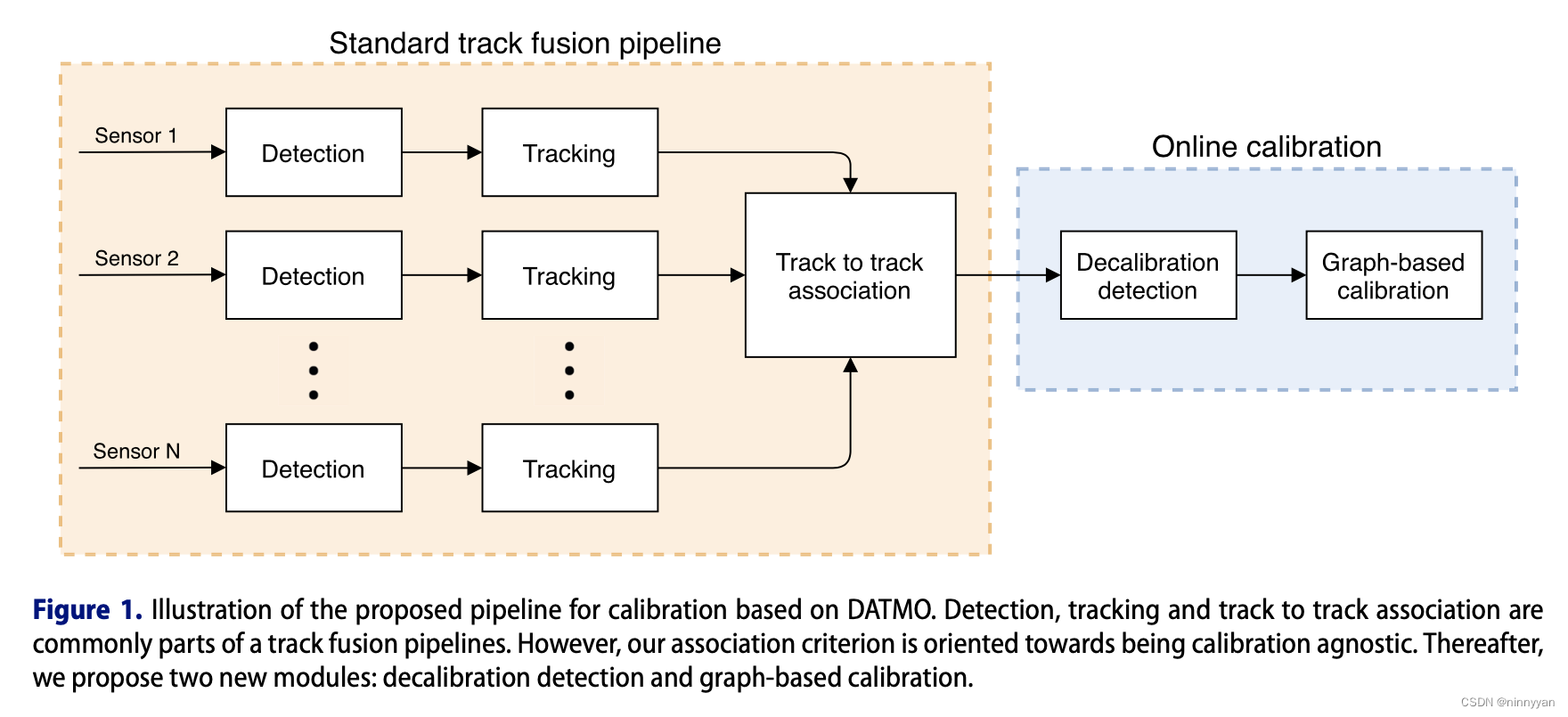
作者:王华峰(花名继儒),Hologres研发
近年来,随着移动端应用的普及,应用埋点、用户标签计算等场景开始诞生,为了更好的支撑这类场景,越来越多的大数据系统开始使用半结构化JSON格式来存储此类数据,以获得更加灵活的开发和处理。Hologres是阿里云自研的云原生一站式实时数仓,支持PB级数据多维分析(OLAP)以及高并发低延迟的在线数据服务(Serving),在对半结构化数据分析场景,Hologres持续优化技术能力,从最开始支持JSONB类型,到支持JSONB GIN索引,再到1.3版本支持JSONB列存,在不牺牲使用灵活性的前提下,提升JSONB数据的写入和查询性能,同时也降低存储成本。JSONB列存也在阿里集团内部多个核心业务使用,其中稳定支撑搜索事业部2022年双11大促,历经生产考验,查询性能提升400%,存储下降50%!
点击查看阿里巴巴搜索事业部双11JSONB实践>>升级JSONB列式存储,Hologres助力淘宝搜索2022双11降本增效!
通过本文,我们将会揭秘Hologres JSONB半结构化数据的技术原理,实现JSON半结构数据的极致分析性能。
什么是半结构化数据
介绍什么是半结构数据之前,我们首先明确下什么是结构化数据。结构化数据可以理解成在关系型数据库(RDBMS)中的一张表,每张表都有明确严格的结构定义,比如包含哪些列,每列的数据类型是怎样的,存储的数据必须严格遵循表结构的定义。
相对应的,半结构化数据就是非固定结构的、经常变化的,且一般是自描述的,数据的结构和内容混杂在一起,最典型的例子就是JSON格式数据。JSON有标准的格式定义,其主要由对象(Object)和数组构成(Array),对象中存储的是键值对,其中键只能是字符串,值可以是字符串、数组、布尔值、Null值、对象或者数组,数组中可以存放任意多个值。
以下就是一个简单的JSON实例,相信大家都很熟悉:
{"user_name": "Adam", "age": 18, "phone_number": [123456, 567890]}
Hologres当前正是通过支持JSON数据类型来提供半结构化数据的能力,为了兼容Postgres生态,我们支持Postgres的JSON/JSONB这两种原生类型,其中JSON类型实际以TEXT格式进行存储,而JSONB类型存储的是解析过后的二进制,因为查询时不需要再解析,所以JSONB在处理时会快很多,下文提到的Hologres半结构化数据方案的很多内部优化都是依托JSONB类型完成的。
我们为什么需要半结构化数据?
半结构化数据得益于其本身的易用性以及强大的表达能力,使得半结构化数据的使用场景非常广泛。
对于数仓来说,每当上游的数据格式有变更时,比如变更数据类型、增删字段,数仓中的强Schema格式的表,必须进行相应的表结构演进(Schema Evoluation)来适配上游的数据,比如需要执行DDL进行加列或者删列,甚至中间的实时数据ETL作业也需要进行适配改动并重新上线。
在有频繁Schema Evoluation的场景的时候,如何保证数据的质量是个很大的挑战,同时维护和管理表结构,对于数据开发人员来说也是一项琐碎且麻烦的工作。
而半结构化数据则天然支持Schema Evoluation,上游业务的变更,只需要在JSON列数据中进行增删相应的字段,无需对数仓中的表做任何DDL就能完成,也能对中间的ETL作业做到透明,这样就能大大降低维护和管理表结构的成本。
传统数仓的半结构化数据解决方案
数仓在处理半结构化数据的时候,衡量一个解决方案好坏的核心考量主要有两点:
- 能否保持半结构化数据的易用性和灵活性
- 能否实现高效的查询性能
而传统的解决方案常常是顾此失彼,没法做到“熊掌”与“鱼”的兼得。常见的JSON数据处理方式有2种:
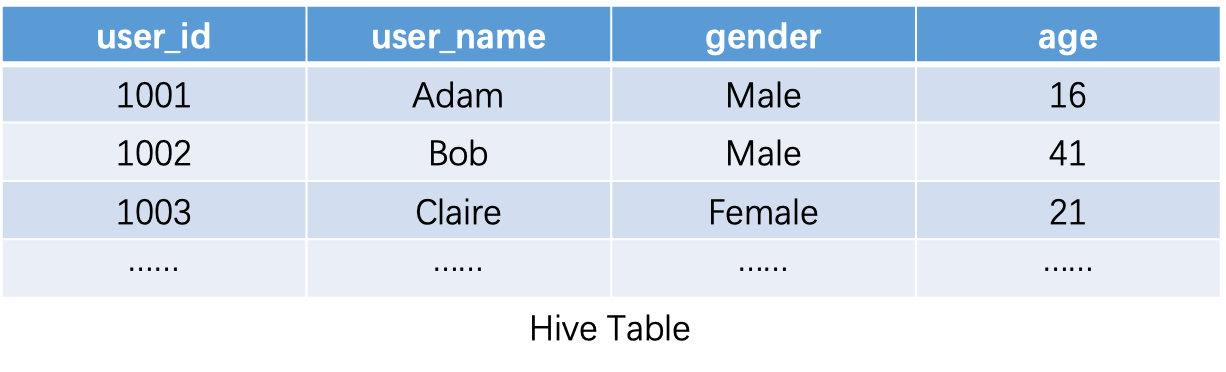
以下方案都以JSON数据为例,假设我们有如下JSON数据:
| {“user_id”:1001, “user_name”: “Adam”, “gender”: “Male”, “age”: 16} |
|---|
| {“user_id”:1002, “user_name”: “Bob”, “gender”: “Male”, “age”: 41} |
| {“user_id”:1003, “user_name”: “Clair”, “gender”: “Female”, “age”: 21} |
方案1: 数仓直接存储原始JSON数据
一种最直观的方案就是将原始JSON数据存成单独的一列,以Hive为例:

在存储层,这张Hive表的数据也是以一个完整的JSON值作为最小的存储粒度在磁盘上连续存储:

之后使用相关的JSON函数进行查询,比如查询所有年龄大于20的用户数:
SELECT COUNT(1) FROM tbl WHERE cast(get_json_object(json_data, '$.age') as int) > 20;
抽象成下面的流程:
上游直接写入JSON类型到Hologres,中间不经过处理,应用层查询时,再去解析需要的数据。
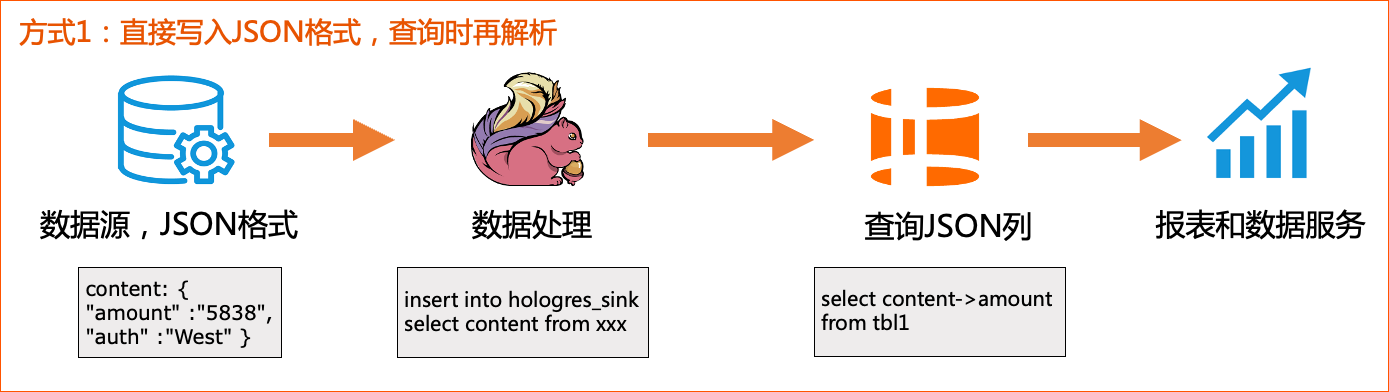
这种处理方式:
- 优点是:JSON则天然支持Schema Evoluation,上游业务的变更,只需要在JSON列数据中进行增删相应的字段,无需对数仓中的表做任何DDL就能完成,也能对中间的ETL作业做到透明,最大程度地保留了半结构化数据的易用性和灵活性,能大大降低维护和管理表结构的成本。
- 缺点是:应用端查询时需要选择合适的处理函数和方法,才能解析到需要的数据,开发较为复杂,如果JSON较复杂,同时查询性能会有退化,因为每次JSON列的数据参与计算的时候,都需要对JSON数据完整的解析一遍,比如需要抽取出整个JSON中某个字段,那么查询引擎执行的时候就要读出每一行JSON,解析一遍,取出需要的字段再返回。这中间会涉及大量的IO和计算,而需要的可能只是JSON数据成百上千字段当中的一个字段,这中间的大量IO和计算都是浪费的。
方案2: 加工成宽表
既然JSON查询时的解析开销很大,那就把解析前置在数据加工链路中,于是另外一种做法就是把JSON拍平成了一张宽表:
相应的抽象出来的流程如下:
上游是JSON格式,在导入时,将JSON进行解析,比如常见的通过Flink的JSON_VALUE函数解析,然后打宽成一张大宽表,再写入至Hologres,对于上层应用,直接查询Hologres中已经解析好的列。
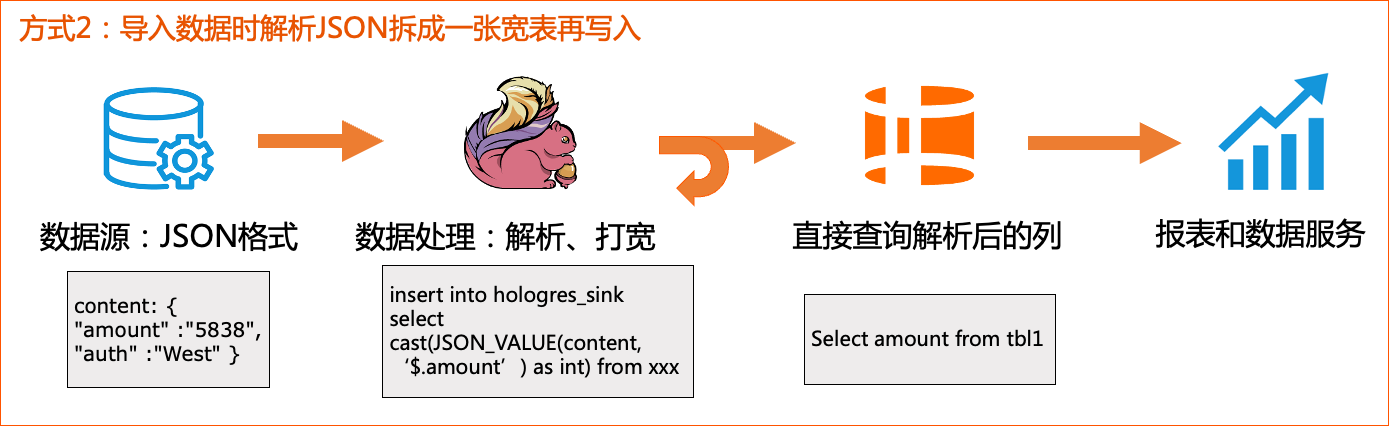
对于这种处理方法:
- 优点是:写入Hologres时,因为是普通列写入,所以写入性能会更好,同时在查询侧,不需要对JSON数据进行解析,查询性能也会更好。
- 缺点是:每当上游的数据格式有变更时,比如变更数据类型、增删字段、执行DDL进行加列或者删列,中间的实时数据ETL作业也需要进行适配改动并重新上线,使用非常不灵活,也会额外增加运维和开发负担。
基于此背景,业界也迫切需要一个既能保持高效的查询性能,又不牺牲使用灵活性的方案,来应对海量半结构化数据的极致分析场景。
Hologres列式JSON实现方案
为了更好的支持JSON分析场景,Hologres不断迭代技术能力,在早期版本支持了JSON数据格式和相关解析函数,用户可以直接写入JSON类型以及相关的查询解析。同时1.1版本在查询层做了JSON相关的优化,有效的提升JSON数据查询性能,比如支持GIN倒排索引,加速JSON数据的过滤,支持表达式下推等,但整体加速场景有限且使用难度较高,于是1.3版本我们做了大量的存储层优化,通过JSONB列存的方式来实现更好的查询性能。
总体方案介绍
经我们观察,实际用户的非结构化数据,在一段时间周期内,整体数据的结构都是比较稳定的,通常只会有有限个数的确定的字段,区别只是每个字段出现的频率会有所不同,且每个字段的数据类型也是整体稳定的。
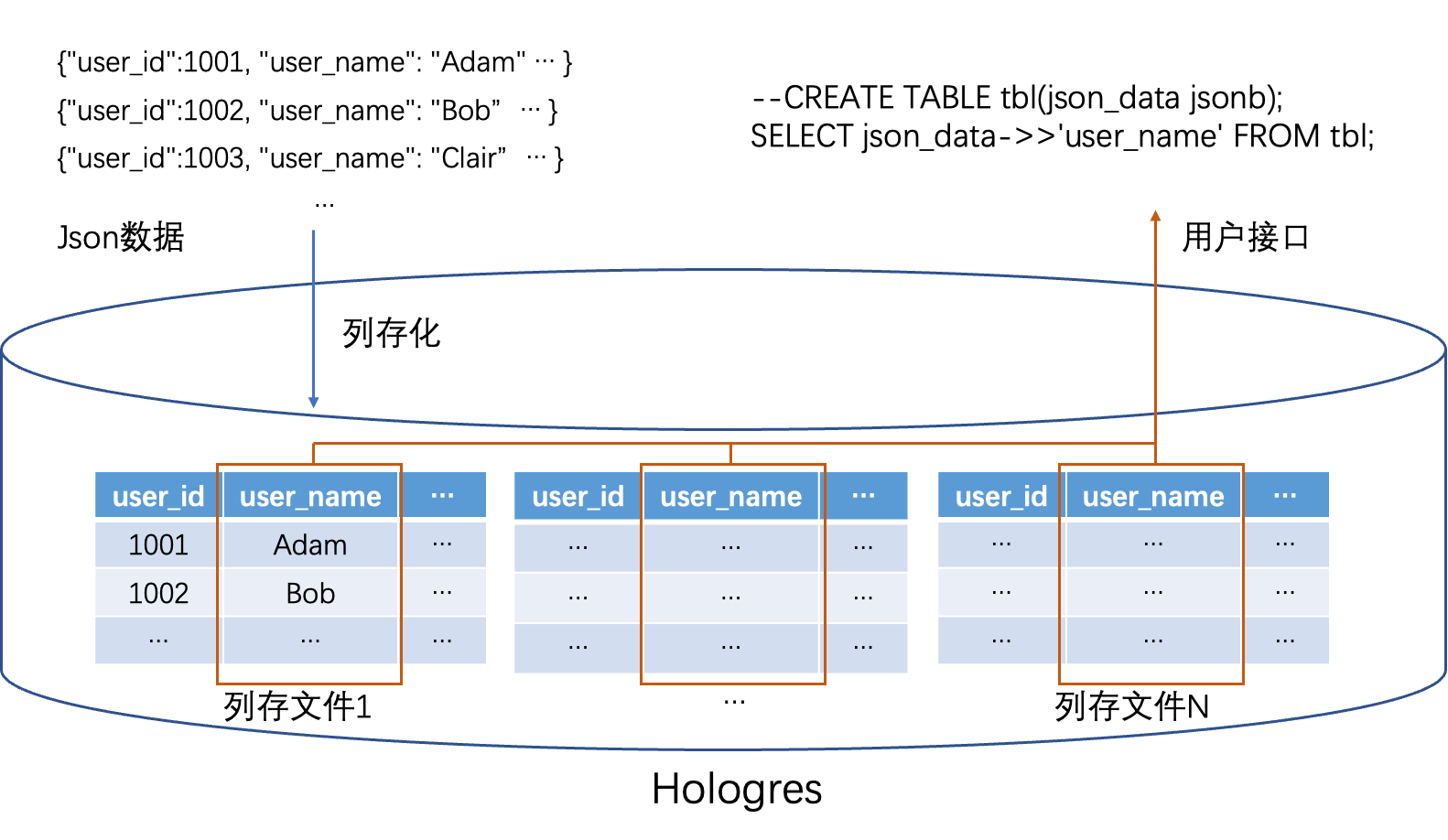
基于以上经验,Hologres提供的实现方案的核心要点就是,在导入JSON类型数据至Hologres的时候,引擎自动去抽取JSON数据的结构(字段个数,字段类型等),然后在存储层,将JSON数据转化成强Schema格式的列式存储格式的文件,以此来达到加速查询的效果,同时对外接口上,依旧保持JSON的语义,真正做到了保持JSON易用性的同时,兼顾了OLAP查询性能。
以下图为例,Hologres每张表在同一个Shard上的数据,也是会分文件存储的,而且同一个文件中的数据,通常也是在邻近的时间点写入的,所以在JSON场景下,文件与文件之间可能会有结构的差异,但单个文件内的数据能有比较稳定的结构,从而整体上做到JSON数据结构的稳定演进。
JSON与JSONB
在详细介绍Hologres JSON列存化实现之前,我们先简单介绍下Postgres中的JSON和JSONB两种数据类型的区别。
JSON和JSONB这两种数据类型在用户接口上没有很大的差异,大部分操作符都是相同,主要区别在于存储格式上的差别:
- JSON类型只会校验写入的数据是否符合JSON规范,存储上直接将JSON原文按照TEXT存储,无任何优化
- JSONB在JSON的基础上,会对数据进行格式优化,存储的是对原始JSON数据优化过后的二进制格式,其优化包含但不限于:
-
- 去除数据中的冗余空格
- 对相同路径下的同名字段去重
- 对JSON数据中的字段进行排序,重新排列组织,加速查询能力
在函数覆盖上,JSON和JSONB这两个类型也有些许差别,比如JSON类型无法直接Cast成INT/Float/Numeric等类型,而JSONB则可以,所以整体语法层面JSONB更完整易用。
Hologres的JSON列存化方案,当前的实现主要还是基于JSONB这个数据类型,具体原因下文会讲到。
JSON结构抽取
JSON数据的结构抽取,主要做的是确定JSON数据的格式,包括JSON具体有哪些字段,每个字段对应的数据类型,以此作为底层列存文件的实际存储结构。
Hologres数据写入流程整体是个LSM (The Log-Structured Merge-Tree)架构,当数据写入到Hologres的一张表的时候,数据首先会写到内存表(MemTable) 中,当一个MemTable满了以后,将其以异步的方式Flush到文件系统中(下图第4步),并初始化一个新的MemTable,同时后台会有任务,不停将Flush到文件系统的文件做进一步的合并(Compaction,下图第5步),更多详情见Hologres存储引擎揭秘
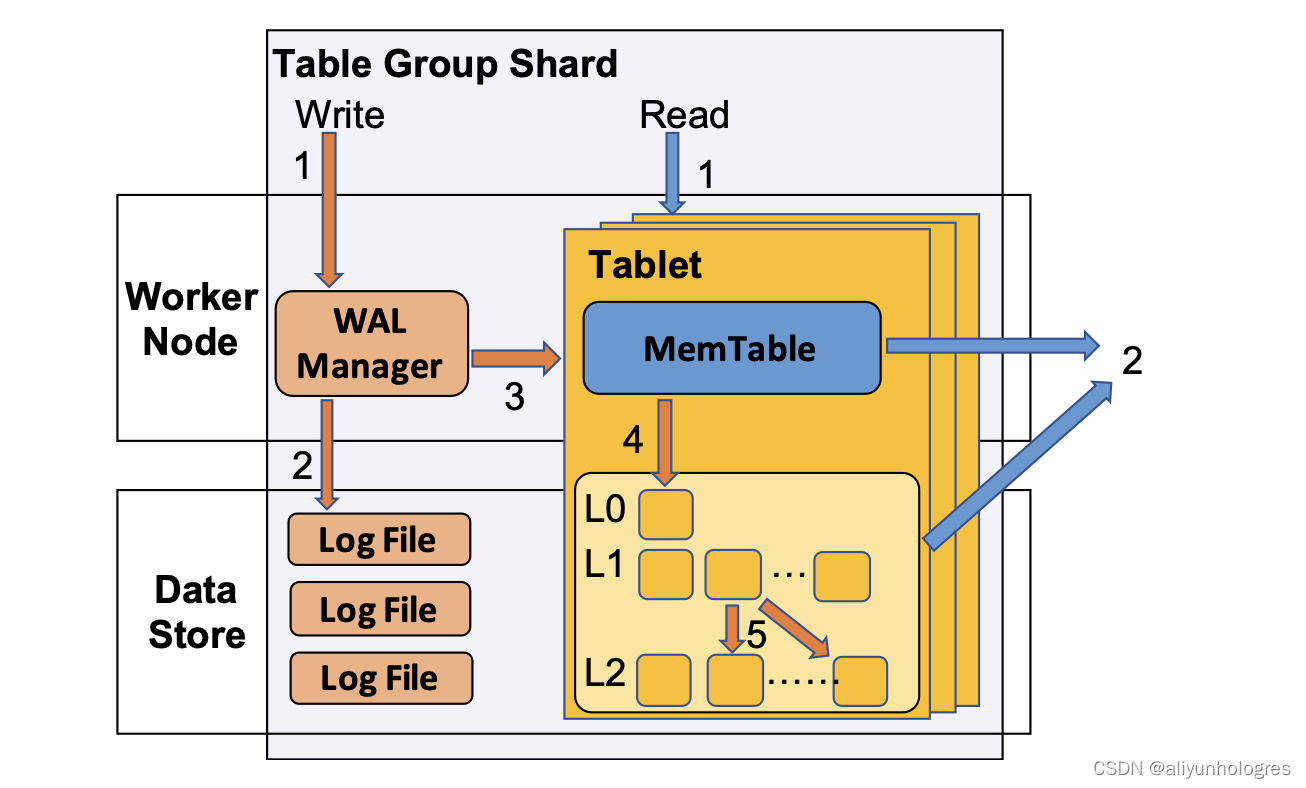
而JSON数据的结构抽取,也主要发生在Flush和Compaction两个阶段。
Flush阶段
当MemTable Flush时,我们会遍历一次在MemTable中所有JSON数据,记录下每个JSON中出现过的字段,以及每个字段的数据类型,遍历完成后,就能知道这列JSON数据列存化之后,具体会有哪些列以及每一列的对应类型。
还是以下面的数据为例:
| {“user_id”:1001, “user_name”: “Adam”, “gender”: “Male”, “age”: 16} |
|---|
| {“user_id”:1002, “user_name”: “Bob”, “gender”: “Male”, “age”: 41} |
| {“user_id”:1003, “user_name”: “Clair”, “gender”: “Female”, “age”: 21} |
我们就能够抽取出以下JSON格式:
| 列名 | 数据类型 |
|---|---|
| user_id | INT |
| user_name | TEXT |
| gender | TEXT |
| age | INT |
另外,在遍历JSON的过程中,我们也会进行类型泛化。比如user_id字段某一行数据出现了超过INT类型阈值的值,我们就会把user_id列的类型泛化成BigINT类型来兼容所有数据。
抽取完JSON结构之后,我们就能把MemTable中的数据写到文件系统了,JSON列数据会被拆分写到对应的4列中去。
Compaction阶段
Compaction做的事情就是把多个文件合并成一个更大的文件,这里也涉及到JSON结构的抽取。
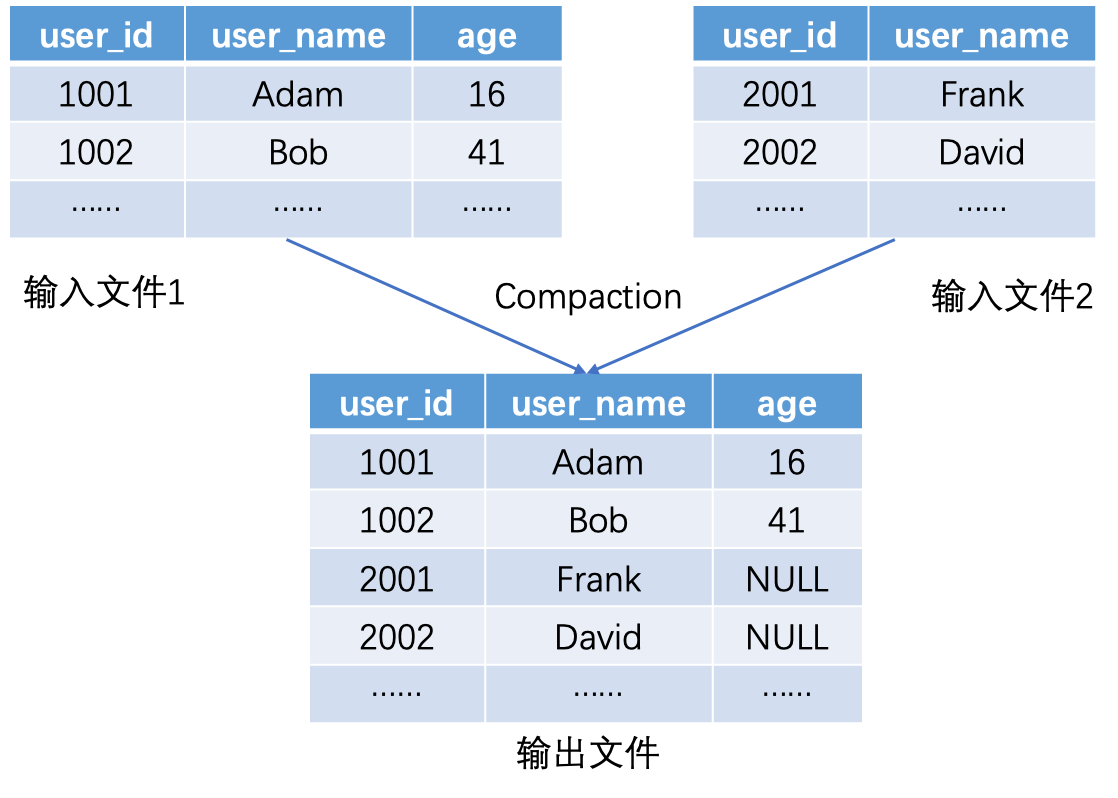
与Flush不同的是,由于Compaction的输入文件已经对JSON列进行了列存化处理,所以我们在大部分情况下并不需要再完整遍历所有文件中的JSON数据去抽取结构,而是可以直接通过文件的Meta信息就能推导出输出文件的JSON格式,只需要对所有文件的输入列取一个并集,并对冲突列的类型进行泛化即可。
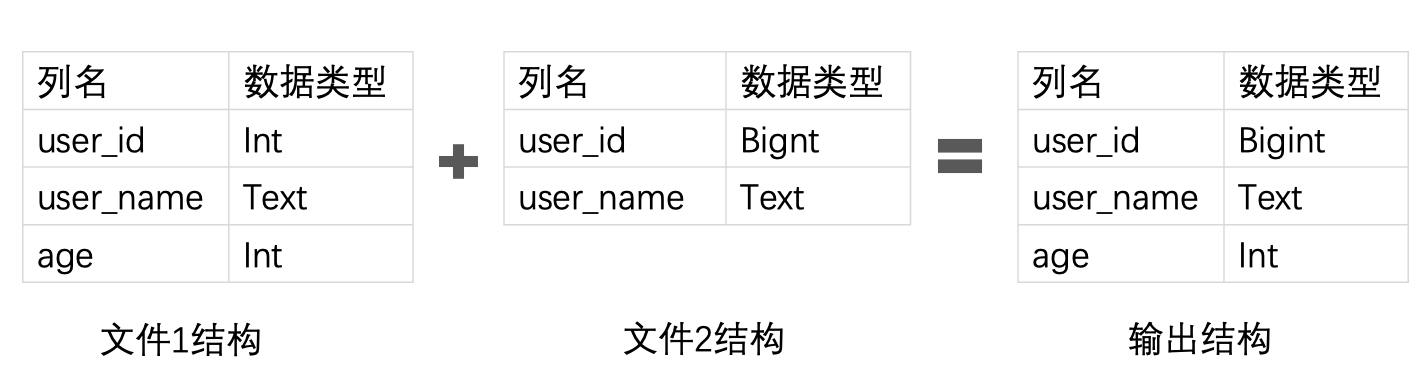
通过上述Flush和Compaction阶段的JSON数据处理,我们就能将数据在存储层列式化,便于后续的查询加速。
查询自适应改写
上文提到,Hologres虽然底层存储将JSONB数据转成了列式存储,但用户接口还是沿用了原生JSONB的查询接口,而由于底层JSONB数据格式的改变,如果查询引擎还是将列式化后的数据当成JSONB类型,查询势必会失败(数据的实际输入类型和执行计划的预期输入类型不一致),所以这就要求我们的查询引擎有查询自适应改写的能力。
接下来我们以一个简单的SQL为例子讲解查询过程中涉及到的查询自适应改写:
CREATE TABLE TBL(json_data jsonb); --建表DDL
SELECT SUM((json_data->'quantity')::BIGINT) FROM TBL;
在Hologres中,对JSONB类型最常用的两个操作符就是**->** 和**->>**
- -> 操作符的含义是,根据操作符后面的路径参数,取出对应的JSONB数据,该操作符的返回数据类型是JSONB
- ->> 操作符的含义是,根据操作符后面的路径参数,取出对应的JSONB数据,该操作符的返回数据类型是TEXT
所以,上面例子的含义就是,读取json_data这一JSONB列中的quantity字段,并转成BIGINT类型后,进行SUM聚合运算。
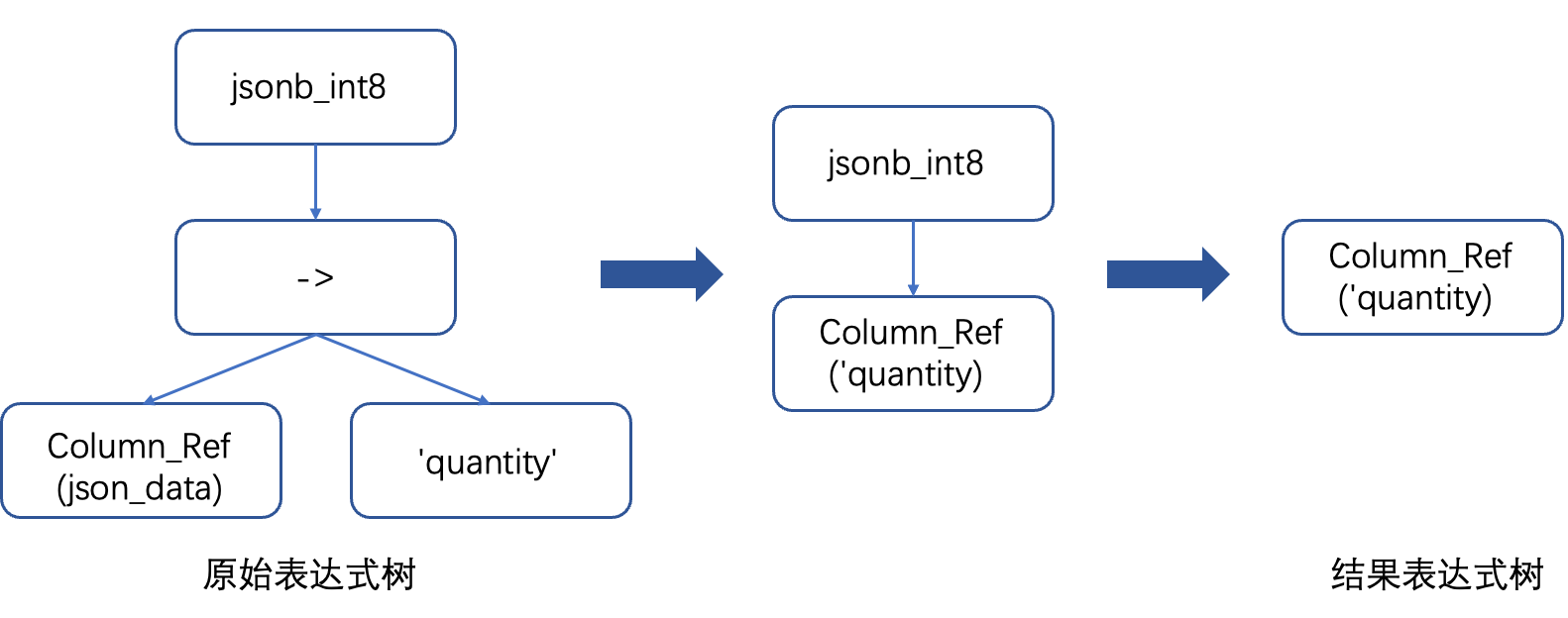
所以在物理执行计划中,Scan节点就会有上图中最左边的表达式树,根节点代表将JSONB转换成BIGINT的函数,它的孩子节点表是取出json_data列中的quantity字段。
但实际上底层文件存储的是列存化后的数据,已经没有了json_data这一物理JSON列,所以我们在Scan节点就需要进行自适应的物理执行计划改写:
- 第一步就是进行列裁剪,如果我们发现底层文件的Meta信息中含有quantity这一列,我们就可以直接消除**->** 这一表达式计算,得到了上图中间所示的表达式树。当然如果我们发现Meta信息中没有quantity这一列,那我们就可以直接跳过扫描这个文件,返回执行结果,大大提升执行效率。
- 第二步就是根据文件Meta信息判断quantity这一列的物理存储类型,当我们发现实际存储类型和要求Cast的类型目标一致时,我们就能进一步改写优化执行计划,省去了Cast的操作,得到了上图中最右所示的表达式树,也就是直接返回物理存储的列数据。另外如果实际存储类型是INT,那么我们就需要将原始的Cast节点替换成INT到BIGINT的Cast操作,来保证结果的正确性。
那为什么不直接让SQL Optimizer把执行计划一开始就改写好呢?
原因在于优化器并不知道JSONB列在存储引擎的真正格式,比如同一列quantity,在文件A中的类型是INT,在文件B中的类型是TEXT,所以对于不同文件的执行计划可能是不同的,SQL Optimizer无法用一个物理执行计划表达所有可能的情况,这就要求执行引擎能够进行自适应的执行计划改写。
脏数据、稀疏数据处理
由于JSON类型的易用性,理论上用户可以写入任意符合JSON格式的数据,这也导致相较于强Schema类型,JSON类型更容易产生脏数据,这就要求Hologres的JSON列式方案要有比较强的鲁棒性,能够容忍脏数据,这里我们主要讨论两类问题::数据类型不一致的问题以及字段名错误导致的数据稀疏问题。
脏数据
首先如何处理不一致的数据类型,假设我们现在有以下JSON数据需要列式存储:
| {“user_id”:1001, “user_name”: “Adam”, “gender”: “Male”, “age”: 16} |
|---|
| {“user_id”:1002, “user_name”: “Bob”, “gender”: “Male”, “age”: 41} |
| {“user_id”:1003, “user_name”: “Claire”, “gender”: “Female”, “age”: “21”} |
可以看到age列的前两行数据都是INT类型的,但是到第三行的时候,age列的值就是一个TEXT类型的数据了,这时候我们就会对类型泛化,泛化成我们在上文提到JSONB类型:
| 列名 | 数据类型 |
|---|---|
| user_id | INT |
| user_name | TEXT |
| gender | TEXT |
| age | JSONB |
我们可以把JSON看做是个递归定义的格式,像16、41、"21"这些age字段的值,本身也是一个JSON值(Object类型),所以我们可以进行这样的类型泛化。这样泛化之后,之后对于age列的查询性能会稍弱于没有脏数据的情况,因为在执行引擎层,无法像上一节提到的,直接略去JSONB的Cast操作,但整体性能还是远好于没有JSON列存化的方案的,因为我们还是只需要读取age这一列数据,可以省去大量的IO和计算操作。
稀疏数据
我们再来看下如何处理稀疏数据,通常稀疏数据产生的原因是上游数据生成的逻辑有问题,生成了大量不重复的字段名,比如以下数据:
| {“user_id”:1001, “user_name”: “Adam”, “gender”: “Male”, “age”: 16, “key_1”: “1”} |
|---|
| {“user_id”:1002, “user_name”: “Bob”, “gender”: “Male”, “age”: 41, “key_2”: “2”} |
| {“user_id”:1003, “user_name”: “Claire”, “gender”: “Female”, “age”: 21, “key_3”: “3”} |
可以看到每一行都有一个不一样的字段,且不重复,如果我们选择抽取key_1,key_2,key_3这三列,那这三列的数据就会非常稀疏,也会导致整体文件的列数膨胀的很厉害。
我们选择将这些稀疏数据单独抽取到特殊的一列(holo.remaining),该列的类型也是JSONB,我们会把出现频度低于某个阈值(可配置)的数据,都存放到这个字段中:
| 列名 | 数据类型 |
|---|---|
| user_id | INT |
| user_name | TEXT |
| gender | TEXT |
| age | INT |
| holo.remaining | JSONB |
可以认为在remaining列中存储的就是整个JSON数据的一个子集,这一列并上其他列式化的数据,就能构造成原来完整的一个JSON值。
查询remaining列时的性能也会稍弱于查询已经列式化的列,因为存储的是JSONB,会包含所有稀疏字段,所以查询时需要在JSONB数据中搜索指定的字段,这里有额外的开销。但因为这一列中存储的都是稀疏的数据,通常查询命中remaining列的概率也不会很高,所以可以容忍。
嵌套与复杂结构处理
上文中给出的JSON实例都是比较简单的扁平化的数据,但实际上含有嵌套结构的JSON数据也是比较常见的,接下来简单介绍下Hologres是如何处理复杂JSON结构的。
嵌套结构
对于嵌套结构,我们可以把JSON数据看成是一颗树,数据都存在叶子节点中(没有复杂嵌套结构的情况下),比如下面这个JSON数据,就会抽取出右图所示的树形结构:

因为非叶子节点本身并不存储数据,所以实际上存储的时候就可以把上面的树状结构拍平得到以下表结构,另外我们的元数据会记录节点的深度信息,以此来保证拍平的时候不会出现列名歧义或者冲突的情况。
复杂嵌套结构
首先我们需要先明确下当前Hologres抽取JSON结构时,只会抽取出以下基本类型:
- INT
- BIGINT
- TEXT
- INT[]
- BIGINT[]
- TEXT[]
- JSONB
这里面JSONB类型就是我们尝试类型泛化后仍旧无法抽取成前面6种基本类型时,作为兜底的类型实现,这当中也包括的复杂嵌套结构,比如下面这行JSON数据就会抽取出右图所示的结构,可以看到对于descs这个字段,因为是数组里面嵌套了非基本类型数据,所以这里类型退化成了JSONB类型。

所以这里要注意的点就是,对于这类退化成JSONB类型的数据,针对这一列的操作的性能会不如那些抽成基本类型数据的列,但整体性能还是会比非列式JSON方案会好很多,因为JSONB列只存储了完整JSON数据的一个子集,查询这一列涉及到的IO和计算都会小很多。
列式JSON不适用场景
查询带出完整JSON数据
Hologres的列式JSON方案对于大部分使用场景都有比较好的优化效果,主要需要注意的点是,对于查询结果需要带出完整JSON列的场景,性能相较于直接存储原始格式的JSON会有退化,比如以下SQL:
CREATE TABLE TBL(pk int primary key, json_data jsonb); --建表DDL
SELECT json_data FROM TBL WHERE pk = 123;
SELECT * FROM TBL limit 10;
原因在于底层已经将JSON数据转成了列式存储,所以当需要查询出完整JSON数据的时候,就需要将那些已经列式存储的数据重新拼装成原来的JSON格式:

这个步骤就会产生大量的IO以及转换开销,如果涉及到的数据量很大,列数又很多,甚至可能成为性能瓶颈,所以这种场景下建议不要开启列式优化。
极稀疏的JSON数据
上文已经提到,当我们列式化JSON数据遇到稀疏的字段时,我们会将这部分字段合并至一个叫做holo.remaining的特殊列中,以此来避免列数膨胀的问题。
所以如果用户的JSON数据,包含的都是稀疏字段,比如极端情况下每个字段都只会出现一次,那么我们的列式化将不会起效,因为所有字段都是稀疏的,那么所有字段都会合并至holo.remaining字段,等于没有进行列式化,这种情况下就不会有查询性能的提升。
Hologres列式JSON方案收益:降本增效
收益1:存储降本
我们使用了TPCH的数据集来测试Hologres JSON列式方案对于存储空间的优化效果,具体测试对比方案是将TPCH的表都建成一列JSONB的格式,然后对比开启列式方案的效果(几张数据量较小的表略去了):
--存储原始Jsonb数据的表
CREATE TABLE CUSTOMER(data jsonb);
CREATE TABLE LINEITEM(data jsonb);
CREATE TABLE ORDERS(data jsonb);
CREATE TABLE PART(data jsonb);
CREATE TABLE PARTSUPP(data jsonb);
--开启列式Json优化的表
CREATE TABLE CUSTOMER_COLUMNAR(data jsonb);
ALTER TABLE CUSTOMER_COLUMNAR ALTER COLUMN data SET (enable_columnar_type = on);
CREATE TABLE LINEITEM_COLUMNAR(data jsonb);
ALTER TABLE LINEITEM_COLUMNAR ALTER COLUMN data SET (enable_columnar_type = on);
CREATE TABLE ORDERS_COLUMNAR(data jsonb);
ALTER TABLE ORDERS_COLUMNAR ALTER COLUMN data SET (enable_columnar_type = on);
CREATE TABLE PART_COLUMNAR(data jsonb);
ALTER TABLE PART_COLUMNAR ALTER COLUMN data SET (enable_columnar_type = on);
CREATE TABLE PARTSUPP_COLUMNAR(data jsonb);
ALTER TABLE PARTSUPP_COLUMNAR ALTER COLUMN data SET (enable_columnar_type = on);
使用了TPCH 100GB的测试集进行验证,结果如下:
| 表名 | 原始JSONB存储 (GB) | 开启列式JSONB优化存储(GB) | 数据压缩比 |
|---|---|---|---|
| CUSTOMER | 4.4 | 2.14 | 2.06 |
| LINEITEM | 43 | 18 | 2.39 |
| ORDERS | 14 | 4.67 | 3 |
| PART | 5.2 | 1.3 | 4.3 |
| PARTSUPP | 7.8 | 5.8 | 1.34 |
可以看到,开启列式JSONB优化后,每张表的存储空间都有比较显著的下降,原因在于列式化之后:
- 原来JSON数据中的字段名都不会再存储了,而只需要存储每个字段对应的具体值,比如下面是转成JSON后CUSTOMER表的一行数据,数据中的c_name、c_phone、c_acctbal等字符串,列式化后都不需存储
{"c_name": "Customer#002662050", "c_phone": "23-793-162-6786", "c_acctbal": 4075.57, "c_address": "paJBRFkD N368pMSvGsYivWyRAs", "c_comment": "ly. fluffily even packages along the blithely even deposits should sleep slyly above the", "c_custkey": 2662050, "c_nationkey": 13, "c_mktsegment": "BUILDING"}
- 列式化后每列的数据类型都是一样的,列式存储能有比较好的数据压缩率
这里要多说一点的是,在某些数据集上我们也观察到过开启列式优化后实际存储空间没有下降的情况,这种情况通常是由于JSON数据中的字段比较稀疏,列数膨胀比较厉害,且列式化后每一列的类型都是TEXT类型,导致压缩效果不好导致的。所以上述测试只是一个理论值,实际用户的数据各种各样,实际压缩后的存储效果还是要以实际情况为准。
收益2:查询性能提升
得益于底层列式化的存储格式,对于那些能够利用到JSON列裁剪的查询,经我们测试观察,通常性能都会有数倍的提升,甚至在特定场景下能有十倍以上的性能提升。
这里我们使用Github的数据集(见文末SQL和DDL附录)来验证Hologres JSON列式化方案的查询提升,该数据集记录了Github上的各种用户行为日志,包括发起代码评审、评论等等,该数据集是一份JSON格式的数据集。我们选用了2015年的总计172309645行的数据,导入到同一个Hologres实例后,对比了使用原生JSON类型、原生JSONB类型存储和开启列式JSONB优化后的查询性能:
| 查询 | JSON(ms) | JSONB(ms) | 列式JSONB(ms) | 列式JSONB相较于原生JSONB的性能提升 |
|---|---|---|---|---|
| Query1 | 26426 | 15831 | 50 | 31562% |
| Query2 | 28657 | 19285 | 320 | 5926% |
| Query 3 | 26900 | 17062 | 869 | 1863% |
| Query 4 | 57356 | 44314 | 1430 | 2999% |
可以看到,开启列式JSONB优化后的查询性能,相较于原始JSONB格式,有了质的提升。但要注意的是,由于数据集的不同,以及查询模式的不同,性能收益可能会有较大的差异,具体效果还是要以实际情况为准。后续我们也将陆续推出Hologres JSON列式方案在不同场景下的实现案例,以及对应的性能收益。
淘宝搜索推荐A/B实验场景成功案例
阿里巴巴搜索推荐事业部通过Hologres承载了阿里巴巴集团淘宝、淘宝特价版、饿了么等多个电商业务的实时数仓场景,包括即席多维分析,A/B Test等。
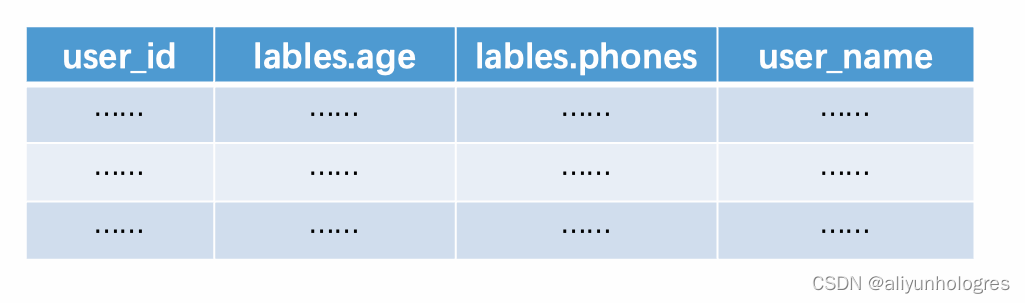
在搜索推荐这类业务场景中,会有很多的用户标签、商品标签、卖家标签和算法桶号等多值属性,以用户标签为例,业务上对用户的画像属性不是一成不变的,业务可能随时需要新增一类属性进行观测,如果每次都需要用一个新的字段来存储新的用户属性,那在整个实时链路上都会十分低效,在使用列式JSONB之前,使用的是Text数组类型作为多值字段的存储格式。
以下是数据和查询示例:
上述SQL的含义就是过滤出命中’layerA:1’、'layerA:2’这两个分桶的数据,并计算对应的PV。
该方案已经稳定使用了几年,但该方案并不是最高效的,无论是存储成本还是计算性能都有进一步提升的空间,且我们认为,从整个数据模型来说,使用JSONB来存储各种属性,才是最直观自然的方式。
以下是改成JSONB方案后的数据与查询示例:
| second_timestamp | pk | UID | … | bts_tags |
|---|---|---|---|---|
| 2022-11-11 00:00:00+08 | 858739e966f7ebd1cfaa49c564741360 | 1 | {“layerA”:“1”, “layerB”:“11”, “layerC”:“111”} | |
| 2022-11-11 00:00:01+08 | e7e3d71fac5a92b87c3278819f6aff8c | 2 | {“layerA”:“1”, “layerB”:“12”, “layerC”:“112”} | |
| 2022-11-11 00:00:01+08 | 828f07dc16f4fa2f4be5ba3a9d38f12a | 3 | {“layerA”:“2”, “layerB”:“11”, “layerC”:“111”} |
SELECT
'layerA:' || (bts_tags ->> 'layerA') AS "bts_tags",
COALESCE(sum(scene_count), 0) AS "pv"
FROM
wireless_pv
WHERE
second_timestamp >= TIMESTAMPTZ '2022-11-11 00:00'
AND second_timestamp <= TIMESTAMPTZ '2022-11-11 23:59'
AND bts_tags ->> 'layerA' IN ('1', '2')
GROUP BY
'layerA:' || (bts_tags ->> 'layerA');
可以看到,切换成JSONB后,无论是数据还是查询,都更加直观且自然了,2022年双11完成了Hologres列式JSONB方案的迁移,并且在迁移后,无论是存储成本还是查询性能,都获得了非常不错的收益:
| 表名 | Array格式查询平均延迟(ms) | JSONB格式查询平均延迟(ms) | JSONB性能提升 |
|---|---|---|---|
| wireless_pv | 5975.5 | 1553.8 | 280% |
| wireless_dpv | 862.5 | 455.8 | 89% |
| 表名 | Array 格式存储量 | JSONB格式存储量 | 存储下降% |
|---|---|---|---|
| wireless_pv | 35 TB | 15 TB | -57% |
| wireless_dpv | 3472 GB | 1562 GB | -55% |
更多详细细节,请参阅: 升级JSONB列式存储,Hologres助力淘宝搜索2022双11降本增效!
总结
Hologres的列式JSON方案,真正做到了在保持JSON易用性和灵活性的同时,兼顾了极致的OLAP查询性能,让用户能够在Hologres上充分挖掘半结构化数据,甚至让Hologres这个一站式实时数仓承担部分数据湖的能力。我们后续也会继续不断优化列式JSON实现,为大家带来更为极致的性能,敬请期待。
附录
- Github数据集: https://www.gharchive.org/
- 查询性能测试DDL
CREATE TABLE gh_2015(gh_jsonb jsonb);
--开启列式优化
ALTER TABLE gh_2015 ALTER COLUMN gh_jsonb SET (enable_columnar_type = on);
- 查询性能测试Query
--Query 1
SELECT COUNT(1) FROM gh_2015 WHERE gh_jsonb->>'type' = 'WatchEvent';
--Query 2
SELECT gh_jsonb->'repo'->>'name', count(1) AS stars FROM gh_2015 WHERE gh_jsonb->>'type' = 'WatchEvent' GROUP BY gh_jsonb->'repo'->>'name' ORDER BY stars DESC LIMIT 50
--Query 3
SELECT to_date((substring((gh_jsonb ->> 'created_at')FROM 1 FOR 8) || '01'), 'YYYY-MM-DD') AS event_month,
sum(coalesce((gh_jsonb -> 'payload' -> 'issue' ->> 'number'), (gh_jsonb -> 'payload' -> 'pull_request' ->> 'number'),
(gh_jsonb -> 'payload' ->> 'number'))::int) AS closed
FROM gh_2015
WHERE (gh_jsonb ->> 'type') = 'IssuesEvent'
AND (gh_jsonb -> 'payload' ->> 'action') = 'closed'
AND (gh_jsonb -> 'repo' ->> 'id')::bigint = 41986369
GROUP BY 1;
--Query 4
SELECT event_month,
all_size
FROM
(SELECT event_month,
COUNT(*) OVER (PARTITION BY event_month) AS all_size,
ROW_NUMBER() OVER (PARTITION BY event_month) AS row_num
FROM
(SELECT (gh_jsonb ->> 'type') AS TYPE,
(gh_jsonb -> 'repo' ->> 'id')::bigint AS repo_id,
(gh_jsonb -> 'payload' ->> 'action') AS action,
to_date((substring((gh_jsonb ->> 'created_at')
FROM 1
FOR 8) || '01'), 'YYYY-MM-DD') AS event_month
FROM gh_2015) t
WHERE TYPE = 'PullRequestEvent'
AND repo_id = 41986369
AND action = 'opened') sub
WHERE row_num = 1
ORDER BY event_month;
了解Hologres:https://www.aliyun.com/product/bigdata/hologram