文章目录
- 一、Service基本了解
- 二、Service定义与创建
- 2.1 相关命令
- 2.2 yaml文件参数大全
- 2.3 创建svc
- 2.3.1 两种创建方式类比
- 2.3.2 验证集群内A应用访问B应用
- 2.3.3 将集群外服务定义为K8s的svc
- 2.3.4 分配多个端口
- 2.4 常用三种类型
- 2.4.1 ClusterIP(集群内部访问)
- 2.4.2 NodePort(浏览器访问)
- 2.4.3 LoadBalancer
- 2.5 svc支持的协议
- 三、svc负载均衡
- 3.1 iptables模式
- 3.2 ipvs模式
一、Service基本了解
Service存在的意义?
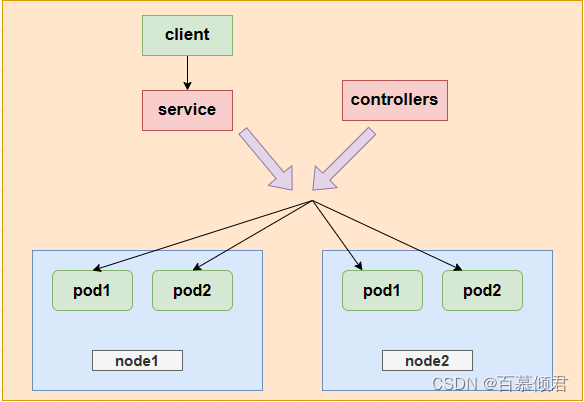
- 引入Service主要是解决Pod的动态变化,通过创建Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上。
- 若提供服务的容器应用是分布式,所以存在多个pod副本,而Pod副本数量可能在运行过程中动态改变,比如水平扩缩容,或者服务器发生故障Pod的IP地址也有可能发生变化。当pod的地址端口发生改变后,客户端再想连接访问应用就得人工干预,很麻烦,这时就可以通过service来解决问题。
概念:
- Service主要用于提供网络服务,通过Service的定义,能够为客户端应用提供稳定的访问地址(域名或IP地址)和负载均衡功能,以及屏蔽后端Endpoint的变化,是K8s实现微服务的核心资源。
svc特点:
- 服务发现,防止阴滚动升级等因素导致Pod IP发生改变而失联,找到提供同一个服务的Pod。
- 负载均衡,定义一组Pod的访问策略。
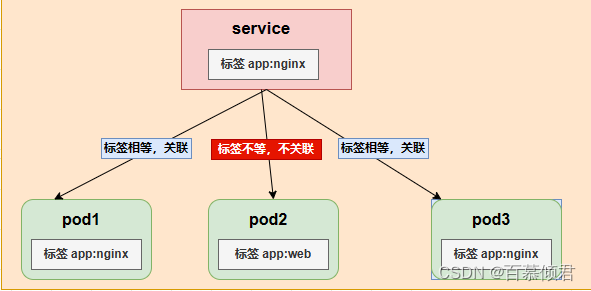
svc与pod关系:
- pod在创建时,与资源没有明确关联,通过service标签和pod标签相匹配来以此关联。
- 可以通过endpoints来查看关联的pod。
二、Service定义与创建
2.1 相关命令
| 命令 | 说明 |
|---|---|
| kubectl create service clusterip web --tcp=80:80 | 命令创建svc |
| kubectl apply -f service.yaml | 定义yaml文件创建svc |
| kubectl expose deployment webapp | 命令创建svc,需要提前创建deploy |
| kubectl get service | 查看svc |
2.2 yaml文件参数大全
| 参数 | 释义 | 是否必选 |
|---|---|---|
| version | 版本号,例如v1 | 必选 |
| kind | 资源对象类型,例如pod、deployment、service | 必选 |
| metadata | 元数据 | 必选 |
| metadata.name | 对象名称 | 必选 |
| metadata.namespace | 对象所属的命名空间,默认值为 default | 必选 |
| metadata.labels | 自定义标签列表 | |
| metadata.annotation | 自定义注解列表 | |
| spec | 详细定义描述 | 必选 |
| spec.selector | Label Selector 配置,将选择具有指定 Label 标签的 Pod 作为管擦绡啷谎理范围 | 必选 |
| spec.type | svc类型,指定svc访问方式,默认为ClusterIP。 1、ClusterP:虚拟服务IP地址,用于K8s集群内部的Pod访问,在 Node 上kube-proxy通过设置的iptables 规则进行转发。 2、NodePort:对外部客户端提供访问应用使用。 3、LoadBalancer:使用外接负载均衡器完成到服务的负载分发,用于公有云环境。 | 必选 |
| spec.clusterlP | 虚拟服务的IP 地址。 当type=ClusterIP 时,若不指定,则系统进行自动分配,也可以手工指定; 当type=LoadBalancer时,需要指定。 | |
| spec.sessionAffinity | 是否支持 Session,可选值为 ClientP,默认值为 None。 ClientIP表示将同一个客户端(根据客户端的IP 地址决定)的访问请求都转发到同一个后端 Pod。 | |
| spec.ports | 定义端口设置列表。 | |
| spec.ports.name | 端口名称 | |
| spec.ports.protocol | 端口协议,支持TCP、HTTP、UDP、SCTP等等,默认值为TCP | |
| Spec.ports.port | svc端口 | |
| spec.ports.targetPort | 容器端口 | |
| spec.ports.nodePort | 当spec.type=NodePort 时,指定映射到宿主机的端口号 | |
| Status | 当spec.ype=lodBalaner 时,设置外部负均衡器的地址,用于公有云环境 | |
| status.loadBalancer | 外部负载均衡器 | |
| status.loadBalancer.ingress | 外部负载均衡器 | |
| status.loadBalancer.ingress.ip | 外部负载均衡器IP | |
| status.loadBalancer.ingress.hostname | 外部负载均衡器的主机名 | |
| spec.selector | 指定关联Pod的标签 | 必选 |
2.3 创建svc
1.创建一个service,名称为seride-demo,指定类型为clusterip,第一个80是svc端口,第二个80是容器端口。
[root@k8s-master bck]# kubectl create service clusterip service-demo --tcp=80:80
2.查看svc

2.3.1 两种创建方式类比
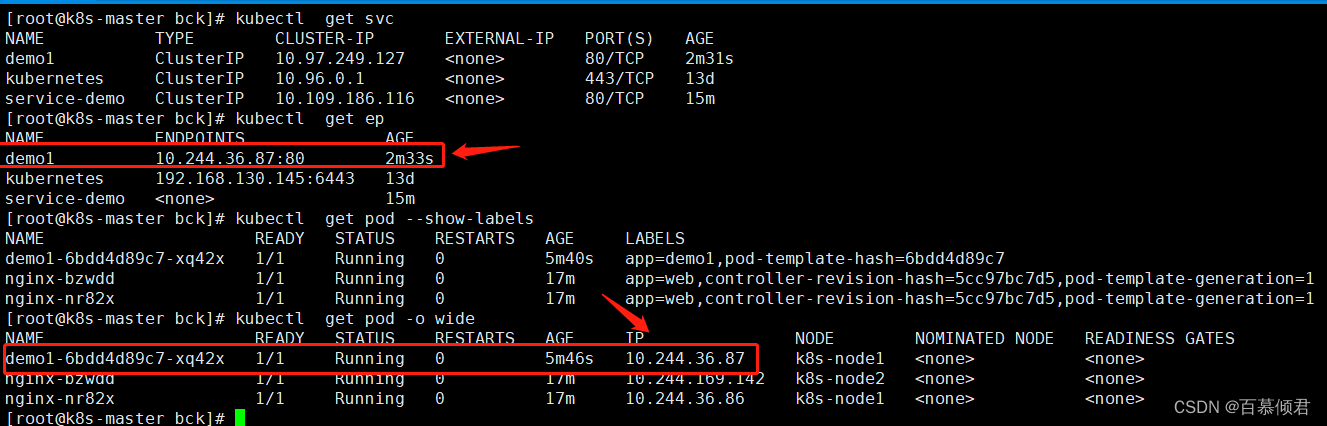
1.先通过kubectl expose方式创建,先创建一个deployment,此时的pod名称为demo1,标签为app=demo1。

2.创建一个svc,名为demo1,看是否能和demo1的pod关联上。
[root@k8s-master bck]# kubectl create svc clusterip demo1 --tcp=80:80
3.此时查看demo1的svc和demo1的pod关联上了,是因为创建的svc标签是和deployment创建的pod标签一样。
2.3.2 验证集群内A应用访问B应用
- 我们创建一个svc后,会随机分配和cluster-ip,配合svc端口,可以在任何一个节点上访问其他应用。

1.创建一个pod,配合上面创建的svc demo1来模拟前端访问后端。这里的bs为前端,demo1为后端。进入bs容器,通过clusterip:svc端口来访问demo1前端网页。
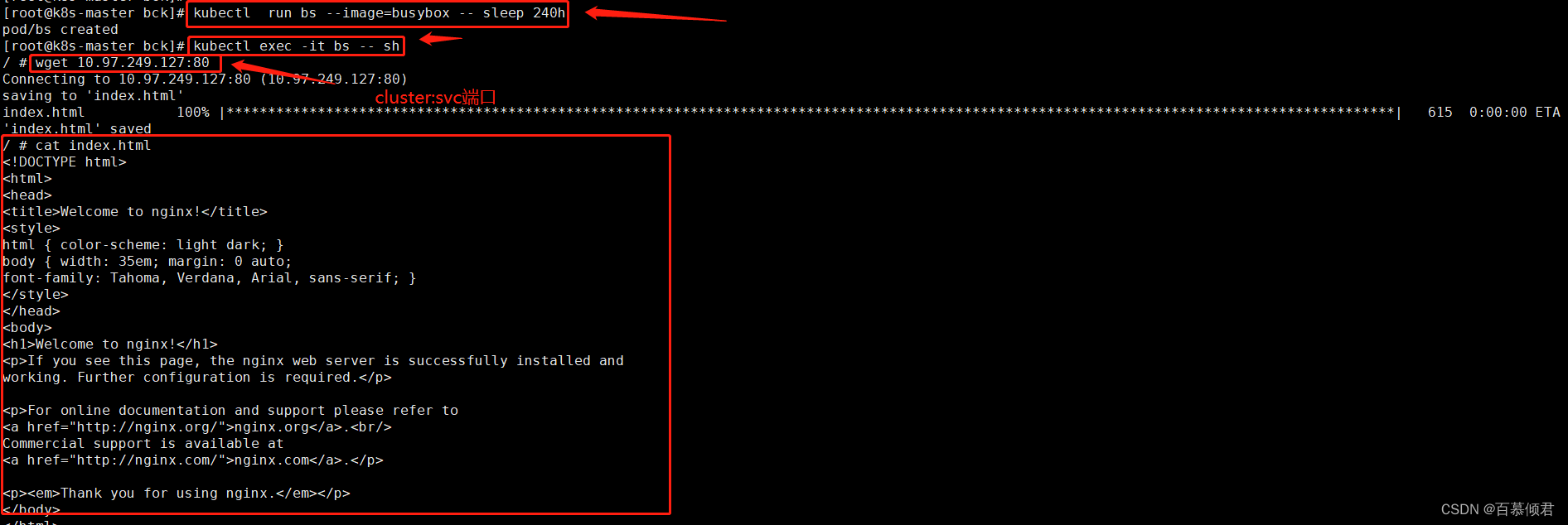
2.3.3 将集群外服务定义为K8s的svc
- 将一个Kubernetes集群外部的已知服务定义为Kubernetes内的一个Service,供集群内的其他应用访问。
应用场景:
- 已部署的一个集群外服务,例如数据库服务、缓存服务等。
- 其他Kubernetes集群的某个服务。
- 迁移过程中对某个服务进行Kubernetes内的服务名访问机制的验证。
1.准备一个集群外的服务,我这里在192.168.130.147上部署一个nginx服务。
[root@k8s-node2 ~]# docker run -d --name nginx1 -p 80:80 nginx
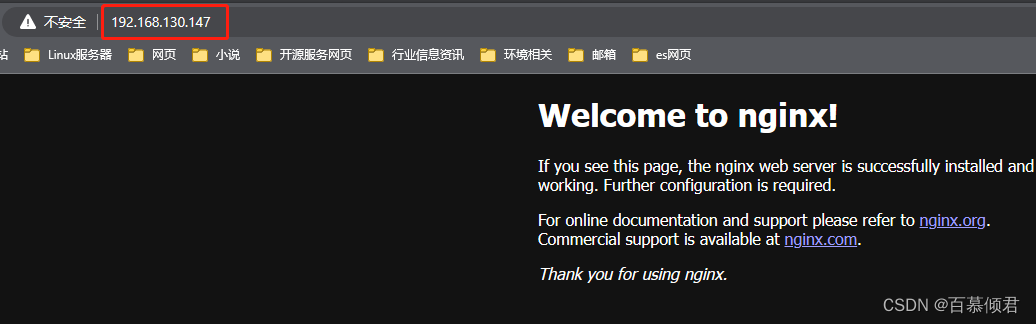
2.此时我想将这个nginx服务定义成K8s集群内部的svc,供集群内的其他应用访问。
[root@k8s-master ~]# cat svc.yaml
---
apiVersion: v1
kind: Service
metadata:
name: qingjun1
spec:
ports:
- protocol: TCP
port: 80
targetPort: 80
---
apiVersion: v1
kind: Endpoints
metadata:
name: qingjun1 ##与svc名称一致。
subsets:
- addresses:
- ip: 192.168.130.147 ##外部服务地址
ports:
- port: 80 ##外部服务访问端口
[root@k8s-master ~]# kubectl apply -f svc.yaml
3.查看,此时就会会创建一个svc并分配clusterip,同时endpoint将其与外部服务关联。
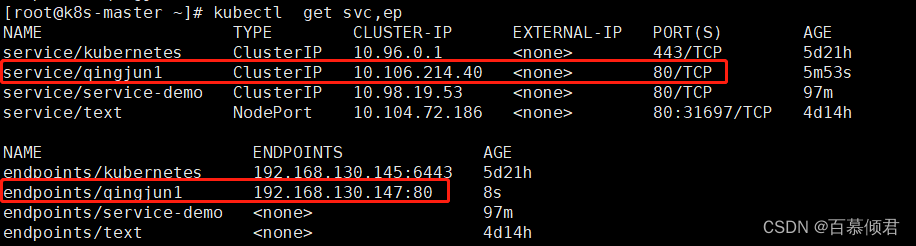
4.此时进入测试容器验证,可以访问到外部服务。
[root@k8s-master ~]# kubectl run bs --image=busybox -- sleep 24h

2.3.4 分配多个端口
- 多端口Service定义:对于某些服务,需要公开多个端口,Service也需要配置多个端口定义,通过端口名称区分。
1.先创建1个pod内有两个容器,一个是Nginx,一个是tomcat。现在需要通过访问80端口到达nginx,访问svc的8080端口到达tomcat。
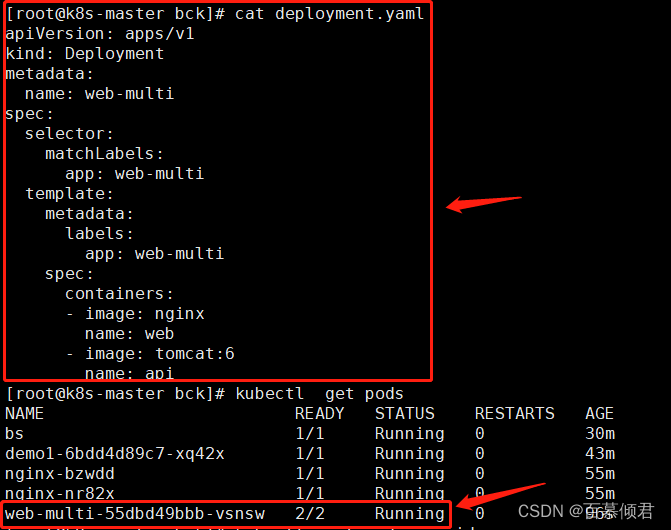
2.创建svc,编辑yaml文件,添加多个端口。
[root@k8s-master bck]# cat svc.yaml
apiVersion: v1
kind: Service
metadata:
name: web-multi
spec:
ports:
# nginx
- name: 80-80
port: 80 ##代理nginx80端口。
protocol: TCP
targetPort: 80
# tomcat
- name: 88-8080
port: 88 ##代理tomcat8080端口。
protocol: TCP
targetPort: 8080
selector:
app: web-multi
type: ClusterIP
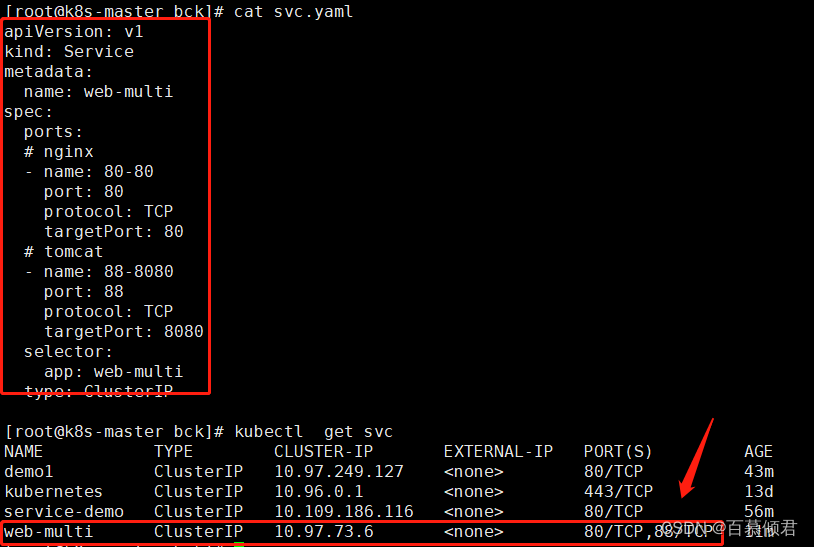
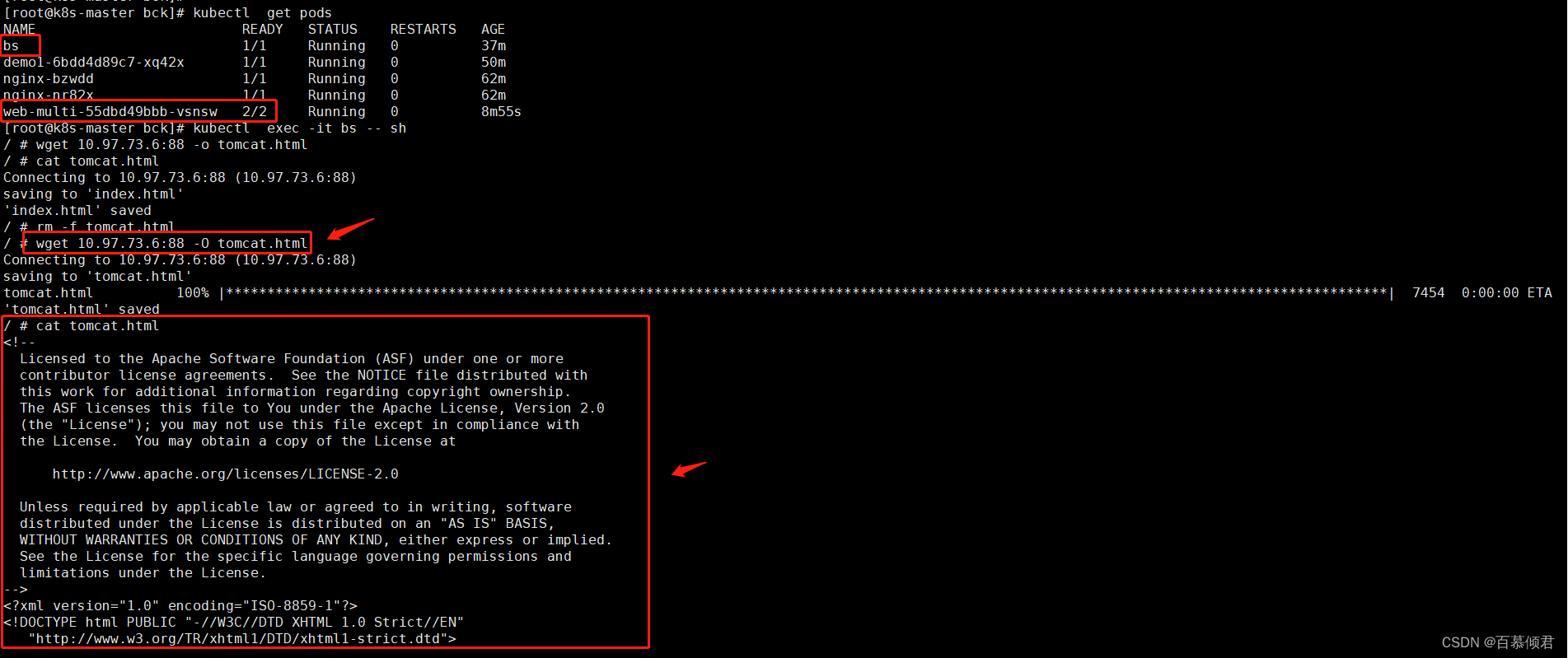
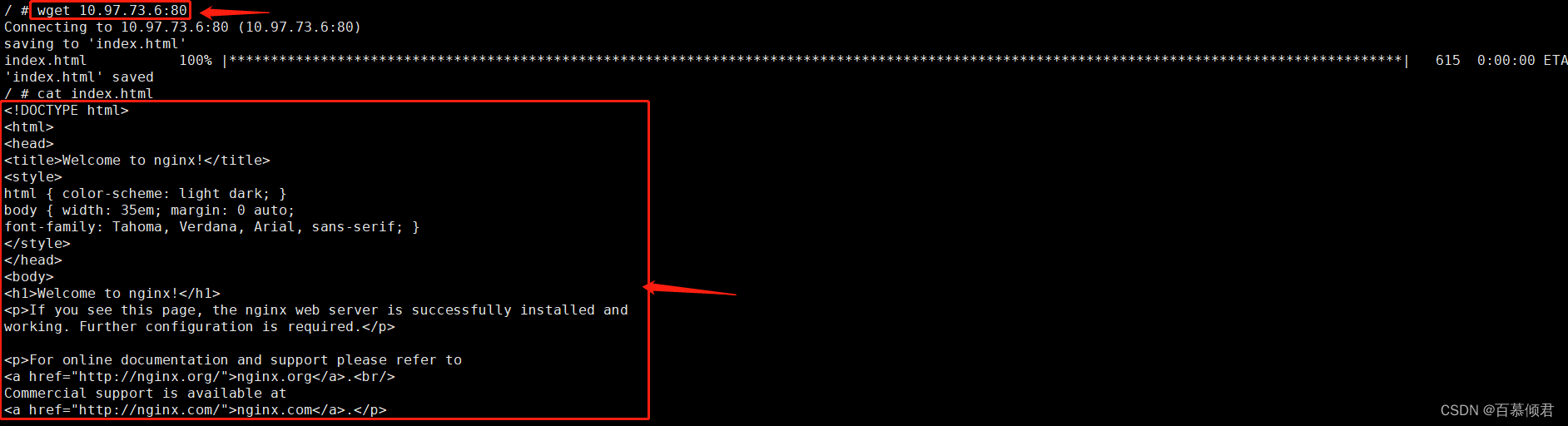
3.通过另外一个pod验证,进入bs容器,访问web-multi里的容器端口。访问88端口,则返回tomcat;访问80端口,则返回nginx。
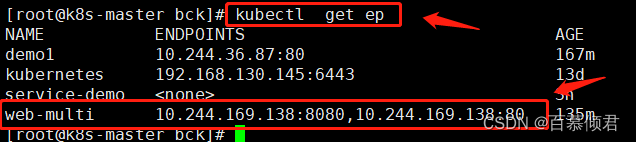
- ep相当于svc的小弟,就相当于rs是deployment的小弟,帮忙连接多个pod。
2.4 常用三种类型
| 类型 | 描述 |
|---|---|
| ClusterIP | 集群内部使用(Pod) |
| NodePort | 对外暴露应用(浏览器) |
| LoadBalancer | 对外暴露应用,将Service映射到一个已存在的负载均衡器的IP地址上,适用公有云 |
| ExternalName | 将Service映射为一个外部域名地址,通过externalName字段进行设置。 |
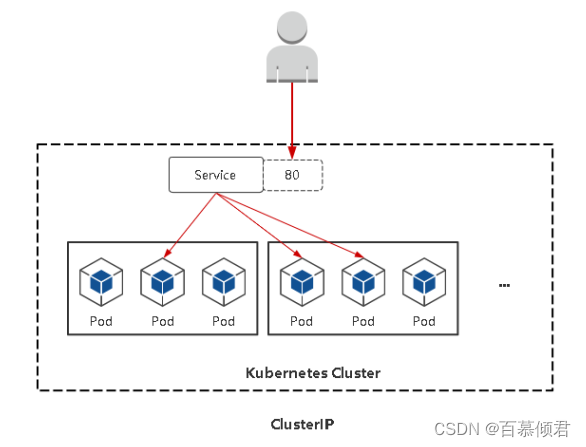
2.4.1 ClusterIP(集群内部访问)
- 作用:默认分配一个稳定的虚拟IP,即VIP,仅可被集群内部的客户端应用访问。
- 原理图:
2.4.2 NodePort(浏览器访问)
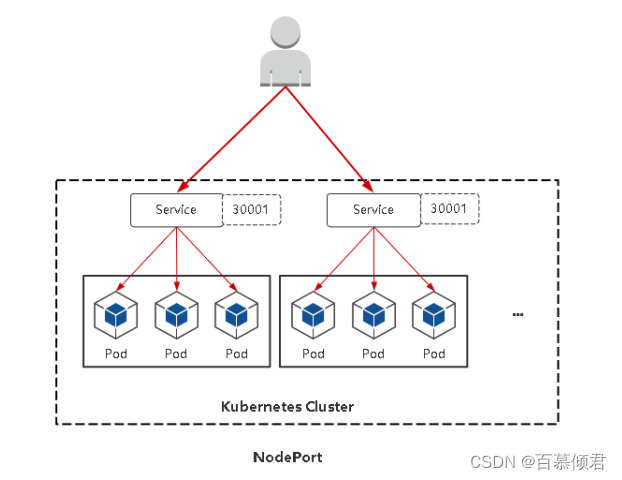
作用:在每个节点上启用一个端口来暴露服务,可以在集群外部访问。也会分配一个稳定内部集群IP地址。
基本常识:
- 访问地址:<任意NodeIP>:
- 端口范围:30000-32767
- 默认情况下,Node的kube-proxy会在全部网卡(0.0.0.0)上绑定NodePort端口号。也可以通过配置启动参数“–nodeport-addresses”指定需要绑定的网卡IP地址,多个地址之间使用逗号分隔。
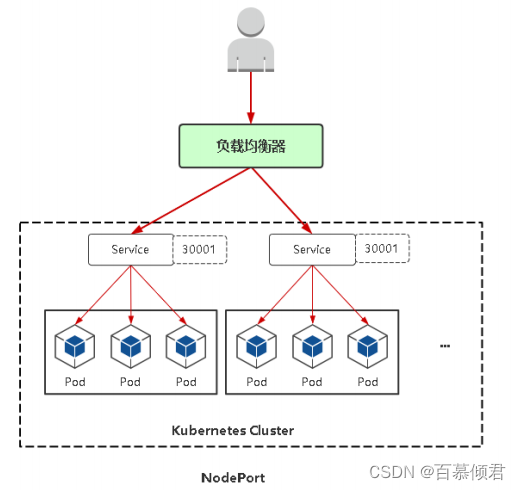
原理图:
注意事项:
- NodePort会在每台Node上监听端口接收用户流量,在实际情况下,对用户暴露的只会有一个IP和端口,那这么多台Node该使用哪台让用户访问呢?
- 这时就需要前面加一个公网负载均衡器为项目提供统一访问入口了。比如在公网机器上部署nginx做负载均衡,配置配置文件upstream ——> 网站A端口30001,upstream2——> 应用服务B端口30002。
- yaml文件配置模板
spec:
type: NodePort ##修改此处
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 30009 ##添加此行,指定端口,也可以不指定,使用随机端口。
selector:
app: web
1.配置svc的yaml文件,指定NodePort类型,使用随机端口。
##这里没有指定端口,后面是随机生成一个端口。
[root@k8s-master bck]# vim svc.yaml
apiVersion: v1
kind: Service
metadata:
name: web-demo1
spec:
ports:
# nginx
- name: 80-80
port: 80
protocol: TCP
targetPort: 80
selector:
app: demo1
type: NodePort ##指定类型。
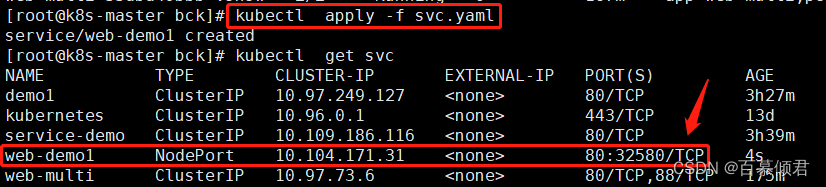
2.导入yaml文件,查看svc随机端口为32580。
3.浏览器访问验证。
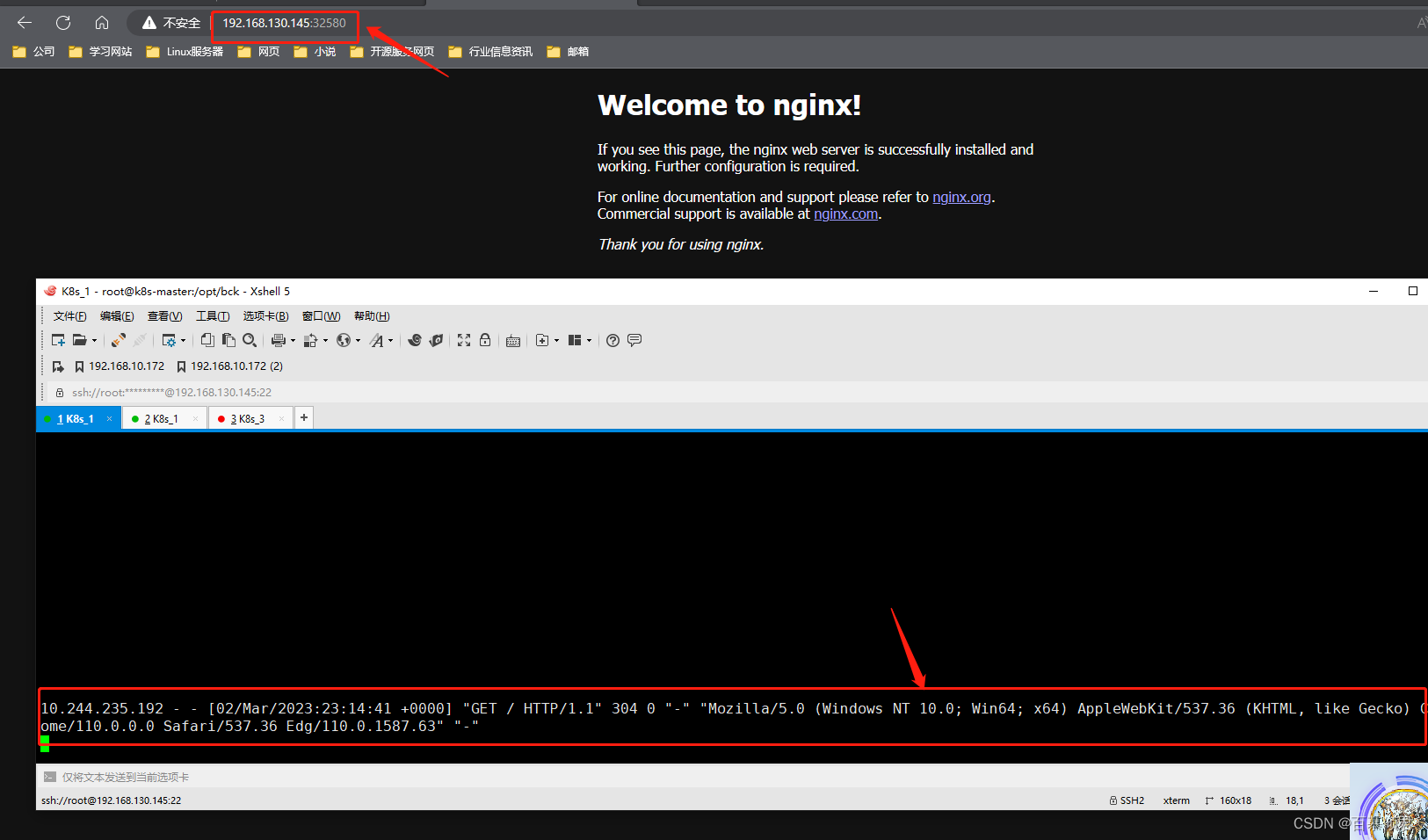
4.使用指定端口。
[root@k8s-master bck]# cat svc.yaml
apiVersion: v1
kind: Service
metadata:
name: web-demo1
spec:
ports:
# nginx
- name: 80-80
port: 80
protocol: TCP
targetPort: 80
nodePort: 30003 ##指定端口。
selector:
app: demo1
type: NodePort ##指定类型。
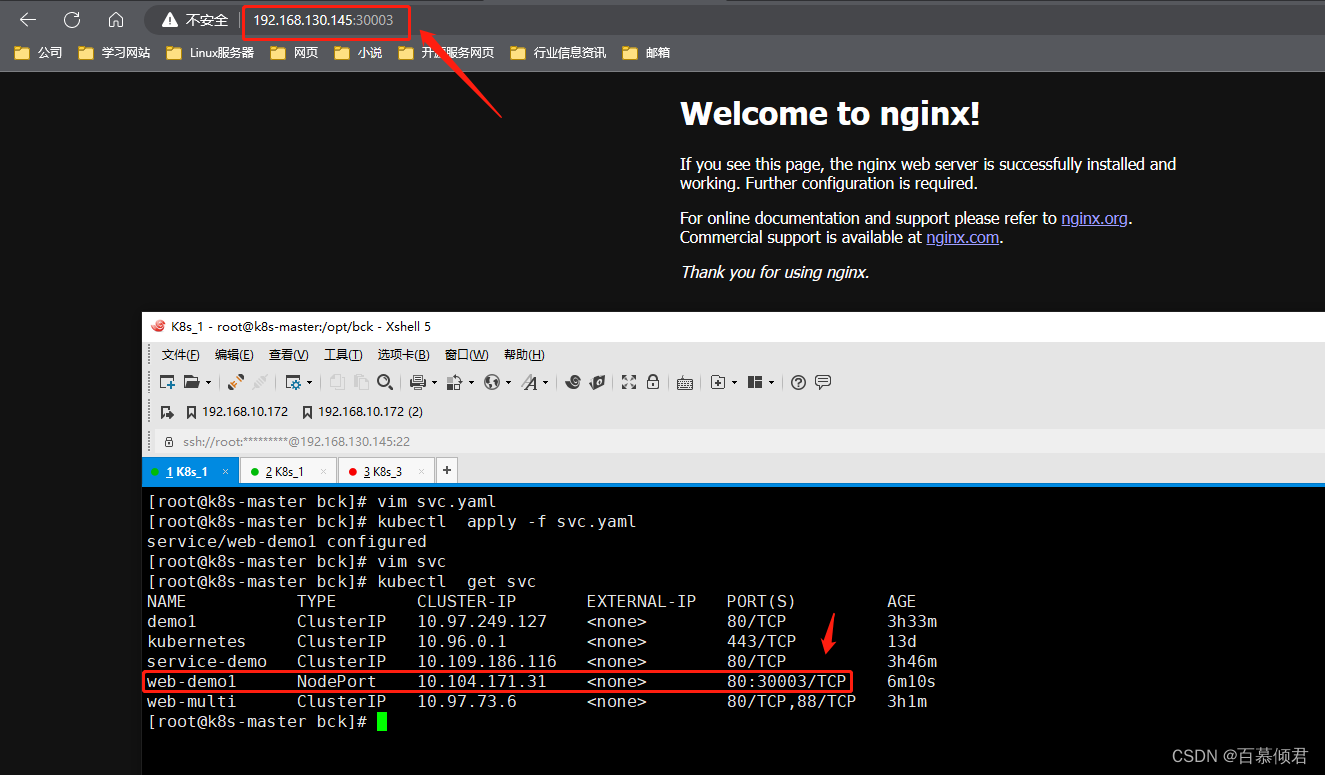
2.4.3 LoadBalancer
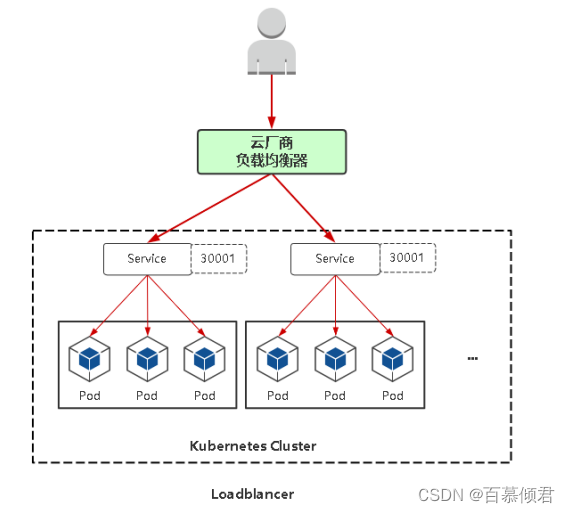
作用:与NodePort类似,在每个节点上启用一个端口来暴露服务。除此之外,Kubernetes会请求底层云平台(例如阿里云、腾讯云、AWS等)上的负载均衡器,将每个Node([NodeIP]:[NodePort])作为后端添加进去。
原理图:
2.5 svc支持的协议
| 协议 | 是否支持 |
|---|---|
| TCP | 默认网络协议,支持所有类型的svc。 |
| UDP | 可用于大多数类型的svc,LoadBalancer类型取决于云服务商对UDP的支持。 |
| HTTP | 取决于云服务商是否支持HTTP和实现机制。 |
| PROXY | 取决于云服务商是否支持HTTP和实现机制。 |
| SCTP | 现已默认启用,如需关闭该特性,则需要设置kube-apiserver的启动参数–feature-gates=SCTPSupport=false进行关闭。 |
- 定义AppProtocol字段,用于标识后端服务在某个端口号上提供的应用层协议类型,例如HTTP、HTTPS、SSL、DNS等。
- 需要设置kube-apiserver的启动参数–feature-gates=ServiceAppProtocol=true进行开启,然后在Service或Endpoint的定义中设置AppProtocol字段指定应用层协议的类型。
三、svc负载均衡
实现原理:
- 当一个Service对象在K8s集群中被定义出来时,集群内的客户端应用就可以通过服务IP访问到具体的Pod容器提供的服务了。从服务IP到后端Pod的负载均衡机制,则是由每个Node上的kube-proxy负责实现的。
实现负载均衡的2种方式:
- kube-proxy的代理模式,通过启动参数–proxy-mode设置。
- 会话保持机制。设置sessionAffinity实现基于客户端IP的会话保持机制,即首次将某个客户端来源IP发起的请求转发到后端的某个Pod上,之后从相同的客户端IP发起的请求都将被转发到相同的后端Pod上。
kube-proxy的代理模式分类:
- userspace模式:用户空间模式,由kube-proxy完成代理的实现,效率最低,不推荐。
- iptables模式:kube-proxy通过设置Linux Kernel的iptables规则,实现从Service到后端Endpoint列表的负载分发规则,效率较高。用此模式时需要给pod设置健康检查,这样可以避免某个后端Endpoint不可用导致客户端请求失败。
- ipvs模式:1.11版本推出,kube-proxy通过设置Linux Kernel的netlink接口设置IPVS规则,转发效率和支持的吞吐率达到最高。ipvs模式要求Linux Kernel启用IPVS模块,如果操作系统未启用IPVS内核模块,kube-proxy则会自动切换至iptables模式。支持负载均衡策略如下:
- rr:round-robin,轮询。
- lc:least connection,最小连接数。
- dh:destination hashing,目的地址哈希。
- sh:source hashing,源地址哈希。
- sed:shortest expected delay,最短期望延时。
- nq:never queue,永不排队。
- kernelspace模式:Windows Server上的代理模式。
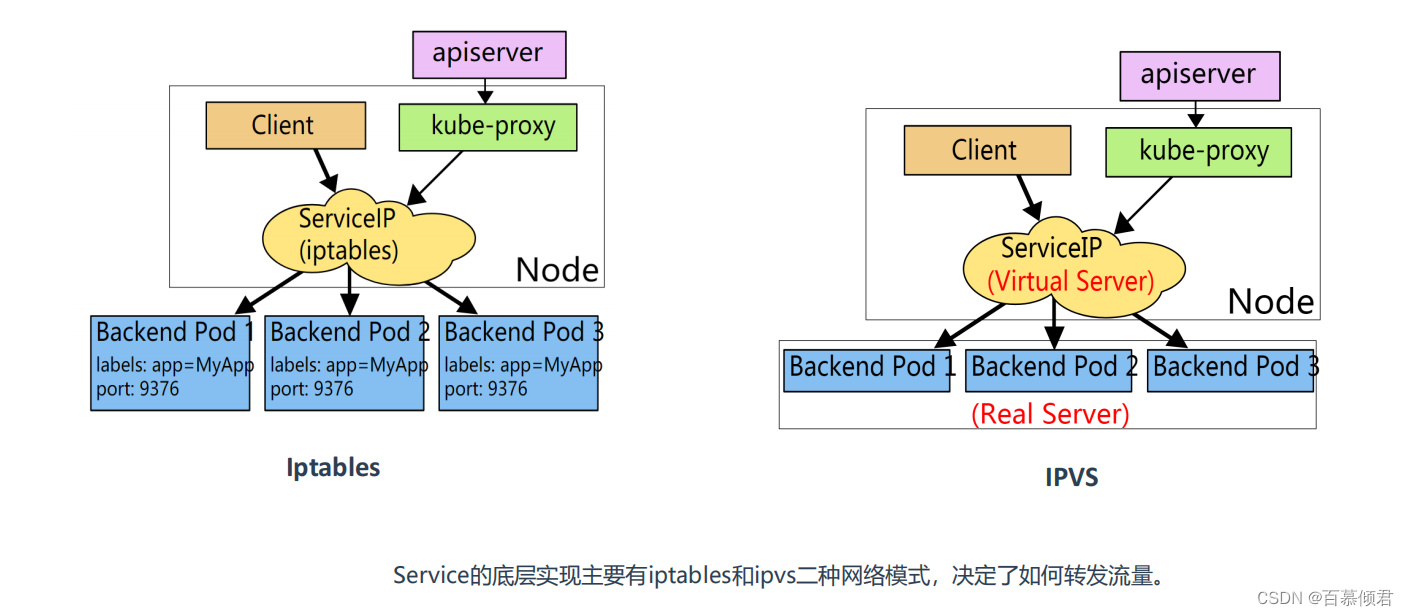
Iptables模式和IPVS模式对比:
- iptables:灵活、功能强大;规则遍历匹配和更新,呈线性时延
- IPVS:工作在内核态,有更好的性能;调度算法丰富:rr,wrr,lc,wlc,ip hash…
概念图:
数据包传输流程:
- 客户端 ->NodePort/ClusterIP(iptables/Ipvs负载均衡规则) -> 分布在各节点Pod
查看负载均衡规则:
- iptables模式:iptables-save |grep < SERVICE-NAME >
- ipvs模式:ipvsadm -L -n
项目流程:
- 项目a:用户——> LB(基于域名分流 a.com) ——> service nodeport 30001 ——> 一组pod(多副本)(相当于项目本身)
- 项目b:用户——> LB(基于域名分流 b.com)——> service nodeport 30002 ——> 一组pod(多副本)(相当于项目本身)
- 项目c:用户——> LB(基于域名分流 c.com)——> service nodeport 30003 ——> 一组pod(多副本)(相当于项目本身)
提问:
- 而这里我们就要看看,我们浏览器访问svc(http://192.168.130.146:30003)是怎么转发到容器内的?
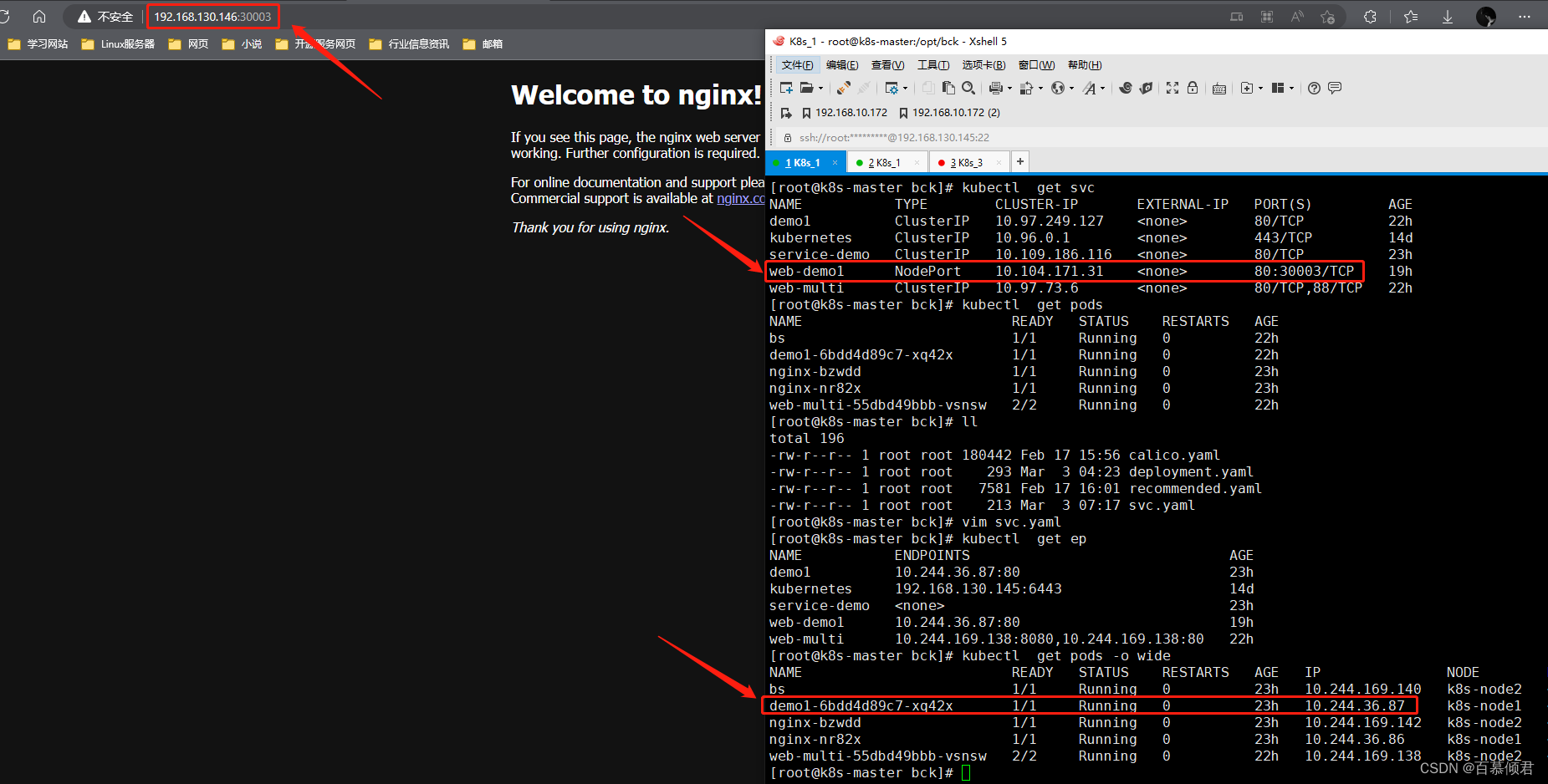
3.1 iptables模式
1.根据svc名称,在工作节点上查看iptables规则。
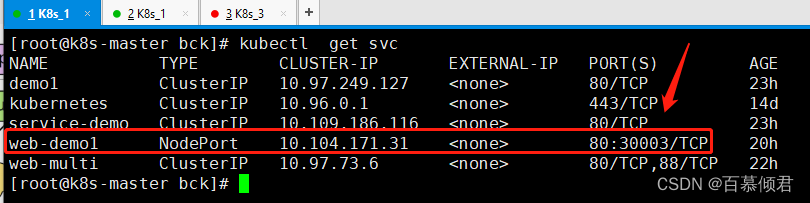

2.将两条规则复制出来分析。(第一步:流量入口)
第一步:浏览器访问30003端口,转发到服务器上的网络协议栈,再转发到该服务器的iptables来处理,根据iptables规则一条条处理。
- -A KUBE-NODEPORTS -p tcp -m comment --comment “default/web-demo1:80-80” -m tcp --dport 30003 -j KUBE-EXT-72T25B5TU2KEWYA6
第二步:处理完第一条规则,再处理第二条,这里就是访问cluster IP,访问pod。
- -A KUBE-SERVICES -d 10.104.171.31/32 -p tcp -m comment --comment “default/web-demo1:80-80 cluster IP” -m tcp --dport 80 -j KUBE-SVC-72T25B5TU2KEWYA6
3.这里给demo1pod扩容增加2个副本,好看出效果。
[root@k8s-master bck]# kubectl scale deployment demo1 --replicas=3
4.根据iptables规则链过滤查看负载均衡结果。(第二步:负载均衡)

1.第一个请求第一个规则的权重概率为33%。
-A KUBE-SVC-72T25B5TU2KEWYA6 -m comment --comment "default/web-demo1:80-80 -> 10.244.169.143:80" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-WNIKZVEWSTDE4VLZ
2.第二个请求第二个规则权重为50%,因为第一个规则已经请求了,就剩第二、第三个请求了。
-A KUBE-SVC-72T25B5TU2KEWYA6 -m comment --comment "default/web-demo1:80-80 -> 10.244.36.87:80" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-ZM2JCM2TG2VXDQG3
3.从第三个请求第三个规则权重为100%,因为此时就剩下最后一条规则,所以请求概率为100%。
-A KUBE-SVC-72T25B5TU2KEWYA6 -m comment --comment "default/web-demo1:80-80 -> 10.244.36.89:80" -j KUBE-SEP-CSYMMWI2AY6NBPWB
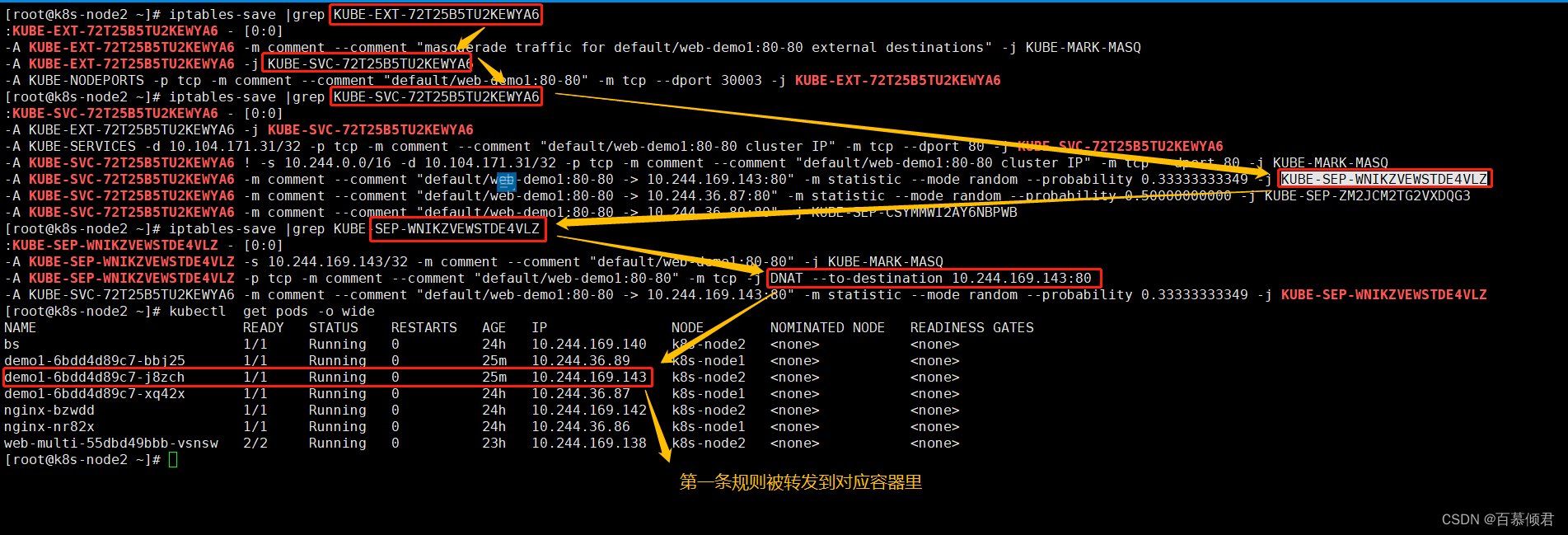
5.查看其中一个规则链,最后转发到对应容器里。(第三步:转发到容器里)
3.2 ipvs模式
- 使用此种模式需要手动去修改,因为默认是iptables模式。不同的k8s集群搭建方式,其修改方式不同。
- kubeadm方式修改ipvs模式:
第一步:修改配置文kube-proxy件参数。 kubectl edit configmap kube-proxy -n kube-system ... mode: “ipvs“ ... 第二步:删除该组Pod,重建所有节点。 kubectl delete pod kube-proxy-btz4p -n kube-system
- 注意事项:
- kube-proxy配置文件以configmap方式挂载存储。
- 如果让所有节点生效,需要重建所有节点kube-proxy pod
- 二进制方式修改ipvs模式:
第一步:编辑修改配置文件。 vi kube-proxy-config.yml mode: ipvs ipvs: scheduler: "rr“ 第二步:重启kube-proxy。 systemctl restart kube-proxy
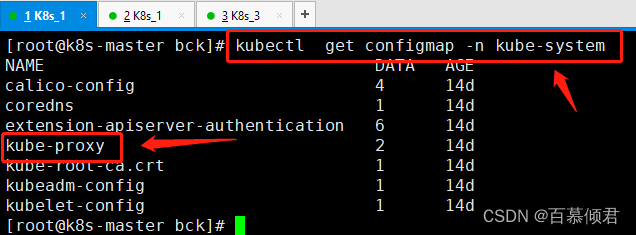
1.查看配置文件位置。
[root@k8s-master bck]# kubectl get configmap -n kube-system
2.在线编辑kube-proxy文件,修改参数为ipvs模式。
[root@k8s-master bck]# kubectl edit configmaps kube-proxy -n kube-system
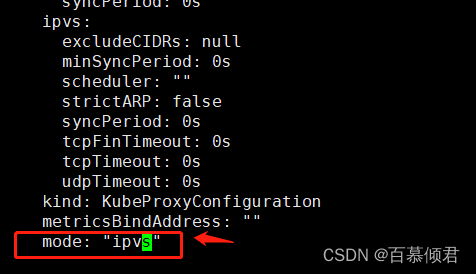
3.此时需要删除这组pod重建,相当于重启。我这里只删除了一个节点,是为了验证对比效果,正常情况下是要重启所有节点的。
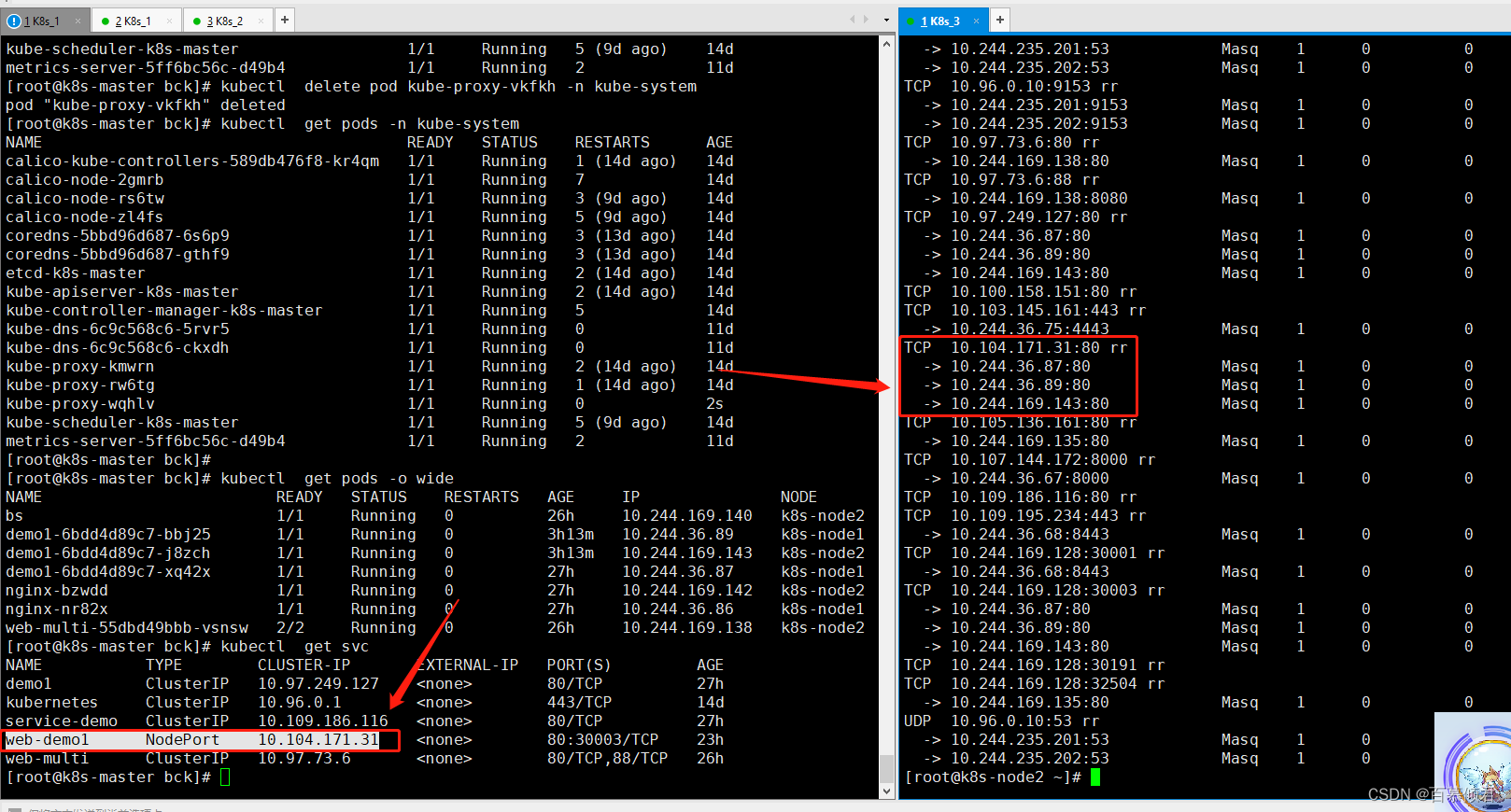
[root@k8s-master bck]# kubectl delete pod kube-proxy-vkfkh -n kube-system
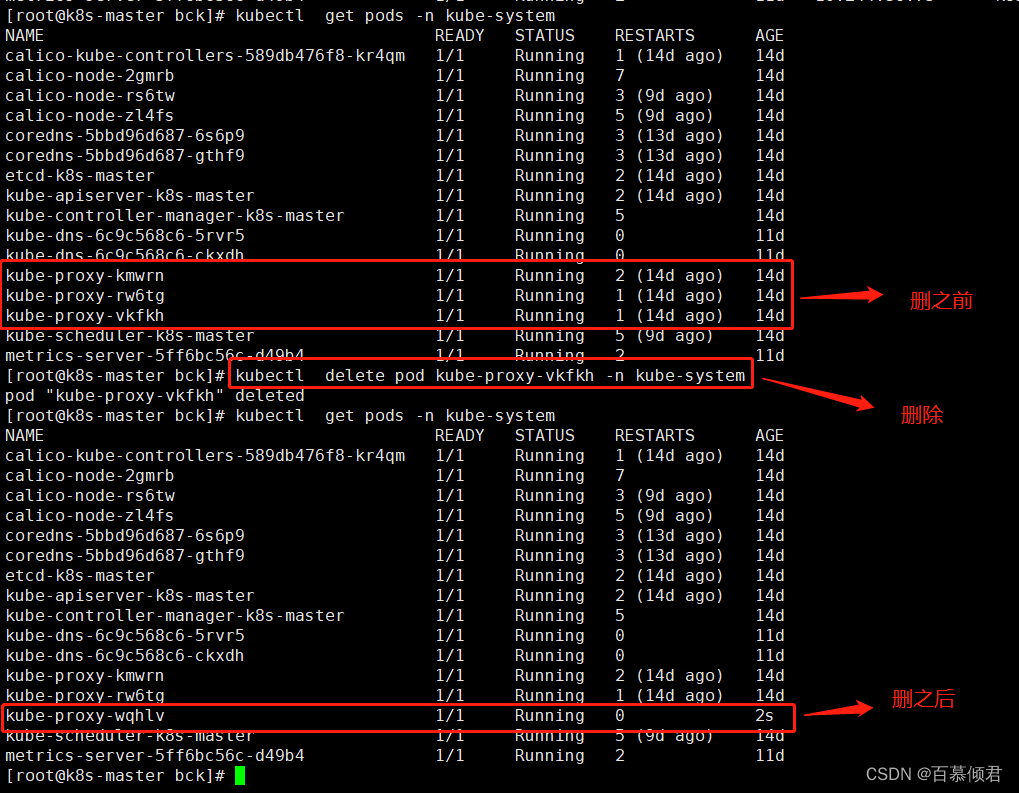
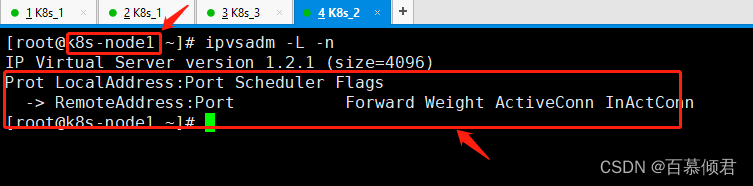
4.在删除的kube-proxy容器所在节点上验证,我这里删除的是node2节点上的kube-proxy,重启后ipvs模式生效;node1节点没有删除,也就没有重启,依然还是iptables模式。使用ipvs模式验证需要安装ipvsadm。
yum -y install ipvsadm
- 查看node1节点没有显示,是因为还是采用的iptables模式。
- 查看node2节点,此时为ipvs模式就显示出路由数据。当访问node2节点IP:30003时,最后路由到列出来的对应容器里。
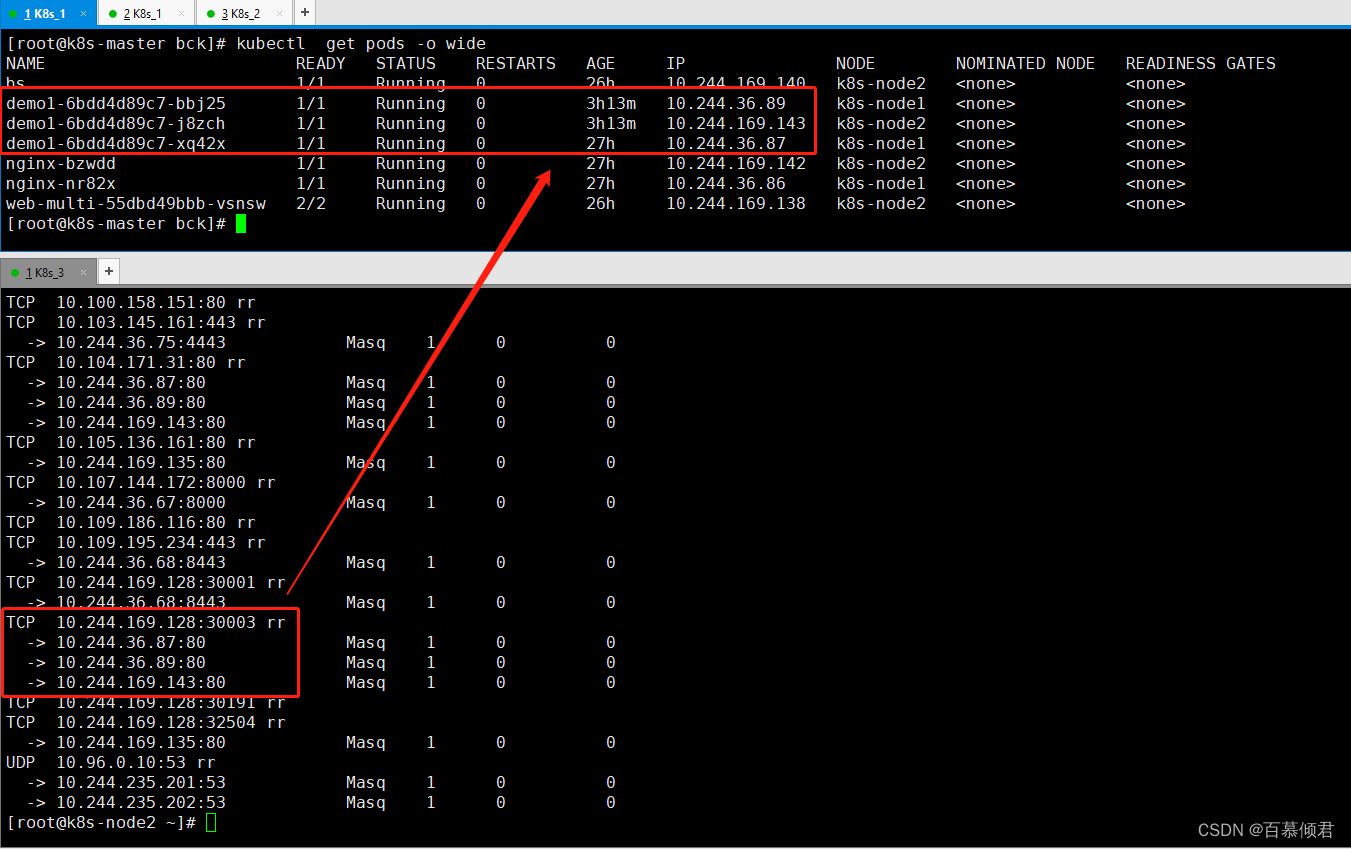
- 访问cluster ip时,就转发到对应的容器里。








![[Pandas] 读取Excel文件](https://img-blog.csdnimg.cn/3112274ca9574ec4b0cc899969cbe515.png)