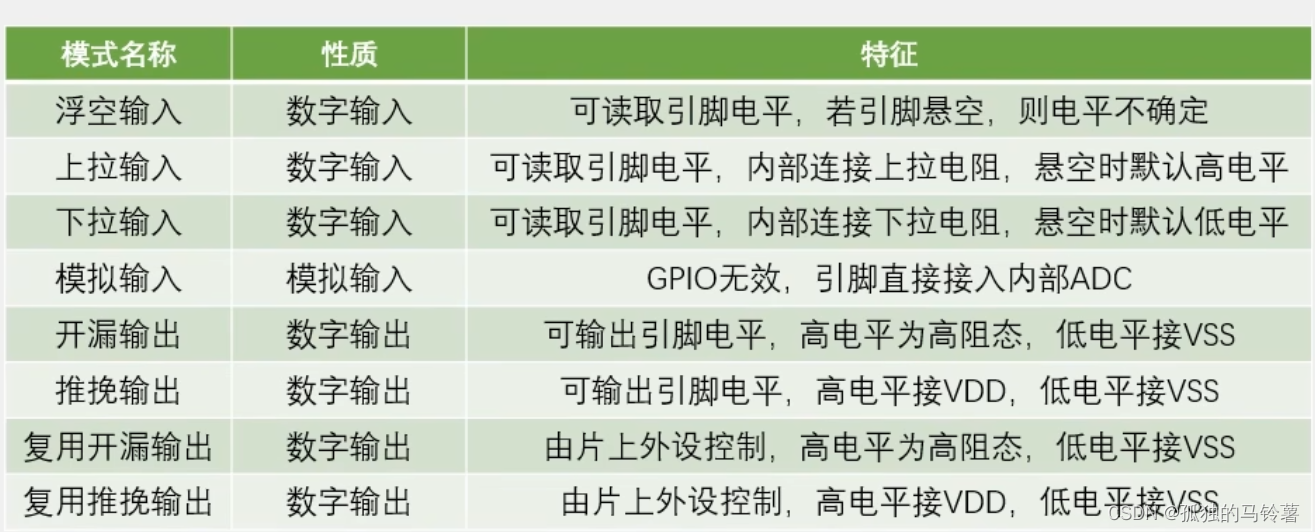
前言
从这篇开始我们进入YOLOv5改进系列。那就先从最简单的添加注意力机制开始吧!( ̄︶ ̄)↗
 【YOLOv5改进系列】前期回顾:
【YOLOv5改进系列】前期回顾:
YOLOv5改进系列(0)——重要性能指标与训练结果评价及分析

目录
前言
🚀一、什么是注意力机制?
🚀二、SE注意力机制原理
2.1 方法介绍
2.2 网络结构
🚀 三、添加SE注意力机制方法
3.1 添加顺序
3.2 具体添加步骤
第①步:在common.py中添加SE模块
第②步:在yolo.py文件里的parse_model函数加入类名
第③步:创建自定义的yaml文件
第④步:验证是否加入成功
第⑤步:修改train.py中 ‘--cfg’默认参数
🌟本人YOLOv5系列导航

🚀一、什么是注意力机制?
我们先来看一张图片,这个是前段时间微博之夜的

那大家的目光更多停留在是在五个美女身上,还是在张大大身上呢 ?(大大老师骚瑞~ORZ)
同样的,不同的粉丝更加关注的对象也是不同的。
再举几个栗子:
看人-->看脸
看文章-->看标题
看段落-->看开头
这时候大家应该大致知道注意力机制是个什么东西了吧~
原理
注意力机制其实是源自于人对于外部信息的处理能力。由于人每一时刻接受的信息都是无比的庞大且复杂,远远超过人脑的处理能力,因此人在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤,这种处理方式被称为注意力机制。
我用通俗的大白话解释一下:注意力呢,对于我们人来说可以理解为“关注度”,对于没有感情的机器来说其实就是赋予多少权重(比如0-1之间的小数),越重要的地方或者越相关的地方就赋予越高的权重。
作用
- 1.提高模型的准确性: 注意力机制可以帮助模型更好地关注重要的信息,从而提高模型的准确性。
- 2.模型解释性更强: 注意力机制可以让模型更好地解释其决策过程,从而提高模型的可解释性。
- 3.可以处理不定长的序列数据: 注意力机制可以处理不定长的序列数据,比如文本数据、语音数据等。
不足
- 1.计算量大:注意力机制需要计算每个位置的权重,因此计算量较大,训练时间较长。
- 2.可能出现过拟合: 如果注意力机制的权重过于复杂,可能会导致过拟合的问题。
- 3.可能需要更多的数据: 注意力机制需要更多的数据来训练和优化,否则可能会出现欠拟合的问题。
更多关于注意力机制的讲解,欢迎大家看我的这篇文章(自认为写的还行):【Transformer系列(2)】注意力机制、自注意力机制、多头注意力机制、通道注意力机制、空间注意力机制超详细讲解
🚀二、SE注意力机制原理
本人的SE论文精读:经典神经网络论文超详细解读(七)——SENet(注意力机制)学习笔记(翻译+精读+代码复现)
本人的SE代码复现:SENet代码复现+超详细注释(PyTorch)
2.1 方法介绍
SE注意力机制(Squeeze-and-Excitation Networks)在通道维度增加注意力机制,关键操作是squeeze和excitation。
通过自动学习的方式,使用另外一个新的神经网络,获取到特征图的每个通道的重要程度,然后用这个重要程度去给每个特征赋予一个权重值,从而让神经网络重点关注某些特征通道。提升对当前任务有用的特征图的通道,并抑制对当前任务用处不大的特征通道。
如下图所示,在输入SE注意力机制之前,特征图的每个通道的重要程度都是一样的,通过SENet之后,不同颜色代表不同的权重,使每个特征通道的重要性变得不一样了,使神经网络重点关注某些权重值大的通道。
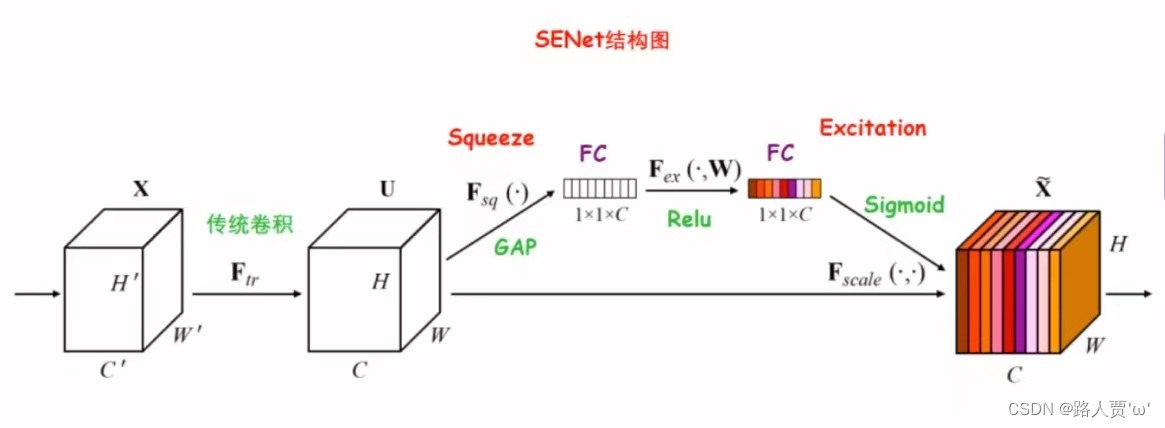
2.2 网络结构
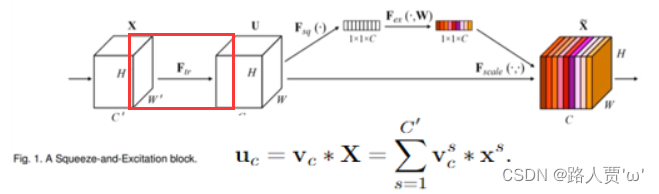
1.Ftr—传统卷积操作:对于一个C×W×H的输入X,在经过Ftr卷积操作之后,得到的输出Uc(也就是C个大小为H×W的特征图)
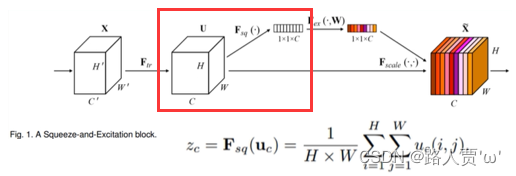
2.Fsq—压缩:Fsq操作就是使用通道的全局平均池化,将包含全局信息的W×H×C的特征图直接压缩成一个1×1×C的特征向量,即将每个二维通道变成一个具有全局感受野的数值,此时1个像素表示1个通道,屏蔽掉空间上的分布信息,更好的利用通道间的相关性。

3.Fex—激励:采用两个全连接层+两个激活函数组成的结构输出和输入特征同样数目的权重值,也就是每个特征通道的权重系数。
(1)第一个FC层:ReLU (δ)
(2)第二个FC层:Sigmoid(σ)
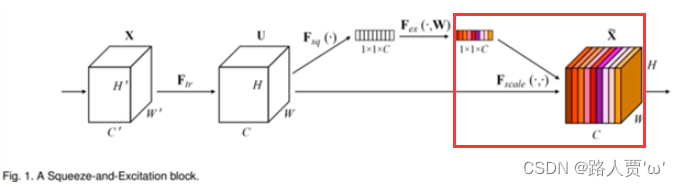
4.Fscale —权重:将Excitation输出的权重看做每个特征通道的重要性,也就是对于U每个位置上的所有H×W上的值都乘上对应通道的权值,完成对原始特征的重校准。
🚀 三、添加SE注意力机制方法
在介绍方法前我们先来回顾一下YOLOv5内一会儿要修改的文件:
models/common.py:这个文件存放着YOLOv5网络搭建常见的通用模块。如果我们需要修改某一模块,那么就需要修改这个文件中对应模块的定义。
models/yolo.py:这是YOLO的特定模块,和网络构建有关。这个文件主要由三个部分:parse_model函数、Detect类和Model类组成。其中parse_model方法是对网络结构进行整体搭建,同时起到注册common.py中各类模块的作用。
models/yolov5s.yaml(以s结构为例):网络的配置文件,models/yolo.py依据这个配置文件中的信息对整体网络进行构建。YOLOv5s网络是YOLOv5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。
3.1 添加顺序
(1)models/common.py --> 加入新增的网络结构
(2) models/yolo.py --> 设定网络结构的传参细节,将SE类名加入其中。(当新的自定义模块中存在输入输出维度时,要使用qw调整输出维度)
(3) models/yolov5*.yaml --> 新建一个文件夹,如yolov5s_SE.yaml,修改现有模型结构配置文件。(当引入新的层时,要修改后续的结构中的from参数)
(4) train.py --> 修改‘--cfg’默认参数,训练时指定模型结构配置文件
3.2 具体添加步骤
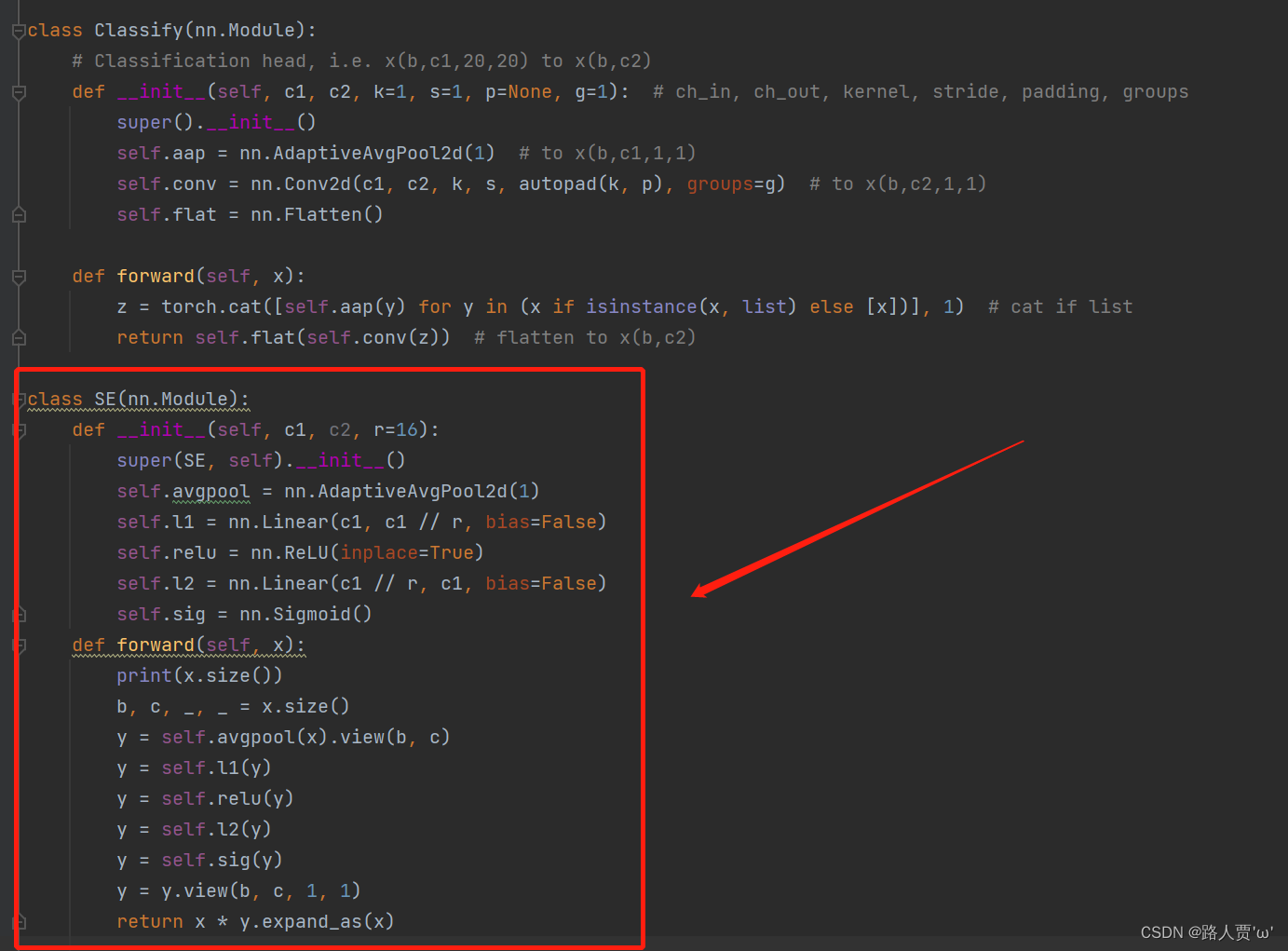
第①步:在common.py中添加SE模块
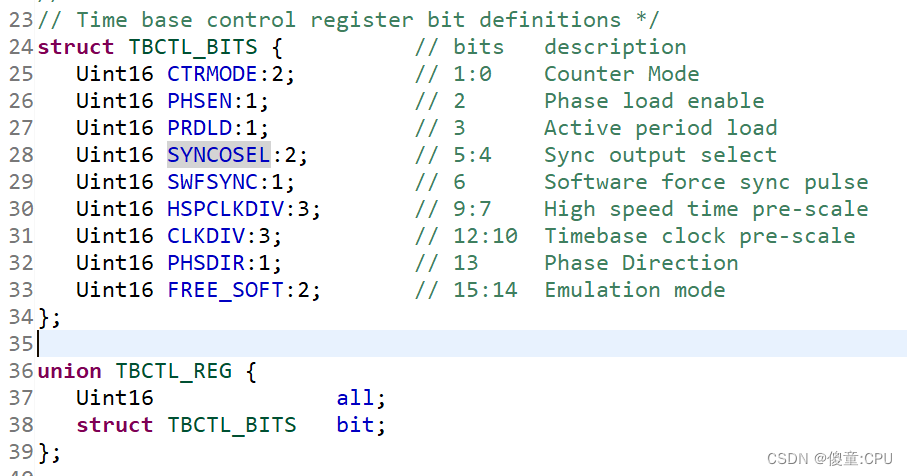
将下面的SE代码复制粘贴到common.py文件的末尾
class SE(nn.Module):
def __init__(self, c1, c2, r=16):
super(SE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
print(x.size())
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)如下图所示:
第②步:在yolo.py文件里的parse_model函数加入类名
首先找到yolo.py里面parse_model函数的这一行
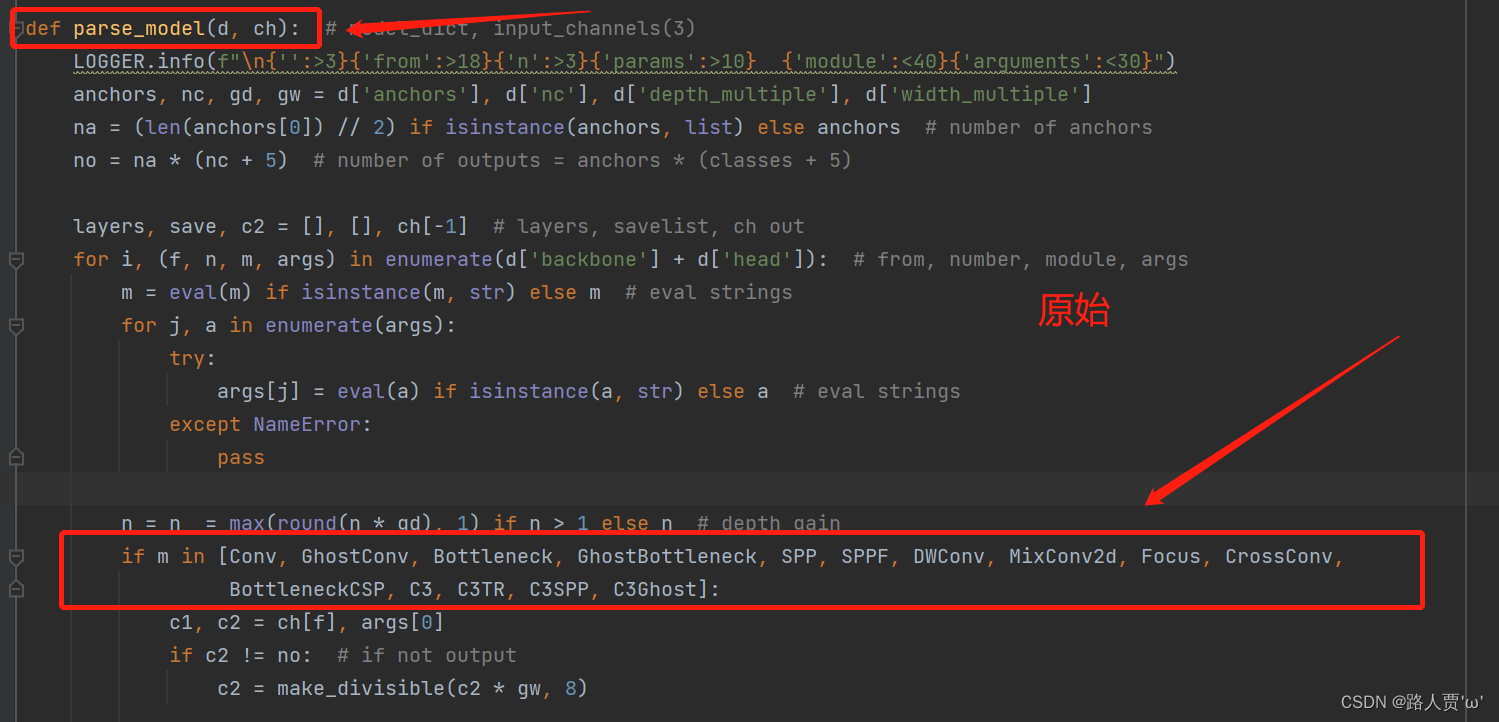
然后把SE添加到这个注册表里面
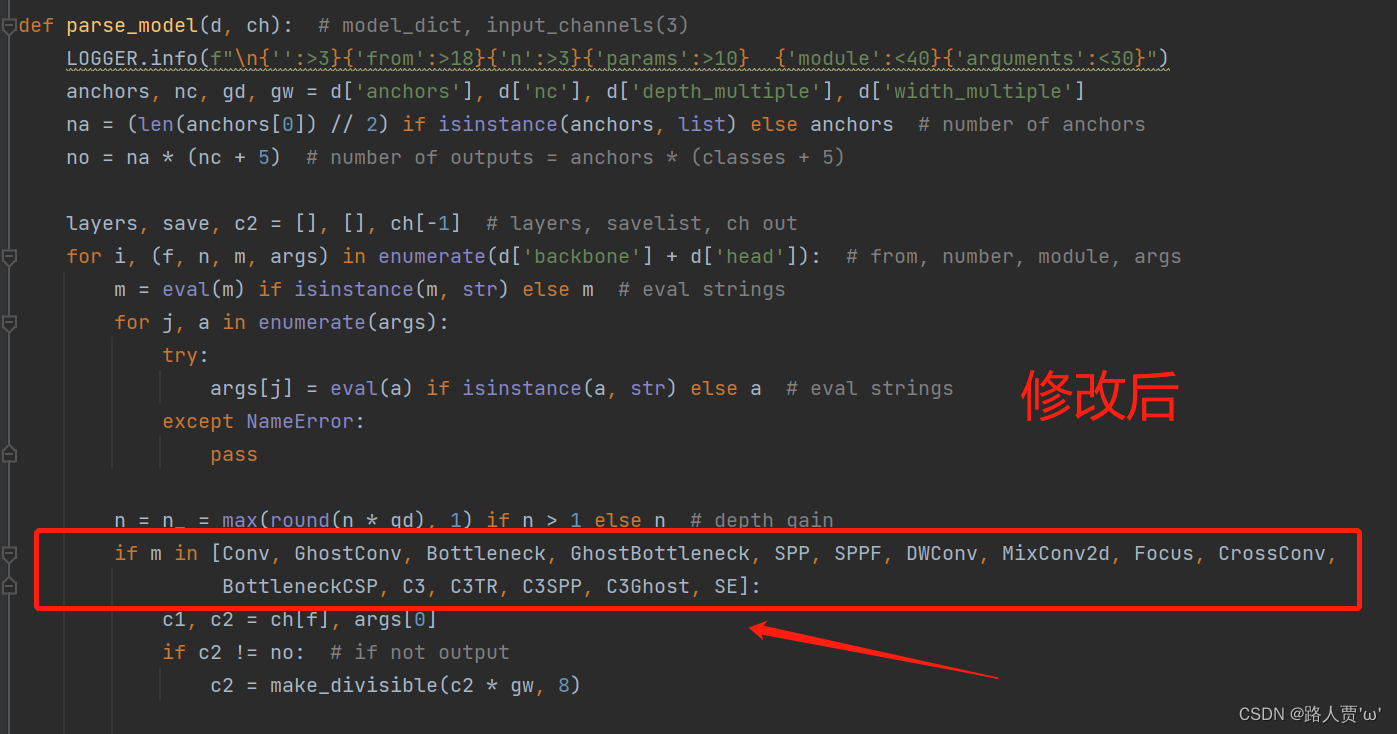
第③步:创建自定义的yaml文件
首先在models文件夹下复制yolov5s.yaml 文件,粘贴并重命名为 yolov5s_SE.yaml
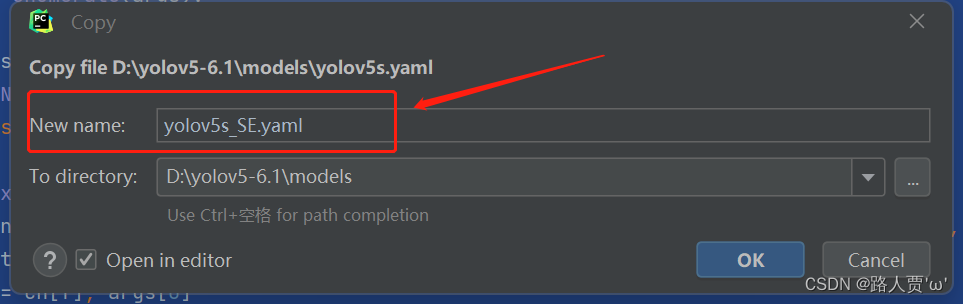
接着修改 yolov5s_SE.yaml ,将 SE加到我们想添加的位置。
注意力机制可以添加在backbone,Neck,Head等部分, 常见的有两种:一是在主干的 SPPF 前添加一层;二是将backbone中的C3全部替换。不同的位置效果可能不同,需要我们用数据集反复测试,“调参大师”就是这样诞生的~
在这里我是用第一种:将 [-1,1,SE,[1024]]添加到 SPPF 的上一层,即下图中所示位置:
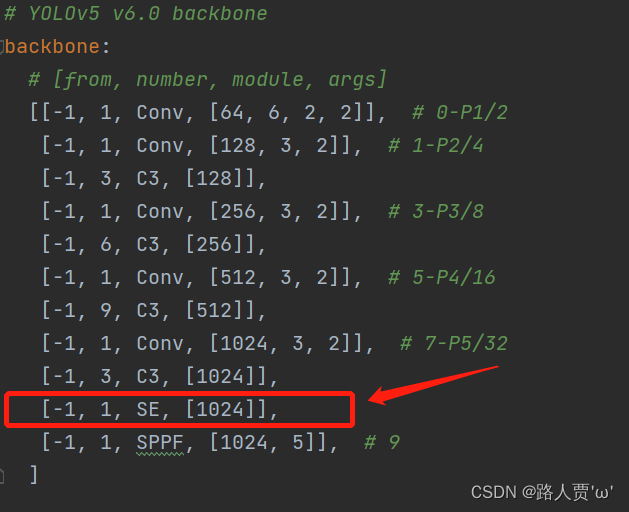
这里回顾一下[from, number, module, args]四个参数含义:
- from : 表示当前模块的输入来自那一层的输出,-1表示将上一层的输出当做自己的输入(第0层的-1表示输入的图像)。
- number: 表示当前模块的重复次数,实际的重复次数还要由上面的参数depth_multiple共同决定,决定网络模型的深度。
- module: 表示该层模块的名称,这些模块写在common.py中,进行模块化的搭建网络。
- args: 表示类的初始化参数,用于解析作为 moudle 的传入参数,会在网络搭建过程中根据不同层进行改变。
这时要注意一个问题:
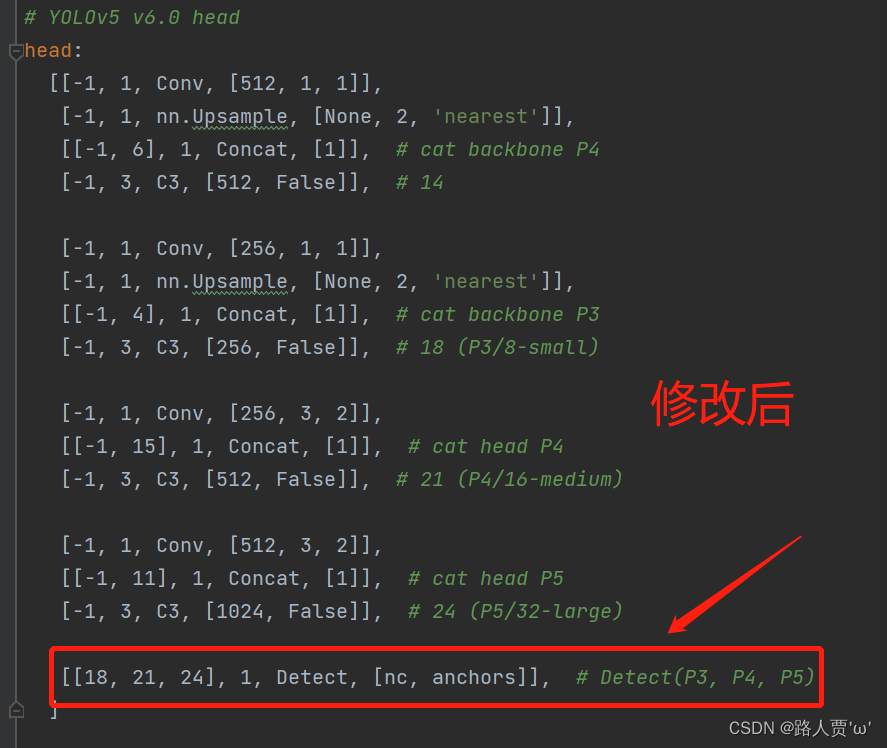
当在网络中添加了新的层之后,那么该层网络后续的层的编号都会发生改变,原本Detect指定的是[ 17 , 20 , 23 ]层,所以在我们添加了SE注意力层之后也要Detect对这里进行修改,即原来的17层变成了18 层;原来的20层变成了21 层;原来的23层变成了24 层;所以Detecet的from系数要改为[ 18 , 21 , 24 ] 。如下图所示:
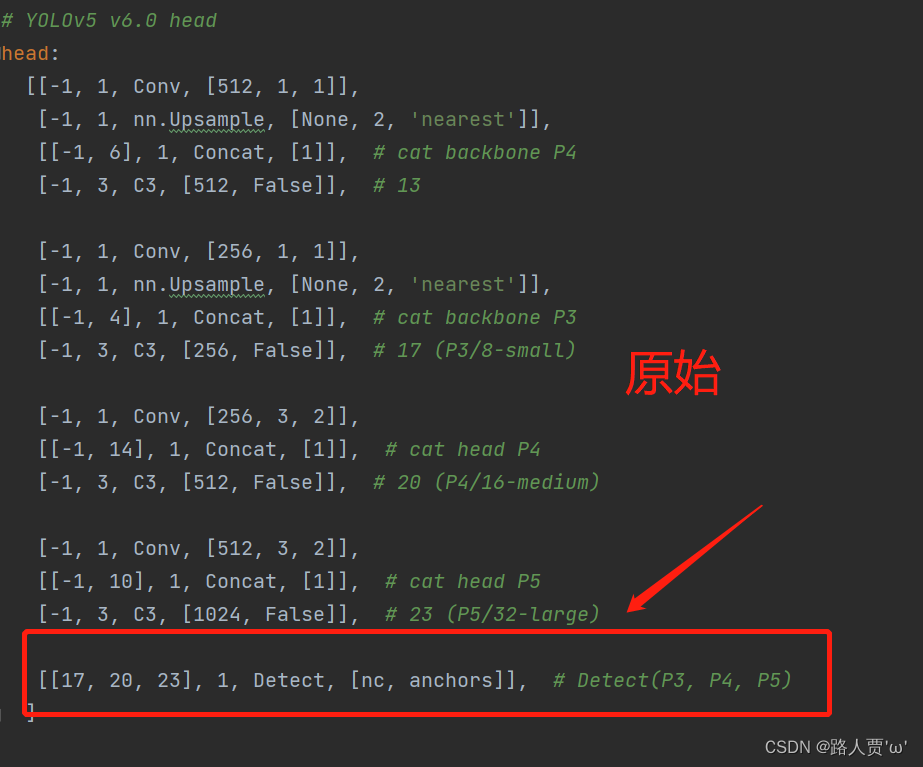
修改后:
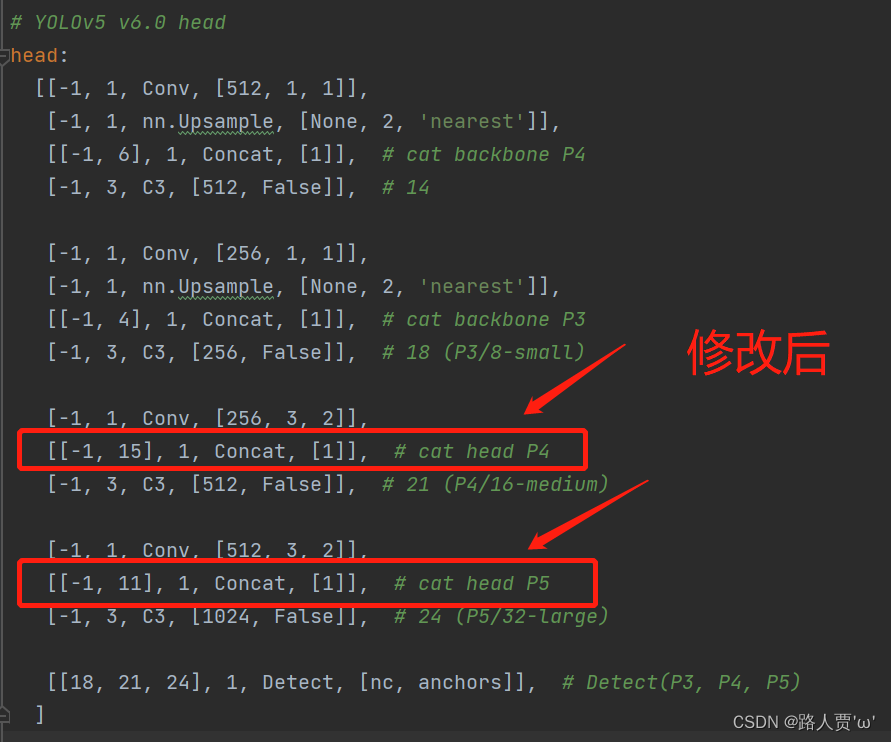
同样的,Concat的from系数也要修改,这样才能保持原网络结构不发生特别大的改变,我们刚才把SE层加到了第9层,所以第9层之后的编号都会加1,这里我们要把后面两个Concat的from系数分别由[ − 1 , 14 ] , [ − 1 , 10 ]改为[ − 1 , 15 ] , [ − 1 , 11 ]。如下图所示:
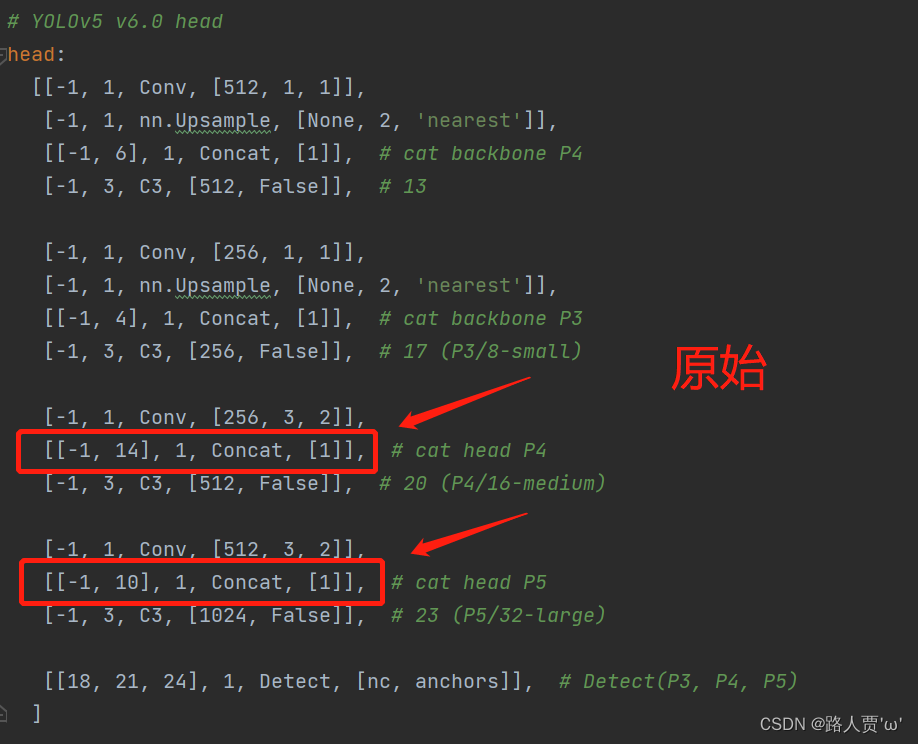
修改后:
第④步:验证是否加入成功
在yolo.py 文件里面配置改为我们刚才自定义的yolov5s_SE.yaml
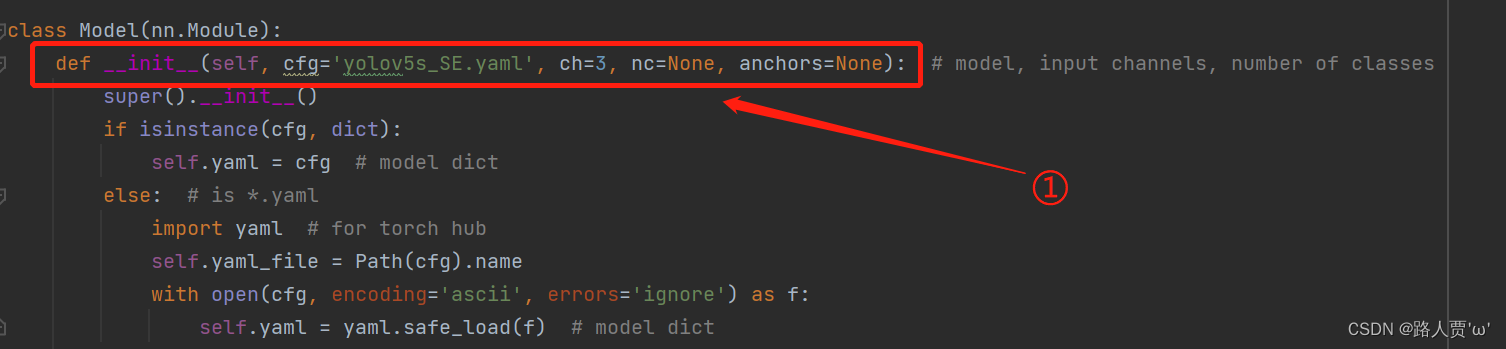
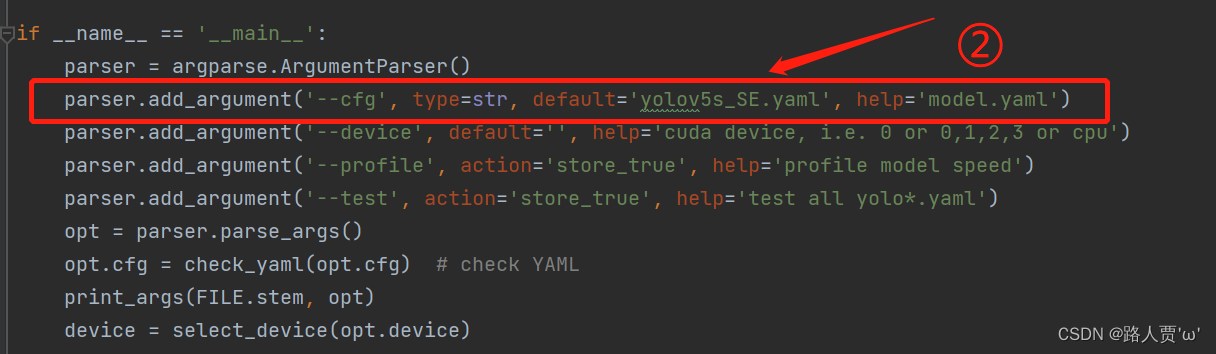
然后运行yolo.py
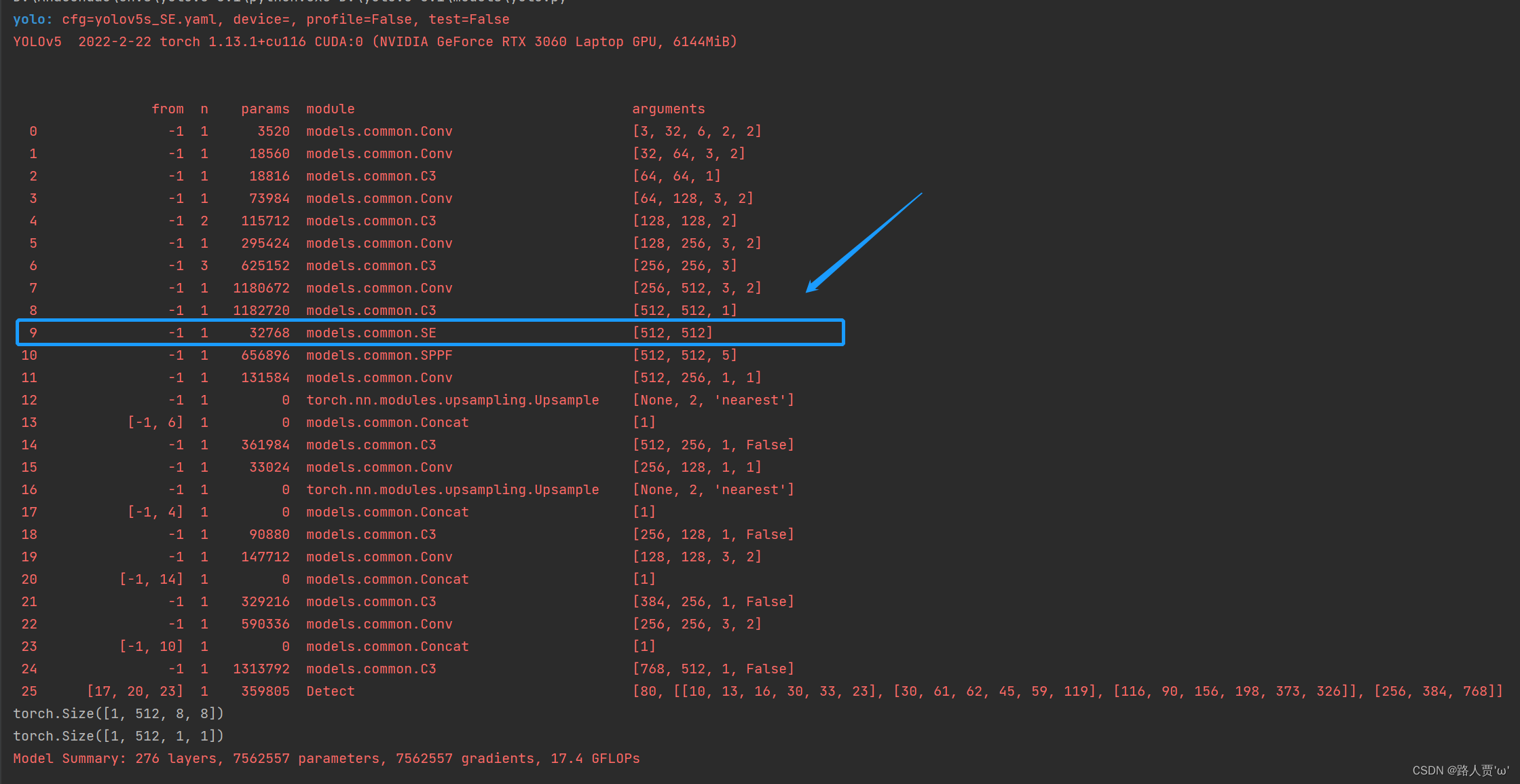
找到SE模块,就说明我们添加成功啦!
第⑤步:修改train.py中 ‘--cfg’默认参数
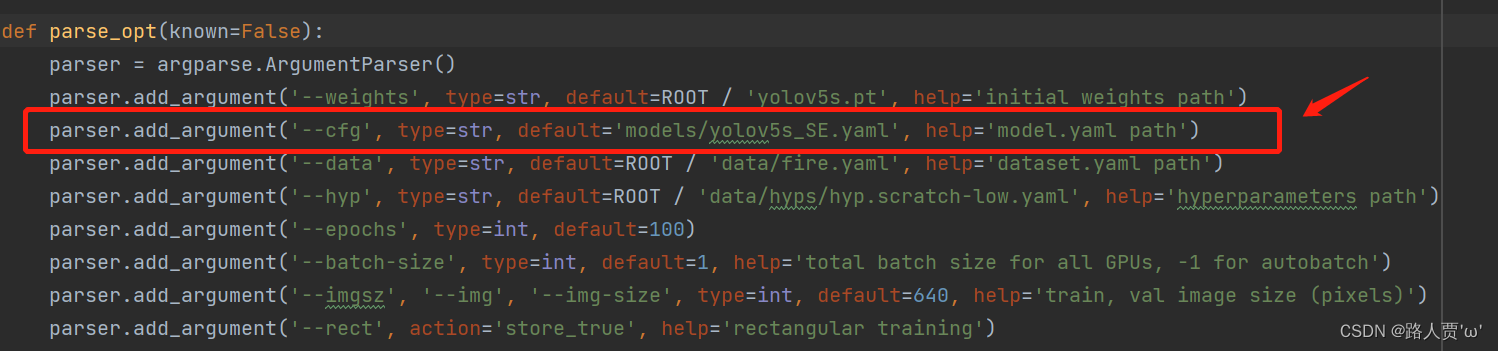
我们先找到 train.py 文件的parse_opt函数,然后将第二行‘--cfg’的 default改为'models/yolov5s_SE.yaml',然后就可以开始训练啦~
完结~撒花✿✿ヽ(°▽°)ノ✿
🌟本人YOLOv5系列导航
🍀YOLOv5源码详解系列:
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
YOLOv5源码逐行超详细注释与解读(5)——配置文件yolov5s.yaml
YOLOv5源码逐行超详细注释与解读(6)——网络结构(1)yolo.py
YOLOv5源码逐行超详细注释与解读(7)——网络结构(2)common.py
🍀YOLOv5入门实践系列:
YOLOv5入门实践(1)——手把手带你环境配置搭建
YOLOv5入门实践(2)——手把手教你利用labelimg标注数据集
YOLOv5入门实践(3)——手把手教你划分自己的数据集
YOLOv5入门实践(4)——手把手教你训练自己的数据集
YOLOv5入门实践(5)——从零开始,手把手教你训练自己的目标检测模型(包含pyqt5界面)
本文参考(感谢大佬们):
CSDN:手把手带你YOLOv5/v7 添加注意力机制(并附上30多种顶会Attention原理图)2023/2/11更新迪菲赫尔曼的博客-CSDN博客
b站:【YOLOv5 v6.1添加SE,CA,CBAM,ECA注意力机制教学,即插即用】




![[Pandas] 读取Excel文件](https://img-blog.csdnimg.cn/3112274ca9574ec4b0cc899969cbe515.png)