LRU Cache
- 📖1. 什么是LRU Cache
- 📖2. 为什么需要LRU算法?
- 📖3. LRU Cache的实现
📖1. 什么是LRU Cache
LRU是Least Recently Used的缩写,意思是最近最少使用. 它是一种Cache替换算法.
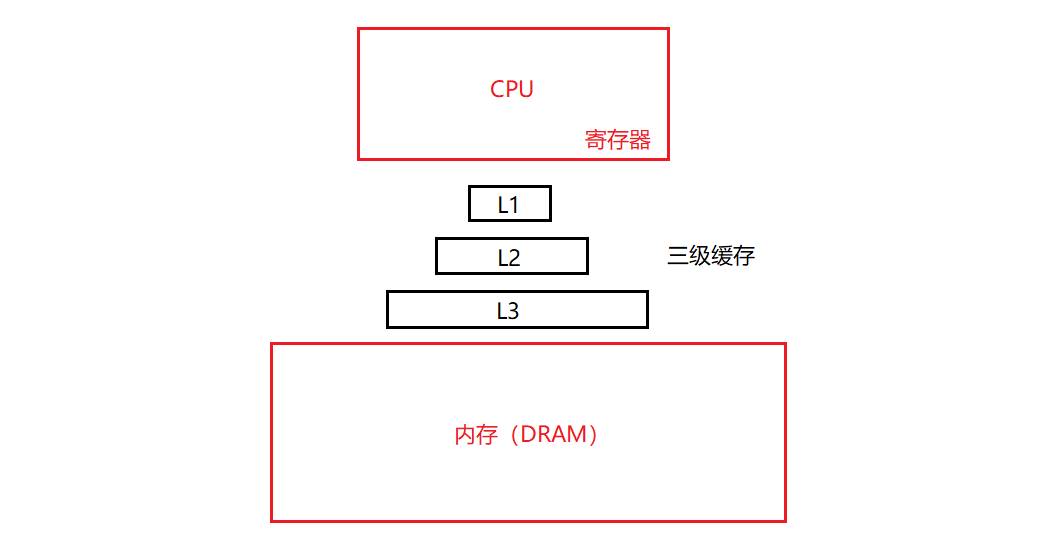
什么是Cache?
狭义的Cache是指位于CPU和主存之间的快速RAM,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术. 广义上的Cache指的是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构. 除了CPU与主存之间有Cache,内存与硬盘之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache-称为Internet临时文件或网络内容缓存等.
📖2. 为什么需要LRU算法?
Cache的容量有限,因此当Cache的容量用完后(其实它不会真的用完,会有一个水位线,如果剩余容量低于这个水位线就需要执行LRU算法),而又有新的内容要添加进来时,就需要挑选并舍弃原有的部分内容,从而腾出空间来放新内容. LRU Cache的替换原则就是将最近最少使用的内容替换掉.
其实,LRU译成最久未使用会更形象,因为该算法每次替换掉的就是一段时间内最近没使用过的内容.
📖3. LRU Cache的实现
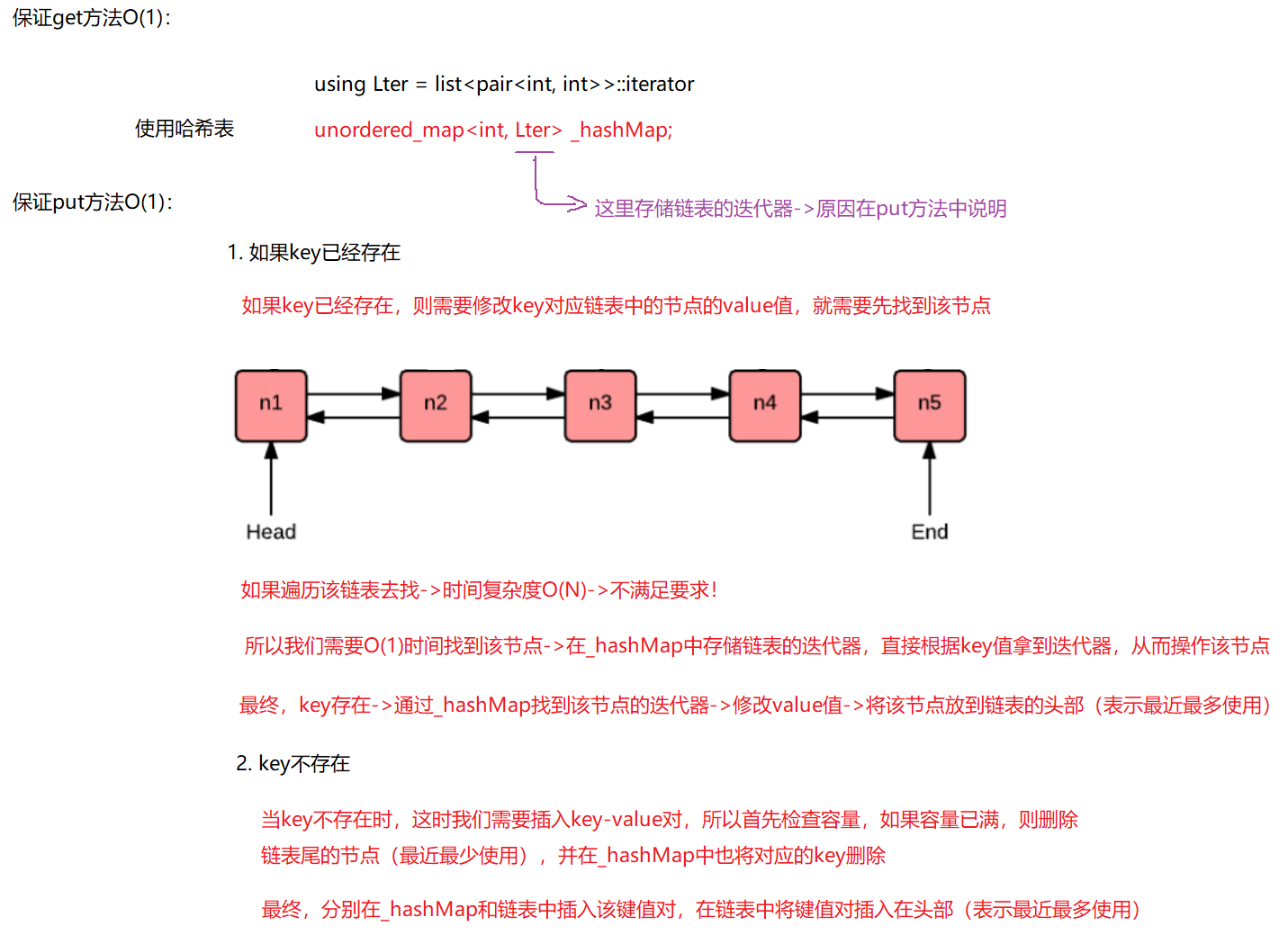
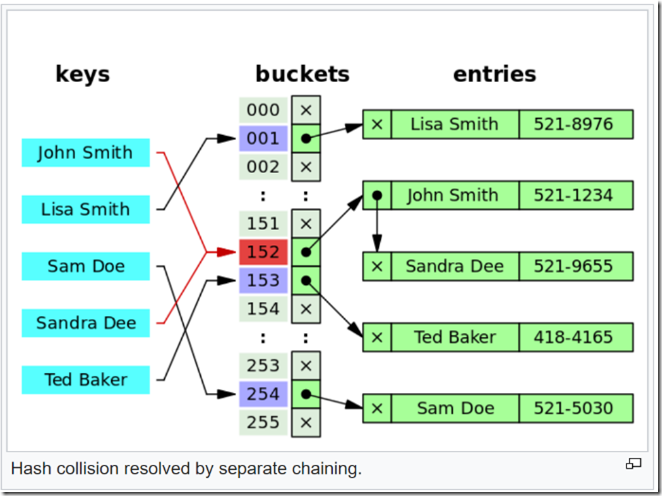
实现LRU Cache的方法和思路很多,但是要保持高效实现O(1)的put和get,那么使用双向链表和哈希表的搭配是最高效和经典的. 使用双向链表是因为双向链表可以实现任意位置O(1)的插入和 删除,使用哈希表是因为哈希表的增删查改也是O(1).
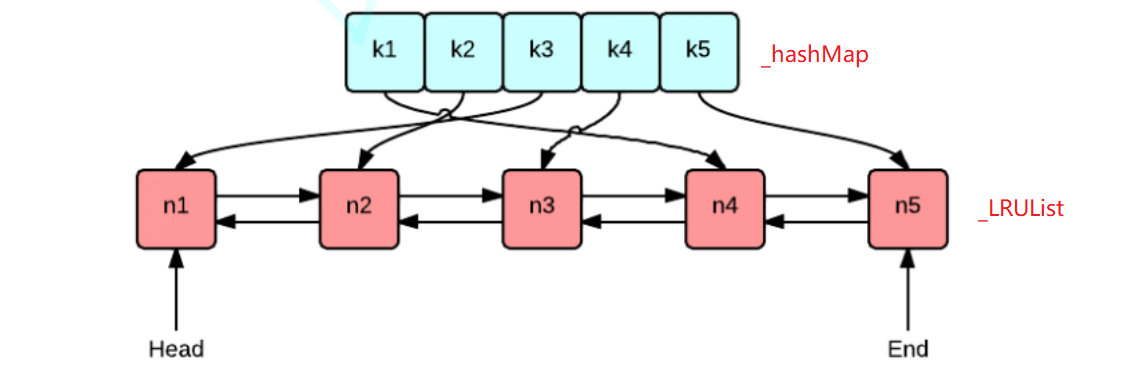
LRU设计要求:

LRU算法分析过程:
最终实现代码:
class LRUCache {
using Lter = list<pair<int, int>>::iterator;
public:
LRUCache(int capacity)
:_capacity(capacity)
{}
int get(int key)
{
auto ret = _hashMap.find(key);
if(ret != _hashMap.end())
{
//找到了
Lter it = ret->second; //拿到了指向链表的迭代器
_LRUList.splice(_LRUList.begin(), _LRUList, it);
return it->second;
}
return -1;
}
void put(int key, int value)
{
auto ret = _hashMap.find(key);
if(ret != _hashMap.end())
{
//修改value值即可
Lter it = ret->second; //拿到链表迭代器
it->second = value;
//将当前key节点移至链表开头
_LRUList.splice(_LRUList.begin(), _LRUList, it);
}
else
{
//检查容量
if(_hashMap.size() == _capacity)
{
pair<int, int> back = _LRUList.back();
_LRUList.pop_back();
_hashMap.erase(back.first);
}
//添加key-value对
_LRUList.push_front({key, value});
_hashMap[key] = _LRUList.begin();
}
}
private:
unordered_map<int, Lter> _hashMap;
list<pair<int, int>> _LRUList;
int _capacity;
};


![[附源码]计算机毕业设计springboot咖啡销售平台](https://img-blog.csdnimg.cn/d8b39b105c684714a1dcfd6e738cb930.png)



![[附源码]计算机毕业设计springboot拉勾教育课程管理系统](https://img-blog.csdnimg.cn/2979b3c094b9420db4d9f939efb3aa0d.png)

![[附源码]Python计算机毕业设计Django的文成考研培训管理系统](https://img-blog.csdnimg.cn/a91adbc05a72486d9d2abf220033f58c.png)



![[附源码]Python计算机毕业设计Django的玉石交易系统](https://img-blog.csdnimg.cn/2c117505bb3c439f8a6ecdfd6234c089.png)
