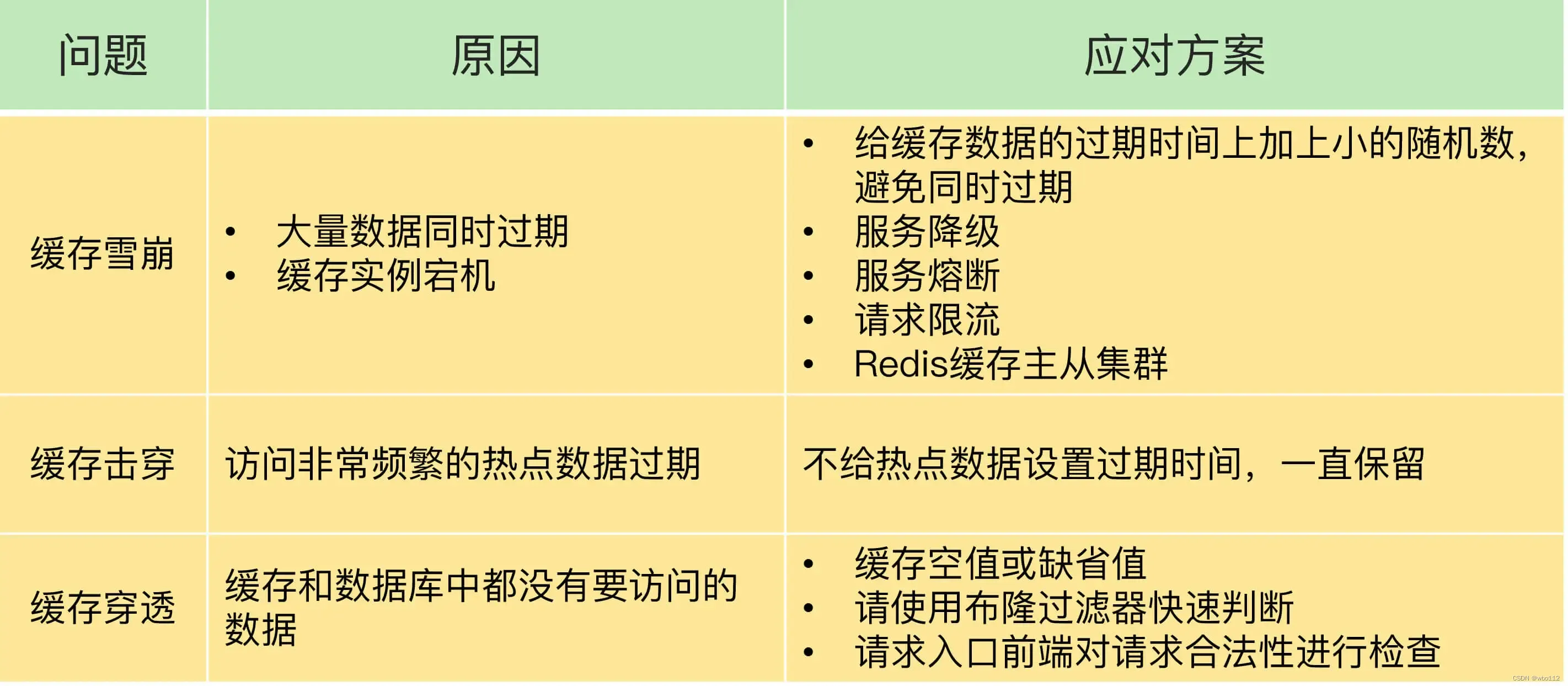
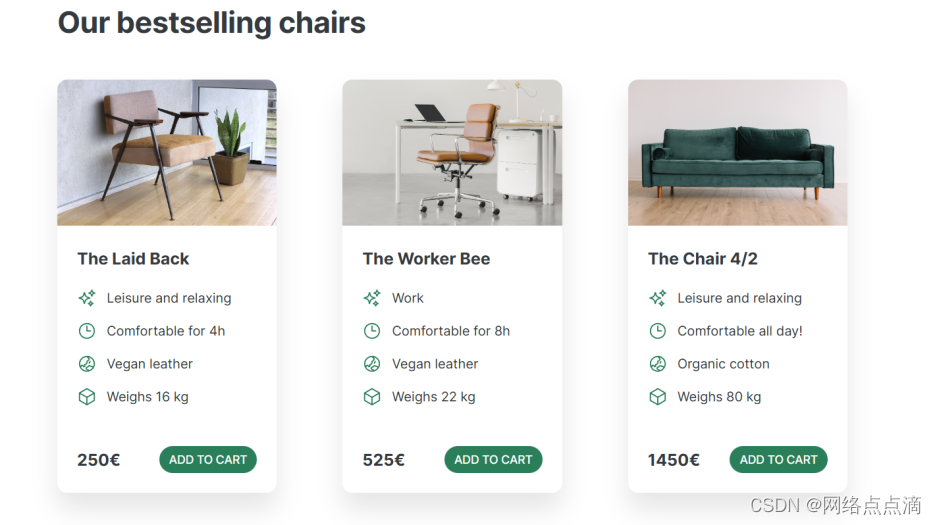
1.Squeeze-and-Excitation(SE)
SE的主要思想是通过对输入特征进行压缩和激励,来提高模型的表现能力。具体来说,SE注意力机制包括两个步骤:Squeeze和Excitation。在Squeeze步骤中,通过全局平均池化操作将输入特征图压缩成一个向量,然后通过一个全连接层将其映射到一个较小的向量。在Excitation步骤中,使用一个sigmoid函数将这个向量中的每个元素压缩到0到1之间,并将其与原始输入特征图相乘,得到加权后的特征图。通过SE注意力机制,模型可以自适应地学习到每个通道的重要性,从而提高模型的表现能力。在实际应用中,SE注意力机制已经被广泛应用于各种深度学习模型中,取得了很好的效果。

代码如下:
import torch
from torch import nn
from torchstat import stat # 查看网络参数
# 定义SE注意力机制的类
class SE_block(nn.Module):
def __init__(self, channel, ratio=16):
super(SE_block, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // ratio, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
if __name__ == '__main__':
# 构造输入层
inputs = torch.rand(2,320,32,32)
# 获取输入通道数
channel = inputs.shape[1]
# 模型实例化
model = SE_block(channel, ratio=16)
# 前向传播查看输出结果
outputs = model(inputs)
print(outputs.shape) #[2, 320, 32, 32]
# print(model) # 查看模型结构
stat(model, input_size=[320,32,32]) # 查看参数,不需要指定batch维度
2.Convolutional Block Attention Module(CBAM)
CBAM用于自适应地调整关注图像中的关键区域。CBAM注意力机制由两个模块组成:通道注意力模块和空间注意力模块。通道注意力模块用于学习每个通道的重要性,使得网络更多地关注那些有意义的特征,同时消除那些无意义的特征。这个模块的输入是一个卷积层的输出,输出是经过权重归一化之后的特征图。具体地,对于每个通道,通道注意力模块使用全局平均池化操作来得到一个特征向量,然后通过两个全连接层学习该通道的重要性,并对最终的卷积层输出进行加权。
空间注意力模块用于学习图像的不同空间区域的重要性,即在不同位置上的注意力权值。这个模块的输入是卷积层的输出,输出是通过空间维度上的卷积操作和全连接操作,产生的每个空间位置的注意力矩阵。这个矩阵能够自适应地调整感受野大小并关注图像中的关键区域。
通道和空间注意力模块可以结合使用,构建CBAM注意力机制。通过这种注意力机制的应用,可以提高图像分类、目标检测和语义分割等任务的准确性。


代码如下:
import torch
from torch import nn
from torchstat import stat # 查看网络参数
# 定义CBAM注意力机制的类
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=8):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 利用1x1卷积代替全连接
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class CBAM_block(nn.Module):
def __init__(self, channel, ratio=8, kernel_size=7):
super(CBAM_block, self).__init__()
self.channelattention = ChannelAttention(channel, ratio=ratio)
self.spatialattention = SpatialAttention(kernel_size=kernel_size)
def forward(self, x):
x = x * self.channelattention(x)
x = x * self.spatialattention(x)
return x
if __name__ == '__main__':
# 构造输入层
inputs = torch.rand(2,320,32,32)
# 获取输入通道数
channel = inputs.shape[1]
# 模型实例化
model = CBAM_block(channel, ratio=16, kernel_size=7)
# 前向传播查看输出结果
outputs = model(inputs)
print(outputs.shape) #[2, 320, 32, 32]
# print(model) # 查看模型结构
stat(model, input_size=[320,32,32]) # 查看参数,不需要指定batch维度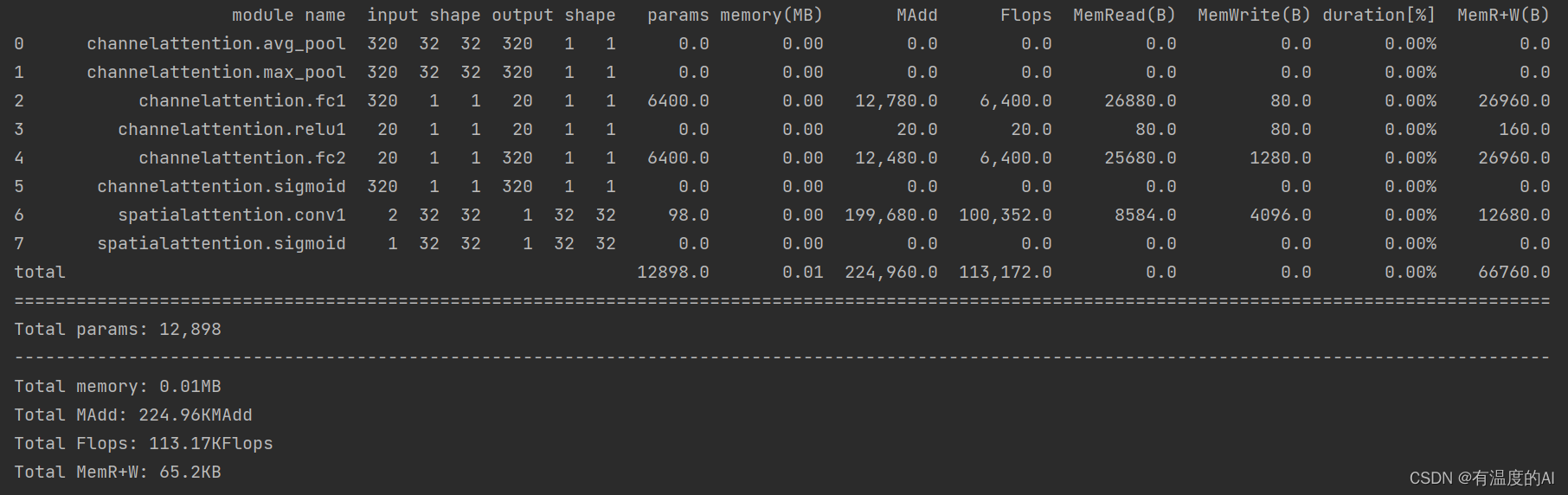
3.Efficient Channel Attention(ECA)
ECA是一种用于图像处理的注意力机制模型。它主要是通过对图像通道进行注意力调控,提高图像特征表示的有效性。具体来说,ECA注意力机制模型由两部分组成:全局平均池化和线性变换。全局平均池化可以对每个通道的信息进行汇聚,从而判断该通道中的信息是否关键;线性变换可以将通道的信息进行缩放和平移,使得关键信息得到更好的保留,非关键信息得到抑制。如果某个通道的信息对于图像表现并不关键,则可以对其进行抑制,以提高其他通道的表现。ECA注意力机制相比于其他注意力机制模型的优势在于其模型复杂度低、计算效率高、效果好。因此,它被广泛应用于图像分类、目标检测和图像分割等领域。

代码如下:
import torch
import math
from torch import nn
from torchstat import stat # 查看网络参数
# 定义ECA注意力机制的类
class ECA_block(nn.Module):
def __init__(self, channel, b=1, gamma=2):
super(ECA_block, self).__init__()
kernel_size = int(abs((math.log(channel, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)
if __name__ == '__main__':
# 构造输入层
inputs = torch.rand(2,320,32,32)
# 获取输入通道数
channel = inputs.shape[1]
# 模型实例化
model = ECA_block(channel)
# 前向传播查看输出结果
outputs = model(inputs)
print(outputs.shape) #[2, 320, 32, 32]
# print(model) # 查看模型结构
stat(model, input_size=[320,32,32]) # 查看参数,不需要指定batch维度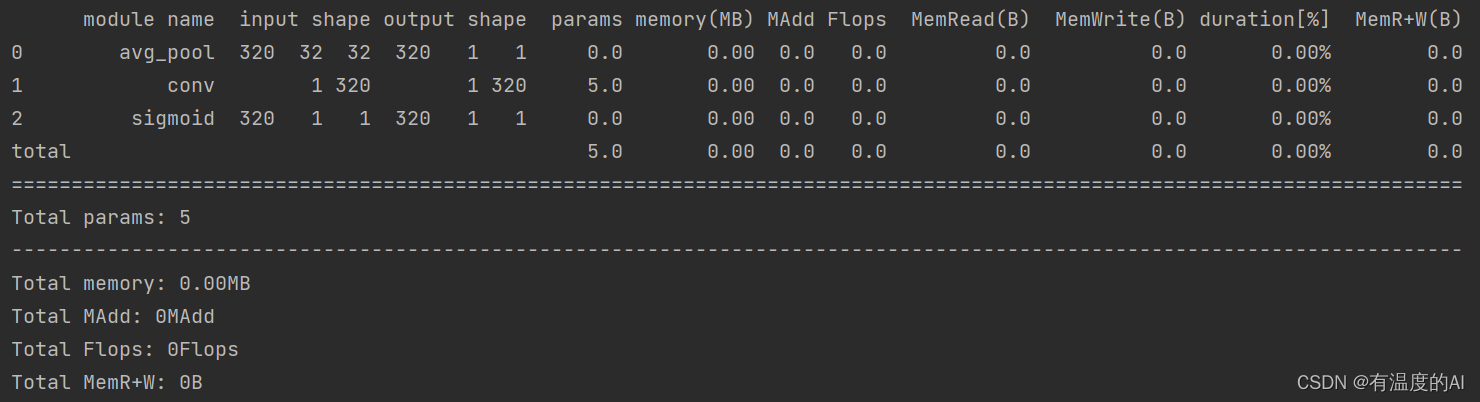
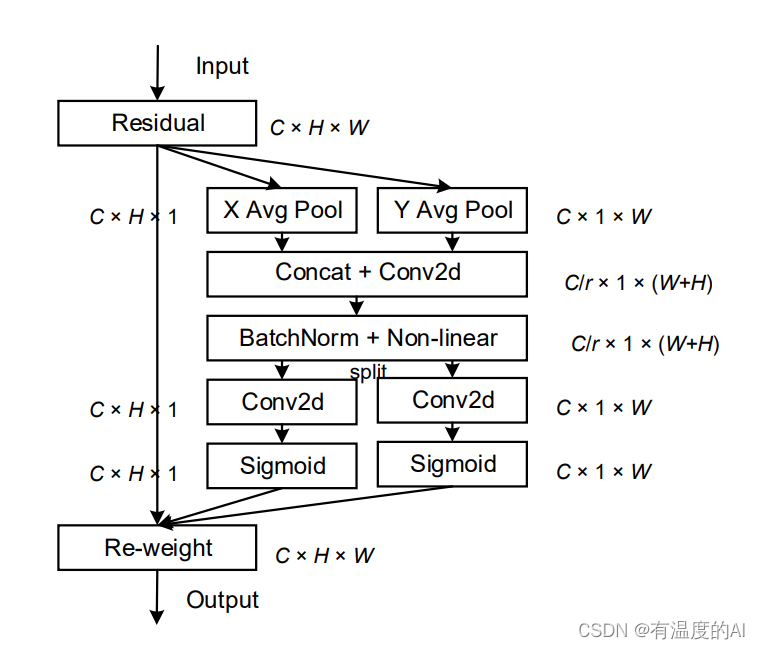
4.Coordinate attention(CA)
CA可以避免全局pooling-2D操作造成的位置信息丢失,将注意力分别放在宽度和高度两个维度上,有效利用输入特征图的空间坐标信息。CA主要分为两个步骤:第一步是坐标信息的嵌入,给定输入X,使用池化层分别沿着水平坐标和垂直坐标对每个通道进行编码,得到一对方向感知特征图。第二步是坐标信息特征图的生成,首先将提取到的特征信息进行拼接,然后利用一个1×1卷积变换函数进行信息转换,进而得到中间特征图,并沿着空间维度分解为两个单独的张量,再利用两个卷积变换为具有相同通道数的张量,最后将输出结果进行扩展,分别作为注意力权重分配值。CA是一个简单灵活即插即用的模块,可以在不带来任何额外开销的前提下,提升网络的精度。
代码如下:
import torch
from torch import nn
from torchstat import stat # 查看网络参数
# 定义CA注意力机制的类
class CA_Block(nn.Module):
def __init__(self, channel, reduction=16):
super(CA_Block, self).__init__()
self.conv_1x1 = nn.Conv2d(in_channels=channel, out_channels=channel // reduction, kernel_size=1, stride=1,
bias=False)
self.relu = nn.ReLU()
self.bn = nn.BatchNorm2d(channel // reduction)
self.F_h = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,
bias=False)
self.F_w = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,
bias=False)
self.sigmoid_h = nn.Sigmoid()
self.sigmoid_w = nn.Sigmoid()
def forward(self, x):
_, _, h, w = x.size()
x_h = torch.mean(x, dim=3, keepdim=True).permute(0, 1, 3, 2)
x_w = torch.mean(x, dim=2, keepdim=True)
x_cat_conv_relu = self.relu(self.bn(self.conv_1x1(torch.cat((x_h, x_w), 3))))
x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([h, w], 3)
s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2)))
s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w))
out = x * s_h.expand_as(x) * s_w.expand_as(x)
return out
if __name__ == '__main__':
# 构造输入层
inputs = torch.rand(2,320,32,32)
# 获取输入通道数
channel = inputs.shape[1]
# 模型实例化
model = CA_Block(channel, reduction=16)
# 前向传播查看输出结果
outputs = model(inputs)
print(outputs.shape) #[2, 320, 32, 32]
# print(model) # 查看模型结构
stat(model, input_size=[320,32,32]) # 查看参数,不需要指定batch维度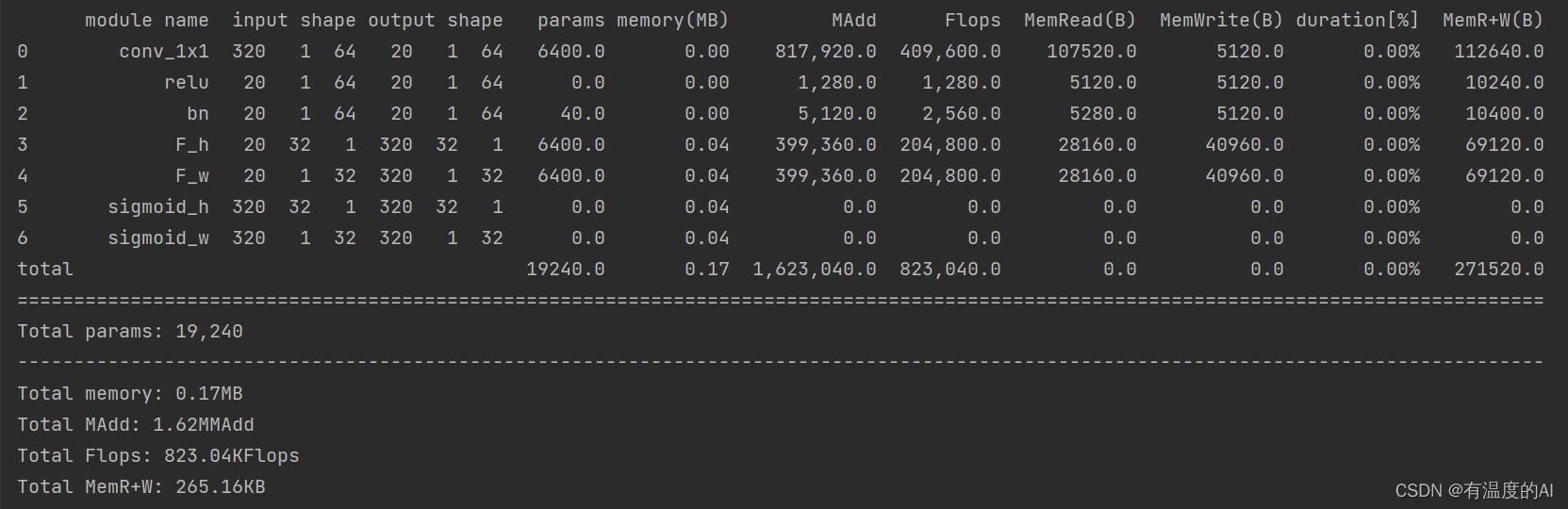
reference
http://t.csdn.cn/0XBy9![]() http://t.csdn.cn/0XBy9
http://t.csdn.cn/0XBy9