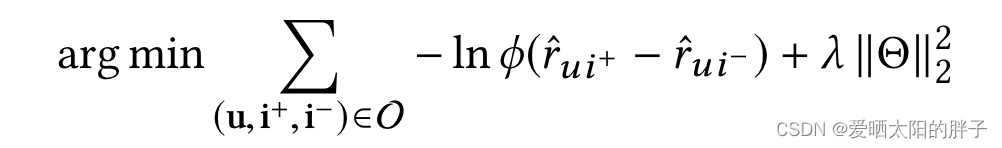文章来自于:曲終人不散丶@知乎,
连接:https://www.zhihu.com/people/qu-zhong-ren-bu-san-zhu-45/posts, 本文仅用于学术分享,如有侵权,前联系后台做删文处理。

Neck是目标检测框架中承上启下的关键环节。它对Backbone提取到的重要特征,进行再加工及合理利用,有利于下一步head的具体任务学习,如分类、回归、keypoint、instance mask等常见的任务。本文将对主流Neck进行阶段性总结。
总体概要
根据它们各自的论文创新点,大体上分为六种,这些方法当然可以同时属于多个类别。
- 上下采样:SSD (ECCV 2016),STDN (CVPR 2018)
- 路径聚合:DSSD (Arxiv 2017),FPN (CVPR 2017),PANet (CVPR 2018),Bi-FPN (CVPR 2020),NETNet (CVPR 2020)
- NAS搜索:NAS-FPN (CVPR 2019)
- 加权聚合:ASFF (Arxiv 2019), Bi-FPN
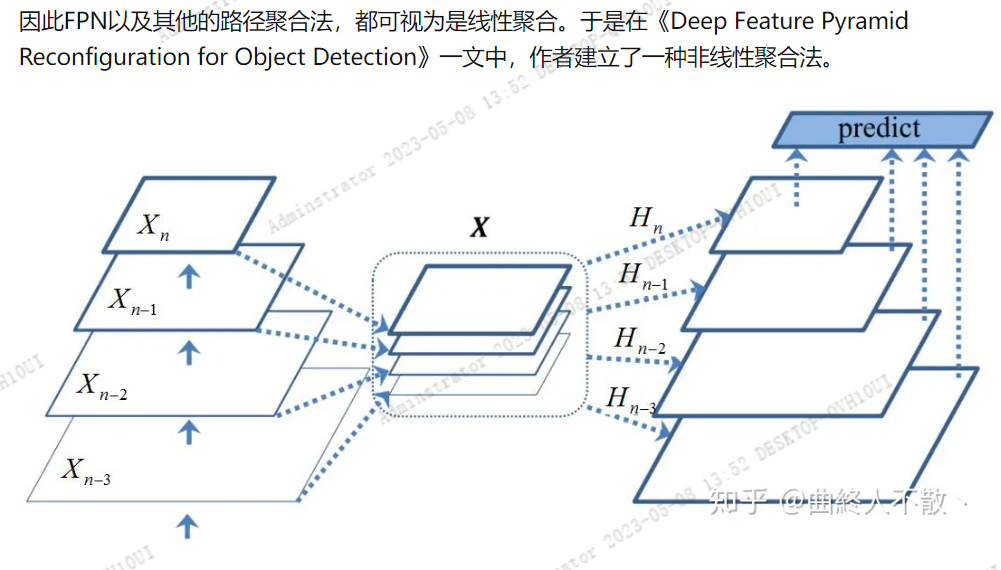
- 非线性聚合:Feature Reconfiguration (ECCV2018, TIP 2019)
- 无限堆叠:i-FPN (Arxiv 2020)
上下采样
该方法的特点是不具有特征层聚合性的操作,如SSD,直接在多级特征图后接head。

STDN是基于SSD的模型,其思想是构造法。由于STDN使用了DenseNet作为主干,因此后面的特征图在尺寸上是相同的,所以需要构造出各种大小的特征图来检测不同大小的物体。中间尺寸特征图直接使用,大尺寸特征图以尺寸变换层上采样获得,小尺寸特征图以池化获得。


路径聚合
该方法基于一个最基本的观察:深层特征图尺寸小,经过层层卷积下采样使得小物体的信息严重丢失,所以深层不利于小物体检测,就将小物体检测交给浅层来做。这也是为什么SSD需要多级head的原因。
然而光是这样还不够,由于深层特征图具有非常丰富的语义信息,那么最好把深层特征再往浅层传,以增加浅层语义信息。于是乎就诞生了最为人所熟知的FPN。在如何上采样方面,FPN使用最邻近上采样,当然还有使用反卷积的DSSD。


这类方法的共性就是反复利用各种上下采样、拼接、点和或点积,来设计聚合策略。可改进的点还包括加上Deformable Conv、Attention、门控机制、跨FPN level的label assignment等,都已有文章。
比较特殊的还有一种名为NETNet (CVPR 2020)的方法,其认为上述路径聚合方案无论怎么设计,对于预测小物体而言,大物体的特征一直存在,因为高层语义信息被传了下来,再加上其本身浅层自带的大物体特征,这对小物体来说会是一种干扰,如下图所示。

因此需要人为地进行干预,为浅层消除大物体特征。思路也很简单,随着下采样的进行,小物体特征会丢失,那么深层必然已经都是大物体的特征。此时对深层上采样,得到的还是大物体特征,再把原来的浅层减去经过上采样的深层,于是浅层就不再有了大物体的特征。那么小物体的特征将被突出化。


对小物体确实改进比较显著,值得一试。
NAS搜索

即利用神经网络搜索方法来搜索合适的聚合路径,但是搜索的时间成本极高,且数学可解释性低。最新的研究已表明,人工设计的路径聚合在精度上亦可超过NAS搜索出来的结构 (大力出奇迹)。
加权聚合
顾名思义,简单的聚合对所有参与的特征层都是一视同仁的,而实际上,这些来自不同层级的特征图对于单个物体而言,必然只有某一个是最适合检测它的。因此对聚合进行加权就显得尤为重要。
ASFF引入了可参与训练的加权因子来体现不同层级特征图的重要性。


非线性聚合

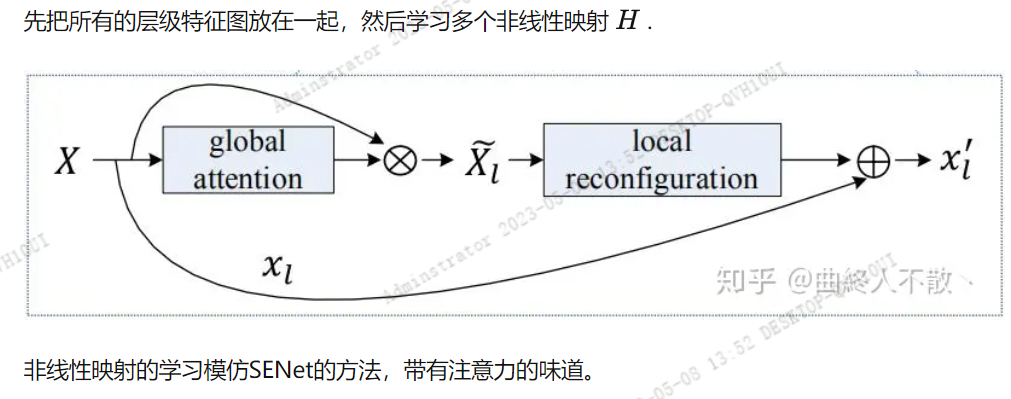
无限堆叠
EfficientDet通过重复堆叠多个Bi-FPN block来获得性能的提升。

显然这样的操作会造成大量的计算开销与显存占用。
那么有没有更好的方法呢?当然有,比如权重共享,即只使用一个FPN block,backbone提取到的特征图会反复经过这个block,由于权重共享,显存占用很少,参数量也少,但是计算量仍然随着重复的次数而增加,因为每迭代一次,对该block的更新最终都需要增加一次反向传播。
但是上述过程有一个有趣的现象,就是当重复计算的次数趋于无穷多次时,这个FPN block的参数会收敛到一个固定点,即特征平衡态。那么如何利用有限次前向传播即可求解这样的网络参数固定点呢?就是《Deep Equilibrium Models》(NeurIPS 2019) 的厉害之处了。只要我们求得了该固定点,我们就直接得到了单个block重复前后向传播无数次的结果。









![P1056 [NOIP2008 普及组] 排座椅](https://img-blog.csdnimg.cn/img_convert/1f85650a12eae06c5afd08b1783206dd.png)