1. 执行环境
Flink 程序可以在各种上下文环境中运行:我们可以在本地 JVM 中执行程序,也可以提交
到远程集群上运行。不同的环境,代码的提交运行的过程会有所不同。这就要求我们在提交作业执行计算时,首先必须获取当前 Flink 的运行环境,从而建立起与 Flink 框架之间的联系。只有获取了环境
上下文信息,才能将具体的任务调度到不同的 TaskManager 执行。
1. 1 创建执行环境
创建执行环境主要是调用 getExecutionEnvironment 的静态方法。这个方法提供了三种方式可以自由选择需要使用的是什么环境。
1.1.1 getExecutionEnvironment
直接调用getExecutionEnvironment 方法,底层源码可以自由判断是本地执行环境还是集群的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
底层源码根据环境不同,返回不同的执行环境对象

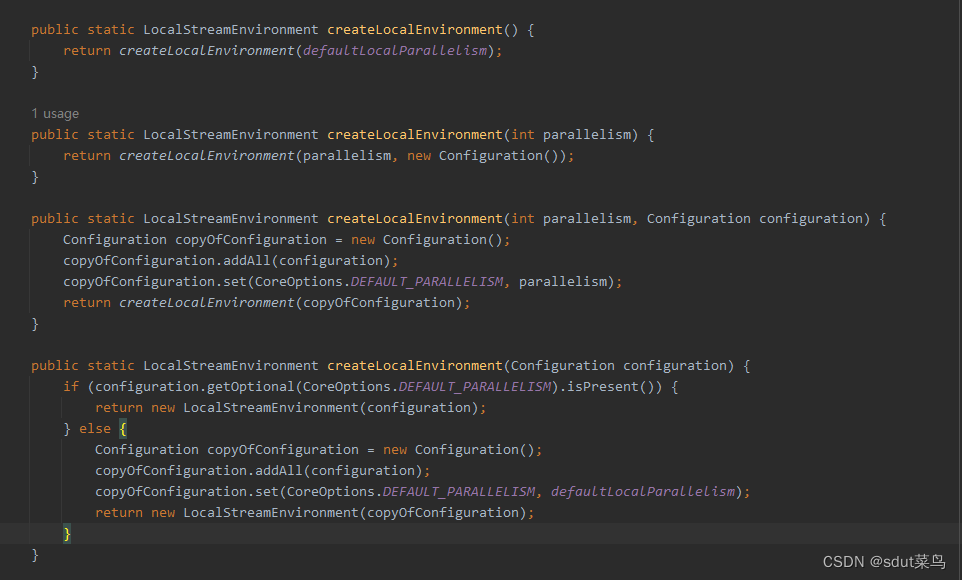
1.1.2 createLocalEnvironment
创建本地执行环境,可以指定默认的并行度 parallelism 参数,如果不传入则使用CPU的默认核心核数 例如:createLocalEnvironment(2)
LocalStreamEnvironment localEnvironment = StreamExecutionEnvironment.createLocalEnvironment(4);
参数有很多,可以指定并行度,也可以传入Configuration对象。
1.1.3 createRemoteEnvironment
创建集群执行环境,需要指定JobMange的主机名和端口号,并指定在集群中运行的jar包
StreamExecutionEnvironment remoteEnvironment = StreamExecutionEnvironment.createRemoteEnvironment("host", 7777, "path/t/jarFile.jar");
当然你也可以传入并行度以及Configuration对象。

1.2 执行模式(Execution Mode)
在Flink中,新版本都是使用DataSream API,DataSetAPI 已经被抛弃了,而且DataSream API支持流批一体,默认是流处理。那么怎么才能让DataSream API使用批处理模式呢? 这就是Flink提供了你的代码的执行模式 Execution Mode
1.2.1 流处理模式(STREAMING)
Flink的DataSream API代码自动使用的是流处理模式,处理的都是需要持续实时处理的无界数据流
1.2.2 批执行模式(BATCH)
批处理模式是专门用于批处理,主要针对于不需要持续计算的有界数据 (批量数据在Flink中认为是有界数据流)
1.2.3 自动模式(AUTOMATIC)
根据输入数据是否有界,来自动选择执行模式
1.2.4 执行模式的配置方法
-
通过命令行配置执行模式
bin/flink run -Dexecution.runtime-mode=BATCH ... -
通过代码指定配置模式
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.BATCH);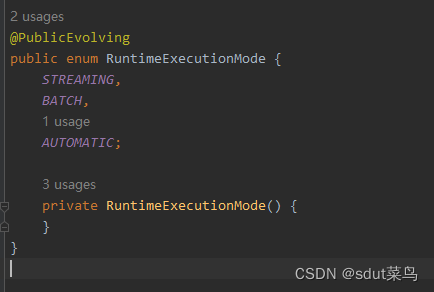
1.3 什么时候选择 BATCH 模式
我们知道,Flink 本身持有的就是流处理的世界观,即使是批量数据,也可以看作“有界
流”来进行处理。所以 STREAMING 执行模式对于有界数据和无界数据都是有效的;而 BATCH
模式仅能用于有界数据。
看起来 BATCH 模式似乎被 STREAMING 模式全覆盖了,那还有必要存在吗?我们能不
能所有情况下都用流处理模式呢?
当然是可以的,但是这样有时不够高效。
我们可以仔细回忆一下 word count 程序中,批处理和流处理输出的不同:在 STREAMING
模式下,每来一条数据,就会输出一次结果(即使输入数据是有界的);而 BATCH 模式下,
只有数据全部处理完之后,才会一次性输出结果。最终的结果两者是一致的,但是流处理模式
会将更多的中间结果输出。在本来输入有界、只希望通过批处理得到最终的结果的场景下,
STREAMING 模式的逐个输出结果就没有必要了。
所以总结起来,一个简单的原则就是:用 BATCH 模式处理批量数据,用 STREAMING
模式处理流式数据。因为数据有界的时候,直接输出结果会更加高效;而当数据无界的时候, 我
们没得选择——只有 STREAMING 模式才能处理持续的数据流。-------------转自尚硅谷Flink教程
1.4 触发执行程序
需要注意的是,写完输出(sink)操作并不代表程序已经结束。因为当 main()方法被调用
时,其实只是定义了作业的每个执行操作,然后添加到数据流图中;这时并没有真正处理数据
——因为数据可能还没来。Flink 是由事件驱动的,只有等到数据到来,才会触发真正的计算,
这也被称为“延迟执行”或“懒执行”(lazy execution)。 -------------转自尚硅谷Flink教程
所以我们需要显式地调用执行环境的 execute()方法,来触发程序执行。execute()方法将一
直等待作业完成,然后返回一个执行结果(JobExecutionResult)。 -------------转自尚硅谷Flink教程


![P1056 [NOIP2008 普及组] 排座椅](https://img-blog.csdnimg.cn/img_convert/1f85650a12eae06c5afd08b1783206dd.png)