首次将GAN用于语义分割,用于辨别分割图是来自GT还是来自分割网络。作者的想法来自借助GAN可以检测和矫正GT和模型分割图的高阶不一致。最后在Standford和PASCAL VOC 数据集上验证了想法。
对抗学习:
使用两个权重和的混合损失函数进行优化,第一个是多类别交叉熵优化分割模型,使用S(x),表示类别c的概率图,第二个损失基于辅助对抗卷积网络,如果辨别器可以分辨出真实的标签和分割模型输出的标签,那么它就会很大。因为对抗CNN认为整个图片或者图片的一部分,和高阶的标签统计不匹配。
我们使用a(x,y)∈[0,1]表示对抗模型预测y是x的标签而不是由分割模型输出s()的标签的概率。
给出数据Xn,对应的标签Yn,损失定义为:
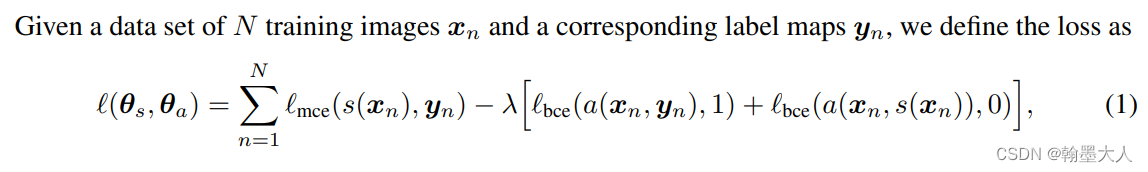
原始GAN的损失为:

看第一项:标签与经过segment模型的输出进行损失计算,即为不加对抗网络的损失,也即为加了对抗网络的生成器损失。

第二项:按理讲就是判别器损失了,判别器中我们知道需要输入的是原始的x和生成的S(x)。
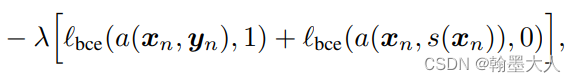
a()输入的是原始图片Yn是Xn GT的概率越大越好,输入的是分割后的S(Xn),则是Xn GT的概率越小越好。
最小化分割模型损失是为了让模型分割的更准确,最大化对抗模型损失是为了让对抗模型辨别的更准确。

训练对抗模型:

训练分割模型:这里多了一个正则化项,解释为在训练分割模型时候还要降低对抗模型的表现。我们最小化分割模型的损失,根据公式我们要最大化λLbce,λLbce表示的是将分割模型输出的结果预测为真实标签的概率,我们希望他为0,如果要最大化,则将分割模型输出的结果预测为真实标签的概率最大,可以替换为将分割模型输出的结果预测为真实标签的概率希望他为1。随着模型训练,我们希望分辨器将分割模型的输出预测为x真实标签的概率为1的损失最小,就与前面的mce损失一致。

根据描述我们可以画出模型框图:
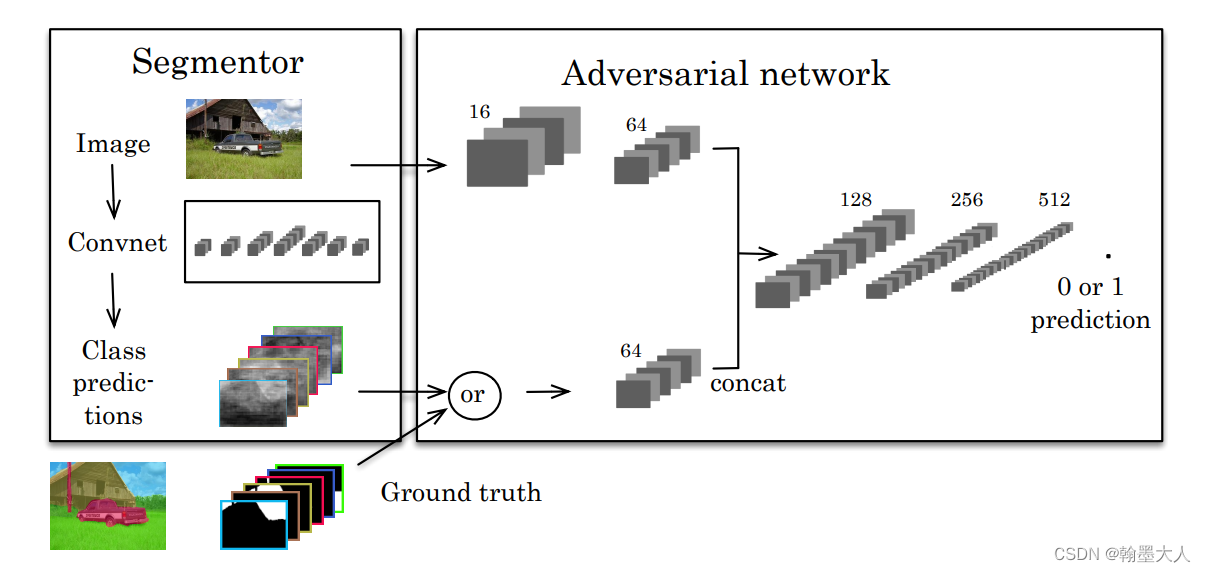
在两个数据集采用不同的模型:
在Standford Background数据集上,对抗模型输入为label map和对应的RGB,label map或者是真实的GT或者是分割输出的mask。两个分支分别处理RGB和label map,每一个输入信号的通道是一样的为64,然后两个信号传入一系列的卷积和池化层。紧接着一个sigmoid输出binary class的概率。
在Pascal Voc上使用了三种变体:Basic(使用分割的label map),Product(使用真实的GT),Scaling。在实验时候采用两种结构:
LargeFOV:label map的大小为34x34.
smallFOV:label map的大小为18x18.
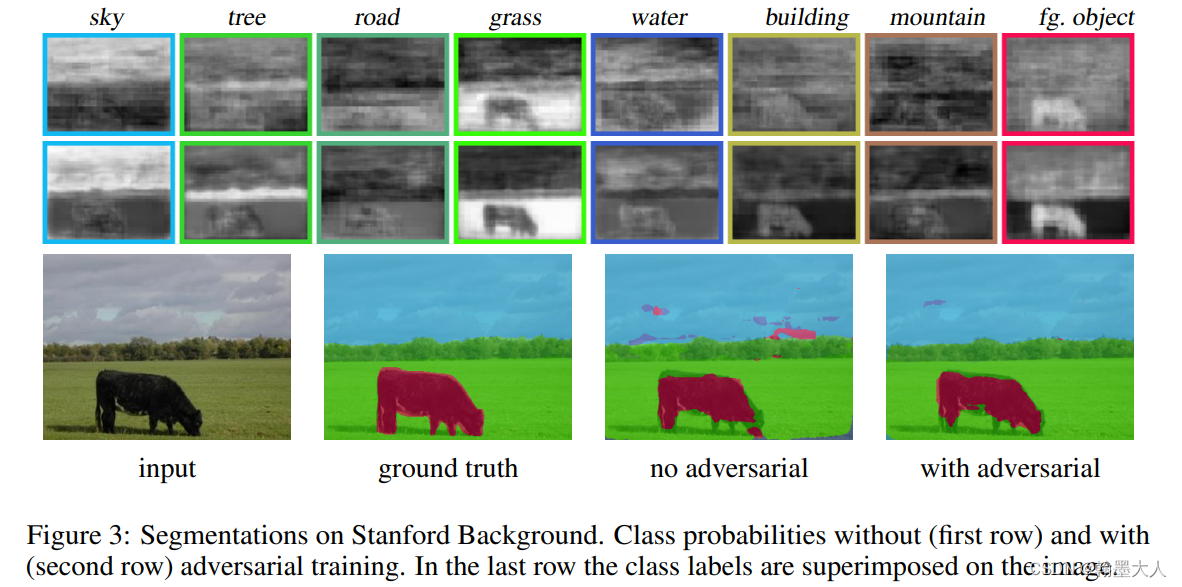
结果:
Semantic Segmentation using Adversarial Networks
news2026/2/16 11:30:47
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/502797.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

从win7升级到win10过程中遇到的问题:安装工具无法运行、卸载VMware
目录 1. 概述2. 微软官方安装工具无法运行3. 控制面板的卸载程序里面找不到VMware4. 输入产品密钥5. 安装完后仍然未激活6. 雨林木风 1. 概述
因为新电脑还没有到,把上学时候的笔记本翻出来顶一顶。旧笔记本还是win7,我的鼠标没办法使用,干脆…
HDCTF web复现
[HDCTF 2023]SearchMaster 传data
使用{if}标签闭合达到命令执行的效果
{if phpinfo()}{/if} NSSCTF{f578f8ba-246e-452b-b070-22bc4fc4313d}
Smarty模板注入&CVE-2017-1000480 - 先知社区 (aliyun.com) [HDCTF 2023]YamiYami 非预期解
第一个连接 跳转到百度…

远程访问(内网穿透)
文章目录 介绍cpolar安装使用终端访问远程桌面访问 仅靠ssh,等只能实现同局域网下的服务器访问,本文介绍使用cpolar内网穿透工具实现非同局域网下的访问 介绍
远程:1804 ubuntu 软件依赖:ssh,xrdp, cpolar…
【K8s】资源管理与实战入门
文章目录 一、资源管理1、资源管理介绍2、YAML语言语法3、资源管理方式4、命令式对象管理--kubectl5、命令式对象配置6、声明式对象配置7、报错 二、实战入门1、namespace2、Pod3、Label4、deployment5、Service 一、资源管理
1、资源管理介绍
在kubernetes中,所有…
如何有效的向 AI 提问 ?
文章目录 〇、导言一、Base LLM 与 Instruction Tuned LLM二、如何提出有效的问题 ?1. 明确问题:2. 简明扼要:3. 避免二义性:4. 避免绝对化的问题:5. 利用引导词:6. 检查语法和拼写:7. 追问细节…

7天获邀请函|环境科学研究学者持加拿大麦吉尔大学Offer申报CSC
I老师要求2周内获得邀请函且指定加拿大。我们只用了7天时间就获得加拿大排名榜首的麦吉尔大学邀请函,整整提前了一半时间,效率奇高。 I老师背景:
申请类型:CSC访问学者
工作背景:某研究所研究人员
教育背景…
g++编译静态库与动态库
该文目的是基本理清一个在linux在c静态库与动态库的编译和使用
一个非常基础的一节,简单的整合了一下目前已有的文章
前提准备:
文件:
touch SoDemoTest.h one.cpp two.cpp three.cpp main.cpp代码
/* SoDemoTest.h */
#ifndef _SO_DEMO_TEST_HEADE…

【Ubuntu22.04】内网部署Ubuntu Server 22.04.2
镜像下载
方式一:官网下载
https://ubuntu.com/download/server 方式二:清华镜像站
https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/22.04.2/ 方式三:百度网盘
链接: https://pan.baidu.com/s/1g24PDfAiPVsxMm7DVpERdg?pwd1020 …

myql的三种删除方式:delete truncate drop
前言
在 MySQL 中,删除的方法总共有 3 种:delete、truncate、drop,而三者的用法和使用场景又完全不同,接下来我们具体来看。
1.delete
detele 可用于删除表的部分或所有数据,它的使用语法如下:
delete …
独立产品灵感周刊 DecoHack #052 - 100个AI 工具导航网站
本周刊记录有趣好玩的独立产品设计开发相关内容,每周发布,往期内容同样精彩,感兴趣的伙伴可以 点击订阅我的周刊。为保证每期都能收到,建议邮件订阅。欢迎通过 Twitter 私信推荐或投稿。 ❤️ 刚换工作再加上个人原因有些自己的事…
消息队列中间件 - 详解RabbitMQ6种模式
RabbitMQ 6种工作模式
对RabbitMQ 6种工作模式(简单模式、工作模式、订阅模式、路由模式、主题模式、RPC模式)进行场景和参数进行讲解,PHP代码作为实例。
安装
客户端实现:添加扩展,执行composer.phar install命令
{"require":…

SSM框架学习-bean实例化
实例化bean的三种方式 1. 构造方法(常用) Spring创建bean调用的是无参的构造方法,且无论该无参构造方法是公有还是私有的,都可以调用(底层实现原理为反射) 2. 静态工厂(了解) 要配置…
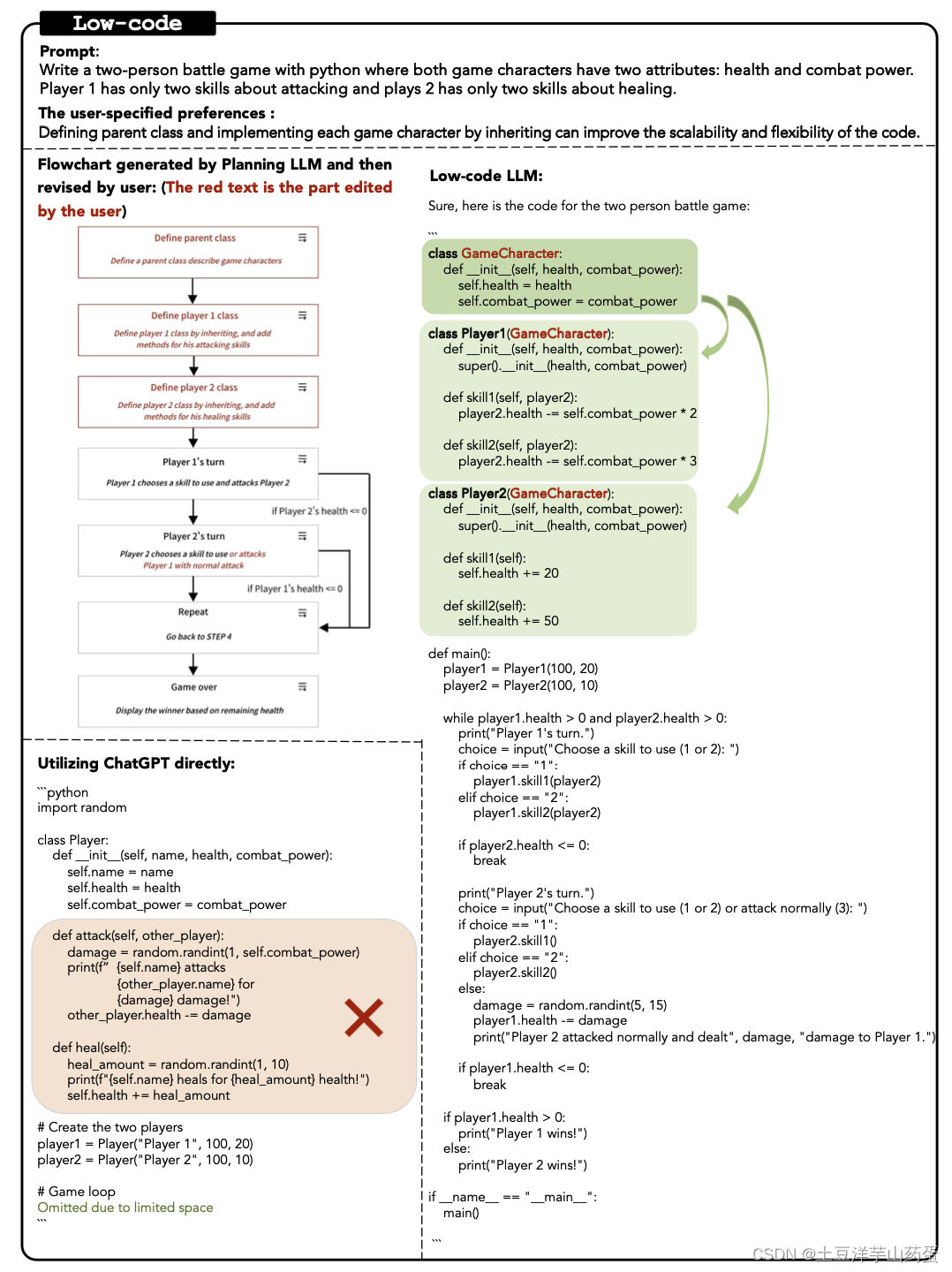
【论文阅读-Low-code LLM】使用LLM进行可视化编程
Low-code LLM: Visual Programming over LLMs
link: https://arxiv.org/abs/2304.08103 repository: https://github.com/microsoft/TaskMatrix/tree/main/LowCodeLLM
摘要
大规模预训练模型(LLMs)在解决困难问题仍具有很大的挑战。这篇文章提出了可以…

lua | 数据类型与变量
目录
一、数据类型
8个基本类型
1.nil(空)
2.boolean(布尔)
3.number(数字)
4.string(字符串) 5.table(表 )
6.function(函数)
7.thread(线程)
8.u…
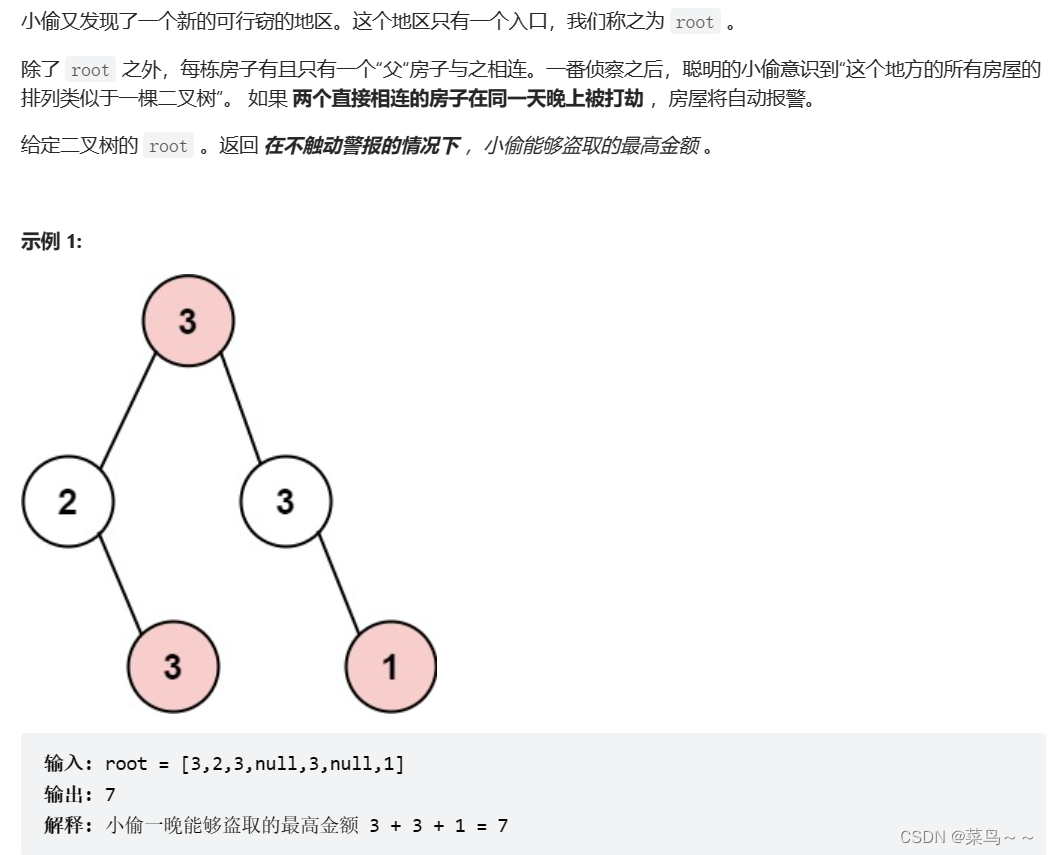
29 - 打家劫舍问题
文章目录 1. 打家劫舍I2. 打家劫舍II3. 打家劫舍III(1) 暴力递归超时(2) 记忆化搜索超时(3) 动态规划 1. 打家劫舍I 动态规划: dp[i] max(dp[i - 2] nums[i], dp[i - 1]);
class Solution {
public:int rob(vector<int>& nums) {if(nums.size() 1) re…
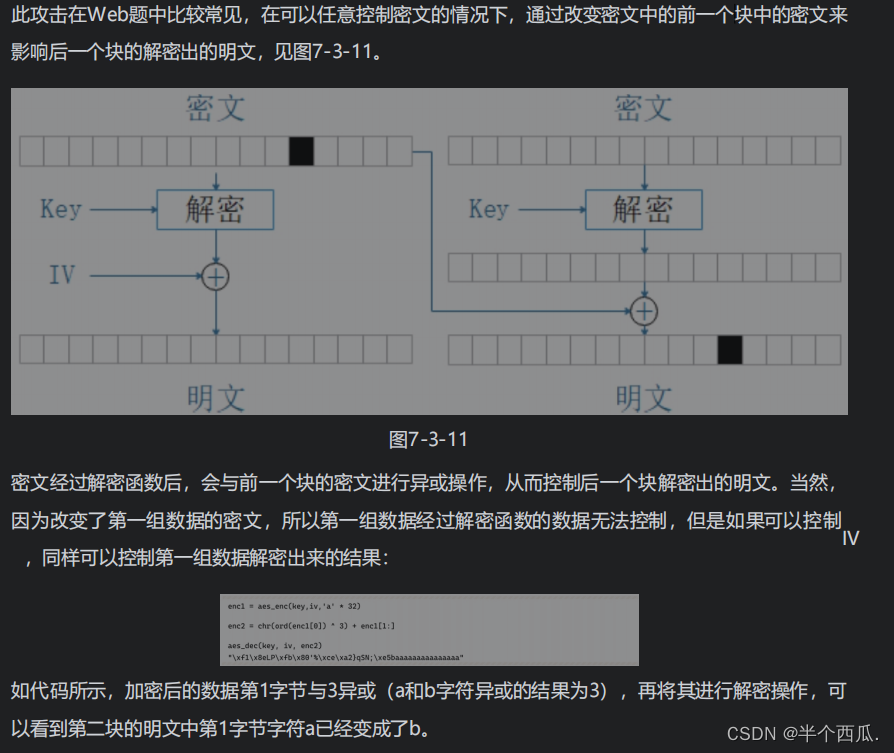
密码学:分组密码.(块密码:是一种对称密码算法)
密码学:分组密码.
分组加密(Block Cipher) 又称为分块加密或块密码,是一种对称密码算法,这类算法将明文分成多个等长的块 (Block) ,使用确定的算法和对称密钥对每组分别加密或解密。分组加密是极其重要的加密体制,如D…

设计模式 -- 中介者模式
前言
月是一轮明镜,晶莹剔透,代表着一张白纸(啥也不懂)
央是一片海洋,海乃百川,代表着一块海绵(吸纳万物)
泽是一柄利剑,千锤百炼,代表着千百锤炼(输入输出)
月央泽,学习的一种过程,从白纸->吸收各种知识->不断输入输出变成自己的内容
希望大家一起坚持这个过程,也同…

瑞芯微RK3568开发板在智慧交通行业中的应用方案
智能交通安全监测系统是通过利用高性能处理器和先进的图像处理算法,实现对交通场景的实时监测、分析和预警,以提高交通安全水平。以下是基于RK3568处理器的智能交通安全监测系统产品的应用方案: 视频采集与处理: 使用RK3568处理器…