文章目录
- 第一章 绪论
- 选择
- 判断题
- 简答题
- 1. NoSQL和关系型数据库在设计目标上有何主要区别?
- 2. 简要总结一下NoSQL数据库的技术特点。
- 第二章 NoSQL数据库的基本原理
- 选择
- 判断
- 简答题
- 1. 描述分布式数据管理的特点。
- 2 什么是CAP原理?CAP原理是否适用于单机环境?
- 3. 简述BASE理论的具体含义。
- 4. 在数据一致性问题上,ACID和BASE的差别是什么?
- 5. 简述NoSQL数据库的4种类型,以及它们的数据模型。
- 6. 布隆过滤器的优缺点是什么?如何降低布隆过滤器的误报率?
- 第三章 HDFS的基本原理
- 选择
- 判断
- 第四章 HBase基础
- 选择
- 判断
- 简答题
- 1. HDFS是否属于NoSQL数据库?请说明用HDFS进行数据管理存在的问题。
- 2. HBase的特点是什么?(4条以上)
- 3. HBase采用了什么样的数据结构?
- 4. HBase的拓扑结构是什么?每个角色起什么作用?
- 5. 请用拓扑结构图的形式展示HBase的典型架构
- 第五章 HBase高级原理
- 选择
- 判断
- 简答题
- 1. HBase中预写日志(WAL)的作用。
- 2. 如何理解HBase的分区拆分机制,包括哪几种方式?
- 3. 如何理解HBase的合并,包括哪几种方式?
- 第七章 MongoDB的原理和使用
- 选择
- 判断
- 简答题
- 1. 描述MongoDB的集群架构(包含的角色和每个角色的作用)。
- 2. 请用拓扑结构图的形式展示MongoDB的典型架构
- 3. 描述MongoDB的分片机制,它支持哪几种分片策略?
- 4. MongoDB集群的数据多副本策略?
- 第八章 其他NoSQL数据库
- 选择
- 判断
- 简答题
- 1. 什么是Neo4j?并对其数据模型进行详细描述。
- 2,描述Redis的数据类型(5种)。
- 3. Redis数据库支持的几种拓扑架构。
- 分析题
第一章 绪论
选择
1、NoSQL一词表示的含义是()。
没有SQL
不是SQL
非关系型数据库 (答案)
关系型数据库
2、大数据时代,数据的存储与管理不包括哪些要求?()
数据管理系统具有很高的扩展性,适应海量数据的迅速增长
满足完整性的约束条件 (答案)
满足用户的高并发读写
要适应多变的数据结构
3、网络存储方式不包括()。
DAS
NAS
ANS (答案)
SAN
4、大数据的特征不包括()。
大量化
价值化
整体化 (答案)
快速化
5、大数据的特征不包括()。
Volumn
Vague (答案)
Variety
Velocity
6、对比关系型数据库,关于NoSQL说法错误的是()。
采用非关系的数据模型
弱化模式或表结构、弱化完整性约束、弱化甚至取消事务机制
无法支持,或不能完整的支持SQL语句
不能实现强大的分布式部署能力 (答案)
7、下面不属于NoSQL数据库的特点的是()。
开源
支持SQL (答案)
分布式
非关系型
8、下面()不属于关系型数据库的特点。
实体和实体间的联系都可以通过关系的方式来表示
关系模型需要满足实体完整性和参照完整性约束
可以通过SQL语句实现数据定义和操作
不支持事务和ACID一致性等特性 (答案)
9、以下数据库中,不是关系数据库的为()。
Mysql
SqlServer
Oracle
Redis (答案)
10、下面不属于数据操作语言的是()。
定义 (答案)
增加
查询
删除
判断题
1、分布式计算在网络中的每台机器都比较廉价,所以这些机器管理起来比较容易 F
2、大数据的特征大量化、价值化、整体化、快速化。 F
3、NoSQL不能替代RDBMS。 T
4、NoSQL会强化表结构和完整性约束。 F
简答题
1. NoSQL和关系型数据库在设计目标上有何主要区别?
(1)关系数据库
优势:以完善的关系代数理论作为基础,具有数据模型、完整性约束和事务的强一致性等特点,借助索引机制可以实现高效的查询,技术成熟,有专业公司的技术支持。
劣势:可扩展性较差,无法较好支持海量数据存储,数据模型过于死板、无法较好支持Web2.0应用,事务机制影响了系统的整体性能等。
(2)NoSQL数据库
优势:NoSQL数据库会采用非关系的数据模型,弱化模式或表结构、弱化完整性约束、弱化甚至取消事务机制。可能无法支持,或不能完整的支持SQL语句。目的是实现强大的分布式部署能力——一般包括分区容错性、伸缩性和访问效率(可用性)等。可以支持超大规模数据存储,灵活的数据模型可以很好地支持Web2.0应用,具有强大的横向扩展能力等。
劣势:缺乏数学理论基础,复杂查询性能不高,大都不能实现事务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业团队的技术支持,维护较困难等。
2. 简要总结一下NoSQL数据库的技术特点。
(1)NoSQL数据库会采用非关系的数据模型
(2)弱化模式或表结构、弱化完整性约束、弱化甚至取消事务机制
(3)可能无法支持,或不能完整的支持SQL语句
(4)目的是实现强大的分布式部署能力——一般包括分区容错性、伸缩性和访问效率(可用性)等
(5)NoSQL大多是开源免费的
第二章 NoSQL数据库的基本原理
选择
1、NoSQL的主要存储模式不包括
键值对存储模式
列存储模式
文件存储模式 (答案)
图存储模式
2、BASE不包括()。
基本可用
软状态
强一致性 (答案)
最终一致性
3、CAP理论不包括()。
Consistency(一致性)
Atomicity(原子性) (答案)
Availability(可用性)
Partition tolerance(分区容错性)
4、()不属于分布式数据管理的特点。
数据分片
数据多副本
一次写入多次读取
读写分离 (答案)
5、分布式部署关系型数据库时,读写分离(主从集群)不包括()。
所有对数据库的修改都通过主服务器
从服务器分担主服务器读服务器请求
解决了写数据的瓶颈 (答案)
主从服务器之间可能存在暂时的数据不一致的情况
6、预防死锁的主要方法包括:一是(),即在设计阶段规定所有的事务都按相同的顺序来封锁表;一是(),即当一个事物加锁时间过长时就判断出现死锁。
顺序法 一次封锁法
超时法 等待图法
顺序法 超时法 (答案)
超时法 顺序法
7、关系型数据库事务机制中的ACID不包括()。
连续性(Continuance) (答案)
隔离性(Isolation)
持久性(Durability)
8、下面关于NoSQL数据库完整性约束不正确的是()。
域完整性一般较弱,或不支持
不能存在主键相同的行,或内容相同但时间戳不同的行 (答案)
一般不提供参照完整性,或者外键
用户定义完整性靠应用程序支持
9、与关系模型相比,关于NoSQL不正确的是()。
NoSQL中可能没有明确的结构
列可能是复合型的
列中的内容和类型可能是随意的、无定义的
会为空值留出存储空间 (答案)
判断
1、CAP理论中,NoSQL数据库需要在C和P之间进行权衡。F
2、NoSQL数据库能够满足CAP三个特性。F
3、一次写入多次读取不是分布式数据管理的特点。F
4、ACID是NoSQL数据库的基本要求。F
5、NoSQL一般不提供参照完整性,或者外键,因此一般也不支持跨表的关联查询。T
6、NoSQL不会为空值留出存储空间,可能很难直接插入数值。T
7、NoSQL由明确的表结构。F
简答题
1. 描述分布式数据管理的特点。
(1)数据分片:使数据均匀分布到多个节点上,可以充分利用各个节点的处理能力、存储能力和吞吐能力。
(2)数据多副本:将数据存储为多个副本,不同的副本存储在不同节点上。
(3)一次写入多次读取:在系统底层只支持新建和追加,此时系统具有更好的顺序存储特性。
(4)分布式系统的可伸缩性:可以移除故障节点,替换新节点,实现数据的再平衡。
2 什么是CAP原理?CAP原理是否适用于单机环境?
CAP是指分布式系统中的Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性)。Consistency(一致性)是指分布式系统中所有节点都能对某个数据达成共识。Availability(可用性)可以理解为分布式系统的响应速度或响应能力。Partition tolerance(分区容错性)指在部分节点故障、以及出现消息丢包的情况下,集群系统(的剩余部分)仍然可以提供服务。
CAP理论是指在分布式系统中,CAP三个特性不可兼得,只能同时满足两个。CAP不能兼顾,但并非绝对对立。
CAP理论的主要场景是在分布式环境下,在单机环境下,基本可不考虑CAP问题.
3. 简述BASE理论的具体含义。
由于CAP无法兼顾,分布式系统需要根据实际业务要求,对一致性做一定妥协,提供弱一致性保障。具体要求为BASE理论:
(1)Basically Available(基本可用):核心部分或其他数据可用。
(2)Soft-state(软状态/柔性事务):允许多个副本存在暂时的不一致状态。
(3)Eventual Consistency (最终一致性):存在中间状态,但经历一段时间之后,最终会一致。
4. 在数据一致性问题上,ACID和BASE的差别是什么?
(1)ACID是典型的强一致性要求。要求多个节点的数据副本都是一致的,强调数据的一致性。ACID是大多数NoSQL抛弃的机制,因为无法在分布式环境中保证效率。
(2)BASE的最终一致性(在一些应用场景下)也可以看作NoSQL允许多个副本可以存在暂时的不同步(即异步更新)。结合CAP理论,这种设计强调PA,可以提高响应速度。
5. 简述NoSQL数据库的4种类型,以及它们的数据模型。
(1)键值对存储模式(key-value)
数据模型:每行数据的结构为:<key, value>。值可以看作是一个单一的存储区域,可以是任何的类型。
列存储模式(column-family)
数据模型:可以看作是一种纵向切分数据的方式,不同列会放到不同的位置(节点)存储,实际软件一般也会按照行键(key)再进行横向切片和分布式存储。
文档存储模式(document)
数据模型:可以看作键值对模式的升级,底层存储的每行数据中仍然存在key(或者ID)和value。但值是采用JSON等格式描述的复杂数据类型。
(4)图存储模式(graph)
数据模型:将数据存储为点和边的关系。
6. 布隆过滤器的优缺点是什么?如何降低布隆过滤器的误报率?
布隆过滤器 的目的是检查某个元素是否存在于集合(例如数据块)中。
优点是空间占用低、检索速度快,缺点则是存储在一定的误报率:当布隆过滤认为某元素存在于集合时,该元素可能并不存在,但如果布隆过滤认为该元素不存在于集合,则肯定不存在。
布隆过滤器的误报率,和哈希算法的个数、二进制向量的大小以及数据总量有关,一般来说二进制向量越大,误报率越低,因此需要在存储空间占用和误报率之间做权衡。降低误报率的方法:(1)采取多个独立的哈希算法同时进行映射。(2)增大二进制向量的大小。
第三章 HDFS的基本原理
选择
1、HDFS的角色不包括()
Masternode (答案)
Namenode
Datanode
Secondary Namenode
2、Hadoop核心组件不包括()。
HDFS
HBase (答案)
YARN
MapReduce
判断
1、Hive不属于NoSQL数据库。T
2、HDFS在数据读写时,对客户提供强一致性保障,在副本复制过程中采用最终一致性方式。T
3、HDFS Namenode的fsimage文件启动加载后,一直保持只读状态,不能直接在内存或硬盘修改。T
4、HDFS的Namenode和DataNode不能在一个物理节点上。F
5、Hadoop核心组件包括Hbase。F
6、HDFS属于NoSQL数据库。F
第四章 HBase基础
选择
1、HBase 的特点不包括 ( )
容量巨大
稀疏性
列存储
支持 join 操作 (答案)
2、HBase插入数据采用()命令
insert
put (答案)
create
delete
3、HBase的逻辑节点不包括()。
Zookeeper
NameNode (答案)
Master
Regionmaster
4、以下 HBase 的说法哪个是不正确的?
在 HBase 中由行键、列族、列和时间戳来唯一确定一个单元格数值。
在 HBase Shell 中创建表时,不需要预先定义列族。 (答案)
HBase 中不同行之间可以由不同的列组成。
HBase 中所有数据都是字符串的形式。
5、HBase虚拟分布式模式需要()个节点?
1 (答案)
2
3
最少3个
6、HBase依赖()提供消息通信机制。
Zookeeper (答案)
Chubby
RPC
Socket
7、HBase依靠()存储底层数据。
Hadoop
HDFS (答案)
Memory
MapReduce
8、下面对HBase的描述不正确的是()?
不是开源的 (答案)
是面向列的
是分布式的
是一种NoSQL数据库
9、HBase Shell 中不包含以下哪个命令?()
Create
Put
Scan
Add (答案)
10、以下过滤器中,哪个可以针对行键进行过滤?()
Rowfilter (答案)
QualifierFilter
FamilyFilter
ValueFilter
11、HBase 基于 java 编程中,能实现删除表功能的接口是()
Table 接口
Admin 接口 (答案)
HbaseConfiguration 类
HTableDescriptor 类
12、Hbase Shell中Alter 命令能完成的功能不包括:()
增加列族
修改列族参数
删除列族
查询列族信息 (答案)<//font>
13、Region 的负载均衡是由()来完成。
Master (答案)
Zookeeper
RegionServer
HBase
14、HBase来源于哪篇文章?
The Google File System
MapReduce
BigTable (答案)
Cubby
判断
1、HBase中的数据都是以字符串形式存储的,为空的列并不占用存储空间。T
2、HBase 的底层存储为 HDFS 。T
3、HBase可以实现事务、多表查询等功能。F
4、HBase创建表时,必须定义列族。T
5、HBase是基于Python语言开发的,它提供了这种语言的API接口来管理和操作数据库。F
简答题
1. HDFS是否属于NoSQL数据库?请说明用HDFS进行数据管理存在的问题。
HDFS不属于NoSQL数据库。
用HDFS进行数据管理存在的问题:
(1)HDFS不支持对数据的随机读写。
(2)HDFS没有数据表的概念,不能提供对数据的表格化存储。
(3)HDFS无法针对行数统计、过滤扫描等常见数据查询功能。
2. HBase的特点是什么?(4条以上)
(1)采用面向列加键值对的存储模式。
(2)可以实现便捷的横向扩展
(3)可以实现自动的数据分片。
(4)可以实现严格的读写一致性和自动的故障转移。
(5)可以实现对全文的检索与过滤。
(6)支持通过命令行或者Java、Python等语言来进行操作。
3. HBase采用了什么样的数据结构?
HBase采用的是一种面向列的键值对存储模式。HBase表中,列族是表结构的一部分,需要在建表时预先定义。
列不属于表结构,HBase不会预先定义列名及其数据类型和值域等内容。每一个记录中的每个字段必须记录自己的列名(列标识符)以及值和时间戳。
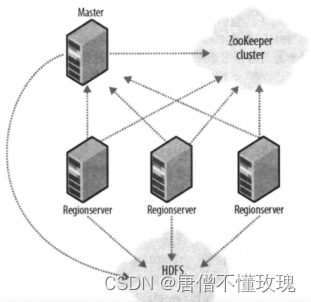
4. HBase的拓扑结构是什么?每个角色起什么作用?
HBase采用主从式架构,包括一个主节点(Hmaster)和若干个从节点(Hregionserver)。除此之外,还需要Zookeeper来实现节点监控和容错。
(1)Zookeeper是一个分布式协调服务,实现节点监控、活跃主节点选举、配置维护等功能
- 维护元数据的总入口,以及记录Master节点的地址
- 监控集群,如果Hregionserver出现故障,则通知Master,Master会将其负责的分区移交给其他Hregionserver
- 当活跃Master节点故障的情况下,Zookeeper会在备用Master节点中选举一个新的活跃Master节点。
(2)HMaster节点是所有Hregionserver的管理者,负责对Hregionserver的管理范围进行分配,但不负责管理用户数据表。
(3)Hregionserver是用户数据表的实际管理者,在分布式集群中,数据表会进行水平分区,每个Hregionserver只会对一部分分区进行管理——负责数据的写入、查询、缓存和故障恢复等。用户表最终是以文件形式存储在HDFS上,但如何将写入并维护这些文件,则是由Hregionserver负责的。
5. 请用拓扑结构图的形式展示HBase的典型架构
第五章 HBase高级原理
选择
1、HFile数据格式中的Data字段用于()。
存储实际的KeyValue数据 (答案)
存储数据的起点
指定字段的长度
存储数据块的起点
2、Rowkey设计的原则,下列哪些选项的描述是不正确的?()
尽量保证越短越好
可以使用汉字
可以使用字符串
本身是无序的 (答案)
3、HFile数据格式中的MetaIndex字段用于()。
Meta块的长度
Meta块的结束点
Meta块数据内容
Meta块的起始点 (答案)
4、下面与Zookeeper类似的框架是?
Protobuf
Java
Kafka
Chubby (答案)
5、HBase不包括如下()分区方式。
自动分区
预分区
固定分区 (答案)
手动拆分
6、当用户读写HBase数据库时,会首先在()寻找表和行键对应的分区。
Master
RegionServer
ZooKeeper (答案)
Region
判断
1、当数据被写入memstore之前,Regionserver会先将数据写入预写日志(WAL,Writeaheadlog)T
2、HBase中每个分区(Region)只能包含一个列族(Store)。F
3、HBase数据库中,META表的入口地址存储在ZooKeeper。T
简答题
1. HBase中预写日志(WAL)的作用。
当数据被写入memstore之前,Regionserver会先将数据写入预写日志(WAL,Writeaheadlog),预写日志一般被写入HDFS,但键值写入时不会被排序,也不会区分Region。
出现节点宕机、线程重启等问题时,memstore中未持久化的数据会丢失。当Regionserver恢复后,会查看当前WAL中的数据,并将记录进行重放(replay),根据记录的表名和分区名,将数据恢复到指定的store中。
在进行自动或手动的数据持久化操作之后,Regionserver会将不需要的WAL清除掉。
2. 如何理解HBase的分区拆分机制,包括哪几种方式?
HBase为了实现分布式大数据管理,设计了表的水平拆分机制,这是HBase实现分布式、负载均衡以及可伸缩性等机制的重要方式。
HBase具有三种分区方式:自动分区、预分区和手动拆分,都是基于行键进行分区。
3. 如何理解HBase的合并,包括哪几种方式?
HBase中设计了合并(compact)机制,通过读取多个小文件,处理并写入一个新的大文件的方式,实现storefile的合并。它包括MajorCompact和Minor Compact两种合并方式。
第七章 MongoDB的原理和使用
选择
1、以下哪个不是MongoDB数据库在分片时需要的节点?
Config Router (答案)
Shard
Mongos
Config Server
2、以下哪个不是MongoDB数据库的索引类型?
单键索引
全文索引
地理位置索引
时间索引 (答案)
3、MongoDB数据库中基本单元为?
表格
集合
文档 (答案)
字段
4、CouchDB与MongoDB比较,不正确的是()。
CouchDB更多地采用通用技术,并考虑和ASF其他模块的配合
CouchDB采用通用JSON格式存储和传输数据
CouchDB支持动态查询,MongoDB不支持动态查询 (答案)
CouchDB支持多主节点间的数据复制,而MongoDB只支持主从复制
5、MongoDB的分片切分机制不包括()。
升序分片
哈希分片
随机分片 (答案)
位置分片
6、MongoDB采用()进行数据存储与编码传输。
JSON
BSON (答案)
XML
YAML
判断
1、MongoDB采用副本集提供数据库的扩缩容能力。F
2、MongoDB的集合是动态模式的,同一个集合里面的文档可以是各式各样的。T
3、MongoDB的主节点选举算法是Paxos算法。F
4、BSON比JSON相比,检索速度更快,更节省空间。F
5、MongoDB中的一组文档称为“集合”,可以类比为传统数据库中的“数据库”。F
6、MongoDB支持复杂的数据结构,支持索引(包括二级索引和地理空间索引),支持聚合查询。T
简答题
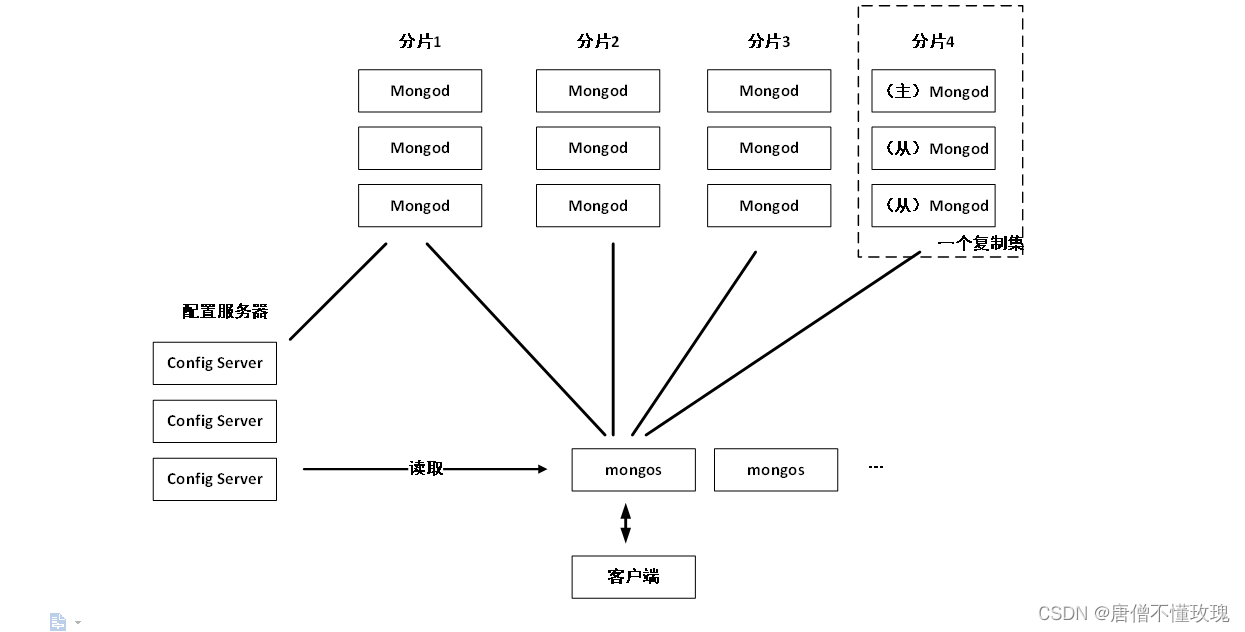
1. 描述MongoDB的集群架构(包含的角色和每个角色的作用)。
MongoDB集群由Mongod、Mongos和Config服务器组成。
(1)负责存储实际数据分片的设备称为Mongod(或称为Shard)。
(2)Mongos服务器,作为用户访问集群的入口,负责与客户端的交互,并在内存中缓存分片数据的存储和路由信息。
(3)Config服务器,负责持久化存储各类元数据和配置信息,当Mongos服务器启动时,会通过Config服务器读取相关信息并缓存到内存。
2. 请用拓扑结构图的形式展示MongoDB的典型架构
3. 描述MongoDB的分片机制,它支持哪几种分片策略?
MongoDB将数据水平切分机制称为分片(Sharding)。MongoDB支持对文档的自动分片,分片的依据是分片键(Shard Keys),分片键可以由文档的一个或多个字段构成。
MongoDB支持三种分片(片键)策略:升序分片、哈希分片和位置分片。
(1)升序分片会将片键进行升序排序,并在当前分片的数据量达到某个阈值时进行分片。
(2)哈希分片会将片键进行哈希运算,使数据的分布更均匀。
(3)位置分片类似于对片键的前缀或子串进行判断。
4. MongoDB集群的数据多副本策略?
MongoDB支持分片的多副本,多副本采用主从备份形式。MongoDB称这种机制为复制集机制。
主节点(Primary节点)负责数据的写入和更新。主节点在更新数据的同时,会将操作信息写入日志,称为oplog。
从节点(Secondary节点)监听主节点oplog的变化,并根据其内容维护自身的数据更新,使之和主节点保持一致(最终一致性)。
第八章 其他NoSQL数据库
选择
1、Redis采用的是()模式。
键值对存储 (答案)
列存储
文档存储
图存储
2、Neo4j中CQL语法不支持的有()
Match
Create
Update (答案)
Delete
3、关于Neo4j中节点(Nodes),关系(Relations),属性(Properties),标签(Labels)说法不正确的有()
节点代表最终的实体对象
关系连接实体对象(Entity),关系没有方向性 (答案)
属性(Properties)表示的是实体对象(Entity)中的属性
标签(Labels)是对实体对象(Entity)做的说明
4、下列哪些场景不适合使用Neo4j.()
强相关的社交网络
电商里的物品推荐
关系中的路径查找
数据检索 (答案)
5、Neo4j中,下面()语句可以删除所有的节点和关系。
MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n, r (答案)
MATCH (n) MATCH (n)-[r]-() DELETE n, r
MATCH (n) OPTIONAL MATCH (n)-[r]-(m) DELETE n, r,m
MATCH (n) MATCH (n)-[r]-(m) DELETE n, r,m
6、Neo4j采用()查询语言。
Cassandra Query Language
Cypher Query Language (答案)
Structured Query Language
Neo4j Query Language
7、()数据库不是基于Java实现的。
Hbase
Cassandra
MongoDB (答案)
Neo4j
8、Neo4j采用的是()模式。
键值对存储
列存储
文档存储
图存储 (答案)
判断
1、搜索引擎系统常和其他NoSQL数据库或分布式文件系统配合使用。T
2、Neo4j中CQL语法不支持limit F
3、Neo4j中CQL语法中 Set的作用是可以更新实体对象(Entity)的属性,也可以新加实体对象(Entity)的属性T
4、Neo4j不支持分布式。F
简答题
1. 什么是Neo4j?并对其数据模型进行详细描述。
Neo4j是一个基于Java语言的开源图数据库系统。Neo4j具有强大的图处理和查询搜索能力,通过专用的Cypher语言完成各类操作。
Neor4j采用将数据存储为节点和边的图存储模式,其中节点表示实体、边表示实体之间的关系。
2,描述Redis的数据类型(5种)。
Redis 支持的数据类型有字符串、散列、列表、集合、有序集合。
3. Redis数据库支持的几种拓扑架构。
(1)主从复制:主从结构具有读写分离,提高效率、数据备份,提供多个副本等优点。
(2)哨兵机制: 哨兵是一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的 master 并将所有的 slave 连接到新的 master。
(3)Redis集群:Redis没有使用一致性哈希机制,而是引入了哈希槽的概念。Redis 集群有16384个哈希槽,集群中所有设备平分这些哈希槽,数据则根据其行键的散列计算结果,映射到不同的哈希槽中。
分析题
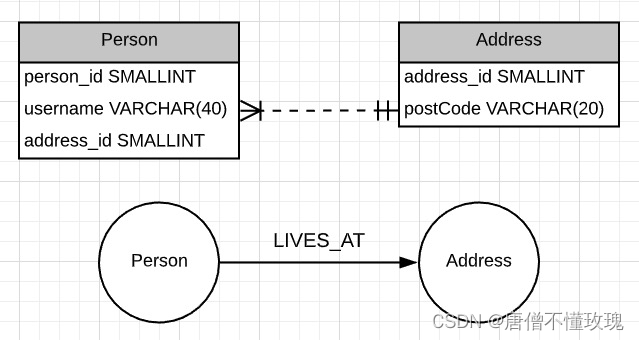
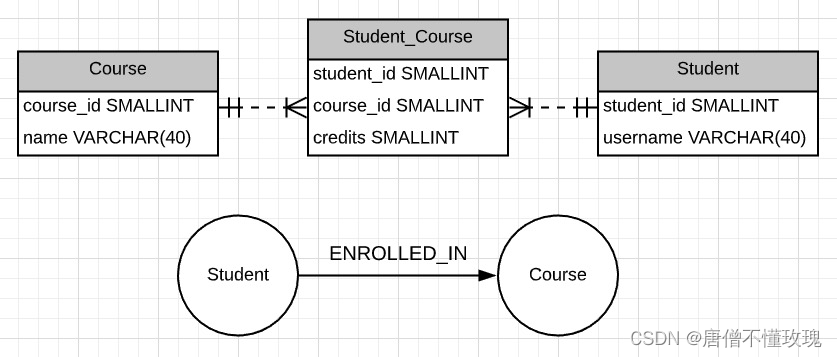
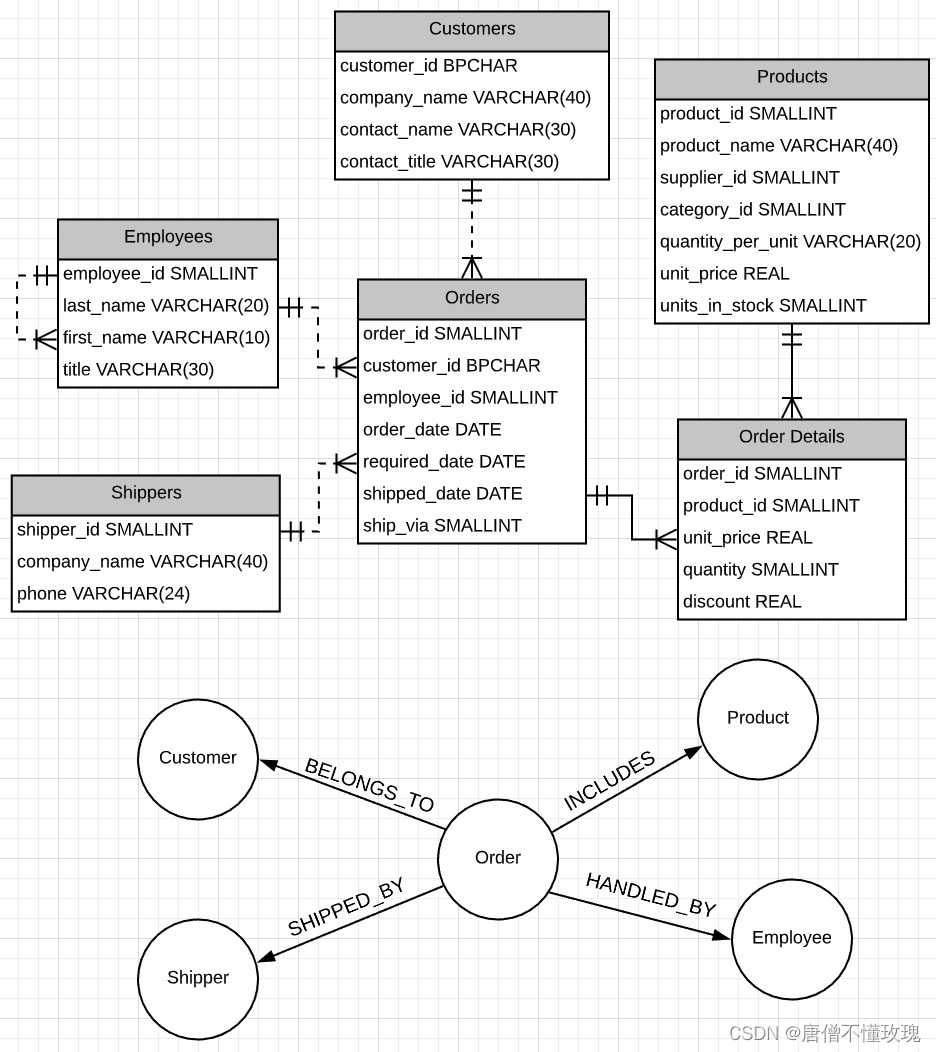
ER图转neo4j 官网说法
下图源于官网 浅分析一波
仔细的看上面的人er图
你会发现 Person中有 address的主键 address_id
也就是说 person 有了外键address_id
转到neo4j中 perdon和address也就有了关系
person-------->address 也就有了 LIVES_AT的关系