文章目录
- Abstract
- Introduction
- Adapter tuning for NLP
- Experiments
- 总结
- 参考
论文名称翻译过来就是“NLP的参数有效迁移学习”,其实就是是目前火热prompt learning(提示学习)出现的铺垫之一了。
NLP第三范式就是预训练模型微调下游任务,所有每当完成一个任务,都需要微调预训练模型。
文章总体的思路就是设计了一个adapter(类似适配器)将预训练模型微调的参数从原先的整个大模型,到只需要训练几个小的适配器,就能够达到和原先做法在下游任务差不多的效果,大大减少了模型训练的参数,提高了效率。
接下来一起稍微读一下文章。
Abstract

微调大型预训练模型是NLP中一种有效的传递机制。然而,在存在许多下游任务的情况下,微调是参数效率低下的:每个任务都需要一个全新的模型。作为替代方案,我们建议使用适配器模块进行传输。适配器模块产生了一个紧凑且可扩展的模型;它们只为每个任务添加几个可训练的参数,并且可以添加新任务,而无需重新访问以前的任务。原始网络的参数保持固定,从而产生高度的参数共享。为了证明适配器的有效性,我们将最近提出的BERT Transformer模型转移到26个不同的文本分类任务中,包括GLUE基准。适配器可以获得接近最先进的性能,同时每个任务只添加几个参数。在GLUE上,我们实现了0.4%以内的完全微调性能,每个任务只添加3.6%的参数。相比之下,每次任务的微调都会训练100%的参数。
Introduction
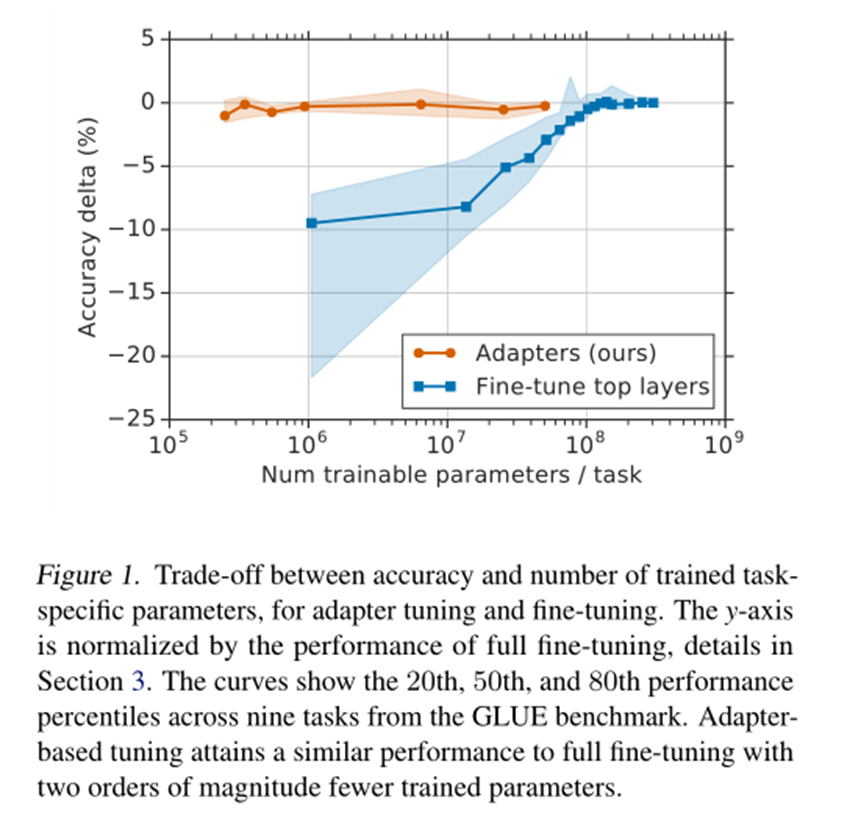
图1。在经过训练的特定任务参数的准确性和数量之间进行权衡,以进行适配器调整和微调。y轴通过完全微调的性能进行归一化,详见第3节。曲线显示了GLUE基准测试中九项任务的第20、第50和第80个性能百分位数。基于自适应的调谐获得了与完全微调类似的性能,训练参数减少了两个数量级。
别的先不谈,看这个图确实是,用了adapter训练的参数在10的6次方就可以有比较好的效果了,需要训练的参数确实少了很多。
接下来作者主要说了NLP中最常见的两种迁移学习技术是基于特征的迁移和微调。

NLP中最常见的两种迁移学习技术是基于特征的迁移和微调。相反,我们提出了一种基于适配器模块的替代传输方法(Rebuffi等人,2017)。基于特征的转移涉及预训练实值嵌入向量。这些嵌入可以是单词(Mikolov等人,2013)、句子(Cer等人,2019)或段落级别(Le&Mikolov,2014)。然后将嵌入提供给自定义的下游模型。微调包括从预先训练的网络中复制权重,并在下游任务中对其进行微调。最近的工作表明,微调通常比基于特征的转移具有更好的性能(Howard&Ruder,2018)。
然后说文章提出的adapter法相比之下效率更高。

基于特征的转移和微调都需要为每个任务设置一组新的权重。如果在任务之间共享网络的较低层,则微调的参数效率更高。然而,我们提出的适配器调整方法的参数效率甚至更高。图1展示了这种权衡。x轴显示了每个任务训练的参数数量;这对应于解决每个附加任务所需的模型大小的边际增加。基于适配器的调整需要训练两个数量级的参数来进行微调,同时获得类似的性能。
接下来讲adapters思路

大概就是说adapter需要训练的参数v是远小于w,而w是固定或者是共享的,从而提升能够训练的效率也能很好的适配下游任务。
Adapter tuning for NLP
这里最关键的估计就是这个了,即这个adapter是怎么设计的,是放在哪的。
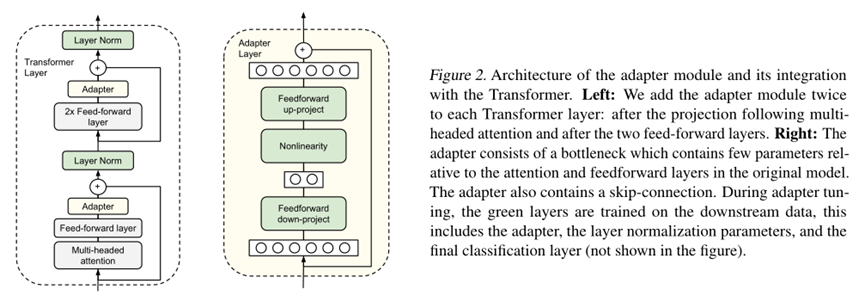
图2:适配器模块的体系结构及其与Transformer的集成。
左图:我们将适配器模块添加到每个Transformer层两次:在投影之后的多头注意力和两个前馈层之后。
右图:适配器由一个瓶颈组成,该瓶颈几乎不包含与原始模型中的注意力和前馈层相关的参数。
适配器还包含一个跳过连接。在适配器调优期间,在下游数据上训练绿色层,这包括适配器、层规范化参数和最终分类层(图中未显示)。
关于适配器的设计,简单来说就是全连接投影+激活函数+残差连接

图2显示了我们的适配器体系结构,以及它在Transformer中的应用。Transformer的每一层都包含两个主要的子层:一个注意力层和一个前馈层。两个层后面都紧接着一个投影,该投影将特征大小映射回层输入的大小。
跳过连接应用于每个子层。
每个子层的输出被馈送到层归一化中。
我们在每个子层之后插入两个串行适配器。
适配器总是直接应用于子层的输出,在投影回输入大小之后,但在添加跳过连接之前。然后,适配器的输出被直接传递到下面的层规范化中。
代码好像没放出来,差不多了。
可以看看实验结果
Experiments
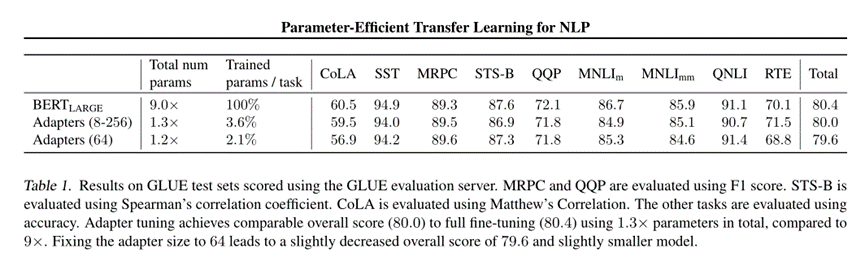
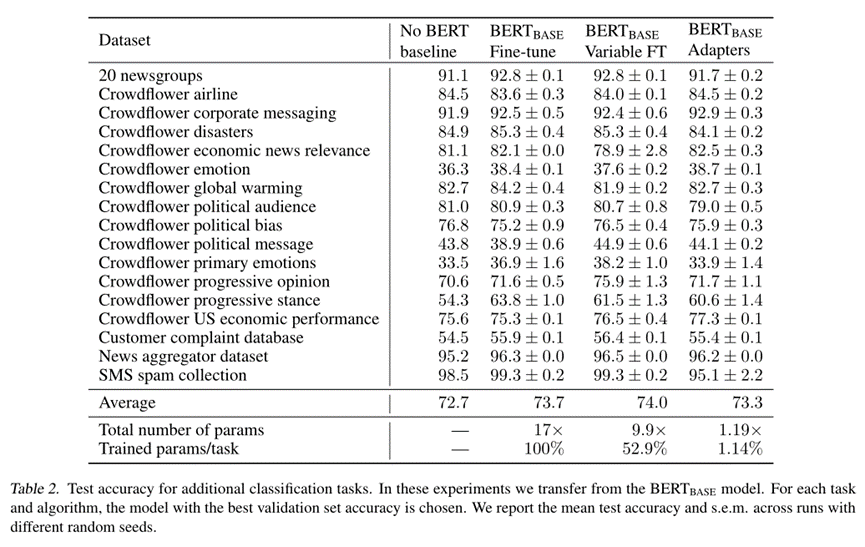
确实,adapter的确和原来微调差不多。
总结
没想到一个adapter接在预训练模型里面,便可以达到“四两拨千斤”的效果。所以说预训练模型并不需要动他,只需要对其每层的输出稍稍调整一下,就可以用到下游任务了。
参考
http://proceedings.mlr.press/v97/houlsby19a/houlsby19a.pdf