Learning-based Video Motion Magnification
哈喽,大家好呀!
这周有点开心,看到了一篇很有趣的论文。最近天气好热,明明已经十一月了,最近的温度却一直在25度以上,甚至有种可以过夏天,穿裙子的感觉。昨天纠结好久,想着今天要不要穿旗袍,因为买来之后就没怎么穿出去过,但又觉得毕竟是要去学校的,还是算了(注意仪表哈哈)。
听说JOJO要来上海了,好开心!我真的好喜欢茸茸小天使!但是没找到帅气的动图,哭哭。真的好爱茸茸!!!放个迪奥大人的动图吧!

(今日论文BGM:《黄金处刑曲》)
让我们带着黄金精神,开始读这篇我觉得非常有价值的论文!
 这篇文章的贡献如下:
这篇文章的贡献如下:
1、提出来第一个基于学习的视频运动放大方法,它实现了高质量的放大和更少的边缘伪影(如下图所示,可以看到吊车图片比左边的图像效果更好),并具有更好的噪声特性。
2、提出了一个合成数据生成方法,捕捉小的运动,允许学习的滤波器在真实视频中很好地推广。
接下来,我们分别来讲,首先来看模型,接下来再看数据集
Problem statement
给定一个图像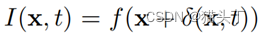 其中,x表示位置,t表示时间,
其中,x表示位置,t表示时间,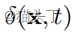 表示关于x,t的运动场,运动放大的目标即放大运动使得
表示关于x,t的运动场,运动放大的目标即放大运动使得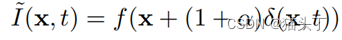 ,其中,
,其中,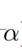 为放大因子。在实际应用中,我们往往只想要放大感兴趣区域,如下:
为放大因子。在实际应用中,我们往往只想要放大感兴趣区域,如下:
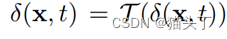
其中,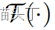 是选择器,用来选择感兴趣区域(ROI),通常是一个时域带通滤波器。
是选择器,用来选择感兴趣区域(ROI),通常是一个时域带通滤波器。
为了简化训练,只考虑一个简单的两帧输入情况。
模型结构
整个模型分为三个部分,编码器,操纵器和解码器,如下所示:
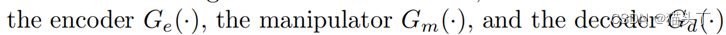
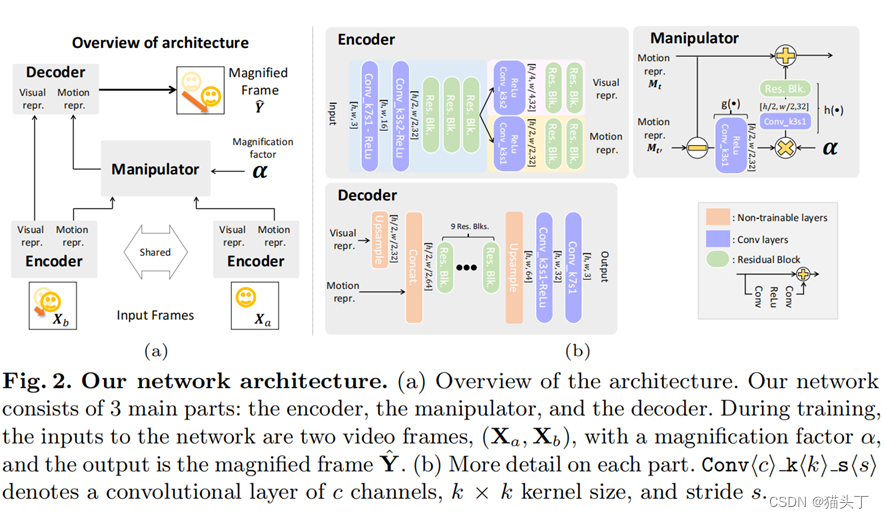 该编码器作为一个空间分解滤波器,提取一个运动表示。
该编码器作为一个空间分解滤波器,提取一个运动表示。
操纵器接收此运动表示并用来放大运动(乘以放大因子)。
最后,解码器将修改后的表示重构为所产生的运动放大帧。
编码器和解码器是完全基于卷积的,并使用残差快来生成高质量的输出。我们在编码器开始时下采样,在解码器结束时进行上采样。实验发现,编码器中有3个3*3的残差块,解码器中有9个残差块效果最好。
我们引入编码器的另一个输出,它表示强度信息(视觉表示),类似于可操纵金字塔分解的振幅。(如图所示有Motion repr.和Visual repr.)这种表示可以减少不期望的强度放大以及最终输出中的噪声。
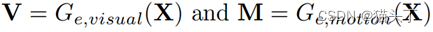
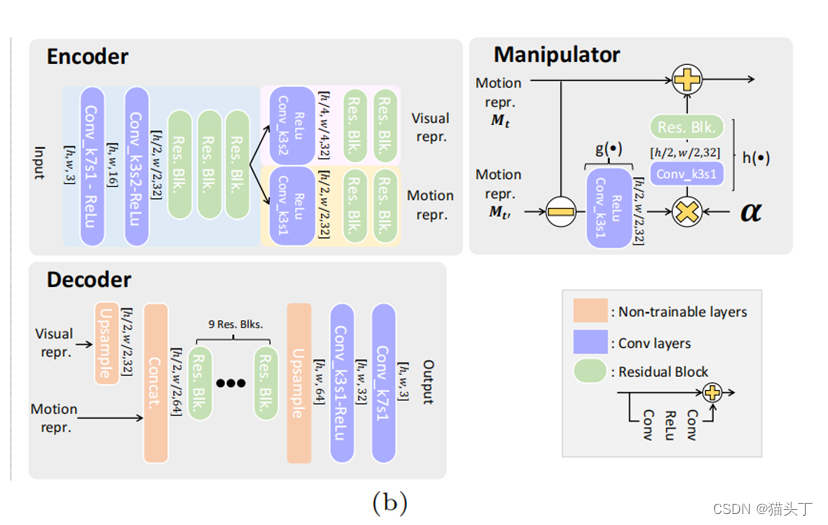
关于操纵器,我们想学习一个运动表示,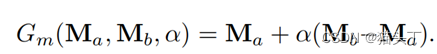 它是线性的。因此,我们的操纵器通过取两个给定帧的运动表示之间的差异,并直接取差之后乘以一个放大系数。
它是线性的。因此,我们的操纵器通过取两个给定帧的运动表示之间的差异,并直接取差之后乘以一个放大系数。
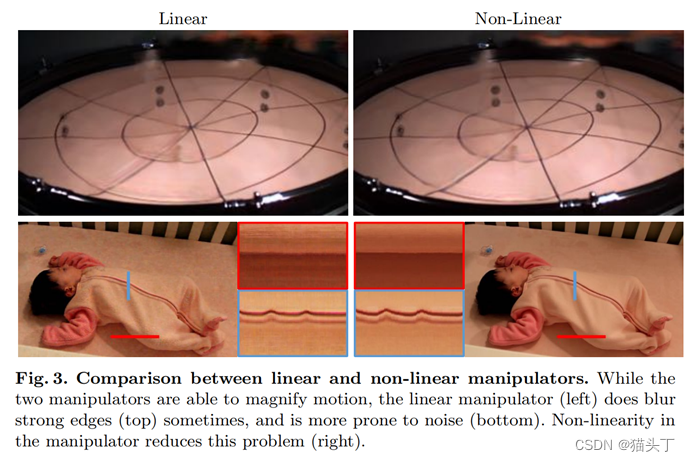
在实际应用中,我们发现操纵器的一些非线性提高了结果的质量。
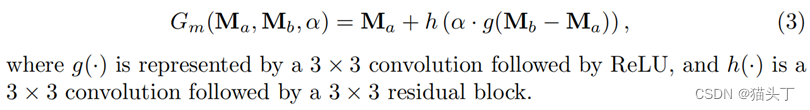 这里g代表一个33的卷积后面跟ReLU,h是一个33的卷积后面跟一个3*3的残差块。如下图对比了线性和非线性的效果,可以看到非线性的效果更好。
这里g代表一个33的卷积后面跟ReLU,h是一个33的卷积后面跟一个3*3的残差块。如下图对比了线性和非线性的效果,可以看到非线性的效果更好。
数据集
接下来,我们来看数据集

前景对象和背景图像
我们利用真实的图像数据集因为它们具有真实的纹理。我们使用了来自MS COCO数据集的20万张图像作为背景,我们使用了7000张PASCA VOC数据集分割对象作为前景。随着运动被放大,填充被遮挡区域变得很重要,所以我们将前景对象直接粘贴到背景上进行模拟遮挡。每个训练样本包含7到15个前景对象,从其原始大小进行随机缩放。我们将缩放因子限制在2,以避免纹理模糊。背景和每个物体的运动数量和方向也是随机的,以确保网络学习局部运动。
低对比度的纹理、全局运动和静态场景
上面所讲的训练示例充满了前景和背景相遇的尖锐和强烈的边缘。这导致网络在低对比度纹理上泛化较差。为了提高在这些情况下的泛化性,我们补充了两个例子:
(1)背景是模糊的
(2)在场景中只有一个移动的背景来模仿一个大的物体
这些提高了在真实视频中大的和低对比度的物体上的性能。
小的运动可能与噪声难以区分。我们发现,在数据中包含静态场景有助于网络学习仅由噪声引起的变化。我们再加两个子集,其中:
(1)场景完全是静态的
(2)背景没有移动,但前景在移动
有了这些,我们的数据集总共包含5个部分,每个部分包含20,000个384*384的图像样本。
结果
定性比较
我们的方法很好地保留了边缘,并且具有较少的振铃伪影。如下图,显示了平衡和婴儿序列的比较,基于相位的方法显示了明显的振铃伪影,而我们的方法几乎是无伪影的。这是因为我们的表示是从例子运动端到端训练出来的,而基于相位的方法依赖于手工设计的多尺度表示,不能很好地处理强边。

定量分析
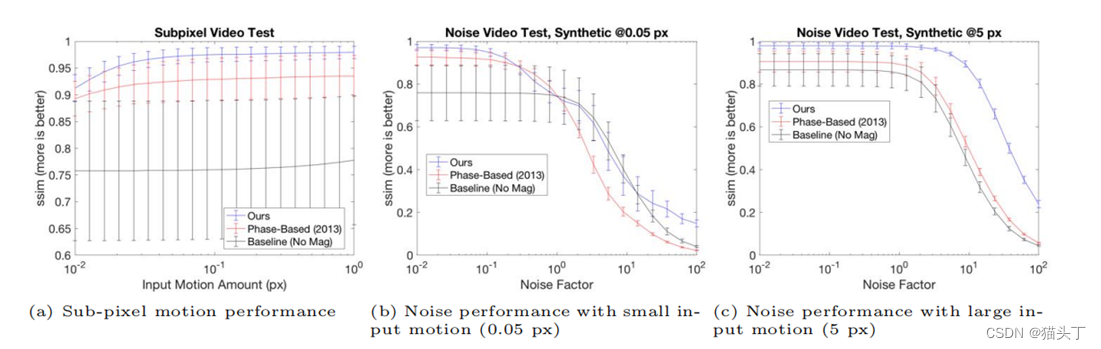
在所有的测试中,我们的方法比基于相位的方法表现得更好。如图9-(a)所示,我们的亚像素性能一直保持得很高,直到0.01像素,并且超过了1个标准差 当运动增加到0.02像素以上时,基于相位的性能。有趣的是,尽管只训练了高达100⇥的放大倍数,但该网络在最小的inpu下表现得相当好 t运动(0.01),其放大系数达到1000⇥。这表明,我们的网络更受它需要产生的输出运动量的限制,而不是它所给出的放大系数。
图9-(b、c)显示了在不同输入运动量的噪声条件下的测试结果。在所有情况下,我们的方法的性能始终高于基于相位的方法 ,当噪声因子增加到1.0以上时,它迅速下降到基线水平。比较不同的输入运动,随着输入运动变小,我们的性能下降得更快( 见图9-(b、c))。这是意料之中的,因为当运动很小时,就很难区分实际的运动和噪声。