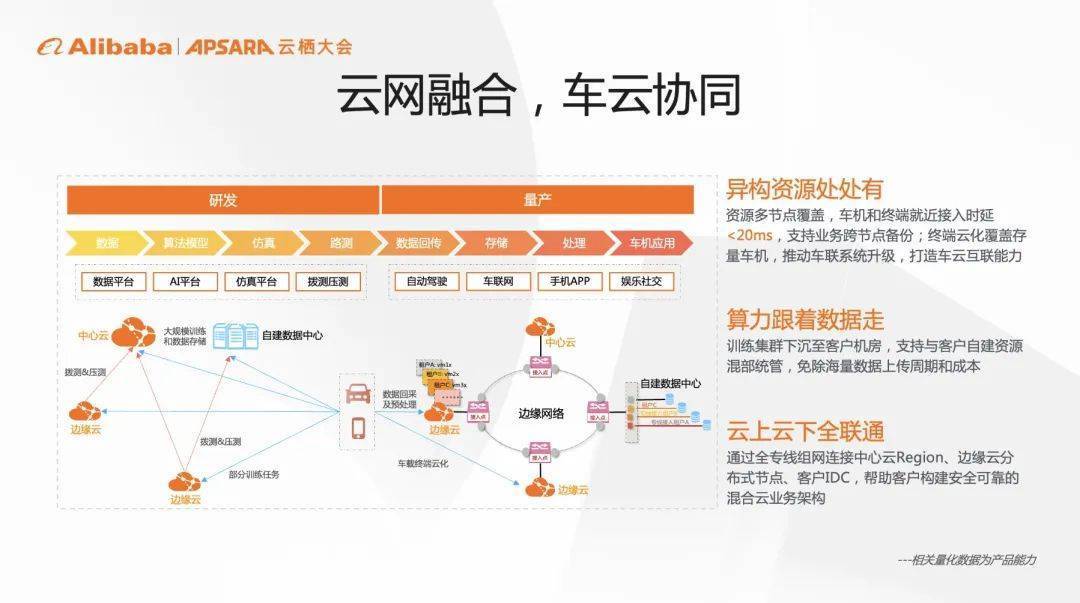
python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程。Python提供了非常好用的多进程包multiprocessing,只需要定义一个函数,Python会完成其他所有事情。借助这个包,可以轻松完成从单进程到并发执行的转换。multiprocessing支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
1. Process
创建进程的类:Process([group [, target [, name [, args [, kwargs]]]]]),target表示调用对象,args表示调用对象的位置参数元组。kwargs表示调用对象的字典。name为别名。group实质上不使用。
方法:is_alive() 、join([timeout])、run()、start()、terminate()。其中,Process以start()启动某个进程。
is_alive():判断该进程是否还活着
join([timeout]):主进程阻塞,等待子进程的退出, join方法要在close或terminate之后使用。
run():进程p调用start()时,自动调用run()
属性:authkey、daemon(要通过start()设置)、exitcode(进程在运行时为None、如果为–N,表示被信号N结束)、name、pid。其中daemon是父进程终止后自动终止,且自己不能产生新进程,必须在start()之前设置。
例1.1:创建函数并将其作为单个进程
import multiprocessing
import time
def worker(interval):
n = 5
while n > 0:
print("The time is {0}".format(time.ctime())) #输出时间的格式
time.sleep(interval)
n -= 1
if __name__ == "__main__":
p = multiprocessing.Process(target = worker, args = (3,))
p.start()
print "p.pid:", p.pid
print "p.name:", p.name
print "p.is_alive:", p.is_alive()结果
| 1 2 3 4 5 6 7 8 |
|
例1.2:创建函数并将其作为多个进程
import multiprocessing
import time
def worker_1(interval):
print "worker_1"
time.sleep(interval)
print "end worker_1"
def worker_2(interval):
print "worker_2"
time.sleep(interval)
print "end worker_2"
def worker_3(interval):
print "worker_3"
time.sleep(interval)
print "end worker_3"
if __name__ == "__main__":
p1 = Process(target=worker_1, args=(6,))
p2 = Process(target=worker_2, args=(4,))
p3 = Process(target=worker_3, args=(2,))
p1.start() p2.start() p3.start()
print("The number of CPU is:" + str(cpu_count()))
for p in active_children():
print("child p.name:=%s" % p.name + "\tp.id=%s" % str(p.pid))
print(p1.pid)
print("END-----")结果
| 1 2 3 4 5 6 7 8 9 10 11 | The number of CPU is:4 |
例1.3:将进程定义为类
import multiprocessing
import time
class ClockProcess(multiprocessing.Process):
def __init__(self, interval):
multiprocessing.Process.__init__(self)
self.interval = interval
def run(self):
n = 5
while n > 0:
print("the time is {0}".format(time.ctime()))
time.sleep(self.interval)
n -= 1
if __name__ == '__main__':
p = ClockProcess(3)
p.start() 注:进程p调用start()时,自动调用run()
结果
| 1 2 3 4 5 |
|
例1.4:daemon程序对比结果
#1.4-1 不加daemon属性
import multiprocessing
import time
def worker(interval):
print("work start:{0}".format(time.ctime()));
time.sleep(interval)
print("work end:{0}".format(time.ctime()));
if __name__ == "__main__":
p = multiprocessing.Process(target = worker, args = (3,))
p.start()
print "end!"结果
| 1 2 3 |
|
#1.4-2 加上daemon属性
import multiprocessing
import time
def worker(interval):
print("work start:{0}".format(time.ctime()));
time.sleep(interval)
print("work end:{0}".format(time.ctime()));
if __name__ == "__main__":
p = multiprocessing.Process(target = worker, args = (3,))
p.daemon = True
p.start()
print "end!"结果
| 1 |
|
注:因子进程设置了daemon属性,主进程结束,它们就随着结束了。
在多线程模型中,默认情况下(sub-Thread.daemon=False)主线程会等待子线程退出后再退出,而如果sub- Thread.setDaemon(True)时,主线程不会等待子线程,直接退出,而此时子线程会随着主线程的对出而退出,避免这种情况,主线程中需要 对子线程进行join,等待子线程执行完毕后再退出。对应的,在多进程模型中,Process类也有daemon属性,而它表示的含义与 Thread.daemon类似,当设置sub-Process.daemon=True时,主进程中需要对子进程进行等待,否则子进程会随着主进程的退 出而退出
#1.4-3 设置daemon执行完结束的方法
import multiprocessing
import time
def worker(interval):
print("work start:{0}".format(time.ctime()));
time.sleep(interval)
print("work end:{0}".format(time.ctime()));
if __name__ == "__main__":
p = multiprocessing.Process(target = worker, args = (3,))
p.daemon = True
p.start()
p.join()
print "end!"结果
| 1 2 3 |
|
2. Lock
当多个进程需要访问共享资源的时候,Lock可以用来避免访问的冲突。
import multiprocessing
import sys
def worker_with(lock, f):
with lock:
fs = open(f, 'a+')
n = 10
while n > 1:
fs.write("Lockd acquired via with\n")
n -= 1
fs.close()
def worker_no_with(lock, f):
lock.acquire()
try:
fs = open(f, 'a+')
n = 10
while n > 1:
fs.write("Lock acquired directly\n")
n -= 1
fs.close()
finally:
lock.release()
if __name__ == "__main__":
lock = multiprocessing.Lock()
f = "file.txt"
w = multiprocessing.Process(target = worker_with, args=(lock, f))
nw = multiprocessing.Process(target = worker_no_with, args=(lock, f))
w.start()
nw.start()
print "end"结果(输出文件)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
3. Semaphore
Semaphore用来控制对共享资源的访问数量,例如池的最大连接数。
import multiprocessing
import time
def worker(s, i):
s.acquire()
print(multiprocessing.current_process().name + "acquire");
time.sleep(i)
print(multiprocessing.current_process().name + "release\n");
s.release()
if __name__ == "__main__":
s = multiprocessing.Semaphore(2)
for i in range(5):
p = multiprocessing.Process(target = worker, args=(s, i*2))
p.start()结果
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
例子2:
import multiprocessing
import time
def worker(s, ):
s.acquire()
print(multiprocessing.current_process().name + "acquire")
time.sleep(1)
# print(multiprocessing.current_process().name + "release\n")
s.release()
if __name__ == "__main__":
s = multiprocessing.Semaphore(2)
for i in range(5):
p = multiprocessing.Process(target = worker, args=(s, ))
# time.sleep(0.01)
p.start()
#####结果######
Process-4acquire
Process-3acquire
Process-1acquire
Process-2acquire
Process-5acquire4. Event
Event用来实现进程间同步通信。
import multiprocessing
import time
def wait_for_event(e):
print("wait_for_event: starting")
e.wait() #一直阻塞的去等待set值
print('*****')
print("wairt_for_event: e.is_set()->" + str(e.is_set()))
def wait_for_event_timeout(e, t):
print("wait_for_event_timeout:starting")
e.wait(2) #等2s去取set值
print('------')
print("wait_for_event_timeout:e.is_set->" + str(e.is_set()))
if __name__ == "__main__":
e = multiprocessing.Event()
# e.set()
w1 = multiprocessing.Process(name="block", target=wait_for_event, args=(e,))
w2 = multiprocessing.Process(name="non-block", target=wait_for_event_timeout, args=(e, 2))
w1.start()
w2.start()
time.sleep(10)
e.set() # 设置set的值
print("main: event is set")结果
| 1 2 3 4 5 | wait_for_event: starting |
5. Queue
Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。put方法用以插入数据到队列中,put方法还有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,会抛出Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常。
get方法可以从队列读取并且删除一个元素。同样,get方法有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。如果blocked为False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常。Queue的一段示例代码:
import multiprocessing
def writer_proc(q):
try:
q.put(1, block = False)
except:
pass
def reader_proc(q):
try:
print q.get(block = False)
except:
pass
if __name__ == "__main__":
q = multiprocessing.Queue()
writer = multiprocessing.Process(target=writer_proc, args=(q,))
writer.start()
reader = multiprocessing.Process(target=reader_proc, args=(q,))
reader.start()
#reader.join() 这样会一直阻塞
#writer.join()结果
| 1 |
|
6. Pipe
Pipe方法返回(conn1, conn2)代表一个管道的两个端。Pipe方法有duplex参数,如果duplex参数为True(默认值),那么这个管道是全双工模式,也就是说conn1和conn2均可收发。duplex为False,conn1只负责接受消息,conn2只负责发送消息。
send和recv方法分别是发送和接受消息的方法。例如,在全双工模式下,可以调用conn1.send发送消息,conn1.recv接收消息。如果没有消息可接收,recv方法会一直阻塞。如果管道已经被关闭,那么recv方法会抛出EOFError。
import multiprocessing
import time
def proc1(pipe):
# while True:
for i in range(3):
print("send: %s" %(i))
pipe.send(i)
time.sleep(1)
def proc2(pipe):
while True:
print ("proc2 rev:", pipe.recv())
time.sleep(1)
def proc3(pipe):
while True:
print("PROC3 rev:", pipe.recv())
time.sleep(1)
if __name__ == "__main__":
pipe = multiprocessing.Pipe()
p1 = multiprocessing.Process(target=proc1, args=(pipe[0],))
p2 = multiprocessing.Process(target=proc2, args=(pipe[1],))
#p3 = multiprocessing.Process(target=proc3, args=(pipe[1],))
p1.start()
p2.start()
# p3.start()
# p1.join()
# p2.join()
# p3.join()
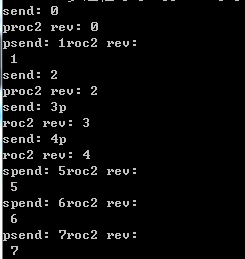
#######结果########
send: 0
proc2 rev: 0
send: 1
proc2 rev: 1
send: 2
proc2 rev: 2结果
7. Pool
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。
例子:
import multiprocessing
import time
def func(msg, a):
# if a == 1:
# time.sleep(8)
# print(1)
print("msg:", msg)
print("++++")
time.sleep(3)
# print("end")
if __name__ == "__main__":
pool = multiprocessing.Pool(processes=3)
for i in range(7):
msg = "hello %d" % (i)
a = i
# 维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
pool.apply_async(func, (msg, a, ))
pool.close()
# 调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
pool.join()
print("Sub-process(es) done.")例7.1:使用进程池(非阻塞)
#coding: utf-8
import multiprocessing
import time
def func(msg):
print "msg:", msg
time.sleep(3)
print "end"
if __name__ == "__main__":
pool = multiprocessing.Pool(processes = 3)
for i in xrange(4):
msg = "hello %d" %(i)
pool.apply_async(func, (msg, )) #维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
print "Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~"
pool.close()
pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print "Sub-process(es) done."一次执行结果
| 1 2 3 4 5 6 7 8 9 10 |
|
函数解释:
- apply_async(func[, args[, kwds[, callback]]]) 它是非阻塞,apply(func[, args[, kwds]])是阻塞的(理解区别,看例1例2结果区别)
- close() 关闭pool,使其不在接受新的任务。
- terminate() 结束工作进程,不在处理未完成的任务。
- join() 主进程阻塞,等待子进程的退出, join方法要在close或terminate之后使用。
执行说明:创建一个进程池pool,并设定进程的数量为3,xrange(4)会相继产生四个对象[0, 1, 2, 4],四个对象被提交到pool中,因pool指定进程数为3,所以0、1、2会直接送到进程中执行,当其中一个执行完事后才空出一个进程处理对象3,所以会出现输出“msg: hello 3”出现在"end"后。因为为非阻塞,主函数会自己执行自个的,不搭理进程的执行,所以运行完for循环后直接输出“mMsg: hark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~”,主程序在pool.join()处等待各个进程的结束。
例7.2:使用进程池(阻塞)
#coding: utf-8
import multiprocessing
import time
def func(msg):
print "msg:", msg
time.sleep(3)
print "end"
if __name__ == "__main__":
pool = multiprocessing.Pool(processes = 3)
for i in xrange(4):
msg = "hello %d" %(i)
pool.apply(func, (msg, )) #维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
print "Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~"
pool.close()
pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print "Sub-process(es) done."一次执行的结果
| 1 2 3 4 5 6 7 8 9 10 |
|
例7.3:使用进程池,并关注结果
import multiprocessing
import time
def func(msg):
print "msg:", msg
time.sleep(3)
print "end"
return "done" + msg
if __name__ == "__main__":
pool = multiprocessing.Pool(processes=4)
result = []
for i in xrange(3):
msg = "hello %d" %(i)
result.append(pool.apply_async(func, (msg, )))
pool.close()
pool.join()
for res in result:
print ":::", res.get()
print "Sub-process(es) done."一次执行结果
| 1 2 3 4 5 6 7 8 9 10 |
|
例7.4:使用多个进程池
import multiprocessing
import os, time, random
def Lee(i):
print('1', i)
time.sleep(3)
print('-----')
# print("\nRun task Lee-%s" %(os.getpid())) #os.getpid()获取当前的进程的ID
# start = time.time()
# time.sleep(random.random() * 10) #random.random()随机生成0-1之间的小数
# end = time.time()
# print('Task Lee, runs %0.2f seconds.' % (end - start))
def Marlon(i):
print('2', i)
time.sleep(3)
print('-----')
# print("\nRun task Marlon-%s" % (os.getpid()))
# start = time.time()
# time.sleep(random.random() * 40)
# end = time.time()
# print('Task Marlon runs %0.2f seconds.' %(end - start))
def Allen(i):
print('3', i)
time.sleep(3)
print('-----')
# print("\nRun task Allen-%s" %(os.getpid()))
# start = time.time()
# time.sleep(random.random() * 30)
# end = time.time()
# print('Task Allen runs %0.2f seconds.' %(end - start))
def Frank(i):
print('4', i)
time.sleep(3)
print('-----')
# print("\nRun task Frank-%s" %(os.getpid()))
# start = time.time()
# time.sleep(random.random() * 20)
# end = time.time()
# print('Task Frank runs %0.2f seconds.' %(end - start))
if __name__ == '__main__':
function_list = [Lee, Marlon, Allen, Frank]
# print("parent process %s" % (os.getpid()))
pool = multiprocessing.Pool(4)
for func in function_list:
# Pool执行函数,apply执行函数,当有一个进程执行完毕后,会添加一个新的进程到pool中
for i in ['a', 'b', 'c','d', 'e', 'f', 'g']:
pool.apply_async(func, args=(i,))
print('Waiting for all subprocesses done...')
pool.close()
# 调用join之前,一定要先调用close() 函数,否则会出错, close()执行后不会有新的进程加入到pool,join函数等待素有子进程结束
pool.join()
print('All subprocesses done.')View Code
#coding: utf-8
import multiprocessing
import os, time, random
def Lee():
print "\nRun task Lee-%s" %(os.getpid()) #os.getpid()获取当前的进程的ID
start = time.time()
time.sleep(random.random() * 10) #random.random()随机生成0-1之间的小数
end = time.time()
print 'Task Lee, runs %0.2f seconds.' %(end - start)
def Marlon():
print "\nRun task Marlon-%s" %(os.getpid())
start = time.time()
time.sleep(random.random() * 40)
end=time.time()
print 'Task Marlon runs %0.2f seconds.' %(end - start)
def Allen():
print "\nRun task Allen-%s" %(os.getpid())
start = time.time()
time.sleep(random.random() * 30)
end = time.time()
print 'Task Allen runs %0.2f seconds.' %(end - start)
def Frank():
print "\nRun task Frank-%s" %(os.getpid())
start = time.time()
time.sleep(random.random() * 20)
end = time.time()
print 'Task Frank runs %0.2f seconds.' %(end - start)
if __name__=='__main__':
function_list= [Lee, Marlon, Allen, Frank]
print "parent process %s" %(os.getpid())
pool=multiprocessing.Pool(4)
for func in function_list:
pool.apply_async(func) #Pool执行函数,apply执行函数,当有一个进程执行完毕后,会添加一个新的进程到pool中
print 'Waiting for all subprocesses done...'
pool.close()
pool.join() #调用join之前,一定要先调用close() 函数,否则会出错, close()执行后不会有新的进程加入到pool,join函数等待素有子进程结束
print 'All subprocesses done.'一次执行结果
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|







![[附源码]Python计算机毕业设计Django点餐系统](https://img-blog.csdnimg.cn/8c08d098542c46779f8acca0d6c1a450.png)