目录
- session
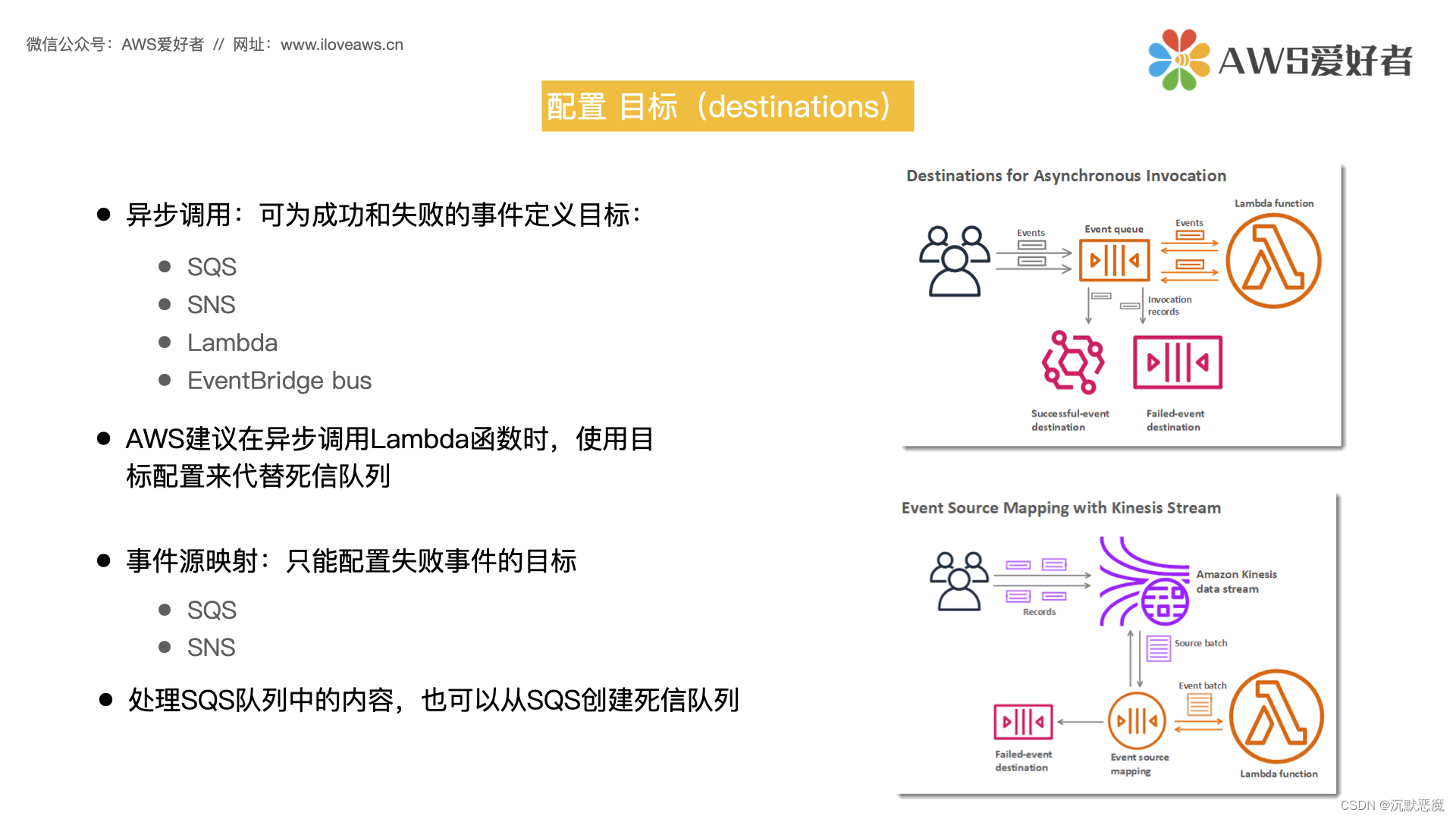
- 1. 模拟登陆取得cookie
- 2. 在登录的情况下继续取得书架上的数据
- 3. 在已经有cookie的情况下直接请求
- 总结
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
session
- session和我们之前用的request十分相似,区别在于他是一个连续状态的request,所以能保持爬虫连接的特性,比如说cookie的信息,这样我们就不需要像使用request时每次request都要带有cookie信息才能爬取到数据。
- session和request的很多方法都是想通的。
1. 模拟登陆取得cookie
难点是找到登陆请求的url和请求的参数名称,这里的小说网隐藏了,但是之前找到过的登陆接口还是能用的,现在我也没办法在现在的网页中找到隐藏的接口,就利用老的接口演示一下模拟登陆和找接口的一般性做法。
- 打开网页的登陆界面,clear所有网络抓包,登陆后在网络抓包中查看信息。
- 之前老网站是有一个login的包,里面有登录请求url和参数
现在已知:
登录url
https://passport.17k.com/ck/user/login
登录方法:post
登录账号密码参数
data = {
"loginName": "你的账号",#帐号
"password": "123456"#密码
}
import requests
# 会话
session = requests.session()#新建一个session对象
# 我们的登录信息
data = {
"loginName": "188888881",#帐号
"password": "123456"#密码
}
# 1. 登录
url = "https://passport.17k.com/ck/user/login"#登录接口rul
session.post(url, data=data)#模拟登陆
# print(session.text)
print(session.cookies) # 查看cookie

2. 在登录的情况下继续取得书架上的数据
- 找到书架数据的来源
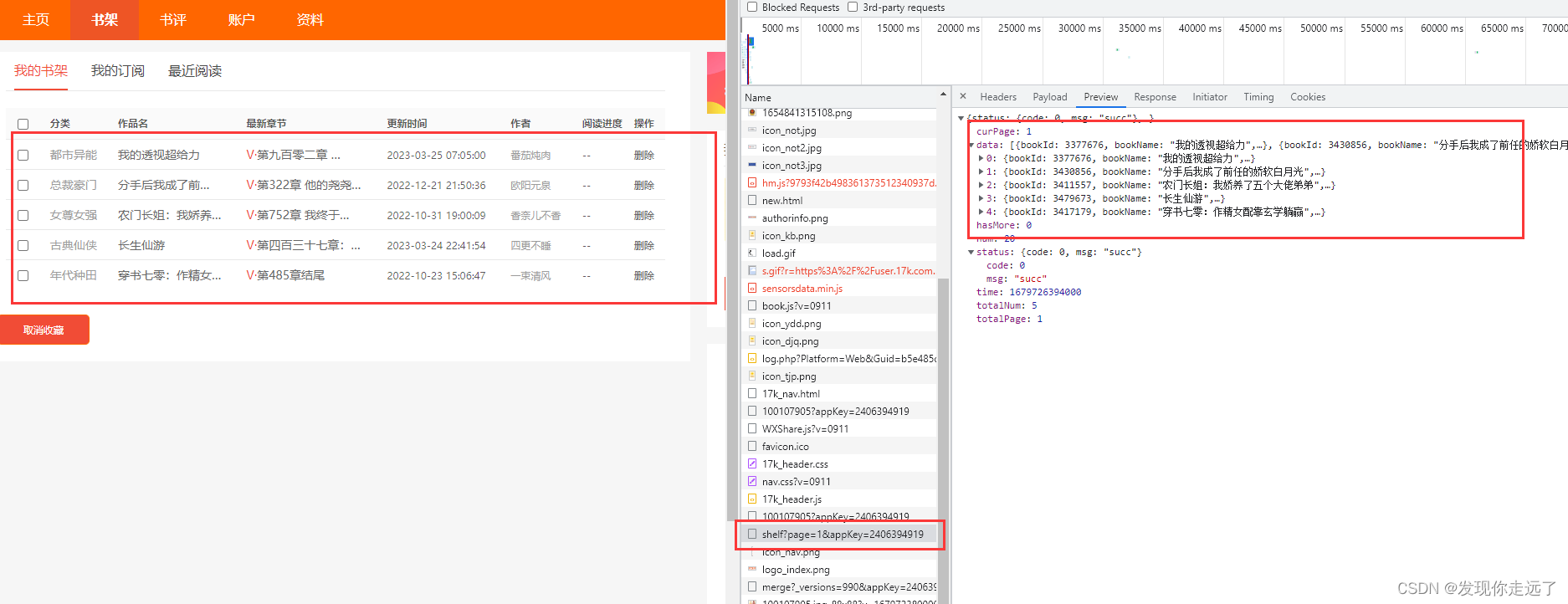
- 找到我们的cookie和请求书架数据的url接口
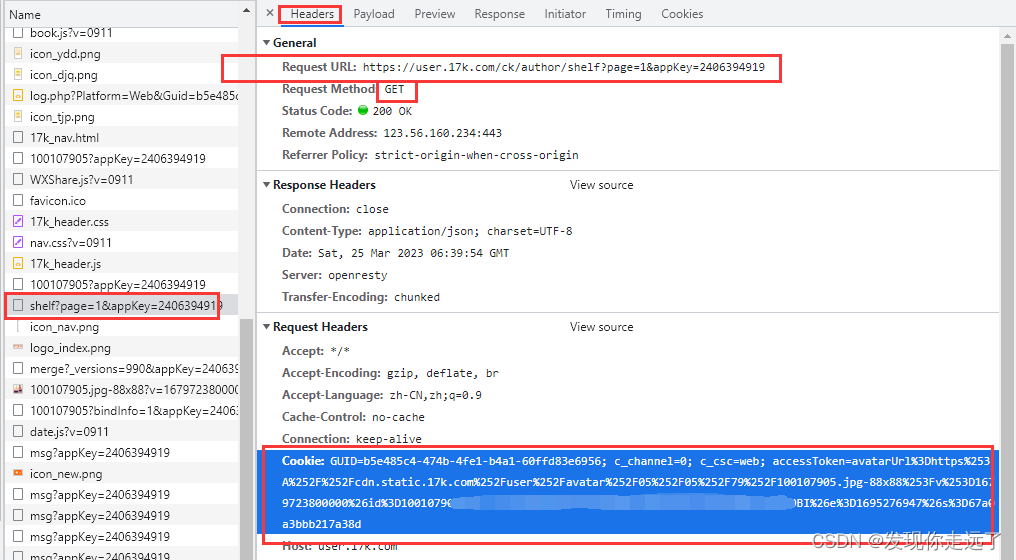

在原来的session基础上继续发送请求得到数据
import requests
# 会话
session = requests.session()#新建一个session对象
# 我们的登录信息
data = {
"loginName": "188888881",#帐号
"password": "123456"#密码
}
# 1. 登录
url = "https://passport.17k.com/ck/user/login"#登录接口rul
session.post(url, data=data)#模拟登陆
# print(session.text)
print(session.cookies) # 查看cookie
# 2. 拿书架上的数据
# 刚才的那个session中是有cookie的
resp = session.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919')
print(resp.json())
3. 在已经有cookie的情况下直接请求
黏贴cookic到我们的request请求头中
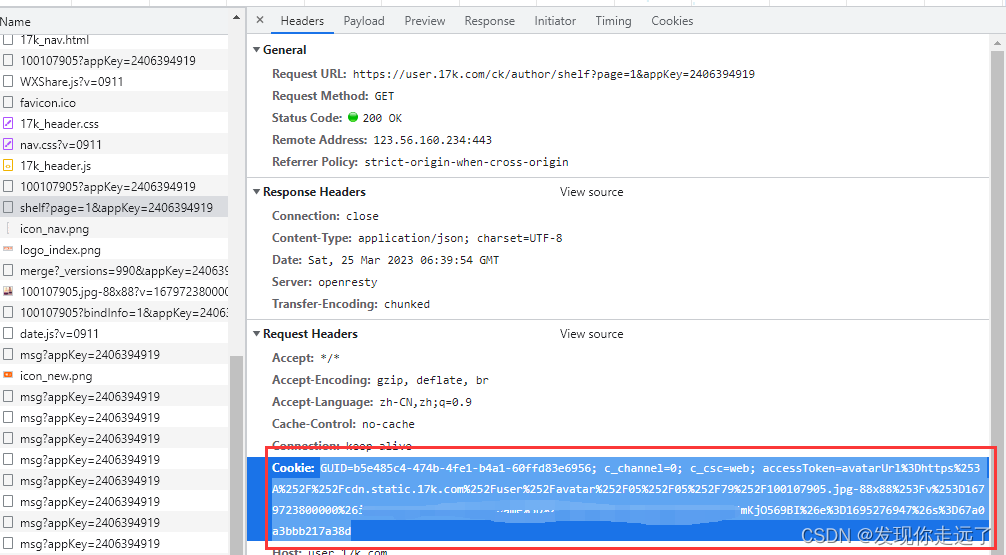
我下面的cookie不可以直接使用,我随便改动了几个数字的····大家用自己的cookie
import requests
resp = requests.get("https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919",
headers={
"Cookie": "GUID=b5e485c4-474b-4fe1-b4a1-60ffd83e6956; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F05%252F05%252F79%252F100107905.jpg-88x88%253Fv%12345678%26id%3D100107905%26nickname%3D%25E4%25B9%1234567889mKjO569BI%26e%3D1695276947%26s%3D67a0a3bbb217a38d",
})
print(resp.text)

总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
『未完待续』