文章目录
- 一、简介
- 二、创建Stream
- 三、常用操作
- 四、其他操作
一、简介
-
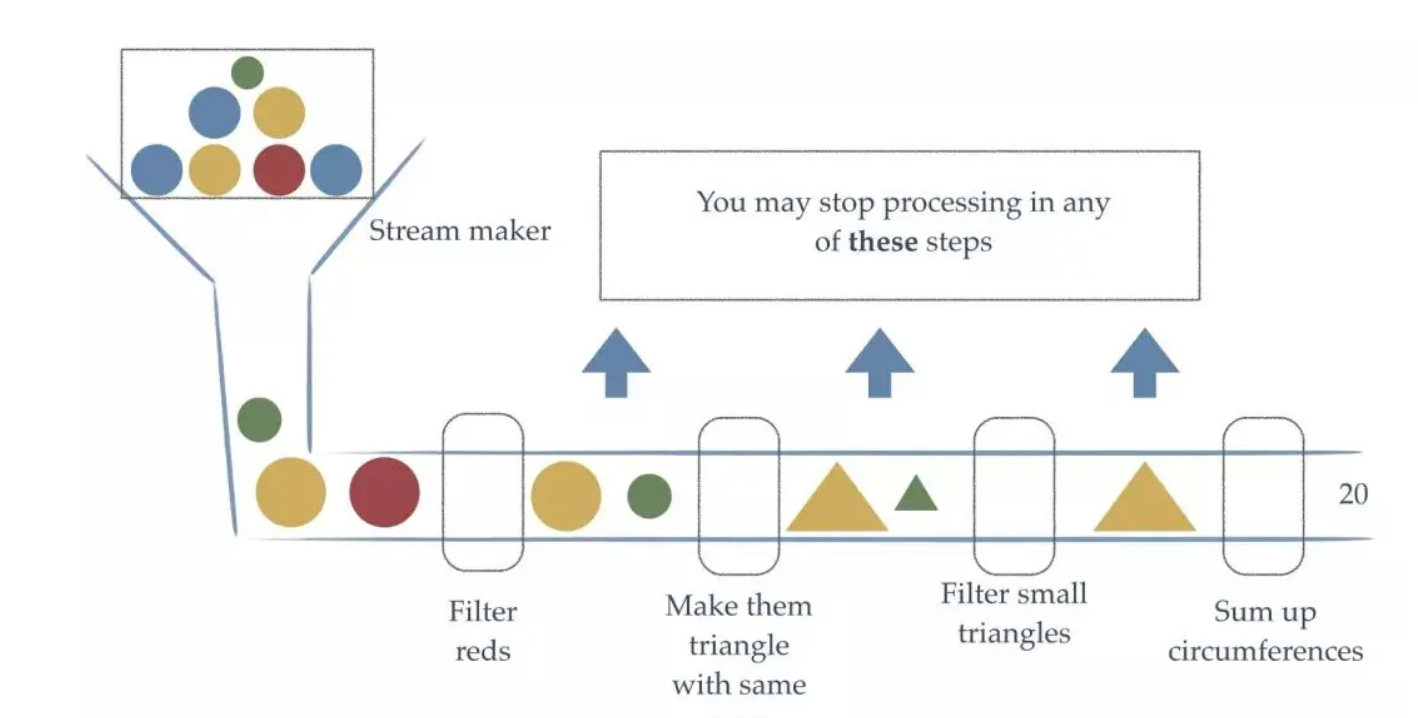
流式 API 从 Java8 开始引入,支持链式书写。
-
流只能消费一次,不能被两次消费(两次最终操作)
-
流在管道中流通,在节点被处理。
-
流【无存储】,流不是一种数据结构,流存储的只是一种数据视图。
-
Stream是独特的,既不同于io,也不同于List。
-
Stream 不是 InputStream/OutputStream,它俩首先不在同一个包,其次概念上也不一样,Stream代表的是任意Java对象的序列。
-
java.util.stream
-
java.io

-
-
Stream 不是 List,List中存储的元素是事先存在于内存中的Java对象,而Stream输出的元素可能并没有预先存储在内存中,而是通过实时计算出来的惰性对象。其次,Stream在理论上能容纳无限对象,List不能。
-
简单流式计算:
cat.map(n -> n.multiply(n)) .limit(100) .forEach(System.out::println); -
流式计算特点:
-
惰性计算,真正的计算通常只发生在最后的结果获取时。流式计算存在第一步、中间一步、最后一步的说法,只有当到达最后一步执行函数的时候,整个惰性函数才会执行。
-
一个Stream可以轻易转换为另一个Stream。
-
存在泛型接口,需要指明使用对象。
-
流式计算应该和 Lambda 表达式一起使用,符合Java8的思想(两者同时升级出现)。
cat.filter(n -> n % 2 == 0) // 不计算 .map(n -> n * n) // 不计算 .limit(100) // 不计算 .sum(); // 计算
-
-
常用操作举例
| 中间操作 | 最终操作 |
|---|---|
| map | forEach |
| filter | collect |
| limit | count |
| sorted | |
| distinct |
-
【无限序列】说明:
对于无限序列,如果直接调用 forEach() 或者 count() 求最终值,会直接进入死循环,因为无限序列永远不可能被计算完。所以我们需要先将起转变为有序序列,例如limit(100)。
-
【并行计算】
-
使用十分简单。
-
正常情况下,Stream为单线程,现在我们想要多线程。
-
parallel(),自动转化多线程。
stream.parallel() .sorted() .toArray(String[]::new);
-
二、创建Stream
4种方法,
其中第1、2种方式创建出来的流顺序是固定的,3、4不固定。
-
of():最简单的方法
Stream<String> stream = Stream.of("a","b","c"); stream.forEach(System.out::println); -
Collection:进阶
// 方式一,Collection直接调用stream方法 List list = List.of("a","b","c"); Stream stream = list.stream(); // 方式二,利用Arrays(本质和方式一差不多) Stream<String> s = Arrays.stream(new String[] { "A"}); -
Supplier(“暗示”,存储算法):采用Stream.generate(),传入Supplier对象。基于Supplier创建的Stream会不断调用
Supplier.get()方法来生成下一个元素,这种Stream中保留的不是元素,而是算法。范例:Stream<Integer> my = Stream.generate(new MySup()); my.limit(10).forEach(System.out::println); // 不断生成自然数的Supplier(范围在Integer之内) class MySup implements Supplier<Integer> { int n = 0; public Integer get() { n++; return n; } } -
其他API接口
- Files类的lines()方法,常用于遍历文本文件。
- 正则表达式Pattern对象存在 splitAsStream() 方法,可以直接把一个长字符串分割成Stream序列而不是数组。
三、常用操作
-
【三种】基本类型流
在Java中,因为Java泛型不支持基本类型,所以我们无法使用像Stream<int>这样的形式来保存int,只能采用形如Integer这样的形式。但是频繁装箱、拆箱操作会牺牲编译器的大量性能。
所以为了提高效率,Java标准库提供了三种使用基本类型的Stream,它们的使用和标准的Stream没有太大区别,直接使用:
- IntStream
- LongStream
- DoubleStream
// 1. IntStream is = Arrays.stream(new int[] { 1, 2, 3 }); // 2. 将Stream<String>转换为LongStream: LongStream s=List.of("1").stream().mapToLong(Long::parseLong); -
==map()==方法简介
- 映射操作,它将一个Stream转换为另一个Stream。
- 每一次映射都会自赋值,形如:a = a + 1,所以不再需要编写复制语句(思想)。
Stream<Integer> s1 = Stream.of(1,2,3); Stream s2 = s1.map(n->n*n); s2.forEach(System.out::println);- 如果我们查看Stream的源码,会发现map()方法接收的对象是Function接口对象,它定义了一个apply()方法,负责把一个T类型转换成R类型:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);@FunctionalInterface public interface Function<T, R> { // 将T类型转换为R: R apply(T t); }- map运算的综合应用案例
List.of(" Apple ", " pear ") .stream() // 转换为Stream .map(String::trim) // 去空格 .map(String::toLowerCase) // 变小写 .forEach(System.out::println); // 打印 -
==forEach()==遍历
stream.forEach(System.out::println); -
filter():过滤,true则通过。
IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9) // 注意lambda的编写形式 .filter(n -> n % 2 != 0) .forEach(System.out::println); -
==reduce()==方法简介
-
reduce()是聚合方法,map和filter是转换方法。
- 转换方法:元素一一对应并转换。非“最终方法”,不会触发计算。
- 聚合方法:合并计算所有值,得到一个最终结果。“最终方法”,会触发计算操作。
-
reduce()方法传入的对象是BinaryOperator接口实现,它定义了一个apply()方法,负责把上次累加的结果和本次的元素进行运算,并返回累加的结果。
-
使用较为复杂,暂时跳过。
@FunctionalInterface public interface BinaryOperator<T> { // Bi操作:两个输入,一个输出 T apply(T t, T u); } -
-
==collect()==方法简介:将Stream转化为集合。
// 1. 过滤空白字符并转为 ArrayList stream.filter(s -> s != null && !s.isBlank()) .collect(Collectors.toList()); // 2. 转为 Set stream.collect(Collectors.toSet()); // 3. 转为 Map,先 key 后 value Stream<String> stream = Stream.of("APPL:Apple"); Map<String, String> map = stream.collect(Collectors.toMap( s -> s.substring(0, s.indexOf(':')), s -> s.substring(s.indexOf(':') + 1))); -
==toArray()==方法简介:将Stream转化为数组。
String[] array = list.stream().toArray(String[]::new);
四、其他操作
-
collect分组输出
- 实际.collect()方法。
- 用途:导入学生名单,然后按班级分类输出。
List<String> list = List.of("Apple", "Banana", "Blackberry", "Coconut", "Avocado", "Cherry", "Apricots"); Map<String, List<String>> g = list.stream().collect(Collectors.groupingBy(s -> s.substring(0, 1), Collectors.toList())); System.out.println(groups); //输出:{A=[Apple, Avocado, Apricots], B=[Banana, Blackberry], C=[Coconut, Cherry]} -
sorted排序(两种方式)
- 已经实现comparable接口的,直接使用;
- 自定义Comparator比较器。
【注意sordted只是转换操作,只会返回新的Stream而不会修改原来的Stream】
// 无“自赋值” stream = stream.sorted(); stream = stream.sorted(String::compareToIgnoreCase); -
distinct去重
// 无“自赋值” stream = stream.distinct(); -
limit截取:从头开始截取。
// 无“自赋值” stream = stream.limit(20); -
skip: 扔掉前面几个元素。
stream = stream.skip(5) -
concat合并流:
Stream<String> s1 = ... ; Stream<String> s2 = ... ; Stream<String> s3 = Stream.concat(s1,s2); -
flatMap平面化:将“三维数据”转化为“二维数据”。
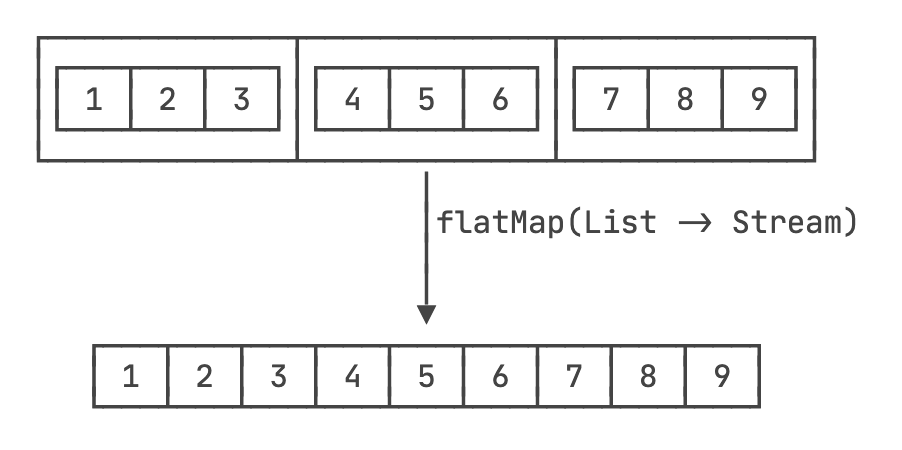
Stream< List<Integer> > s = Stream.of( Arrays.asList(1, 2, 3), Arrays.asList(4, 5, 6), Arrays.asList(7, 8, 9)); Stream<Integer> i = s.flatMap(list -> list.stream()); -
数学计算
- count():返回元素个数。
- max(Comparator<? super T> cp):找出最大元素。
- min(Comparator<? super T> cp):找出最小元素。
- sum():对所有元素求和,只适用于数值类型。
- average():对所有元素求平均数。
-
匹配
- boolean allMatch(Predicate<? super T>):所有元素均满足测试条件。
- boolean anyMatch(Predicate<? super T>):至少有一个元素满足测试条件。
-
复合实例
Stream<Student> ds= Stream.of(
new Student("zhang",99.6),
new Student("qian",78.12),
new Student("sun",59.9),
new Student("sun",60.0));
ds.filter(stu -> stu.getScore()<60.0)
.forEach(System.out::println);