文章目录
- 栈
- 栈的操作
- 栈的初始化
- 入栈
- 出栈
- 取栈顶的元素
- 判断栈是否为空
- 求栈中数据元素的个数
- 遍历栈中的所有元素
- 清空栈
- 栈的存储结构
- 顺序存储
- 链式存储
- 顺序栈和链栈的区别
- 栈的实战题目
- 队列
- 队列的操作
- 入队
- 出队
- 遍历队列
- 清空队列
- 队列的存储结构
- 顺序存储
- 循环队列
- 链式存储
- 队列实战题目
- 总结
- ❤️ 作者简介:大家好我是小鱼干儿♛是一个热爱编程、热爱算法的大三学生,蓝桥杯国赛二等奖获得者
- 🐟 个人主页 :https://blog.csdn.net/qq_52007481
- ⭐ 个人社区:【小鱼干爱编程】
- 🔥 算法专栏:算法竞赛进阶指南
- 💯 刷题网站:虽然市面上有很多的刷题网站,但是里面的题又多又杂,不适合系统性的提高算法能力,这里推荐一款我常用的刷题网站 👉点击跳转
写在前面:在学习栈和队列前我先强调一下,栈和队列都是一种编程思想,实现方式有很多种,我们只需要满足栈和队列各自的条件就可以,不必拘泥写一个类
栈
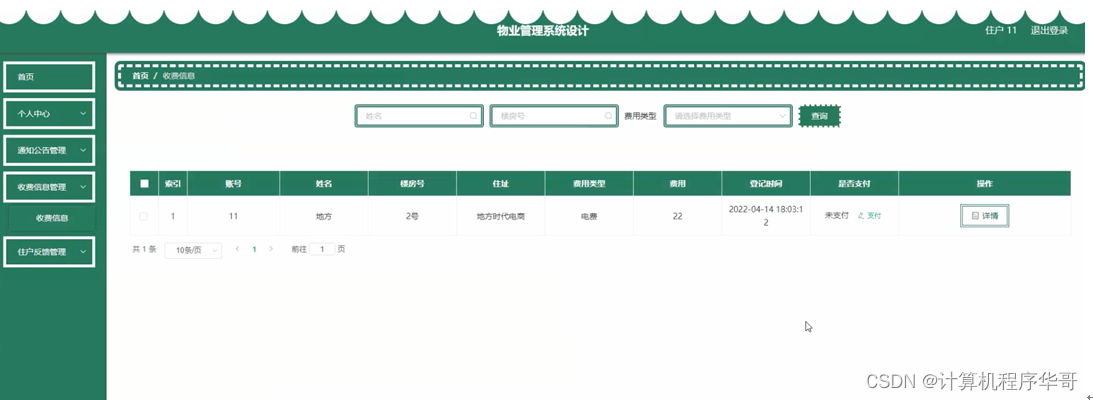
栈是限定仅在表尾进行插入和删除的线性表,允许插入、删除的一端是栈顶,另一端成为栈低,不含任何数据元素的栈称为空栈。
假设S = [x1,x2,x3,x4,x5....xn],x1为栈底元素,xn为栈顶元素,插入和删除只能从xn端操作,进栈只能是按x1,x2,x3,x4,x5....xn的顺序进栈,出栈只能从栈顶出栈,也就是说,先进的数据元素后出去,后进的数据元素先出去。后进先出(LIFO last in fist out)
栈的操作
这里我们先创建一个栈的类,这里我们只是将基础的框架搭建了起来,并没有写具体的函数内容,后面再讲解的时候会具体说明。
# 第一个讲解我们使用的是顺序栈,具体的情况后面会有详细的介绍。
class SequenceStack:
"""顺序栈"""
def __init__(self):
"""初始化"""
self.stack_arr = [] # 栈空间,用列表
self.top = 0 # 指针,指向栈顶
self.maxsize = 10 # 设置栈的最大长度
def push(self):
"""入栈"""
pass
def pop(self):
"""出栈"""
pass
def gethead(self):
"""得到栈顶的元素"""
pass
def isempty(self):
"""判断栈是否为空"""
pass
def size(self):
"""栈中的元素"""
pass
def next(self):
"""从栈顶遍历到栈底"""
pass
def clear(self):
"""清空栈"""
pass
栈的初始化
栈的初始化就是创建一个空的栈,在本文章中栈的初始化就是创建sequencestack对象
stack = SequenceStack()
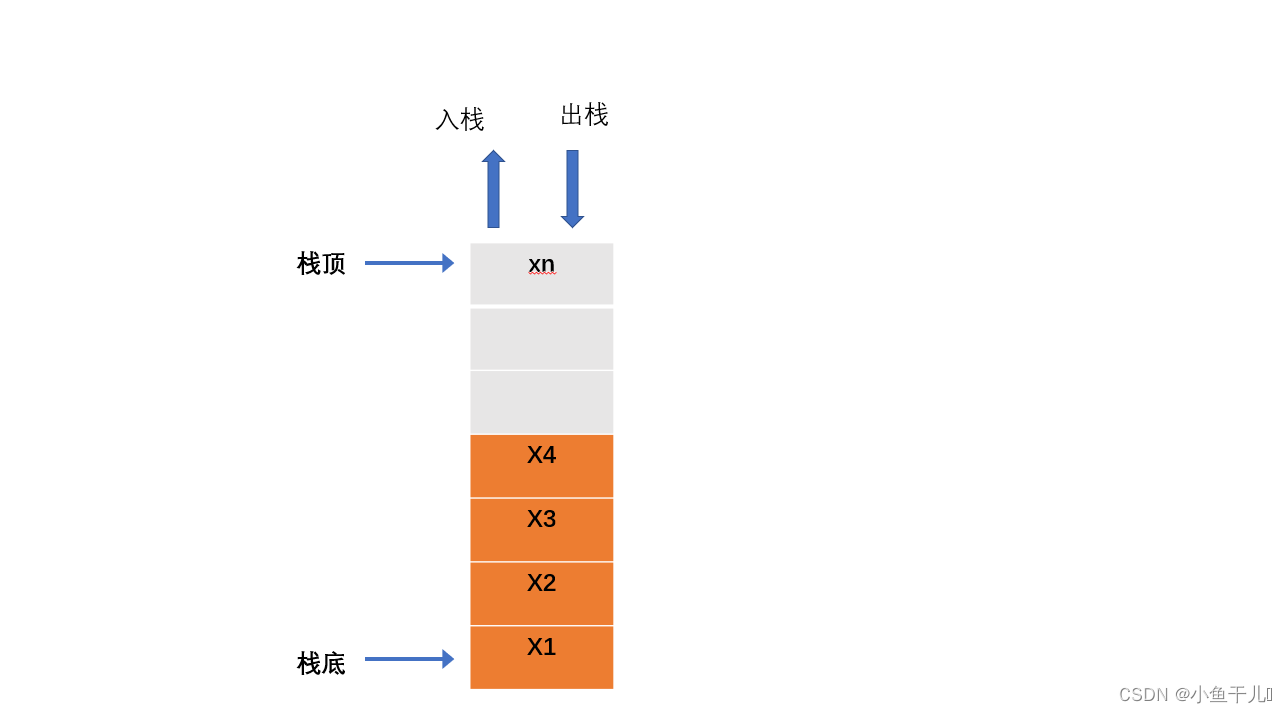
入栈
将新的元素添加到栈顶的位置,top指针向上移1

代码实现
def push(self,arg):
"""入栈"""
if self.top + 1 >= self.maxsize:
print("栈已满,请重新选择操作")
return
self.stack_arr.append(arg)
self.top+=1
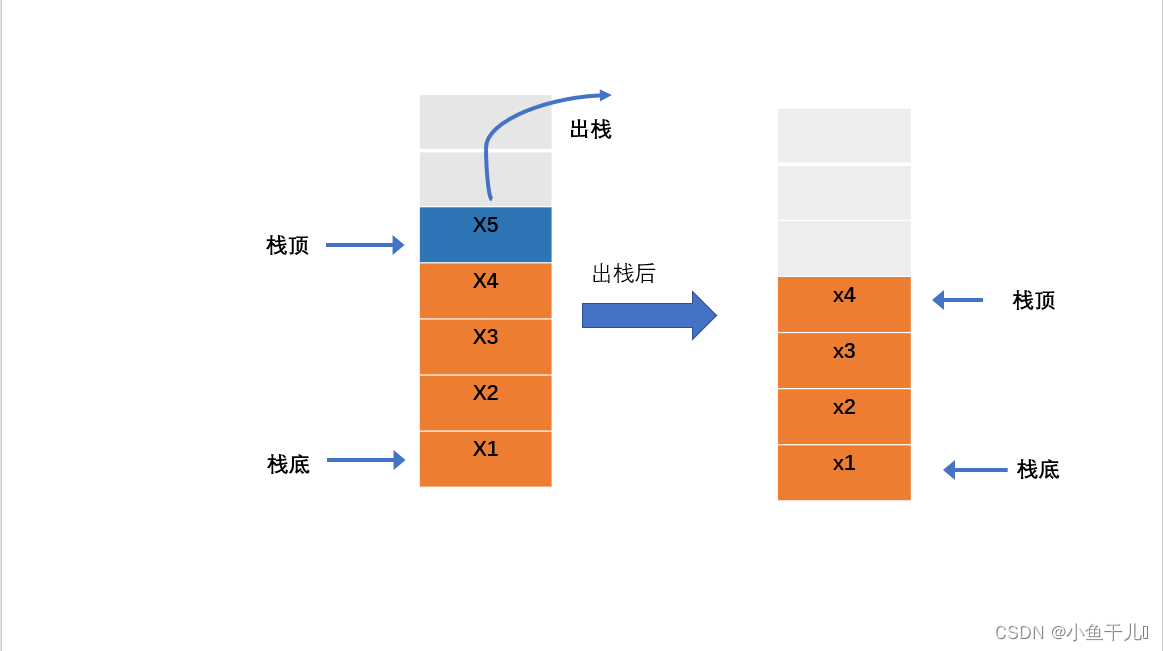
出栈
删除栈顶的数据元素
代码实现
def pop(self):
"""出栈"""
if self.top < 0:
print("栈以空无法出栈")
return
self.top -= 1
return self.stack_arr.pop()
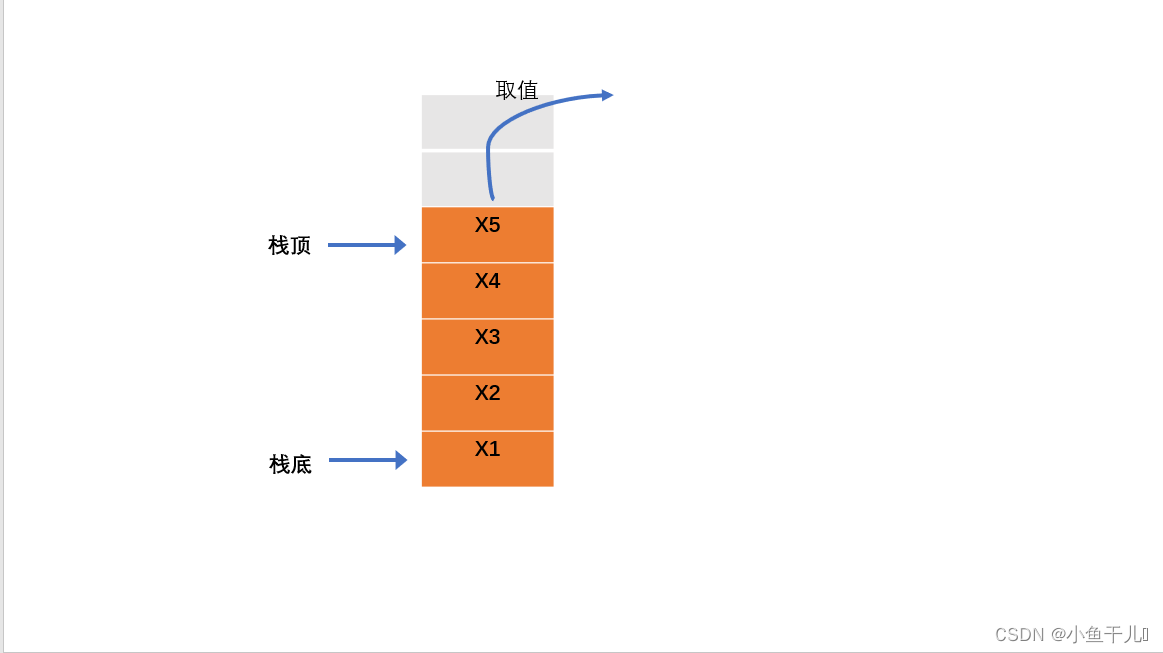
取栈顶的元素
取栈顶的数据元素,但是不会影响栈的内容
代码实现
def gethead(self):
"""得到栈顶的元素"""
if self.top < 0:
print("栈以空")
return
return self.stack_arr[self.top]
判断栈是否为空
判断栈是否为空
代码实现
def isempty(self):
"""判断栈是否为空"""
if len(self.stack_arr) == 0:
return True
else:
return False
求栈中数据元素的个数
返回栈中的数据元素的个数
代码是实现
def size(self):
"""栈中的元素"""
return len(self.stack_arr)
遍历栈中的所有元素
依次访问栈中的元素
代码实现
def next(self):
"""从栈顶遍历到栈底"""
for i in self.stack_arr:
print(i)
清空栈
清空栈中的所有内容
代码实现
def clear(self):
"""清空栈"""
self.stack_arr.clear()
self.top = -1
栈的存储结构
顺序存储
顺序栈:利用一组地址连续的的存储单元依次存放自栈底到栈顶的所有数据元素,利用了数组实现,我们将数组索引为0的一端作为栈底,另一端作为栈顶。
代码实现
class SequenceStack:
"""顺序栈"""
def __init__(self):
"""初始化"""
self.stack_arr = []
self.top = -1
self.maxsize = 10 # 设置栈的最大长度
def push(self, arg):
"""入栈"""
if self.top + 1 >= self.maxsize:
print("栈已满,请重新选择操作")
return
self.stack_arr.append(arg)
self.top += 1
def pop(self):
"""出栈"""
if self.top < 0:
print("栈以空无法出栈")
return
self.top -= 1
return self.stack_arr.pop()
def gethead(self):
"""得到栈顶的元素"""
if self.top < 0:
print("栈以空")
return
return self.stack_arr[self.top]
def isempty(self):
"""判断栈是否为空"""
if len(self.stack_arr) == 0:
return True
else:
return False
def size(self):
"""栈中的元素"""
return len(self.stack_arr)
def next(self):
"""从栈顶遍历到栈底"""
for i in self.stack_arr:
print(i)
def clear(self):
"""清空栈"""
self.stack_arr.clear()
self.top = -1
链式存储
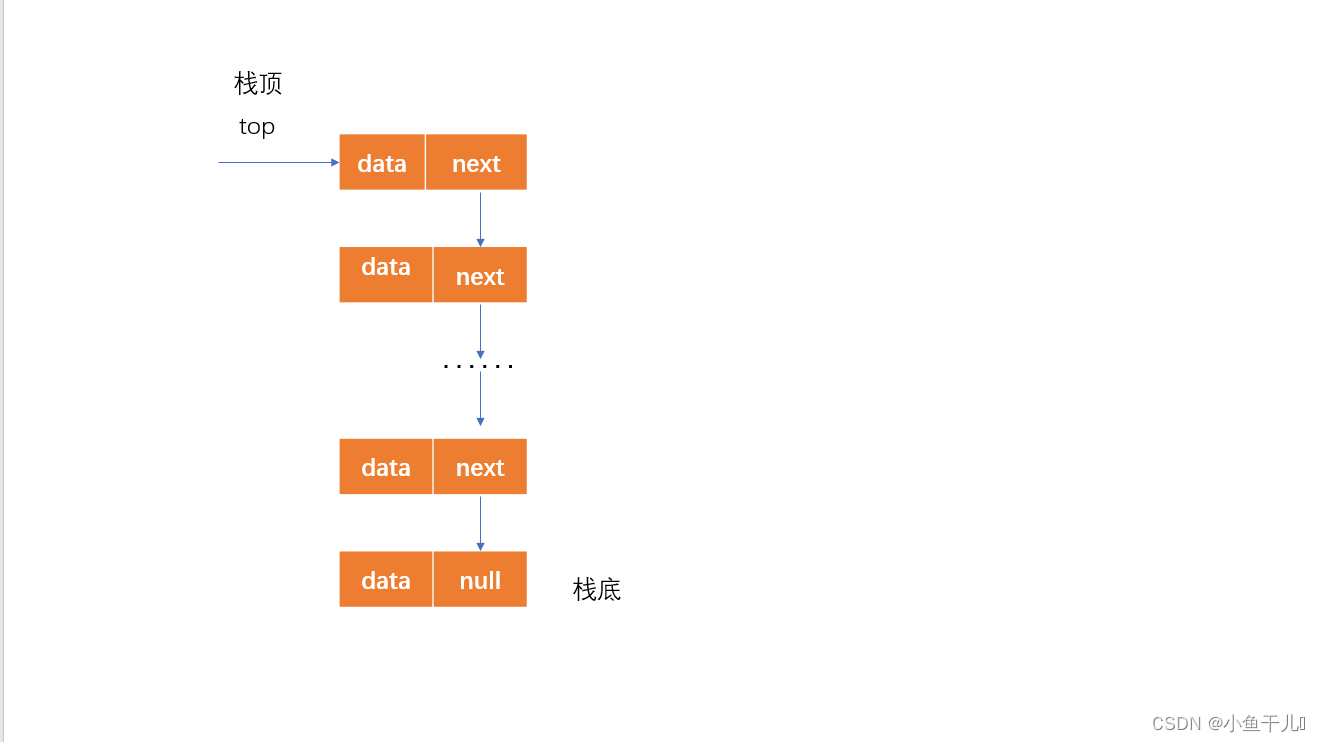
栈的链式存储结构称为链栈,利用的链表实现,链表中的每个元素由两个部分组成,一部分是存储本身的数据信息,一部分存储其直接后继的内存地址,分别叫做为
数据域,地址域
链表和顺序表的功能都一样,我就不分开介绍了。因为存储结构的不同,导致代码内部的实现方法不同,大家仔细看一下代码实现的区别就行了。
链栈的基本结构
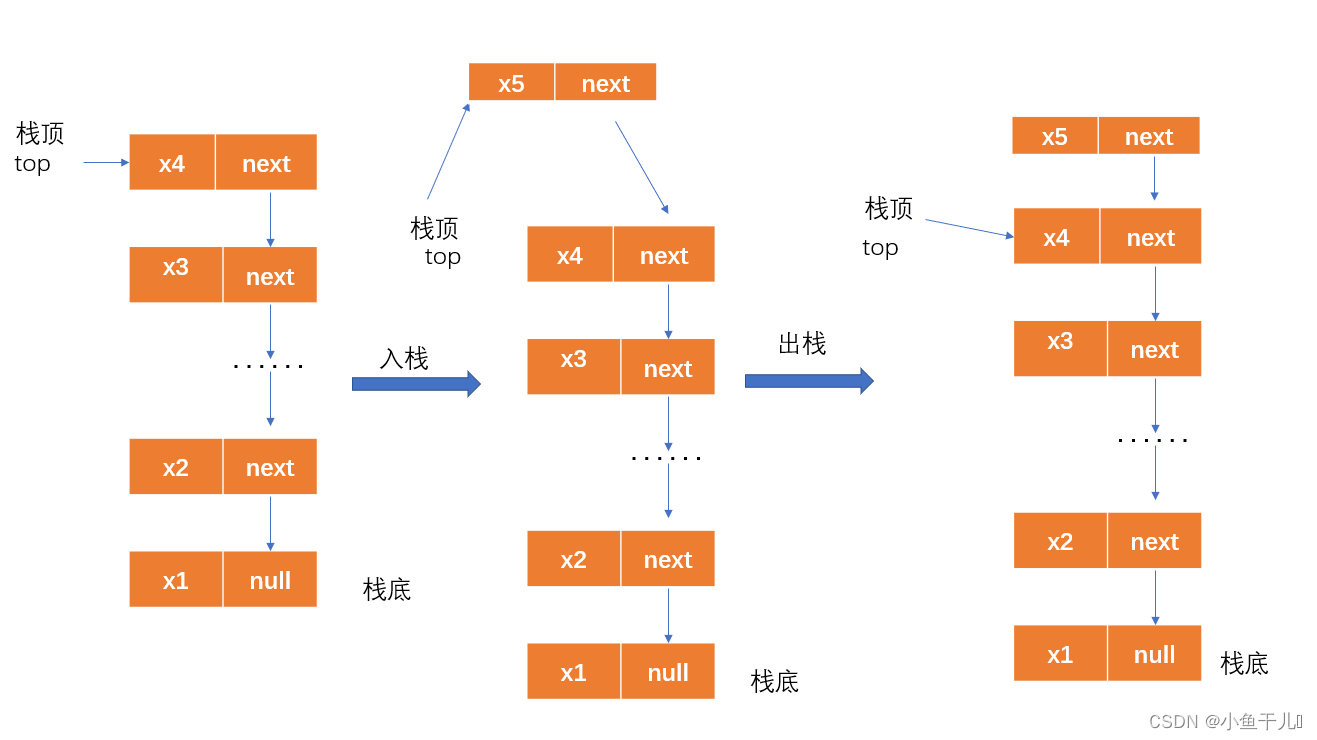
入栈出栈
代码实现
class LinkStack:
def __init__(self):
self.length = 0
self.top = None
def push(self, arg):
"""入栈"""
self.top = Node(data=arg, next=self.top)
self.length += 1
def pop(self):
"""出栈"""
if self.top == None:
print("栈已空,无法删除元素")
return
x = self.top.data
self.top = self.top.next
self.length -= 1
return x
def gethead(self):
"""获取栈顶的元素"""
if self.top == None:
print("栈已空,无法删除元素")
return
return self.top.data
def size(self):
"""求出栈中数据元素的个数"""
return self.length
def isEmpty(self):
"""判断栈是否为空"""
return self.top == None
def next(self):
"""遍历"""
p = self.top
while p != None:
print(p.data)
p = p.next
def clear(self):
"""清空栈"""
self.top = None
self.length = 0
顺序栈和链栈的区别
顺序存储:存储空间预先分配,可能会出现空间闲置或溢出的现象,元素个数不能自由扩充。
链式存储:动态分配,不会出现闲置或者栈溢出的现象,数据元素可以自由扩充。
栈的实战题目
实战的题目这里选择的就是牛客网中系列题 👉传送门
由于篇章的限制,这里我就写一个比较经典的算法有效括号匹配,其余的题目我会出新的文章
有效括号序列
class SequenceStack:
# 这个类可以选择上面的任意一个类,这里就不再进行重复了,主要说算法的实现方式
pass
def brace_match(s):
"""验证括号是否合法"""
if len(s) == 0:
"""当长度为0的时候直接返回"""
return False
match = {'}': '{', ']': '[', ')': '('} # 右括号和左括号的键值队,用于后面的判断
stack = SequenceStack() # 创建栈
for ch in s:
if ch in {'{', '[', '('}: # 只让左括号进栈
stack.push(ch)
else:
if stack.isEmpty():
return False
elif stack.gethead() == match[ch]:
# 当元素为右括号的时候,如果和栈顶的元素是一对括号的时候,栈顶的元素出栈
stack.pop() # stack_top() != match(ch)
else:
return False
# 最后判断栈是否为空,如果栈为空则代表该序列是有效的括号序列
# 如果栈非空则代表栈不为空
if stack.isEmpty():
return True
else:
return False
队列
队列是一种运算受限的线性表,元素的添加操作在表的一端进行,而另一端的删除在另一端进行,允许插入的一端称为队尾,允许删除的一端称为队头。
假设队列 q = [x1,x2,x3,,,,,xn] x1是队头,x2是队尾,队列中的数据的入队序列是x1,x2,x3,,,xn,队列也只能按这个顺序进行出队,队列的特点是先进入队列的先出来,后进队的必须等前面的数据出队完成以后才可以出队,所以队列也成为先进先出表(First in First out)

队列的操作
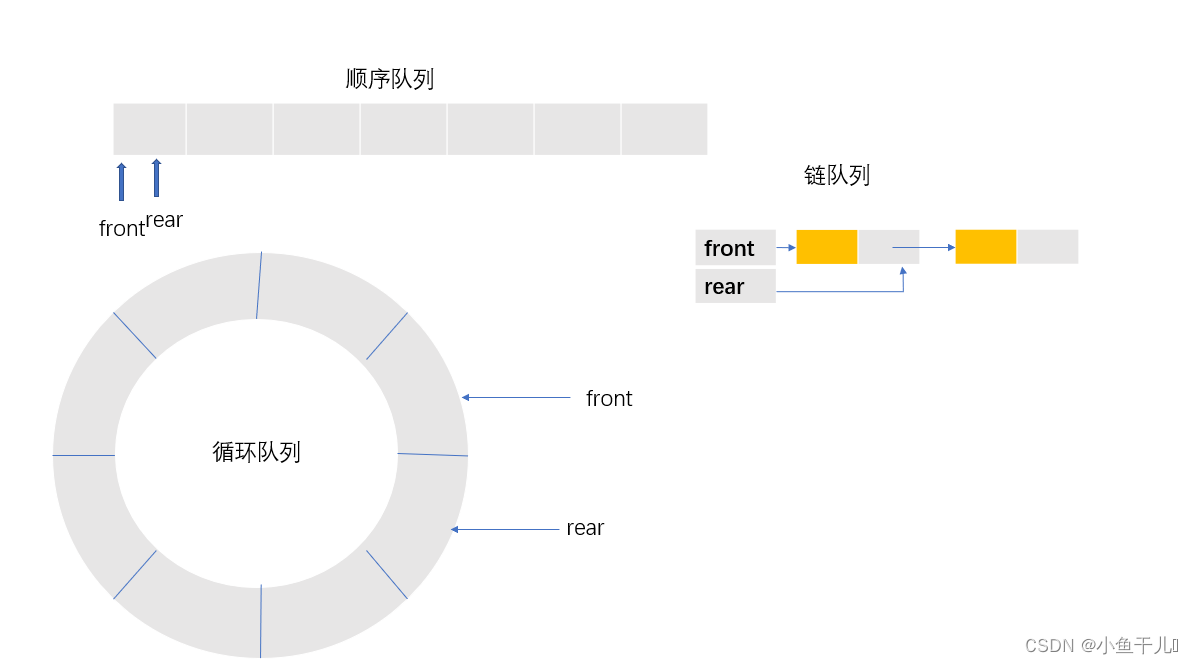
队列由由多种实现方式,这里就选三个比较有代表性的实现方式讲解’基础队列,循环队列,链队列,代码放在后面,在讲解的途中就在分别展示了
说明:循环队列也是用数组来实现的,只不过通过,一些算法实现了数组空间的复用,而且不用频繁的移动数组中的元素。
初始化队列
入队
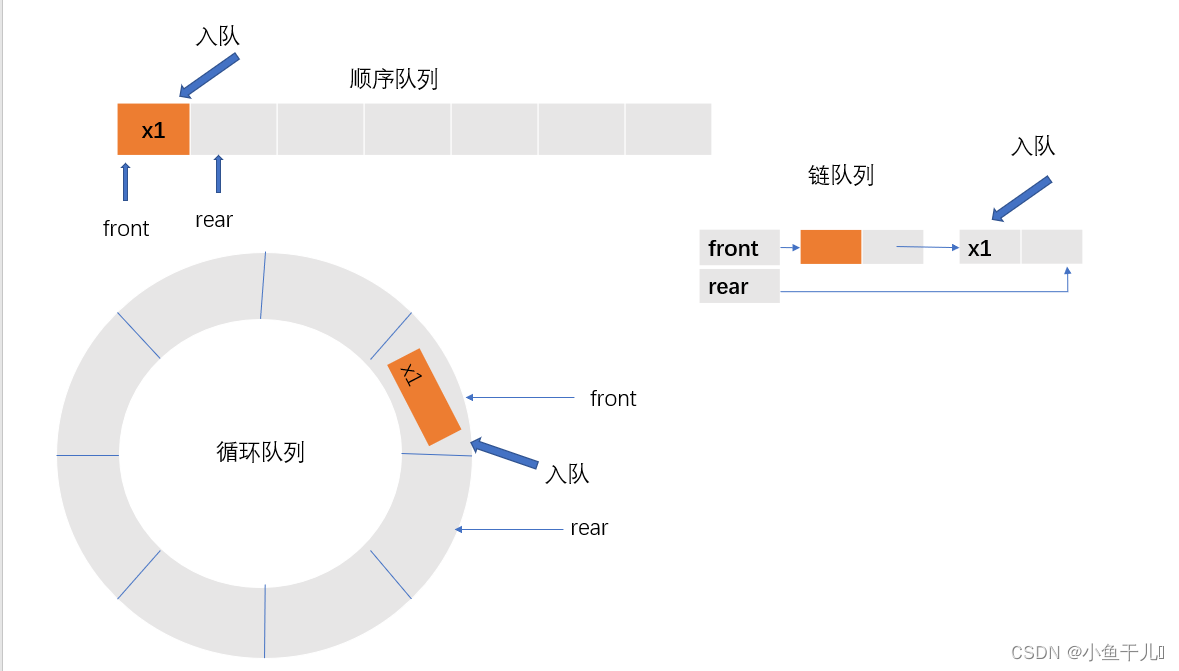
出队
原队列
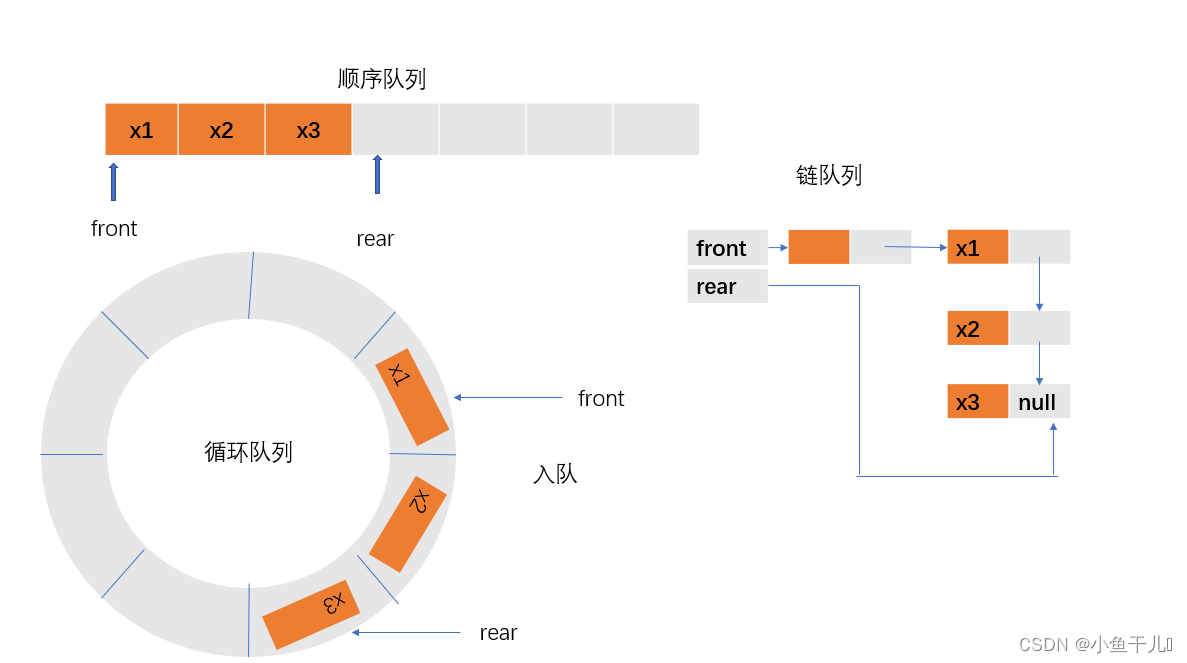
出队
顺序队列:就是将第一个元素返回出去,其余的元素向前移动一单位
循环队列:就是将队头的指针向后移动一个单位,里面的元素变为无效数据,等待覆盖
链队列:就是链表的删除,将头部指针front,指向队头的的指针移动到,指向队头后一个元素

遍历队列
顺序队列:将数组中的中的数据从开头一直遍历到最后
循环队列:创建一个临时的指针tmp该指针的位置和front指针一样,根据这个临时指针tmp的移动一次访问元素,直至临时指针和rear指针指向同一个位置的时候停止。
链队列:从头部直接遍历,循环调用next方法,直至到next==null的时候停止遍历
清空队列
清空队列就是将队列中的所有元素清空,让队列回归最初的状态
顺序队列:清空列表中的元素,并将rear指针回归到最初的位置
循环队列:清空列表中的元素,并将指针回归到最初的位置
链队列:将头部指针指向为null
队列的存储结构
顺序存储
基础队列的队头始终在数组的头部,每删除一个元素,整个队列就会向前移动一个单位,保证队列头始终在数组的第一个元素。这样我门就可以发现每执行删除操作(出队),队列就要移动一次,这样会造成系统的额外开销。
class BaseQueue:
def __init__(self):
self.data = []
self.front = 0
self.rear = 0 # 记录队尾
self.maxlength = 10 # 设置队列的最大长度
def enqueue(self, arg):
"""入队"""
if self.rear >= self.maxlength:
print("队列已满")
return
self.rear += 1
self.data.append(arg)
def dequeue(self):
"""出队"""
if self.rear == 0:
print("队列已空")
return
self.rear -= 1
return self.data.pop(0)
def gethead(self):
"""获取队头"""
if self.rear == 0:
print("队列已空")
return
return self.data[0]
def size(self):
"""返回队列的长度"""
return self.rear
def isEmpty(self):
"""判断队列是否为空"""
return self.rear == 0
def next(self):
"""遍历并输出"""
p = self.rear
for i in range(0, p):
print(self.data[i])
def clear(self):
"""清空队列"""
self.data.clear()
self.rear = 0
循环队列
循环队列,本质上还是使用数组进行实现,只是在逻辑上将首部、尾部连接起来,形成一个环状的循环队列,循环队列存储的元素个数比数组的长度少一,用来区分队满还是对待队空。
class LoopQueue:
def __init__(self):
self.maxsize = 10
self.data = [0 for i in range(self.maxsize)]
self.front = 0
self.rear = 0
def enqueue(self, arg):
"""入队"""
if (self.rear + 1) % self.maxsize == self.front:
print("队列已满,无法入队")
return
self.data[self.rear] = arg
self.rear = (self.rear + 1) % self.maxsize
def dequeue(self):
"""出队"""
if self.isEmpty():
print("队列已空,无法读取元素")
return
tmp = self.data[self.front]
self.front = self.front + 1 % self.maxsize
return tmp
def gethead(self):
"""获取队头"""
if self.isEmpty():
print("队列已空,无法读取元素")
return
tmp = self.data[self.front]
return tmp
def size(self):
"""返回队列的长度"""
if self.front <= self.rear:
return self.rear - self.front
else:
return self.maxsize - (self.front - self.rear)
def isEmpty(self):
"""判断队列是否为空"""
return self.front == self.rear
def next(self):
"""遍历并输出"""
tmp = self.front
while tmp < self.rear:
print(self.data[tmp])
tmp += 1
def clear(self):
"""清空队列"""
self.front = 0
self.rear = 0
链式存储
队列的链存储结构称为链队列,它是限制在表头删除和表尾插入的单链表,由于需要在表尾进行插入操作,所以为操作方便除头指针外有必要再增加一个指向尾节点的指针
这个部分用到的链表的知识比较多,如果有不理解的可以去补补链表的知识
class Node(object):
"""节点类"""
def __init__(self, data=None):
self.data = data
self.next = None
class LinkQueue:
def __init__(self):
self.length = 0
self.front = None # 头节点
self.rear = None # 尾节点
def enqueue(self, arg):
"""入队"""
node = Node(data=arg)
if self.isEmpty():
self.front = self.rear = node
self.length += 1
else:
self.rear.next = node
self.rear = node
self.length += 1
def dequeue(self):
"""出队"""
if self.isEmpty():
print("队列为空")
else:
resulst = self.front.data
self.front = self.front.next
self.length-=1
return resulst
def gethead(self):
"""获取队头"""
if not self.isEmpty():
return self.front.data
else:
print("队列为空")
def size(self):
"""返回队列的长度"""
return self.length
def isEmpty(self):
"""判断队列是否为空"""
if self.length == 0:
return True
else:
return False
def next(self):
"""遍历并输出"""
tmp = self.front
while tmp:
print(tmp.data)
tmp = tmp.next
def clear(self):
"""清空队列"""
self.front = None
self.rear = None
队列实战题目
这两个题目我们再刚开始讲解的时候已经写过了

总结
- 栈是限定再表尾进行插入或删除的线性表,又称后进先出的线性表,栈有两种存储表示,顺序栈,链式栈,链的主要操作是进栈和出栈,对于出栈和进栈操作判断栈满还是栈空
- 队列是一种先进先出的线性表,它只允许在表的一端进行插入,而在另一端进行删除,队列也有两种存储结构,顺序存储,链式存储,队列的主要操作是进队和出队,对于顺序表需要注意队满和队空的情况
- 栈和队列是在程序设计中被广泛使用的两种数据结构,其具体的应用场景都是与其展示方法和运算规则相互关联的。
写在最后 博主的能力有限,欢迎大家进行指正
如果大家想巩固自己的所学,希望大家多做一些实际的题目,结合实际能够有更好的理解。推荐大家去牛客网刷题 👉传送门