Better Few-Shot Relation Extraction with Label Prompt Dropout
core idea
在小样本关系分类中,prompt信息是relation name是信息,这篇文章为了保持train和test的一致性,将train中的一些relation name信息删除掉了。(相反,我们提出了一种称为标签提示剔除的新方法,它在学习过程中随机剔除了标签描述)

Model
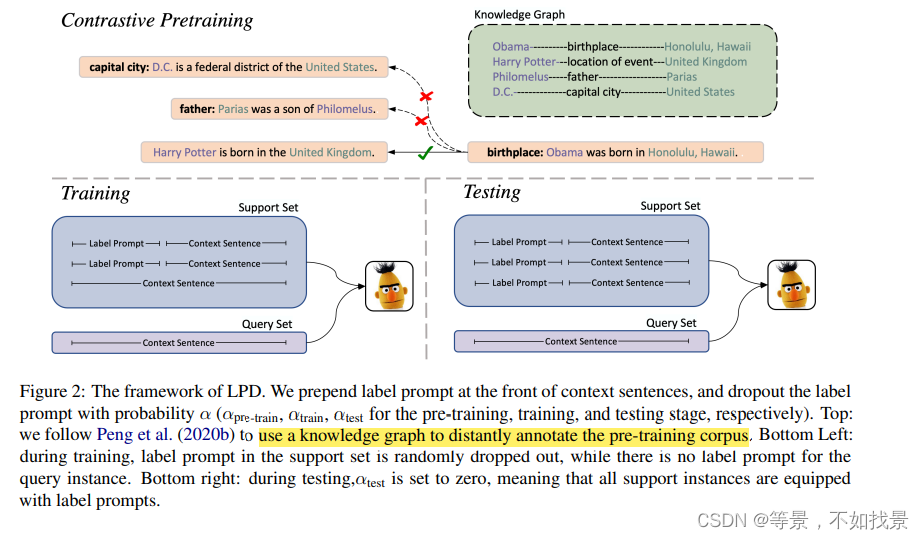
introduction中提到的:我们直接将文本标签和上下文句子连接起来,并将它们一起反馈给Transformer编码器(Vaswani等人,2017)。文本标签作为标签提示2,指导并规范Transformer编码器通过自我注意输出标签感知的关系表示。在训练过程中,我们随机丢弃了提示标记,以创造一个更具挑战性的场景,比如模型必须学会在有关系描述和没有关系描述的情况下工作。
较为简单和文章的工作相比。
Model structure
(1)通过远程监督,将知识图谱中的知识在维基百科数据上标注,形式用于pre_training的数据集。——对抗学习( the two sentences will be labeled as a positive pair if K defines a relation R such that (h1,t1) and (h2, t2) belongs to that relation. Sentences that do not form a positive pair will be sampled as negative pairs.)+掩码学习(mask entity spans with the special [BLANK] token with probability ρblank = 0.7 to avoid relying on the shallow cues of entity mentions.
)
(2)利用在pre-training训练好的模型,按照introduction中的思路训练。通过一个episode中的例子得到每个类型的原型表示,原型是由start entity和tail entity 组成,通过dot product得到最终的类型。
(For K-way-N-shot learning, we average the
relation representations of the K support instances
within one class to obtain the class prototype. The
dot product between the query instance and each
class prototype is then calculated and used as the
logit in the cross entropy loss)
Experiments
在具体实验中,还考虑了模型的迁移能力。
分析了在filter的维基百科中的模型为什么在fewrel1上好而在fewrel2上不好。









![[附源码]计算机毕业设计springboot健康医疗体检](https://img-blog.csdnimg.cn/f9922c1a0d0047f082c63783f47a71e0.png)