场景如下:
MySQL版本如下:
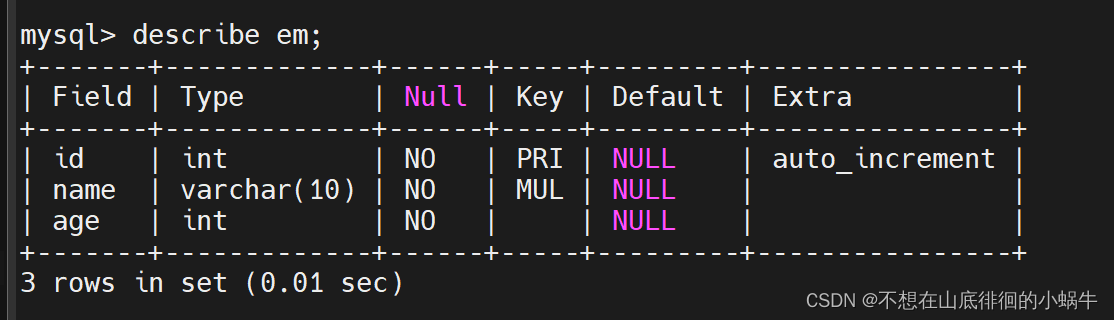
- 表结构如下:
- 索引结构如下:
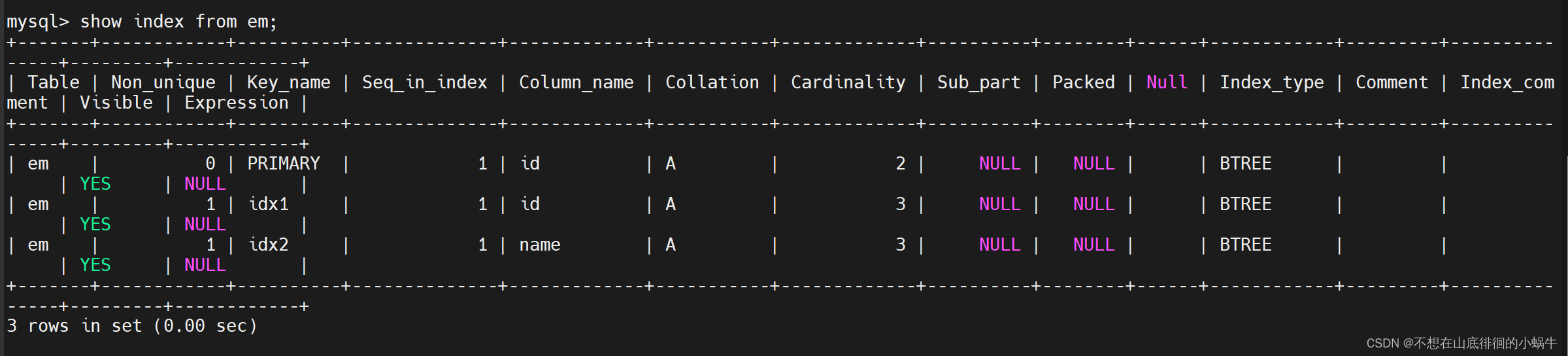
- 查询语句以及执行计划如下:
- 第一条查询语句:
select name from em where name like ‘%b’;

可以发现使用了name 字段创建的索引
- 第二条查询语句:
select id from em where name like ‘%b’;

-
第三条查询语句:
select * from em where name like ‘%b’;

为什么会这样?
mysql 的执行流程如下:
-
语法分析和语义分析:MySQL查询优化器首先会对用户提交的查询语句进行语法分析和语义分析,以确保查询语句的正确性。
-
查询优化:MySQL查询优化器会根据查询语句中的表、索引、WHERE条件、GROUP BY、ORDER BY等信息,生成多个查询执行计划,并对每个执行计划进行成本估算,最终选择成本最小的执行计划。
-
查询执行:MySQL查询优化器根据选择的查询执行计划,执行查询语句,并生成查询结果。
还有一种场景当数据量小的时候其实也有可能走索引的
gpt 解释如下
当数据量比较小的时候,尽管使用LIKE语句中含有通配符,MySQL在查询时也可以通过对索引进行全表扫描来快速定位匹配的记录。由于数据量比较小,扫描整个索引树并读取索引节点的成本较低,相比于全表扫描的成本较小,因此索引扫描的性能可能优于全表扫描。此时,使用索引进行查询可能比不使用索引更快。
但是,当数据量增大到一定程度时,使用LIKE语句进行模糊匹配的效率会越来越低。因为这种模糊查询需要进行全表扫描,扫描整个表中的每一行记录,判断是否符合查询条件。此时,如果数据量太大,就需要扫描的数据量也会变得很大,而且由于索引树的高度也会增大,索引扫描的成本也会变得很高
总结 : mysql 会选择成本最小的执行计划,显然name字段只需要查询索引就能得到索引结果,而不需要全文查询。因此,索引是否能生效本质上还是要看mysql对各种执行计划成本的计算决定的。