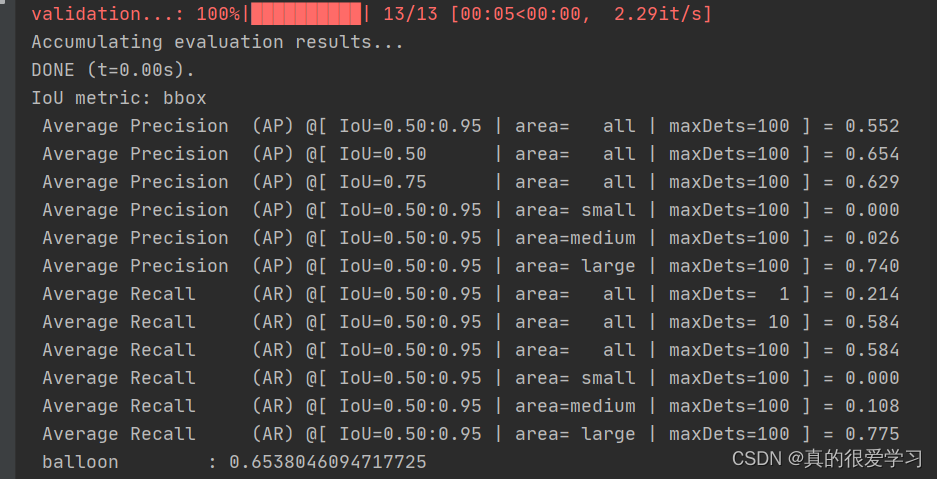
1. yarn-client
-
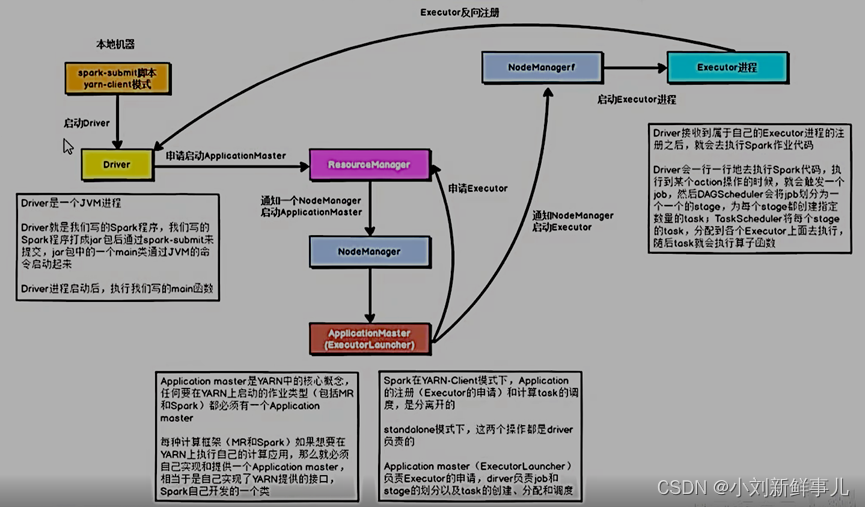
Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯,申请启动ApplicationMaster;
-
随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher(加载器),只负责向ResourceManager申请Executor内存;
-
ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程;
-
Executor进程启动后向ResourceManager发送心跳,向Driver反向注册,Executor全部注册完成后,Driver开始执行main函数
-
之后执行到action算子时,触发一个job,并根据宽依赖开始划分Stage,每个stage生成对应的TaskSet,之后将Task分发到各个Executor上执行,执行完毕释放资源。
以运行词频统计WordCount为例,提交命令如下:
[xiaokang@hadoop01 ~]$ /opt/software/spark-3.0.1/bin/spark-submit\
--master yarn \ #运行yarn
--deploy-mode client \ #部署模式client
--driver-memory 512m \ #为driver分配的内存大小
--executor-memory 512m \ #每个executor的内存大小
--executor-cores 1 \ #每个executor 1核
--num-executors 2 \ #集群的executor个数
--queue default \
--class cn.itcast.spark.start.SparkSubmit \
hdfs://node01:8020/spark/apps/spark-day02_2.11-1.0.0.jar \
/datas/wordcount.data \
/datas/swcy-client
2. yarn-cluster
-
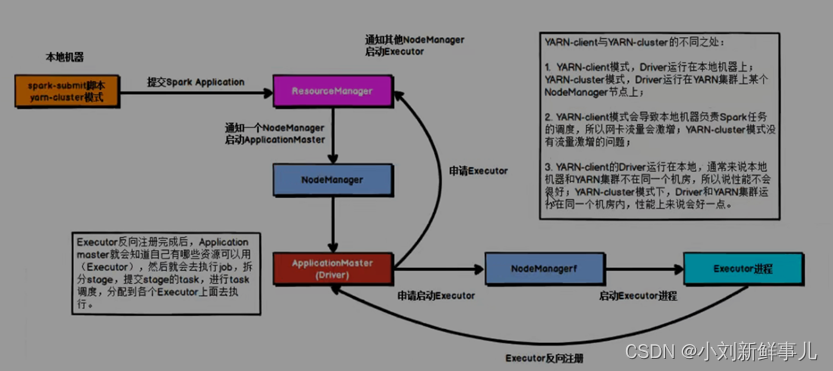
任务提交后会和ResourceManager通讯,申请启动ApplicationMaster;
-
随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver;
-
Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后在合适的NodeManager上启动Executor进程;
-
Executor进程启动后会向ResourceManager发送心跳,向Driver反向注册;
-
Executor全部注册完成后,Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
以运行词频统计WordCount为例,提交命令如下:
[xiaokang@hadoop01 ~]$ /opt/software/spark-3.0.1/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--driver-momery 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--queue default \
--class cn.itcast.spark.start.SparkSubmit \
hdfs://node01:8020/spark/apps/spark-day02_2.11-1.0.0.jar \
/datas/wordcount.data \
/datas/swcy-cluster
3. YARN-client与YARN-cluster的不同之处
-
YARN-client模式,Driver运行在本地机器上;
YARN-cluster模式,Driver运行在YARN集群的某个NodeManager节点上; -
YARN-client模式会导致本地机器负责Spark任务的调度,所以网卡流量会激增;
YARN-cluster模式没有流量激增的问题; -
YARN-client的Driver运行在本地,通常来说本地机器和YARN集群不在同一个机房,所以说性能不会很好;
YARN-cluster模式下,Driver和YARN集群运你在同一个机房内,性能上来说会好一点。



![[Netty] 面试问题 1 (十八)](https://img-blog.csdnimg.cn/09098c9c82ea40098172070b5082ed1d.png)