MySQL8.0 性能测试与新特性介绍
- 性能对比
测试内容
- 测试mysql5.7和mysql8.0 分别在读写、只读、只写模式((oltp_read_write,oltp_read_only,oltp_write_only))下不同并发时的性能(tps,qps)
测试环境
- 测试使用版本分别为mysql8.0.20和mysql5.7.30
- Sysbench测试前先重启mysql服务,并清空OS的cache(避免多次测试时命中缓存)
- 每次进行测试都是新生成测试数据后再进行mysql8.0和mysql5.7的测试
- 每次测试时保证mysql8.0和mysql5.7参数一致
- sysbench 测试数据: --table-size=2000000 --tables=20 --time=600
系统环境
- 操作系统都是CentOS Linux release 7.4.1708 (Core)
- 主要配置参数都是:
innodb_buffer_pool_size 8GB
innodb_log_buffer_size 16M
innodb_log_file_size 256M
innodb_flush_log_at_trx_commit 1
sync_binlog 1
binlog_format ROW
log_bin ON
transaction_isolation REPEATABLE-READ
- sysbench 版本:
[root@cpe-172-100-1-35 jsunicom]# sysbench --version
sysbench 1.1.0
测试数据
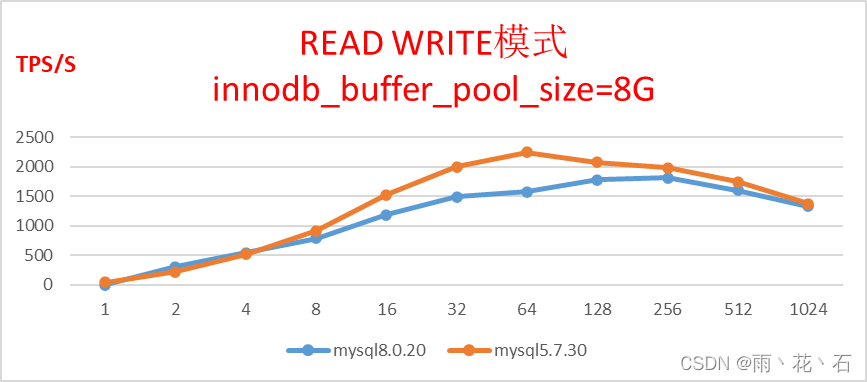
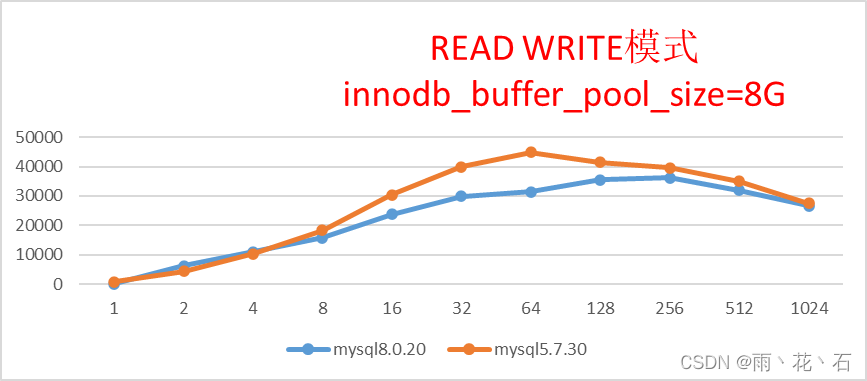
- 读写模式
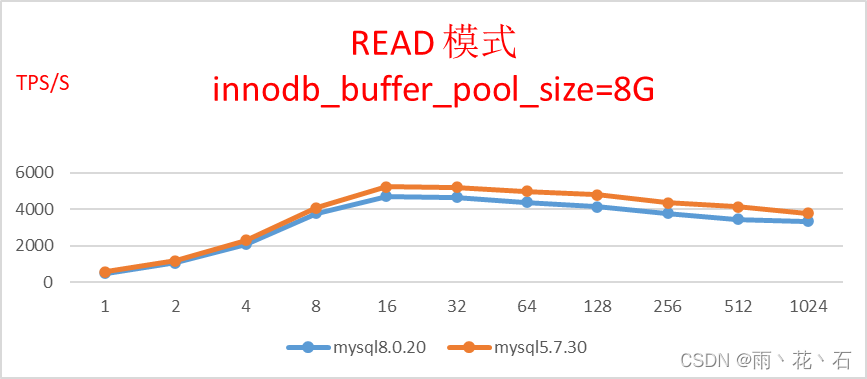
- 只读模式

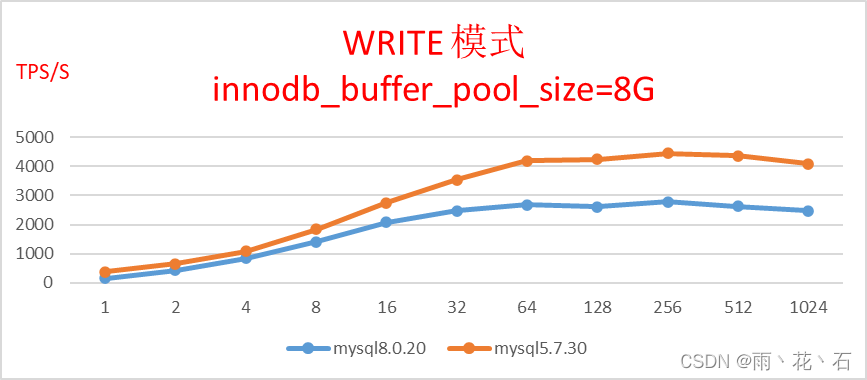
- 只写模式

- 新功能介绍
- 账户与安全
- 用户创建和授权
MySQL5.7创建用户和用户授权命令可以同时执行
mysql> grant all privileges on *.* to 'yuhuashi'@'%' identified by 'yuhuashi';
MySQL8.0创建用户和用户授权的命令分开执行
##创建用户
mysql> create user 'yuhuashi'@'%' identified by 'yuhuashi';
Query OK, 0 rows affected (0.04 sec)
##用户授权
mysql> grant all privileges on *.* to 'yuhuashi'@'%';
Query OK, 0 rows affected (0.10 sec)
- 认证插件更新
##之前认证
mysql> show variables like 'default_authentication%';
+-------------------------------+-----------------------+
| Variable_name | Value |
+-------------------------------+-----------------------+
| default_authentication_plugin | mysql_native_password |
+-------------------------------+-----------------------+
##之后认证
mysql> show variables like 'default_authentication%';
+-------------------------------+-----------------------+
| Variable_name | Value |
+-------------------------------+-----------------------+
| default_authentication_plugin | caching_sha2_password |
备注:如果要修改成之前的认证插件,一般有2种方式:
- 修改配置文件(my.cnf):
default_authentication_plugin= mysql_native_password
- 修改用户密码指定认证插件(这里只针对某一个用户,其他用户不受影响):
mysql> alter user 'yuhuashi'@'%' identified with mysql_native_password by 'yuhuashi';
- 密码管理
MySQL8.0新增了允许限制使用之前的密码
#新密码不能和前面三次的密码相同
password_history =3
#新密码不能同90天内使用过的密码相同
password_require_current = 90
#默认为off;为on 时 修改密码需要用户提供当前密码 (开启后修改密码需要验证旧密码,root 用户不需要)
password_reuse_interval=on
-
- 修改密码策略:
方式一、修改mysql配置文件(my.cnf),全局生效,但需要重启服务器
#找到mysql的配置文件 my.cnf, 我的在/opt/mysql/my.cnf
vi /opt/mysql/my.cnf
#在最后增加一行, 保存退出
password_history=3
方式二、持久化参数设置,则在重启服务后也会有效(set global 重启失效)
#使用 命令 set persist password_history=3
#这个具体的实现是增加了一个配置文件
mysql> set persist password_history=3;
#查看新增的配置文件
[root@yuhuashi ~]# more /opt/mysql/data/mysqld-auto.cnf
{ "Version" : 1 , "mysql_server" : { "password_require_current" : { "Value" : "ON" , "Metadata" : { "Timestamp" : 1590646007245828 , "User" : "root" , "Host" : "localh
ost" } } , "password_history" : { "Value" : "3" , "Metadata" : { "Timestamp" : 1590713952266867 , "User" : "root" , "Host" : "localhost" } } } }
方式三、对指定用户设置
mysql> alter user 'yuhuashi1'@'%' password history 3;
#通过下面的sql,可以查询我们修改的变化
mysql> select user,host,password_reuse_history from mysql.user;
#我们尝试修改密码试试
mysql> alter user 'yuhuashi'@'%' identified by 'yuhuashi';
ERROR 3638 (HY000): Cannot use these credentials for 'yuhuashi@%' because they contradict the password history policy
#上面的这个配置项成功是因为在mysql数据库中多了一张password_history的表,在这张表中记录了修改记录。
mysql> select * from mysql.password_history;
#如果我们把这个表delete 之后,就可以正常修改了,建议不要随便动这个表
-
- password_require_current变量配置说明
只针对普通用户有效,针对root等具有修改mysql.user表权限的用户无效
举例说明:
root账户登录
mysql> alter user 'yuhuashi'@'%' identified by 'mysql';
Query OK, 0 rows affected (0.03 sec)
yuhuashi账户登录,修改自身密码
mysql> alter user 'yuhuashi1'@'%' identified by 'mysql';
ERROR 3638 (HY000): Cannot use these credentials for 'yuhuashi1@%' because they contradict the password history policy
mysql> alter user 'yuhuashi1'@'%' identified by 'yuyu' replace 'mysql';
Query OK, 0 rows affected (0.02 se
- 角色管理
MySQL8.0新增了根据角色设置用户权限,如下图所示:

这个特性就相当于oracle role的管理,下面举例来说明:
#创建一个名字叫rw_role的角色
mysql> create role 'rw_role';
Query OK, 0 rows affected (0.01 sec)
#给这个角色授权,赋予增删改查的权限
mysql> grant select,insert,update,delete on yuhuashi.* to 'rw_role';
Query OK, 0 rows affected (0.08 sec)
#给用户赋予角色
mysql> create user test identified by 'test';
Query OK, 0 rows affected (0.03 sec)
mysql> show grants for 'test';
+----------------------------------+
| Grants for test@% |
+----------------------------------+
| GRANT USAGE ON *.* TO `test`@`%` |
+----------------------------------+
1 row in set (0.00 sec)
mysql> grant 'rw_role' to 'test';
Query OK, 0 rows affected (0.01 sec)
mysql> show grants for 'test';
+-----------------------------------+
| Grants for test@% |
+-----------------------------------+
| GRANT USAGE ON *.* TO `test`@`%` |
| GRANT `rw_role`@`%` TO `test`@`%` |
+-----------------------------------+
2 rows in set (0.00 sec)
mysql> show grants for 'test' using 'rw_role';
+--------------------------------------------------------------------+
| Grants for test@% |
+--------------------------------------------------------------------+
| GRANT USAGE ON *.* TO `test`@`%` |
| GRANT SELECT, INSERT, UPDATE, DELETE ON `yuhuashi`.* TO `test`@`%` |
| GRANT `rw_role`@`%` TO `test`@`%` |
+--------------------------------------------------------------------+
#测试,用test账户登录
mysql> select current_role();
+----------------+
| current_role() |
+----------------+
| NONE |
+----------------+
#用set 激活
mysql> set role 'rw_role';
Query OK, 0 rows affected (0.00 sec)
mysql> select * from yuhuashi.test;
Empty set (0.00 sec)
#为用户设置默认的角色
mysql> set default role 'rw_role' to 'test';
Query OK, 0 rows affected (0.04 sec)
mysql> select * from mysql.default_roles;
+------+------+-------------------+-------------------+
| HOST | USER | DEFAULT_ROLE_HOST | DEFAULT_ROLE_USER |
+------+------+-------------------+-------------------+
| % | test | % | rw_role |
+------+------+-----------
- 优化器索引
- 隐藏索引(invisible index)
特点:不会被优化器使用,但仍然需要维护
应用场景:软删除,灰度发布,新索引替换老索引
举例说明:

注意: 主键不能设置隐藏索引
- 降序索引
MySQL8.0之前:虽然可指定降序索引,实际上是升序索引
MySQL8.0:正式意义上支持降序索引,只有InnoDB引擎支持降序并且只支持BTREE降序索引,MySQL8.0不在对group by操作进行隐式排序,需要使用order by进行排序。

虽然age列指定了desc,但在实际的建表语句中还是将其忽略了。再来看看MySQL 8.0的结果。
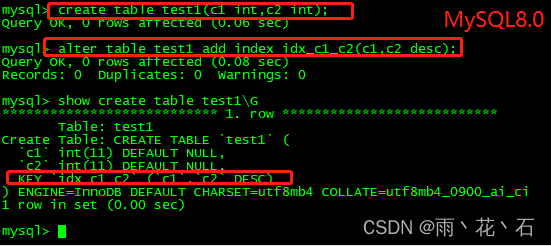
降序索引的意义
如果一个查询,需要对多个列进行排序,且顺序要求不一致。在这种场景下,要想避免数据库额外的排序-“filesort”(Using filesort代表查询中有排序操作),只能使用降序索引。
。
MySQL5.7

MySQL8.0

对比结果: MySQL 8.0因为降序索引的存在,避免了“filesort”。
这其实是降序索引的主要应用场景。如果只对单个列进行排序,降序索引的意义不是太大,无论是升序还是降序,升序索引完全可以应付。还是同样的表,看看下面的查询。
MySQL5.7

MySQL8.0

对比说明: 虽然c1是升序索引,但在第二个查询中,对其进行降序排列时,并没有进行额外的排序,使用的还是索引, 而在8.0中,对于反向扫描,有一个专门的词进行描述“Backward index scan”。
终于不再对group by进行隐式排序
由于降序索引的引入,MySQL 8.0再也不会对group by操作进行隐式排序。

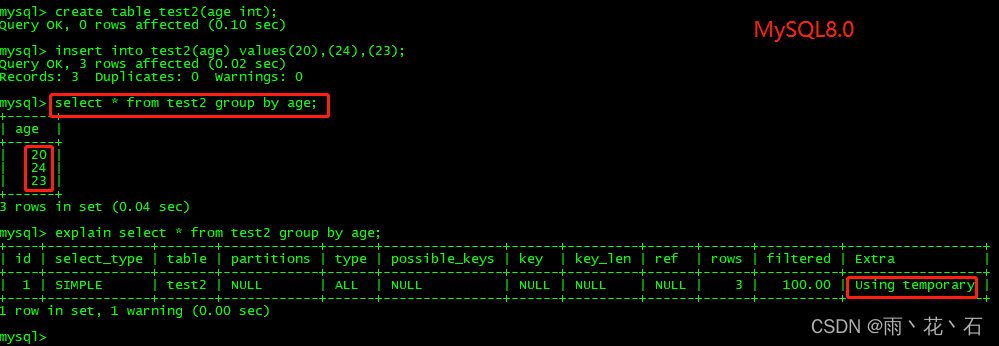
对比总结:不仅结果没有升序输出,执行计划中也没有“Using filesort”.可见,MySQL 8.0对于group by操作确实不再进行隐式排序。
- 函数索引
mysql8.0.13开始支持在索引中使用函数(表达式)的值,之前是使用列值,现在可以使用函数表达式的值使用索引,同时也支持降序索引,json数据的索引。之前版本的数据库是没法对json里各个节点的数据索引,函数索引是基于虚拟计算列功能来实现的。可以方便对json格式数据的查询。

查看执行计划:
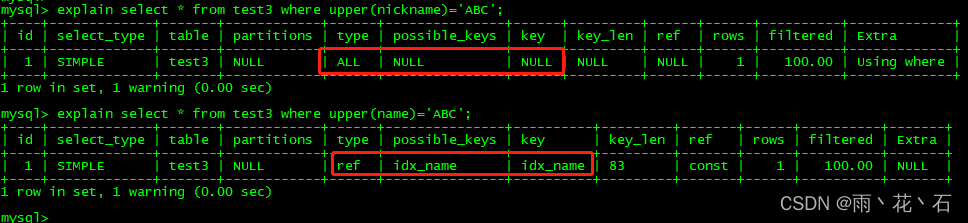
总结:虽然nickname有建索引,但还是全表扫描
针对JSON节点的索引

- 通用表达式
即with子句,是sql语句的增强,很多主流数据库都有该功能,mysql8.0也是拥有了该功能。这在实际使用经常会用使用到。
- 非递归CTE
举例说明:
派生表(子查询):select * from (select 1) as dt;
通用表表达式:with dt as (select 1)select * from dt;就相当于一个变量,在后面语句中使用。:

另外CTE可能在SELECT/UPDATE/DELETE之前,包括with derived as ( subquery )的子查询, 例如:
with derived as (
subquery
)
delete from table_name
where table_name.col_name in (
select col_name from derived
);
- 递归CTE
在查询中引用自己的定义,使用RECURSIVE表示。和编程语言中的递归函数调用差不多。生成一些模拟数据也比较方便。
举例说明:

- 递归限制
递归查询必须指定终止条件
MySQL8.0提供两个参数避免用户未指定终止条件
- cte_max_recursion_depth:默认值1000
mysql> show variables like 'cte_max%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| cte_max_recursion_depth | 1000 |
+-------------------------+-------+
测试-死循环:

当前会话/持久化设置cte_max_recursion_depth
mysql> set session cte_max_recursion_depth=2000;
Query OK, 0 rows affected (0.00 sec)
mysql> set persist cte_max_recursion_depth=2000;
Query OK, 0 rows affected (0.02 sec)
- max_execution_time:默认无限制,单位毫秒
mysql> show variables like 'max_execution_time';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| max_execution_time | 0 |
同样设置这个参数和cte_max_recursion_depth一样。
- 总结
- 通用表达式与派生表类似,就像语句级别的临时表或试图
- CTE可以在查询中多次引用,可以引用其他CTE,可以递归
- CTE支持SELECT/INSERT/UPDATE/DELETE等语句
- 窗口函数
- 窗口函数定义
MySQL8.0支持窗口函数(Windows Function),在Oracle中也成为分析函数。
窗口函数与分组聚合函数类似,但是每一行数据都生成一个结果。简单的说,聚合函数是将多条记录聚合为一条,而窗口函数是每条记录都会执行,有几条记录执行完还是几条。
聚合窗口函数:SUM/AVG/COUNT/MAX/MIN等等
- 专用窗口函数
MySQL8.0中定义的窗口函数主要有以下几种:
| 函数名 | 参数 | 描述 |
| cume_dist() | 否 | 累计分布值。即分组值小于等于当前值的行数与分组总行数的比值。取值范围为(0,1]。 |
| dense_rank() | 否 | 不间断的组内排序。使用这个函数时,可以出现1,1,2,2这种形式的分组。 |
| first_value() | 是;first_value(expr) | 返回分组内截止当前行的第一个值。 |
| lag() | 是;lag(expr,[N,[default]]) | 从当前行开始往前取第N行,如果N缺失默认为1。若没有没有,则默认返回default。default默认值为NULL |
| last_value() | 是;last_value(expr) | 返回分组内截止当前行的最后一个值。 |
| lead() | 是;lead(expr,[N,[default]]) | 从当前行开始往后取第N行。函数功能与lag()相反,其余与lag()相同。 |
| nth_value() | 是;nth_value(expr,N) | 返回分组内截止当前行的第N行。first_value\last_value\nth_value函数功能相似,只是返回分组内截止当前行的不同行号的数据。 |
| ntile() | 是;ntile(N) | 返回当前行在分组内的分桶号。在计算时要先将改分组内的所有数据划分成N个桶,之后返回每个记录所在的分桶号。返回范围从1到N |
| percent_rank() | 否 | 累计百分比。该函数的计算结果为:小于该条记录值的所有记录的行数/该分组的总行数-1. 所以改记录的返回值为[0,1] |
| rank() | 否 | 间断的组内排序。其排序结果可能出现如下结果:1,1,3,4,4,6 |
| row_number() | 否 | 当前行在其分组内的序号。不管其排序结果中是否出现重复值,其排序结果都为:1,2,3,4,5 |
注:‘参数’列说明该函数是否可以加参数。“否”说明该函数的括号内不可以加参数。expr即可以代表字段,也可以代表在字段上的计算,比如sum(col)等。
- 举例说明:
首先创建测试用例

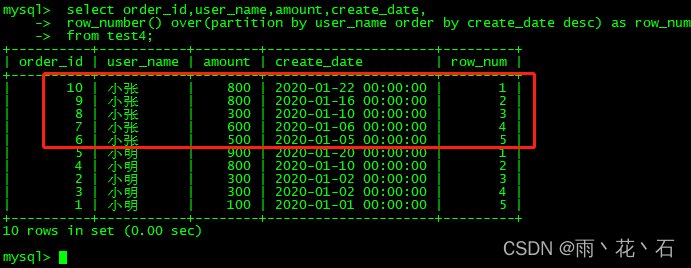
- row_number(partition by xxxx order by xxx)
查询求每个用户的最新的一个订单。
- rank()
类似于 row_number(),也是排序功能,但是rank()有什么不一样?假如再往测试表中写入一条数据: insert into test4 values (11,'小张',800,'2020-1-22'); 那么这时候对于测试表中的’小张’用户来说,有两条create_date完全一样的数据那么在row_number()编号的时候,这两条数据却被编了两个不同的号理论上讲,这两条的数据的排名是并列最新的。因此rank()就是为了解决这个问题的,也即:排序条件一样的情况下,其编号也一样。

- dense_rank()
dense_rank()的出现是为了解决rank()编号存在的问题的,rank()编号的时候存在跳号的问题,如果有两个并列第1,那么下一个名次的编号就是3,结果就是没有编号为2的数据。如果不想跳号,可以使用dense_rank()替代。

- avg,sum等聚合函数在窗口函数中的的增强
可以在聚合函数中使用窗口功能,比如sum(amount)over(partition by user_no order by create_date) as sum_amont,达到一个累积计算sum的功能。

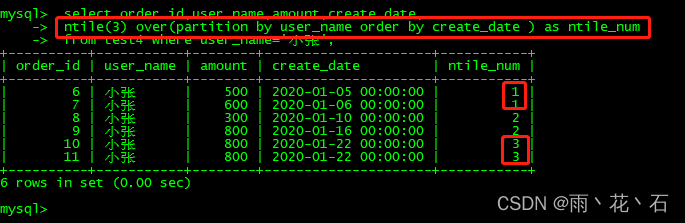
- NTILE (N) 将数据按照某些排序分成N组
举个简单的例子,按照分数线的倒序排列,将学生成绩分成上中下3组,可以得到哪个程序数据上中下三个组中哪一部分,就可以使用NTILE(3) 来实现。
- first_value(column_name) and last_value(column_name)
first_value和last_value基本上见名知意了,就是取某一组数据,按照某种方式排序的,最早的和最新的某一个字段的值。

- nth_value(column_name,n)
从排序的第n行还是返回nth_value字段中的值,这个函数用的不多,要表达的这种逻辑,看个例子体会以下:

- cume_dist
在某种排序条件下,小于等于当前行值的行数/总行数,得到的是数据在某一个纬度的分布百分比情况。
举例说明:
第一行的数据的日期(create_date) 是2020-01-05 00:00:00,小于等于2020-01-05 00:00:00的数据是1行,计算方式是:1/5 = 0.2
第一行的数据的日期(create_date) 是2020-01-06 00:00:00,小于等于2020-01-06 00:00:00的数据是2行,计算方式是:1/5 = 0.4
以此类推,最终结果如下:

- percent_rank()
同样是数据分布的计算方式,只不过算法变成了:当前RANK值-1/总行数-1 。
实际中的用的也不多,举例说明:

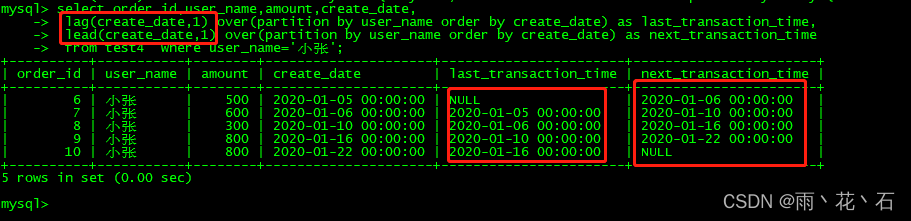
- lag以及lead
lag(column,n)获取当前数据行按照某种排序规则的上n行数据的某个字段,lead(column,n)获取当前数据行按照某种排序规则的下n行数据的某个字段。
举例说明,按照时间排序,获取当前订单的上一笔订单发生时间和下一笔订单发生时间(可以计算订单的时间上的间隔度或者说买的频繁程度)
- InnodDB增强
- 集成数据字典
最新的MySQL 8.0 发布之后,对数据库数据字典方面做了较大的改进。
- 首先是,将所有原先存放于数据字典文件中的信息,全部存放到数据库系统表中,即将之前版本的.frm,.opt,.par,.TRN,.TRG,.isl文件都移除了,不再通过文件的方式存储数据字典信息。
- 其次是对INFORMATION_SCHEM,mysql,sys系统库中的存储引擎做了改进,原先使用MyISAM存储引擎的数据字典表都改为使用InnoDB存储引擎存放。从不支持事务的MyISAM存储引擎转变到支持事务的InnoDB存储引擎,为原子DDL的实现,提供了可能性。
- 原子DDL操作
MySQL8.0开始支持原子DDL操作,一个原子DDL操作,具体的操作内容包括:数据字典更新,存储引擎层的操作,在binlog中记录DDL操作。并且这些操作都是原子性的,表示中间过程出现错误的时候,是可以完整回退的。
举例说明:
MySQL5.7中执行drop 命令drop table t1,t2;如果t1存在,t2不存在,会提示t2表不存在,但是t1表仍然会被删除。
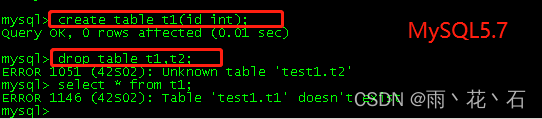
MySQL8.0执行同样的drop命令,也会提示t2表不存在,但是t1表不会被删除,保证了原子性。

- 自增列持久化
- MySQL8.0以前的版本InnoDB自增列计算(auto_increment)的值只存储在内存中,这样每次MySQL服务器重启后,会重新扫描表的主键最大值,如果之前已经删除过id=100的数据,但是表中当前记录的最大值如果是99,那么经过扫描,下一条记录的id是100,而不是101。
- MySQL8.0则是每次在变化的时候,都会将自增计数器的最大值写入redo log,同时在每次检查点将其写入引擎私有的系统表。则不会出现自增主键重复的问题。
举例说明:
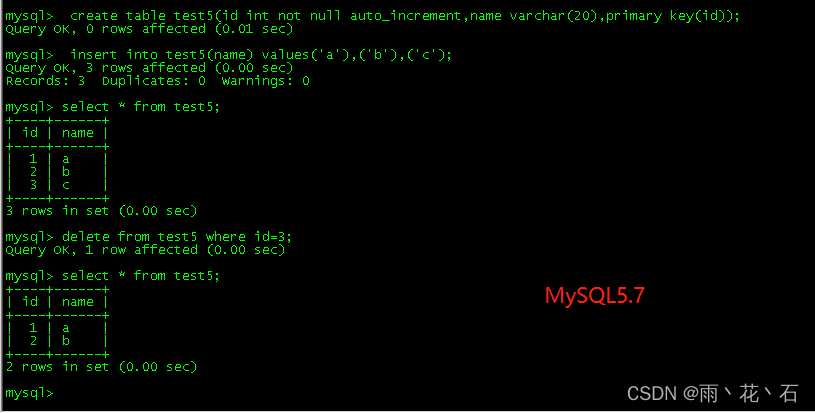
重启MySQL服务


MySQL8.0

重启服务

插入数据

- 死锁检查控制
MySQL8.0(MySQL5.7.15)增加了一个新的动态变量(innodb_deadlock_detect),用于控制系统是否执行InnoDB死锁检查。
对于高并发的系统,禁用死锁检查可带来性能的提高。因为在高并发系统中,当大量线程等待同一个锁时,死锁检查会大大拖慢数据库
- 锁定语句选项
SELECT …FOR SHARE 和SELECT …FOR UPDATE中支持NOWAIT
SKIP LOCKED选项
对于NOWAIT ,如果请求的行被其他事务锁定时,若想获取被锁住的数据,则立即返回不可访问异常。
对于SKIP LOCKED,从返回的结果集中移除被锁定的行。
还是举例说明:

再重新打开新的窗口

- 其他功能改进
- 支持部分快速DDL,ALTER TABLE …ALGORITHM=INSTANT;
- InnoDB临时表使用共享的临时表空间ibtmp1.
- 新增静态变量innodb_dedicated_server,自动配置InnoDB内存参数:
Innodb_buffer_pool_size/innodb_log_file_size等。
- 支持ALTER TABLESPACE …RENAME TO重命名通用表空间。
- 支持使用innodb_directories选项再服务器停止时将表空间文件移动到新的位置
- InnoDB表空间加密特性支持重做日志和撤销日志。
- JSON增强
- 内联路径操作符
MySQL8.0增加了JSON操作符column->>path,等价于
JSON_UNQUOTE(column->path)或JSON_UNQUTOE(json_extract(column,path))

mysql8.0还扩展了这个路径表达式的语法,可以支持范围的操作。

- JSON聚合函数
可以将表中列的数据聚合成对应的json数组或者json对象。
MySQLl8.0(MySQL5.7.22)增加了两个聚合函数
- JSON_ARRAYAGG() ,用于将多行数据组合生成JSON数组。

- JSON_OBJECTAGG(),用于生成json对象,支持多个列

备注:如果存在重复值,最后面的值覆盖前面的值
- JSON实用函数
用于对json对象的输出或者获取json所占用的存储空间。
MySQL8.0(MySQL5.7.22)增加了3个实用函数
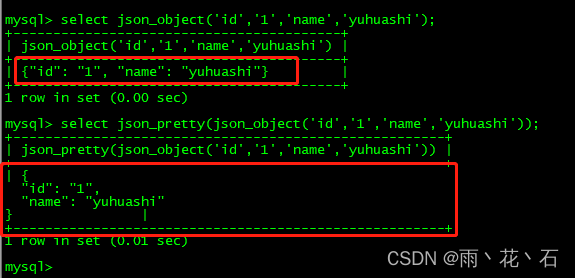
- JSON_PRETTY()
这个函数用于在输出json对象内容的时候进行格式化或者美化输出。
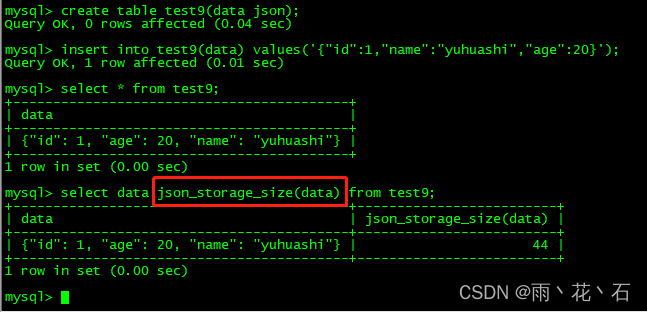
- JSON_STORAGE_SIZE()
返回json数据所占用的空间大小
- JSON_STORAGE_FREE(),MySQL8.0新增
用于更新某些json列之后,相应的一些字段它可能释放的存储空间

- JSON合并函数
MySQL8.0(MySQL5.7.22)增加了JSON_MERGE_PATCH()
MySQL8.0(MySQL5.7.22)增加了JSON_MERGE_PRESERV()
两个函数都用于合并json数据,区别在于前者重复属性会使用最新的属性值,后者会保留所有的属性值。并且废弃了json_merge()函数。
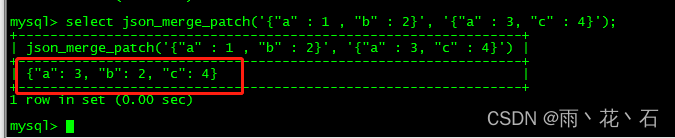
- JSON_MERGE_PATCH()
会覆盖旧值
- JSON_MERGE_PRESERV()
会保留所有值

- JSON_MERGE()
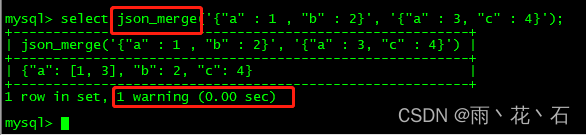
- JSON表函数
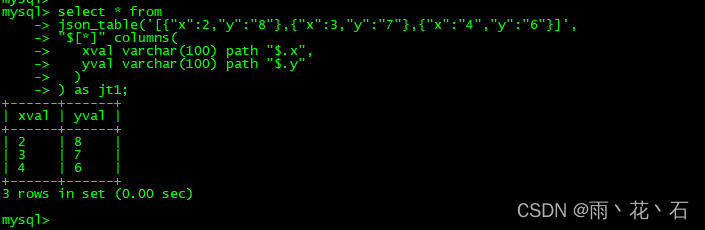
MySQL8.0增加了JSON_TABLE(),将JSON数据转换为关系表。
可以将该函数的返回结果当作一个普通的表,使用SQL进行查询。



![[pgrx开发postgresql数据库扩展]附1.存储过程的优缺点与数据库扩展函数](https://img-blog.csdnimg.cn/img_convert/cdbbe4b5116cdb91bdea33d185958cb2.webp?x-oss-process=image/format,png)