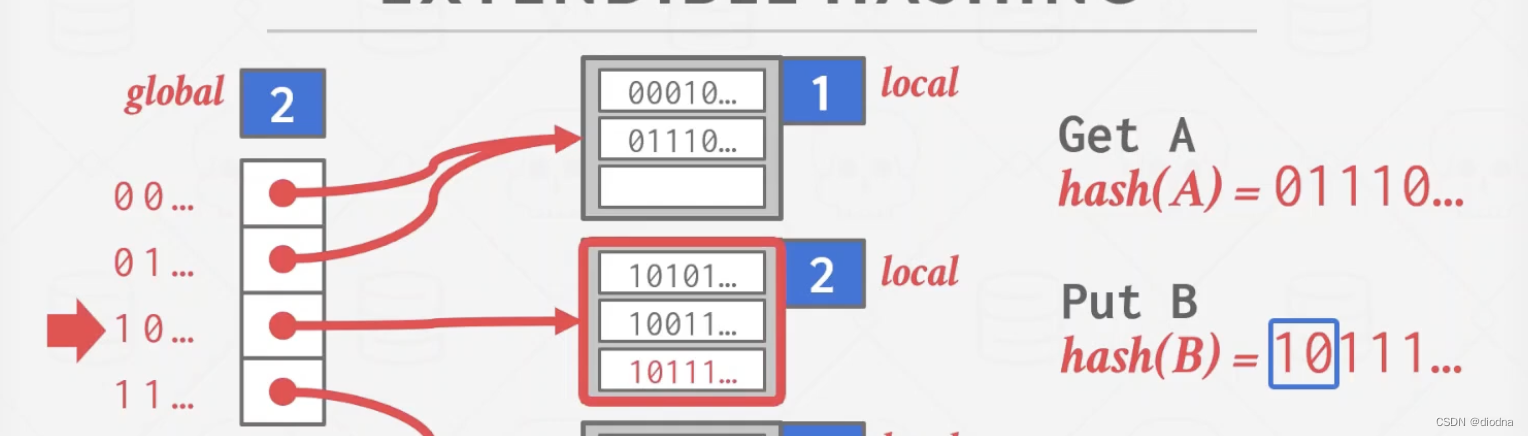
获取树形结构
- 一、背景介绍
- 二、 思路和方案
- 方案一:使用递归查询的方式并构建树形结构
- 方案二:使用临时表的方式构建树形结构
- 使用临时表的优缺点
- 三、过程
- 项目案例
- 核心代码
- 四、总结
- 五、升华
一、背景介绍
我们在开发中时常会遇到需要用到树形结构这种表示层级关系的结构来表示数据,层级关系明确用户能够很直观的理解彼此的关系。
例如:
本篇博客主要是总结从一张字段具有父子关系的表中查询并将其转换成树形结构通常需要怎么做,具体步骤是什么?以此来解决后序需要类似的问题如何快速实现或者是有思路,将经历转变为自己的经验。
二、 思路和方案
目前一共有两种实现的方案,方案一:使用递归查询的方式并构建树形结构;方案二:使用临时表的方式构建树形结构。
方案一:使用递归查询的方式并构建树形结构
通过递归查询的方式,从根节点开始递归查询所有子节点,然后将他们组成一个树形结构。
宏观步骤:
- 通过一次查询获取整个表中的数据。
- 再从查询出的数据中筛选出根节点。
- 从根节点开始查询所有子节点,再对于每个子节点,在递归查询他们所有子节点
并将它们组成一个子树。 - 将所有子树组成一个完整的属性结构。
方案二:使用临时表的方式构建树形结构
下面是列举的一个示例,起到提供思路的目的。这块儿内容并没有进行实践
宏观步骤:
1.创建临时表temp_tree,用来存储树形结构的各个节点,包括节点id、节点名称、父节点id和层级等信息。
CREATE TEMPORARY TABLE temp_tree (
id INT PRIMARY KEY,
name VARCHAR(255),
parent_id INT,
level INT
);
2.向临时表中插入树形结构的各个节点信息。
INSERT INTO temp_tree (id, name, parent_id, level)
SELECT id, name, parent_id, level
FROM your_table
ORDER BY parent_id, id;
注意这里的查询语句需要按照父节点id和节点id进行排序,以保证树形结构的正确性。
3.通过递归查询的方式,构造树形结构的节点之间的关系,并将结果存储在一个数组或者集合中。
List<Node> nodeList = new ArrayList<>();
// 递归查询,构造节点之间的关系
public void buildTree(List<Node> nodeList, int parentId, int level) {
for (Node node : temp_tree) {
if (node.getParentId() == parentId) {
node.setLevel(level);
nodeList.add(node);
buildTree(nodeList, node.getId(), level + 1);
}
}
}
// 构建树形结构
buildTree(nodeList, 0, 0);
4.根据构造出来的节点关系,生成树形结构的数据行。
public List<Map<String, Object>> generateTreeData(List<Node> nodeList) {
List<Map<String, Object>> treeData = new ArrayList<>();
for (Node node : nodeList) {
Map<String, Object> data = new HashMap<>();
data.put("id", node.getId());
data.put("name", node.getName());
data.put("level", node.getLevel());
if (node.getParentId() != 0) {
data.put("parentId", node.getParentId());
}
treeData.add(data);
}
return treeData;
}
// 生成树形结构数据行
List<Map<String, Object>> treeData = generateTreeData(nodeList);
注意这里生成的树形结构数据行可以根据实际需要进行定制,比如可以增加其他属性,比如节点状态、节点类型等等。
使用临时表的优缺点
- 使用临时表的主要优势是它能够在数据库中更加灵活地处理数据,因此适用于一些需要进行更加复杂操作的情况,如对树形结构进行排序、过滤等操作。
- 灵活性:使用临时表实现可以将数据加载到内存中,这使得在程序中对树形结构进行操作时更加灵活,尽管临时表在构建时需要一定的时间和资源,但在数据量较大时,在临时表中,数据已经存储在内存中,查询和修改速度更快,能够更好地支持大规模数据的处理。
同时,当你需要对数据进行分页处理时,使用方案一可能会比较麻烦,因为你需要对整个数据集进行递归并处理出树形结构,然后再进行分页操作。而使用临时表,你可以在数据库中将数据按照分页条件先筛选出来,然后再进行递归并处理出树形结构。
临时表的缺点是需要占用更多的存储空间,而且实现起来相对比较复杂,需要编写 SQL 查询语句。如果数据量较大或者需要对树形结构进行复杂的操作,使用临时表可能更加合适。
三、过程
目前采取的是 方案一:使用递归查询的方式并构建树形结构
在程序中进行递归构建树形结构,并且在此之前已经将数据全部取出,那么使用方案一也许会更加简单和高效。因为你无需再将数据导入到临时表中。使用临时表的主要优势是它能够在数据库中更加灵活地处理数据,因此适用于一些需要进行更加复杂操作的情况,如对树形结构进行排序、过滤等操作。
项目案例
目前是需要从一张字段具有父子关系的表中查询并将其转换成树形结构。
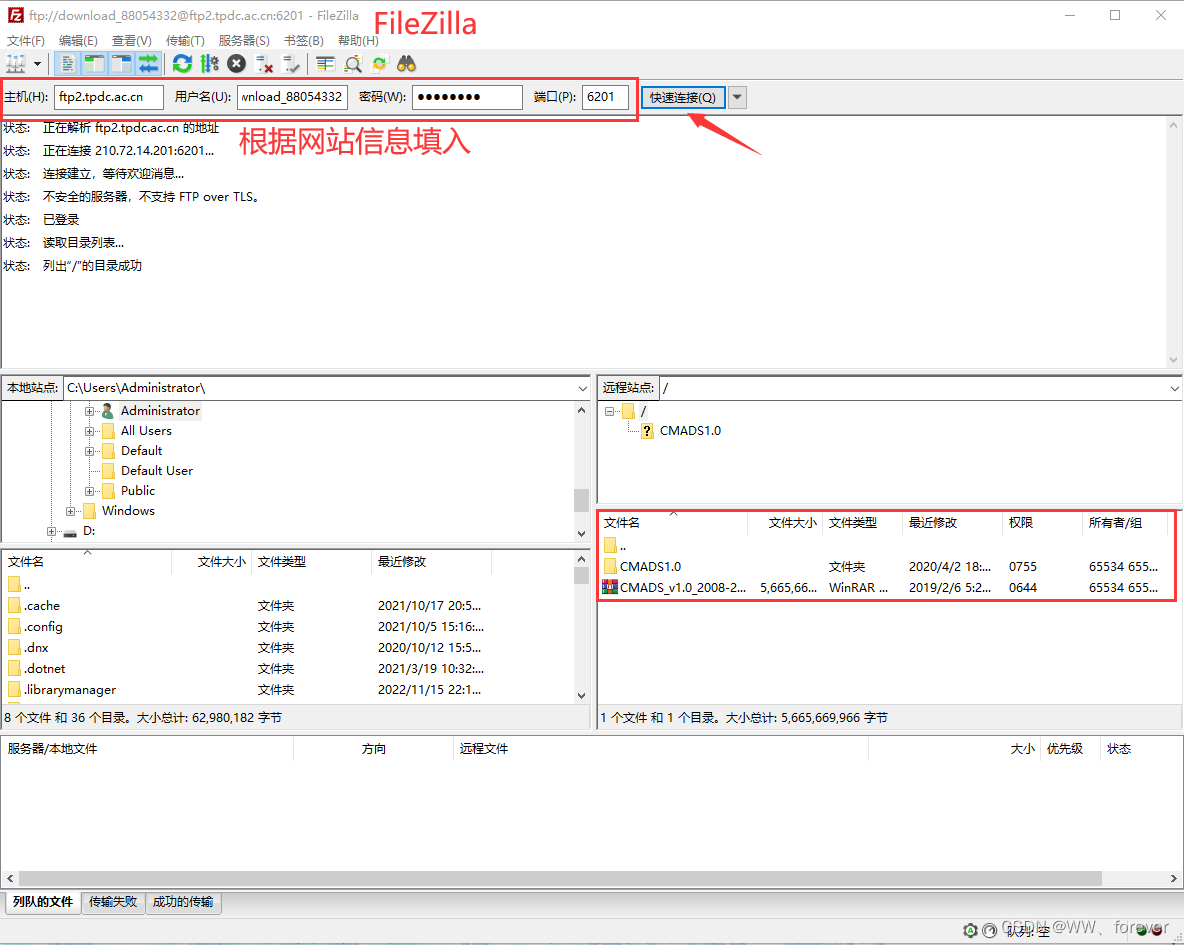
表结构:p_id表示父节点,p_id为0表示为根节点

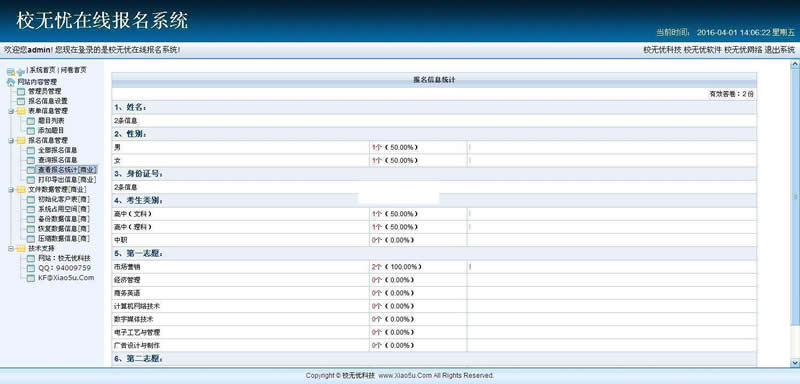
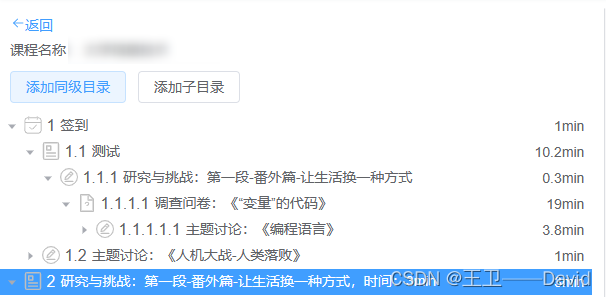
前端渲染的结果:
核心代码
树形结构体中的核心内容
public class ChapterTreeInfo implements Serializable {
/**
* 主键
*/
@JsonSerialize(using = com.fasterxml.jackson.databind.ser.std.ToStringSerializer.class)
private BigInteger id;
/**
* 父章节id
*/
private BigInteger p_id;
/**
* 章节目录排序
*/
private Integer order;
/**
* 章节id
*/
private String chapter_id;
/**
* 章节名称
*/
private String chapter_title;
/**
* 执行时间
*/
private Integer limit_time;
/**
* 活动id
*/
private String active_id;
private List<ChapterTreeInfo> children;
// getter and setter methods
核心方法
//1.通过课程id查询所有的章节信息
List<ArproChapterInfo> arproChapterInfos = arproChapterInfoMapper.queryChapterInfo(courseId);
//将需要的数据导入到准备好的ChapterTreeInfo结构中,为后序的递归做准备
List<ChapterTreeInfo> chapterTreeInfos = dataProcessing(arproChapterInfos);
//容器,用于表示整体的树形结构
List<ChapterTreeInfo> chapterTreeInfoList=new ArrayList<>();
//找出父节点,并为其添加子节点
for (ChapterTreeInfo chapterTree:chapterTreeInfos) {
//说明此节点是最初的父节点,为他添加子节点
if(chapterTree.getP_id()==null||chapterTree.getP_id().intValue()==0){
//找到该父节点下的所有子节点(以及子节点下的子节点...)
ChapterTreeInfo chapterTreeInfo=findChildren(chapterTree,chapterTreeInfos);
//为该父节点添加子节点
chapterTreeInfoList.add(chapterTreeInfo);
}
}
return chapterTreeInfoList;
dataProcessing方法将将查询出来的数据更换到树形结构中
/**
* 将字典数据遍历放入chapterTreeInfos中
*
* @param arproChapterInfoList
* @return
*/
public static List<ChapterTreeInfo> dataProcessing(List<ArproChapterInfo> arproChapterInfoList) {
//将entity转为自定义的model,有两种方式一种方式是进行for循环添加,一种是使用stream流进行添加,这里选择使用stream流中的peek操作允许你访问流中的每个元素,并且可以对每个元素进行一些操作
List<ChapterTreeInfo> chapterTreeInfos=new ArrayList<>();
arproChapterInfoList.stream().peek(chapterLeaf->{
ChapterTreeInfo chapterTree =new ChapterTreeInfo();
//获取节点的父id
chapterTree.setP_id(chapterLeaf.getpId());
//获取节点的id
chapterTree.setChapter_id(chapterLeaf.getChapterId());
//获取节点名字
chapterTree.setChapter_title(chapterLeaf.getChapterTitle());
//获取节点时间
chapterTree.setLimit_time(chapterLeaf.getLimitTime());
//获取节点内容
chapterTree.setContents(chapterLeaf.getContents());
//获取节点的信息
chapterTree.setType(chapterLeaf.getType());
//将节点信息存入到树形结构中
chapterTreeInfos.add(chapterTree);
}).collect(Collectors.toList());
return chapterTreeInfos;
}
findChildren寻找根节点的子节点,进行递归
/**
* 递归
*
* @param
* @param chapterTreeModels
* @return ChapterTreeModel
*/
public static ChapterTreeInfo findChildren(ChapterTreeInfo chapterTreeModel, List<ChapterTreeInfo> chapterTreeModels) {
for (ChapterTreeInfo chapterTree:chapterTreeModels) {
//判断该节点的父节点id是否等于传递进来的节点的id(表名传进来的节点具有子节点)
if (chapterTreeModel.getId().equals(chapterTree.getP_id())) {
if (chapterTreeModel.getChildren()==null){
chapterTreeModel.setChildren(new ArrayList<>());
}
//递归查询当前节点是否还有子节点,直到没有子节点那就就将当前节点
chapterTreeModel.getChildren().add(findChildren(chapterTree,chapterTreeModels));
}
}
return chapterTreeModel;
}
以上就是方案一的核心代码。
四、总结
- 通过这次博客总结对于查询树形结构有了更深的熟悉度和常用思路。
- 另外对于获取树形结构的另外一种方式,创建临时表的方式也有了一定的了解。以至于自己下一次遇到类似的问题多了一个思考的维度。
- 对于在程序中进行递归还是在数据库中递归,也有了这方面的了解,以及数据库实现递归的方式,如SQL 查询语句使用了 WITH RECURSIVE 关键字,实现了递归查询。
五、升华
- 对于解决问题的方式,不止一种,需要有意识的想到要去找多种的实现方式,进行对比选择一种复合当前的实现方式。