文章目录
- 一、TensorRT介绍,工作流程和优化策略
- TensorRT是什么
- TensorRT的工作流程
- TRT优化策略介绍
- 二、TensorRT的组成和基本使用流程
- 三、TensorRT的基本使用流程
- 四、TensorRT Demo代码 : SampleMNIST
- Caffe Parser方式构建
- 五. TensorRT Plugin
- 基本概念
- 工作流程
- API介绍
- Dynamic Shape Plugin API
- Static Shape官方Demo代码讲解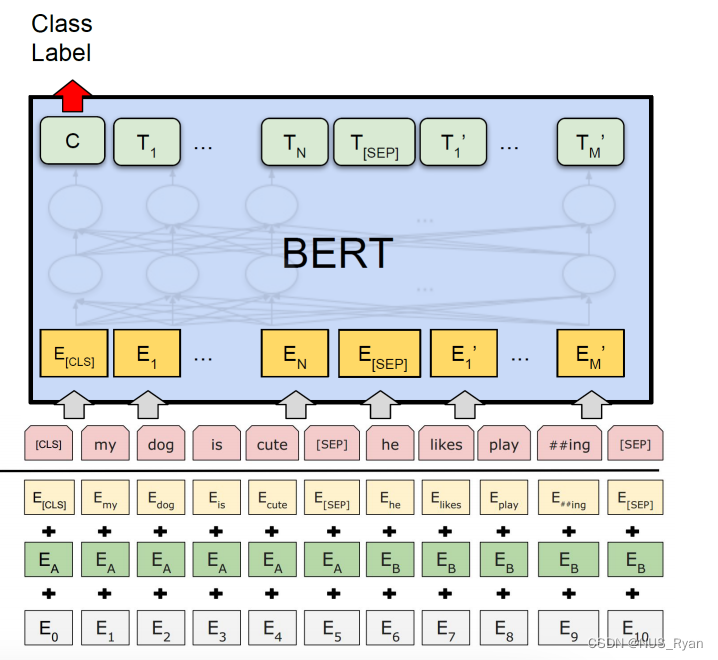
- TensorRT Plugin Creator
- TensorRT Plugin 如何进行debug
- 六. TensorRT INT8 加速
- FP16
- INT8
- 为什么INT8量化会快呢?
- 为什么INT8对于准确度的影响是有限的
- 动态对称量化算法
- 动态非对称量化算法
- 静态对称量化算法
- 进阶讨论:INT8量化算法的实际收益
- 进阶讨论:如何使用TensorRT进行大规模上线
- 总结和建议
一、TensorRT介绍,工作流程和优化策略
TensorRT是什么

首先,根据上图可知,TensorRT是一个适配NVIDIA GPU的深度学习的推理框架,其能实现高性能深度学习推理,优化器和加速库,能够实现低延迟和高吞吐量,可以部署到超大规模的数据中心,嵌入式(Jetson)或者汽车产品。
TensorRT的工作流程
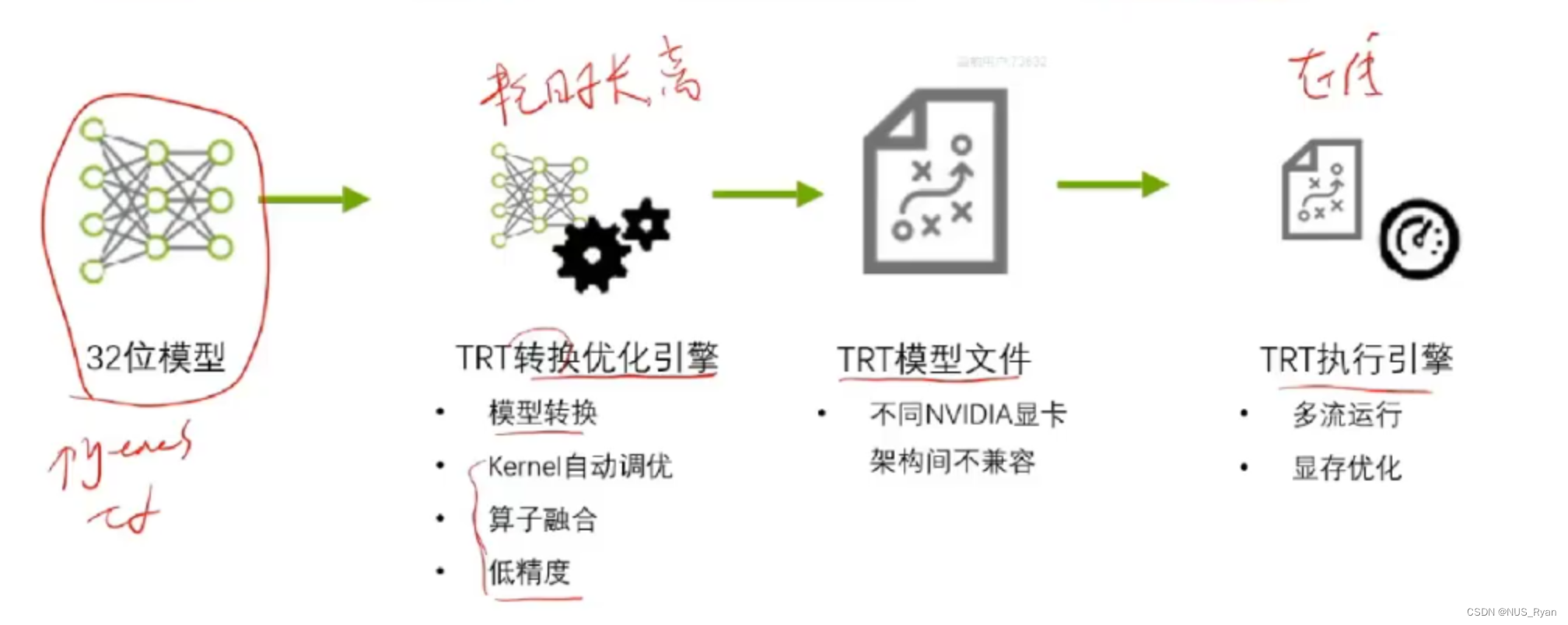
TRT优化策略介绍
- 低精度优化: 比如INT8加速和FP16精度
- Kernel自动调优: 比如在cublas中对于矩阵乘法有多种实现,如何采取合适的矩阵乘法方式就是kernel自动调优。
- 算子融合:
比如原算子如下: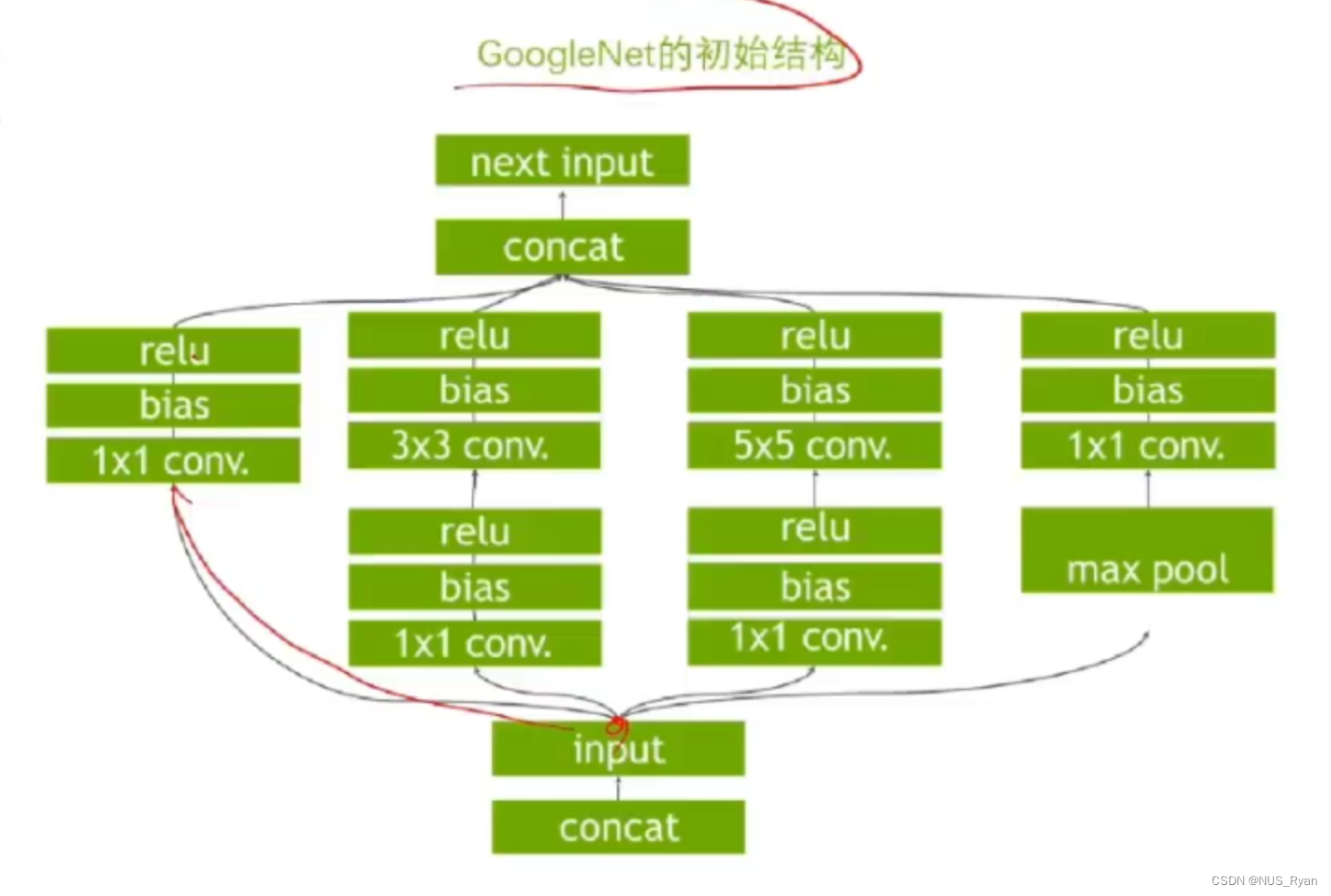
融合后的算子如下:
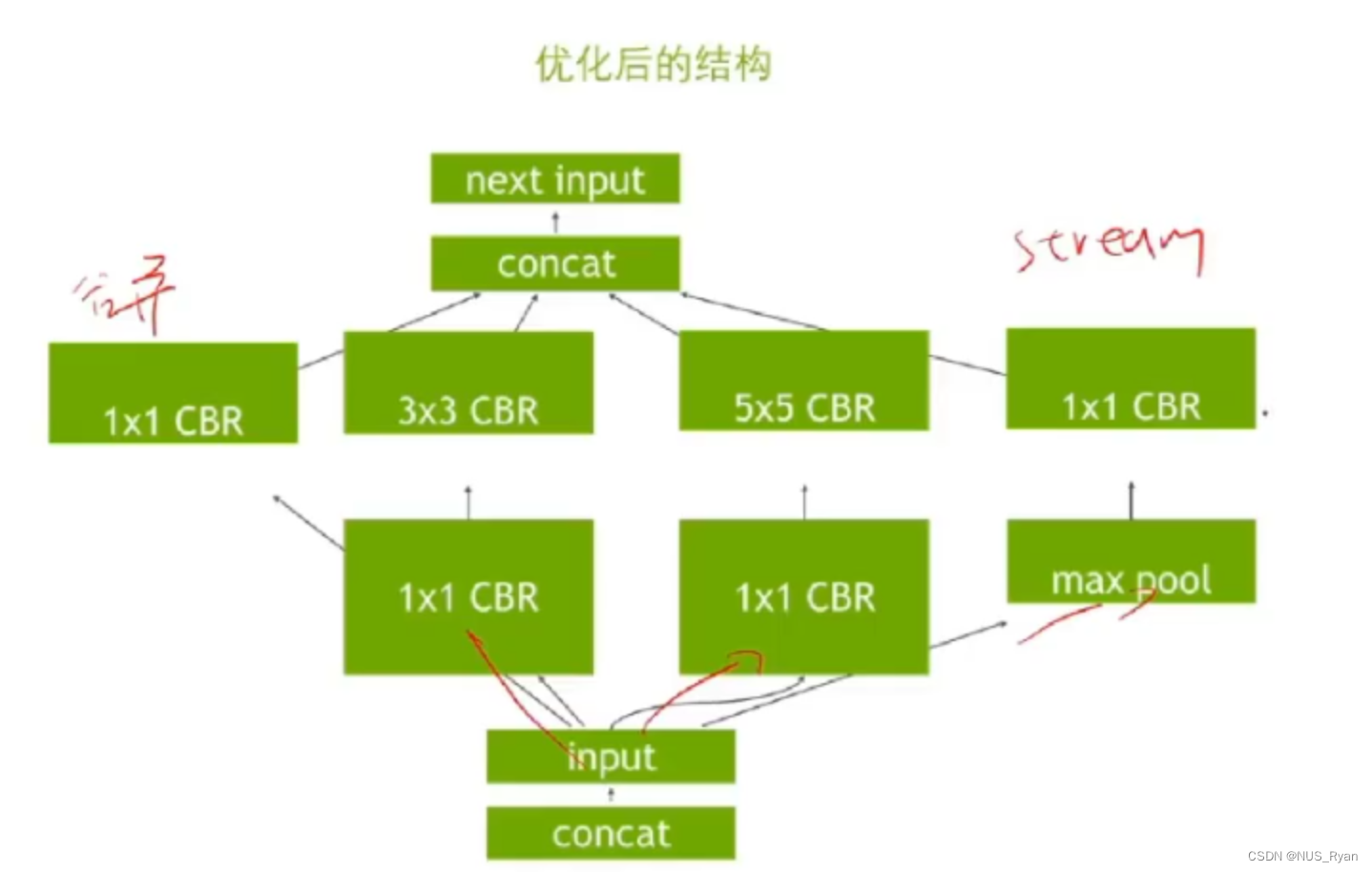
4. 多流运行
5 显存优化
二、TensorRT的组成和基本使用流程
TRT的核心部分是闭源的:
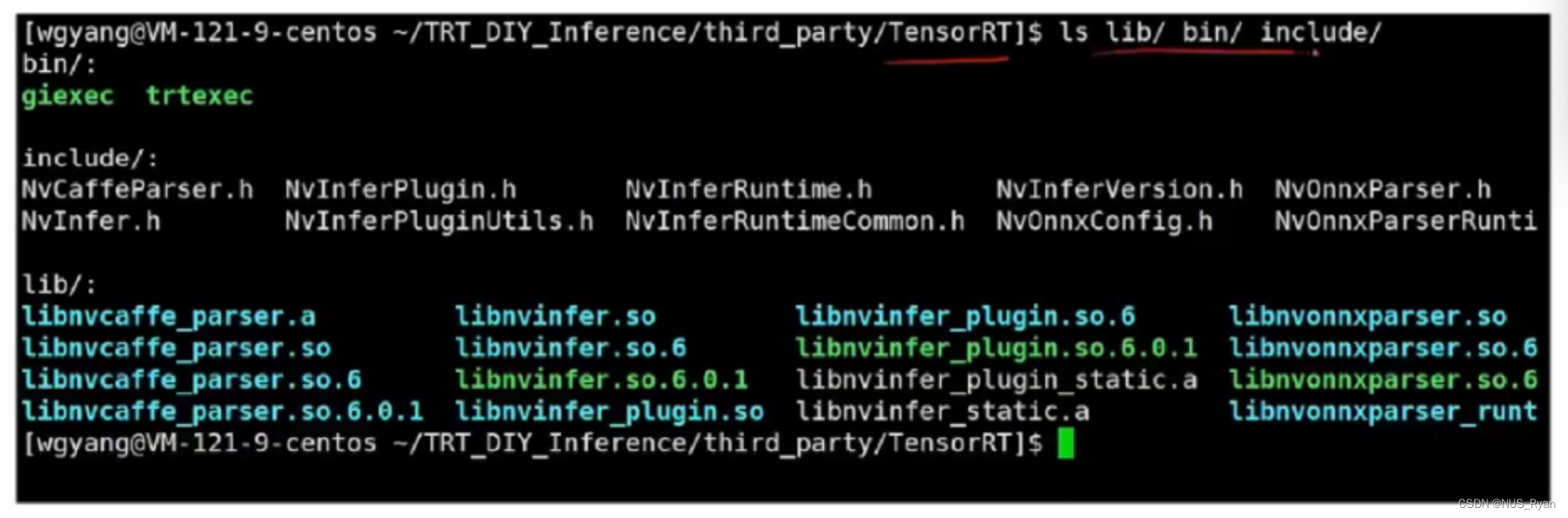
GIthub开源代码,比如模型解析器(caffe,onnx),代码例子和plugin例子:
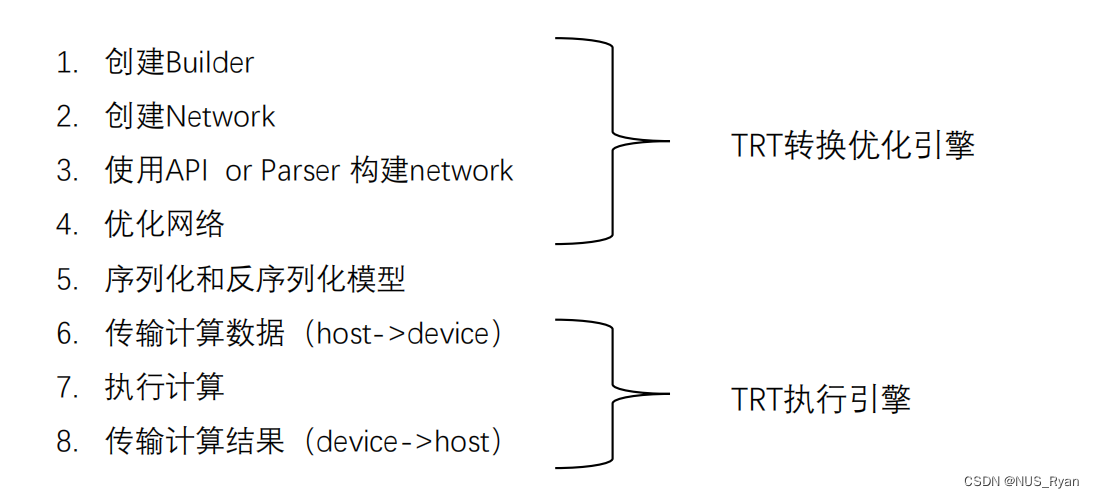
三、TensorRT的基本使用流程
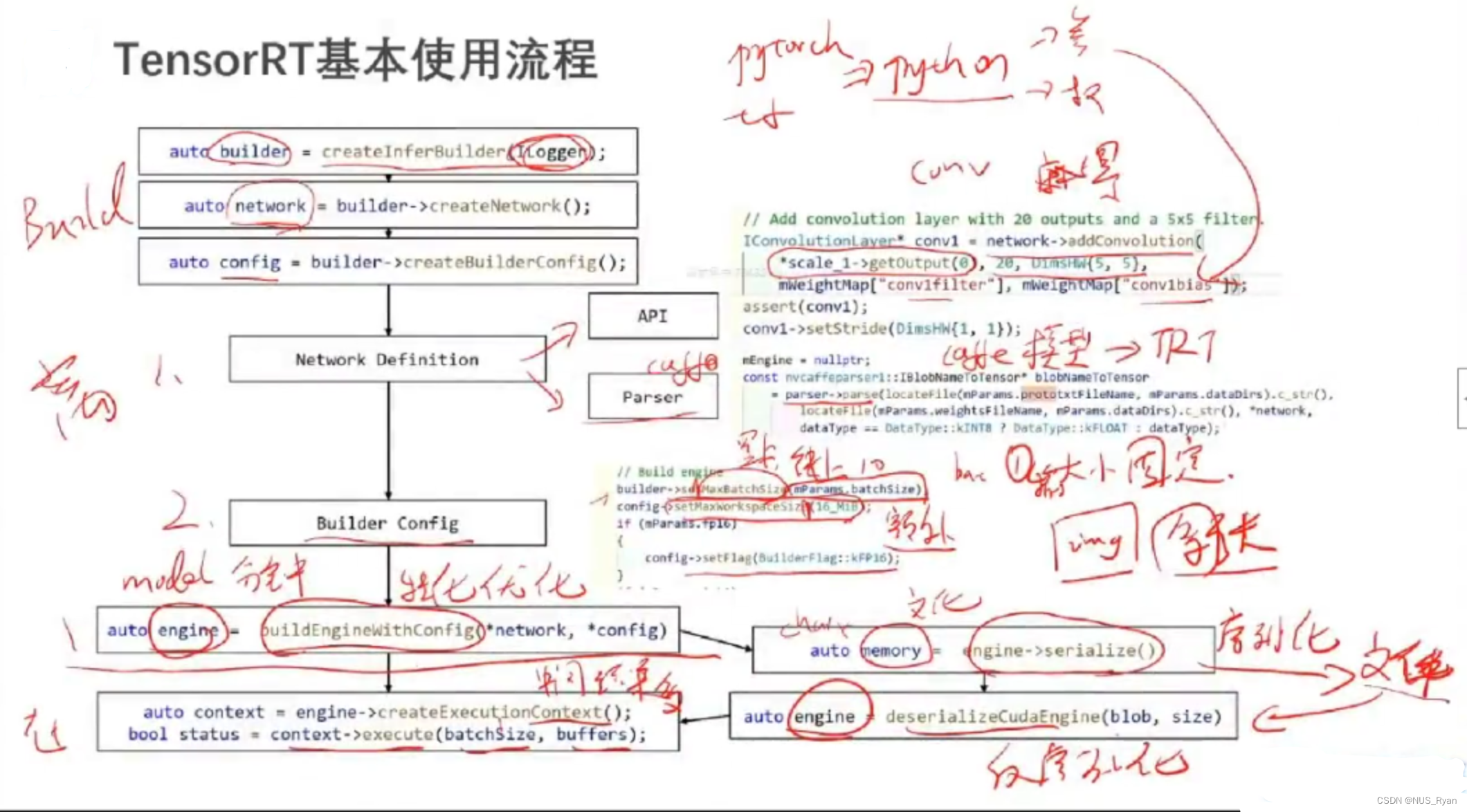
四、TensorRT Demo代码 : SampleMNIST
bool SampleMNIST::build(){
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger.getTRTLogger()));
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetwork());
auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
auto parser = SampleUniquePtr<nvinfer1::ICaffeParser>(nvcaffeparser1::createCaffeParser());
constructNetwork(parser,network);
builder->setMaxBatchSize(mParams.batchSize); //kernel调优前要确认好
config->setMaxWorkspaceSize(16_MiB);
config->setFlag(BuilderFlag::kGPU_FALLBACK);
config->setFlag(BuilderFlag::kSTRICT_TYPES);
if(mParams.fp16){
config->setFlag(BuilderFlag::kFP16);
}
if(mParams.int8){
config->setFlag(BuilderFlag::kINT8);
}
mEngine=std::shared_ptr<nvinfer1::ICudaEngine>(
builder->buildEngineWithConfig(*network,*config),
samplesCommon::InferDeleter());
return true;
}
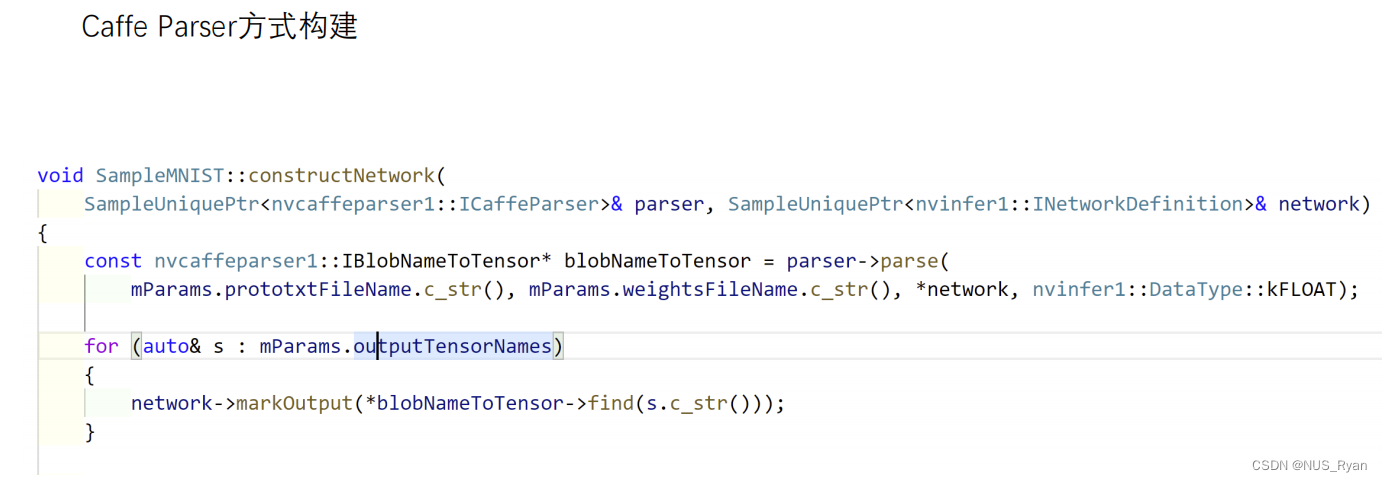
Caffe Parser方式构建
基于Parser的方式构建Network非常简洁
五. TensorRT Plugin
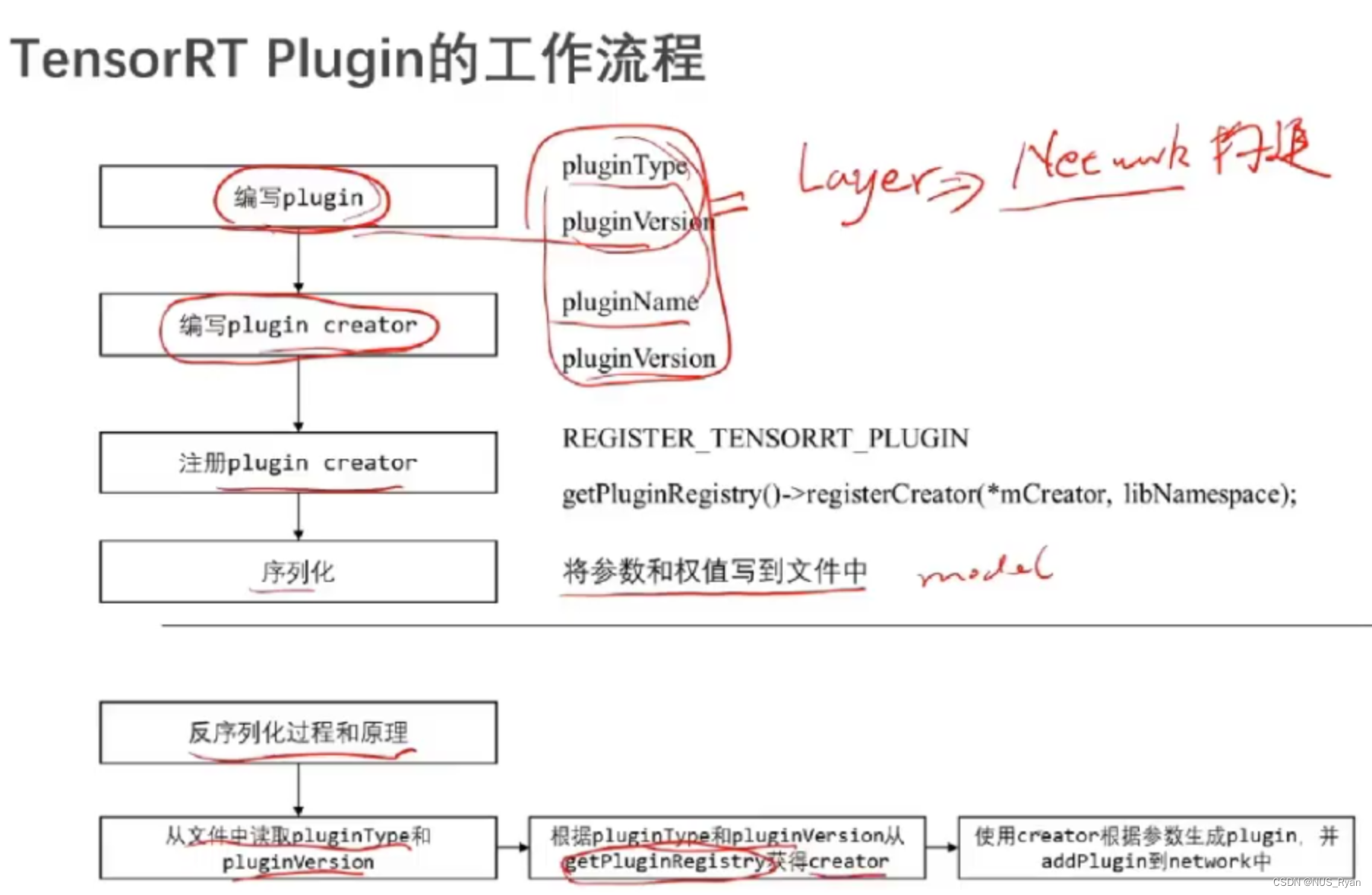
基本概念
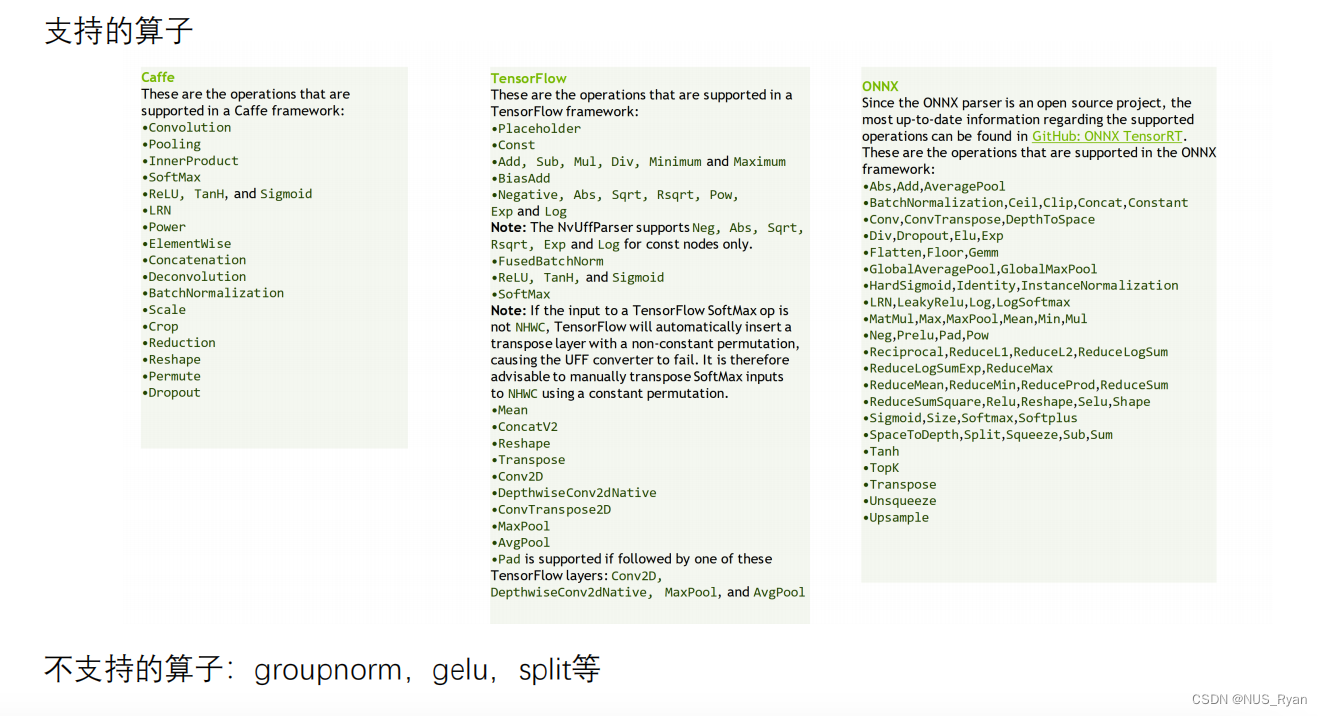
Plugin存在的意义是扩展TensorRT不支持的算子以及进行深度优化和合并已有的算子
- TensorRT支持和不支持的算子如下:
- 对于复杂的网络,合并算子是非常需要的,比如可以将下方的代码合并为一个plugin,从而有效提高性能:
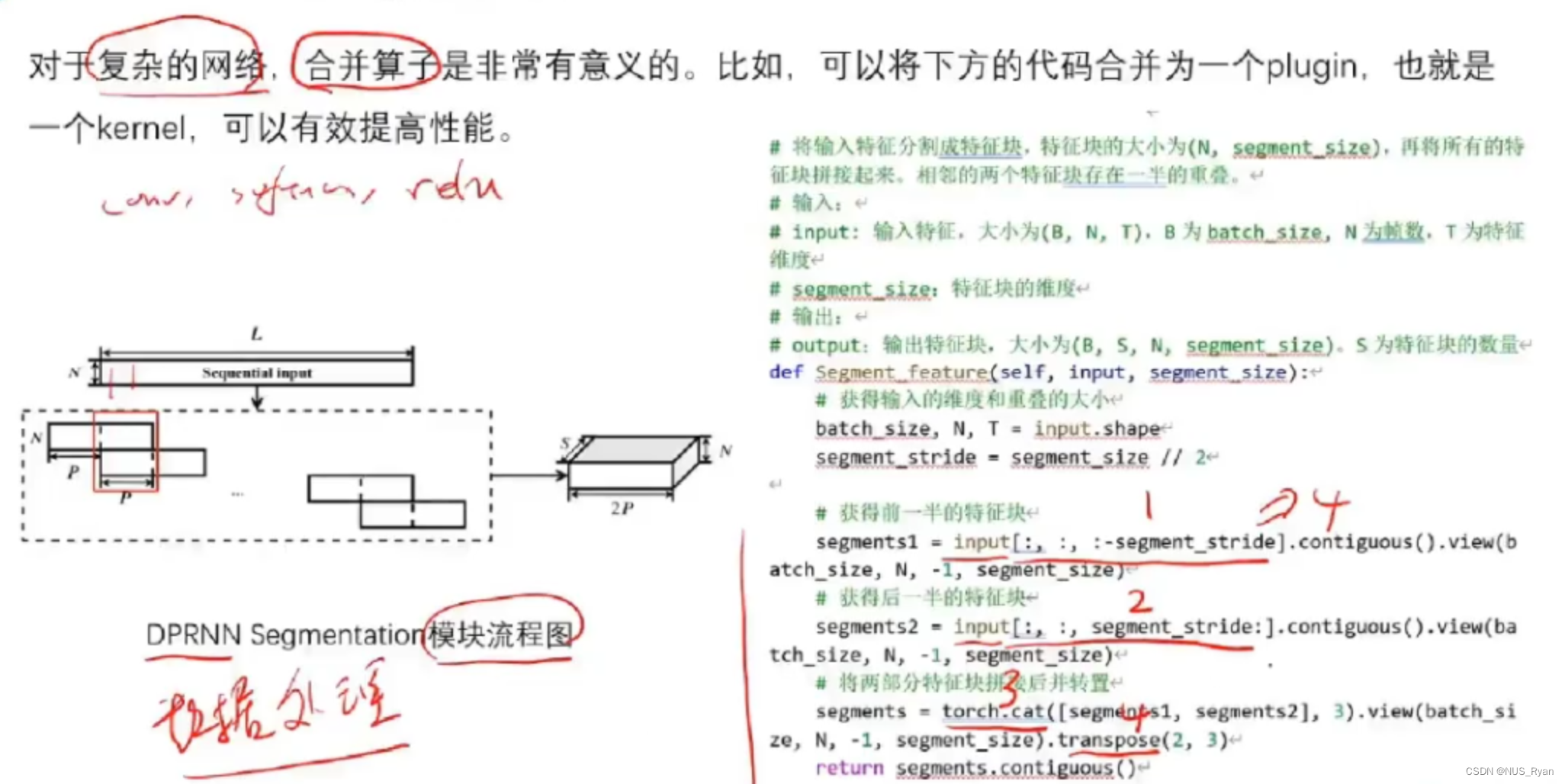
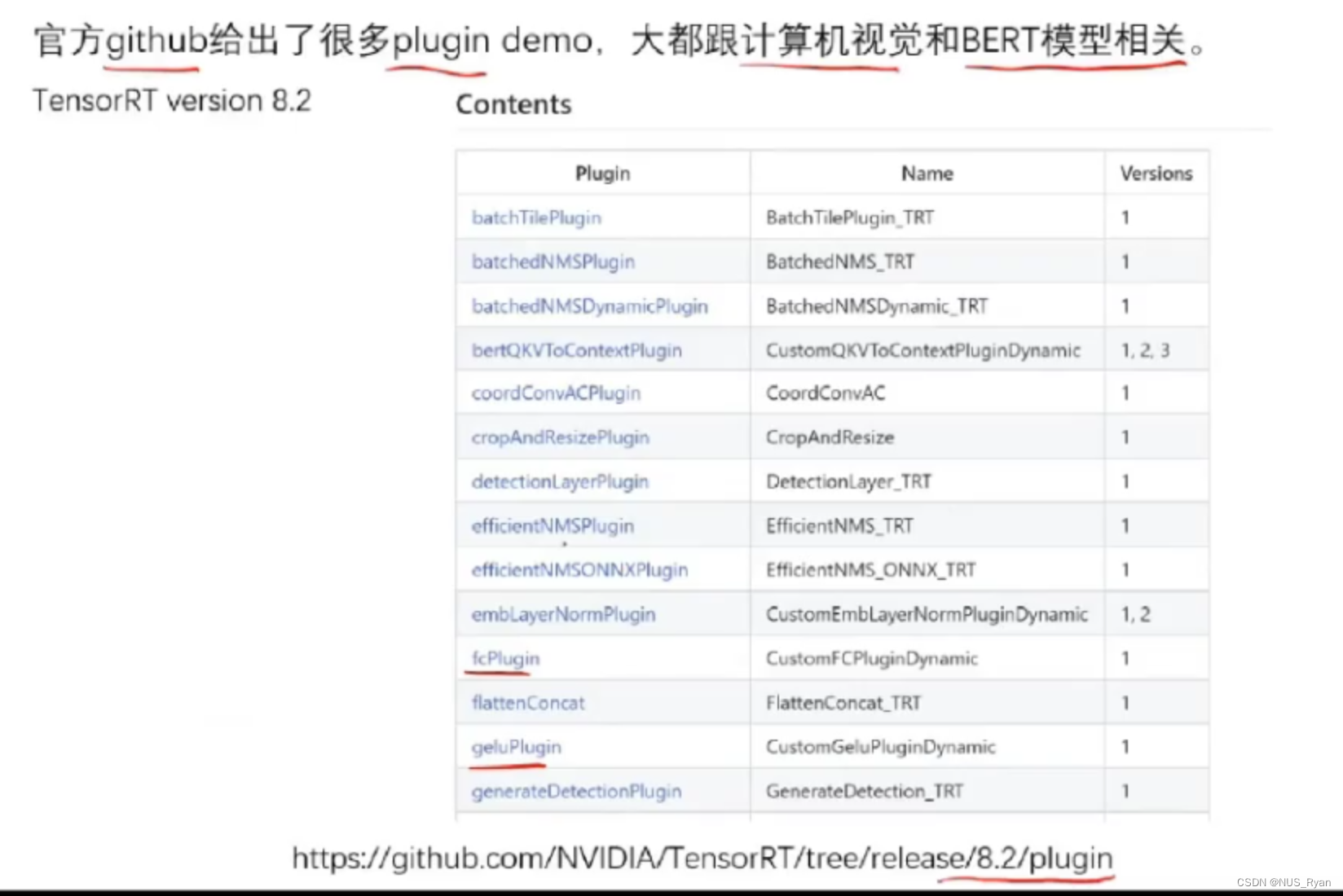
其实官方也实现了很多TRT Plugin Demo
工作流程
API介绍
在TensorRT中,API可以大概分为两类,一类是Static Shape,即输入维度定死,另一类是Dynamic Shape,即输入维度是动态的。
在TensorRT中,Dynamic Shape允许模型接受不同尺寸的输入,而无需重新构建引擎。这对于处理可变大小的输入数据非常有用。下面是一个使用TensorRT C++ API构建具有动态输入形状的模型的简化示例:
#include <NvInfer.h>
#include <iostream>
#include <vector>
using namespace nvinfer1;
int main()
{
// Create the builder and the network.
IBuilder* builder = createInferBuilder(gLogger);
INetworkDefinition* network = builder->createNetworkV2(1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
// Add an input layer with a dynamic shape.
// Set the minimum, optimum, and maximum dimensions.
Dims4 minDims(1, 3, 100, 100);
Dims4 optDims(1, 3, 224, 224);
Dims4 maxDims(1, 3, 512, 512);
ITensor* input = network->addInput("input", DataType::kFLOAT, Dims4(-1, 3, -1, -1));
builder->setMaxBatchSize(1);
// Set the input dynamic shape profile.
IOptimizationProfile* profile = builder->createOptimizationProfile();
profile->setDimensions("input", OptProfileSelector::kMIN, minDims);
profile->setDimensions("input", OptProfileSelector::kOPT, optDims);
profile->setDimensions("input", OptProfileSelector::kMAX, maxDims);
builder->setOptimizationProfile(profile, 0);
// ... (add other layers to the network)
// Mark the output layer.
ITensor* output = ...; // The output tensor of the last layer in the network.
network->markOutput(*output);
// Build the engine.
builder->setMaxWorkspaceSize(1 << 20);
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
// ... (use the engine to run inference)
// Clean up resources.
engine->destroy();
network->destroy();
builder->destroy();
return 0;
}
在这个例子中,我们首先使用kEXPLICIT_BATCH标志创建具有显式批处理支持的网络。然后,我们添加一个输入层,其形状为(-1, 3, -1, -1),其中-1表示维度是动态的。接下来,我们为输入创建一个优化配置文件,并设置最小、最优和最大尺寸。最后,我们使用这个配置文件构建引擎。
当使用这个引擎进行推理时,您可以为具有动态形状的输入设置不同尺寸的数据,而无需重新构建引擎。请注意,这个例子仅说明了构建具有动态输入形状的引擎的基本概念。实际上,您需要向网络中添加其他层,并根据您的需求调整其他参数。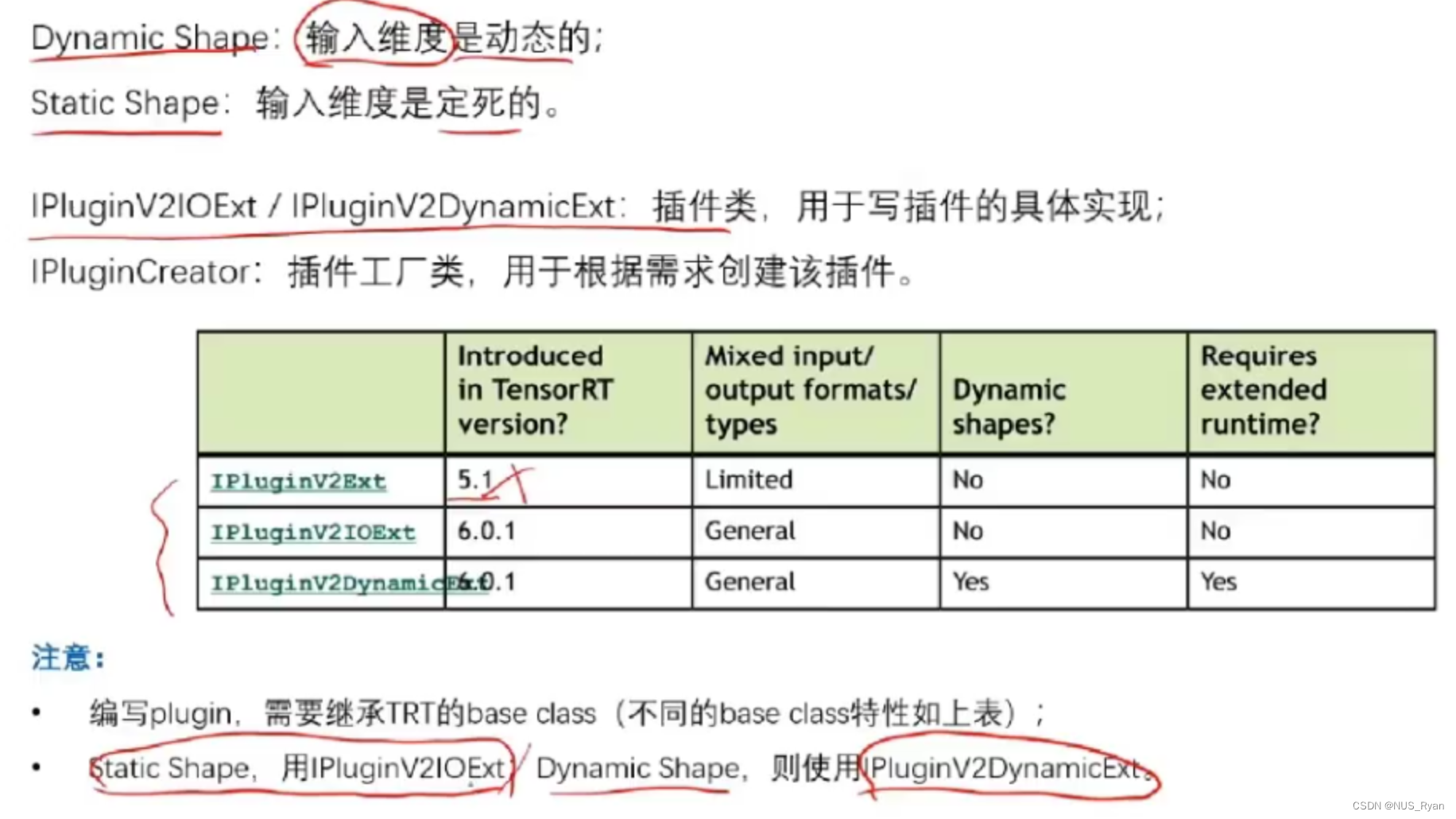
Dynamic Shape Plugin API

Static Shape官方Demo代码讲解
下面我们实现一个EmbLayerNormPlugin Static Shape 的DemoEmbLayerNormPlugin 是 BERT 模型Embedding + Layernorm的合并,BERT 的 EmbLayerNormPlugin 层,主要有以下5个参数:
- 三个 Embedding 参数矩阵,分别是词语的 Embedding,位置的 Embedding, token type 的 Embedding。
- Embedding 操作除上面3个 embedding 做对应位置的求和,同时还要过一个 LayerNorm 操作,即对Embedding 方向的维度做一个归一化,所以还需要LayerNorm 的 beta 和 gamma 参数。
embLayerNormPlugin.h
/*
* Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#ifndef TRT_EMB_LAYER_NORM_PLUGIN_H
#define TRT_EMB_LAYER_NORM_PLUGIN_H
#include "NvInferPlugin.h"
#include <string>
#include <vector>
namespace bert
{
using namespace nvinfer1;
// One of the preferred ways of making TensorRT to be able to see
// our custom layer requires extending IPluginV2 and IPluginCreator classes.
// For requirements for overriden functions, check TensorRT API docs.
class EmbLayerNormPlugin : public IPluginV2Ext
{
public:
EmbLayerNormPlugin(const std::string& name, const bool use_fp16, const Weights& beta, const Weights& gamma,
const Weights& word_emb, const Weights& pos_emb, const Weights& tok_emb);
EmbLayerNormPlugin(const std::string& name, const void* data, size_t length);
// It doesn't make sense to make EmbLayerNormPlugin without arguments, so we
// delete default constructor.
EmbLayerNormPlugin() = delete;
int getNbOutputs() const override;
Dims getOutputDimensions(int index, const Dims* inputs, int nbInputDims) override;
int initialize() override;
void terminate() override;
size_t getWorkspaceSize(int) const override
{
return 0;
};
int enqueue(
int batchSize, const void* const* inputs, void** outputs, void* workspace, cudaStream_t stream) override;
size_t getSerializationSize() const override;
void serialize(void* buffer) const override;
bool supportsFormat(DataType type, PluginFormat format) const override;
const char* getPluginType() const override;
const char* getPluginVersion() const override;
void destroy() override;
nvinfer1::IPluginV2Ext* clone() const override;
void setPluginNamespace(const char* pluginNamespace) override;
const char* getPluginNamespace() const override;
DataType getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const override;
bool isOutputBroadcastAcrossBatch(int outputIndex, const bool* inputIsBroadcasted, int nbInputs) const
{
return false;
}
bool canBroadcastInputAcrossBatch(int inputIndex) const
{
return false;
}
void configurePlugin(const Dims* inputDims, int nbInputs, const Dims* outputDims, int nbOutputs,
const DataType* inputTypes, const DataType* outputTypes, const bool* inputIsBroadcast,
const bool* outputIsBroadcast, PluginFormat floatFormat, int maxBatchSize) override;
private:
const std::string mLayerName;
std::string mNamespace;
float* mGammaDev;
float* mBetaDev;
float* mWordEmbDev;
float* mTokEmbDev;
float* mPosEmbDev;
size_t mLd; // leading dim = hidden size
size_t mB; // batch size
size_t mS; // sequence length
size_t mWordVocabSize;
size_t mPosVocabSize;
size_t mTokVocabSize;
Weights mBeta;
Weights mGamma;
Weights mWordEmb;
Weights mTokEmb;
Weights mPosEmb;
DataType mType;
};
class EmbLayerNormPluginCreator : public IPluginCreator
{
public:
EmbLayerNormPluginCreator();
const char* getPluginName() const override;
const char* getPluginVersion() const override;
const PluginFieldCollection* getFieldNames() override;
IPluginV2* createPlugin(const char* name, const PluginFieldCollection* fc) override;
IPluginV2* deserializePlugin(const char* name, const void* serialData, size_t serialLength) override;
void setPluginNamespace(const char* pluginNamespace) override;
const char* getPluginNamespace() const override;
private:
static PluginFieldCollection mFC;
static std::vector<PluginField> mPluginAttributes;
std::string mNamespace;
};
}
#endif // TRT_EMB_LAYER_NORM_PLUGIN_H
embLayerNormPlugin.cu
/*
* Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
#include "NvInfer.h"
#include "embLayerNormPlugin.h"
#include "logger.h"
#include "pluginKernels.h"
#include "pluginUtil.h"
#include <cassert>
#include <cstring>
#include <vector>
using bert::operator+;
namespace bert
{
template <typename T, unsigned TPB>
__global__ void embLayerNormKernel(int ld, const int* inputIds, const int* tokenIds, const float* beta,
const float* gamma, const float* wordEmb, const float* posEmb, const float* tokEmb, T* output)
{
cub::Sum pairSum;
// 1. lookup word and token of the block
// blockIdx.x = position in the sequence
// blockIdx.y = batch
// gridDim.x = S
// gridDim.y = B
__shared__ int wordId;
__shared__ int tokenId;
const T rld = T(1.f) / T(ld);
const int seqPos = blockIdx.y * gridDim.x + blockIdx.x;
if (threadIdx.x == 0)
{
wordId = inputIds[seqPos];
tokenId = tokenIds[seqPos];
}
__syncthreads();
// 2. load pos/tok/word embeddings and add them toghether
// offset into embeddings is given by wordId * hidden_size
const int poffset = blockIdx.x * ld;
const int woffset = wordId * ld;
const int toffset = tokenId * ld;
// the output offset is given by b * (S*hidden_size) + s * hidden_size
const int outOffset = seqPos * ld;
kvp<T> threadData(0, 0);
for (int it = threadIdx.x; it < ld; it += TPB)
{
const T w(wordEmb[woffset + it]);
const T t(tokEmb[toffset + it]);
const T p(posEmb[poffset + it]);
const T val = w + t + p;
output[outOffset + it] = val;
const T rldval = rld * val;
threadData = pairSum(threadData, kvp<T>(rldval, rldval * val));
}
// 3. layer norm on the sum
layerNorm<T, TPB>(threadData, ld, outOffset, beta, gamma, output);
}
template <typename T>
int embSkipLayerNorm(cudaStream_t stream, int ld, int B, int S, const int* inputIds, const int* token_ids,
const float* beta, const float* gamma, const float* wordEmb, const float* posEmb, const float* tokEmb, T* output)
{
constexpr int tpb = 256;
const dim3 grid(S, B, 1);
const dim3 block(tpb, 1, 1);
embLayerNormKernel<T, tpb>
<<<grid, block, 0, stream>>>(ld, inputIds, token_ids, beta, gamma, wordEmb, posEmb, tokEmb, output);
CHECK(cudaPeekAtLastError());
return 0;
}
using namespace nvinfer1;
// Clip plugin specific constants
namespace
{
static const char* EMB_LAYER_NORM_VERSION{"1"};
static const char* EMB_LAYER_NORM_NAME{"CustomEmbLayerNormPlugin"};
} // namespace
// Static class fields initialization
PluginFieldCollection EmbLayerNormPluginCreator::mFC{};
std::vector<PluginField> EmbLayerNormPluginCreator::mPluginAttributes;
REGISTER_TENSORRT_PLUGIN(EmbLayerNormPluginCreator);
EmbLayerNormPlugin::EmbLayerNormPlugin(const std::string& name, const bool outputFp16, const Weights& beta,
const Weights& gamma, const Weights& wordEmb, const Weights& posEmb, const Weights& tokEmb)
: mLayerName(name)
, mLd(beta.count)
, mGamma(gamma)
, mBeta(beta)
, mWordEmb(wordEmb)
, mPosEmb(posEmb)
, mTokEmb(tokEmb)
, mGammaDev(nullptr)
, mBetaDev(nullptr)
, mWordEmbDev(nullptr)
, mTokEmbDev(nullptr)
, mPosEmbDev(nullptr)
{
// Assuming Weights.count is the number of elements and not bytes
assert(beta.count == gamma.count);
assert(wordEmb.count % mLd == 0);
assert(posEmb.count % mLd == 0);
assert(tokEmb.count % mLd == 0);
mWordVocabSize = wordEmb.count / mLd;
mPosVocabSize = posEmb.count / mLd;
mTokVocabSize = tokEmb.count / mLd;
// We set mS in configure
mType = outputFp16 ? DataType::kHALF : DataType::kFLOAT;
}
EmbLayerNormPlugin::EmbLayerNormPlugin(const std::string& name, const void* data, size_t length)
: mLayerName(name)
{
gLogVerbose << "EMB LN Deser start\n";
// Deserialize in the same order as serialization
const char* d = static_cast<const char*>(data);
const char* a = d;
DESER(d, mType);
DESER(d, mLd);
DESER(d, mS);
DESER(d, mWordVocabSize);
DESER(d, mPosVocabSize);
DESER(d, mTokVocabSize);
mBetaDev = deserToDev<float>(d, mLd);
mGammaDev = deserToDev<float>(d, mLd);
mWordEmbDev = deserToDev<float>(d, mLd * mWordVocabSize);
mPosEmbDev = deserToDev<float>(d, mLd * mPosVocabSize);
mTokEmbDev = deserToDev<float>(d, mLd * mTokVocabSize);
assert(d == (a + length));
// this signals init not to allocate/copy
mGamma.count = -1;
mBeta.count = -1;
mWordEmb.count = -1;
mTokEmb.count = -1;
mPosEmb.count = -1;
mGamma.values = nullptr;
mBeta.values = nullptr;
mWordEmb.values = nullptr;
mTokEmb.values = nullptr;
mPosEmb.values = nullptr;
gLogVerbose << "EMB LN Deser done\n";
}
const char* EmbLayerNormPlugin::getPluginType() const
{
return EMB_LAYER_NORM_NAME;
}
const char* EmbLayerNormPlugin::getPluginVersion() const
{
return EMB_LAYER_NORM_VERSION;
}
int EmbLayerNormPlugin::getNbOutputs() const
{
return 2;
}
DataType EmbLayerNormPlugin::getOutputDataType(int index, const nvinfer1::DataType* inputTypes, int nbInputs) const
{
assert(index == 0 || index == 1);
if (index == 0)
{
assert(mType == DataType::kHALF || mType == DataType::kFLOAT);
return mType;
}
return DataType::kINT32;
}
Dims EmbLayerNormPlugin::getOutputDimensions(int index, const Dims* inputs, int nbInputDims)
{
// Input should be input ids and token ids and the input mask
// Output should be the embeddings tensor and mask indices
assert(nbInputDims == 3);
assert(inputs[0].nbDims == 1); // S
assert(inputs[0].nbDims == inputs[1].nbDims);
const int S = inputs[0].d[0];
assert(inputs[1].d[0] == S);
assert(inputs[2].d[0] == S);
assert(index == 0 || index == 1);
if (index == 0)
{
const int hidden_size = mLd;
return Dims4{S, hidden_size, 1, 1};
}
return Dims{1, 1};
}
int EmbLayerNormPlugin::initialize()
{
if (mGamma.values)
{
CHECK(cudaMalloc(&mGammaDev, sizeof(float) * mGamma.count));
CHECK(cudaMemcpy(mGammaDev, mGamma.values, sizeof(float) * mGamma.count, cudaMemcpyHostToDevice));
}
if (mBeta.values)
{
CHECK(cudaMalloc(&mBetaDev, sizeof(float) * mBeta.count));
CHECK(cudaMemcpy(mBetaDev, mBeta.values, sizeof(float) * mBeta.count, cudaMemcpyHostToDevice));
}
if (mWordEmb.values)
{
CHECK(cudaMalloc(&mWordEmbDev, sizeof(float) * mWordEmb.count));
CHECK(cudaMemcpy(mWordEmbDev, mWordEmb.values, sizeof(float) * mWordEmb.count, cudaMemcpyHostToDevice));
}
if (mTokEmb.values)
{
CHECK(cudaMalloc(&mTokEmbDev, sizeof(float) * mTokEmb.count));
CHECK(cudaMemcpy(mTokEmbDev, mTokEmb.values, sizeof(float) * mTokEmb.count, cudaMemcpyHostToDevice));
}
if (mPosEmb.values)
{
CHECK(cudaMalloc(&mPosEmbDev, sizeof(float) * mPosEmb.count));
CHECK(cudaMemcpy(mPosEmbDev, mPosEmb.values, sizeof(float) * mPosEmb.count, cudaMemcpyHostToDevice));
}
return 0;
}
int EmbLayerNormPlugin::enqueue(int batchSize, const void* const* inputs, void** outputs, void*, cudaStream_t stream)
{
int status = -1;
// Our plugin outputs only one tensor
const int* inputIds = static_cast<const int*>(inputs[0]);
const int* segmentIds = static_cast<const int*>(inputs[1]);
const int* inputMask = static_cast<const int*>(inputs[2]);
if (mType == DataType::kFLOAT)
{
float* output = static_cast<float*>(outputs[0]);
embSkipLayerNorm<float>(stream, mLd, batchSize, mS, inputIds, segmentIds, mBetaDev, mGammaDev, mWordEmbDev,
mPosEmbDev, mTokEmbDev, output);
}
else if (mType == DataType::kHALF)
{
half* output = static_cast<half*>(outputs[0]);
embSkipLayerNorm<half>(stream, mLd, batchSize, mS, inputIds, segmentIds, mBetaDev, mGammaDev, mWordEmbDev,
mPosEmbDev, mTokEmbDev, output);
}
else
{
assert(false);
}
int* maskIdx = static_cast<int*>(outputs[1]);
computeMaskIdx(stream, mS, batchSize, inputMask, maskIdx);
return status;
}
size_t EmbLayerNormPlugin::getSerializationSize() const
{
return 2 * sizeof(float) * mLd // beta + gamma
+ sizeof(mType) + sizeof(mLd) * 5 //mLd, mS, m*VocabSize
+ sizeof(float) * mLd * mWordVocabSize // word emb
+ sizeof(float) * mLd * mPosVocabSize // pos emb
+ sizeof(float) * mLd * mTokVocabSize // tok emb
;
}
void EmbLayerNormPlugin::serialize(void* buffer) const
{
char* d = static_cast<char*>(buffer);
const char* a = d;
writeToBuffer(d, mType);
writeToBuffer(d, mLd);
writeToBuffer(d, mS);
writeToBuffer(d, mWordVocabSize);
writeToBuffer(d, mPosVocabSize);
writeToBuffer(d, mTokVocabSize);
serFromDev(d, mBetaDev, mLd);
serFromDev(d, mGammaDev, mLd);
serFromDev(d, mWordEmbDev, mLd * mWordVocabSize);
serFromDev(d, mPosEmbDev, mLd * mPosVocabSize);
serFromDev(d, mTokEmbDev, mLd * mTokVocabSize);
assert(d == a + getSerializationSize());
}
void EmbLayerNormPlugin::configurePlugin(const Dims* inputs, int nbInputs, const Dims* outputs, int nbOutputs,
const DataType* inputTypes, const DataType* outputTypes, const bool* inputIsBroadcast,
const bool* outputIsBroadcast, PluginFormat format, int maxBatchSize)
{
// Validate input arguments
assert(nbOutputs == 2);
assert(nbInputs == 3);
assert(inputs[0].nbDims == 1);
mS = inputs[0].d[0];
assert(mS == inputs[1].d[0]);
assert(mS == inputs[2].d[0]);
assert(outputs[0].nbDims == 4);
assert(outputs[0].d[0] == mS);
assert(outputs[0].d[1] == mLd);
assert(outputs[0].d[2] == 1);
assert(outputs[0].d[3] == 1);
assert(outputs[1].nbDims == 1);
assert(outputs[1].d[0] == 1);
assert(format == PluginFormat::kNCHW);
assert(inputTypes[0] == DataType::kINT32);
assert(inputTypes[1] == DataType::kINT32);
assert(inputTypes[2] == DataType::kINT32);
const DataType out_type = outputTypes[0];
assert(out_type == DataType::kFLOAT || out_type == DataType::kHALF);
assert(outputTypes[1] == DataType::kINT32);
}
bool EmbLayerNormPlugin::supportsFormat(DataType type, PluginFormat format) const
{
if (type == DataType::kINT32 || type == DataType::kFLOAT || type == DataType::kHALF)
{
return format == PluginFormat::kNCHW;
}
else
{
return false;
}
}
void EmbLayerNormPlugin::terminate()
{
gLogVerbose << "EMBLN terminate start" << std::endl;
cudaFree(mGammaDev);
cudaFree(mBetaDev);
cudaFree(mWordEmbDev);
cudaFree(mTokEmbDev);
cudaFree(mPosEmbDev);
gLogVerbose << "EMBLN terminate done" << std::endl;
}
void EmbLayerNormPlugin::destroy()
{
gLogVerbose << "EMBLN destroy start" << std::endl;
// This gets called when the network containing plugin is destroyed
delete this;
gLogVerbose << "EMBLN destroy start" << std::endl;
}
IPluginV2Ext* EmbLayerNormPlugin::clone() const
{
gLogVerbose << "EMBLN clone start" << std::endl;
auto ret = new EmbLayerNormPlugin(mLayerName, mType == DataType::kHALF, mBeta, mGamma, mWordEmb, mPosEmb, mTokEmb);
ret->mS = mS;
ret->mWordEmbDev = mWordEmbDev;
ret->mPosEmbDev = mPosEmbDev;
ret->mTokEmbDev = mTokEmbDev;
ret->mBetaDev = mBetaDev;
ret->mGammaDev = mGammaDev;
gLogVerbose << "EMBLN clone done" << std::endl;
return ret;
}
void EmbLayerNormPlugin::setPluginNamespace(const char* libNamespace)
{
mNamespace = libNamespace;
}
const char* EmbLayerNormPlugin::getPluginNamespace() const
{
return mNamespace.c_str();
}
EmbLayerNormPluginCreator::EmbLayerNormPluginCreator()
{
mFC.nbFields = mPluginAttributes.size();
mFC.fields = mPluginAttributes.data();
}
const char* EmbLayerNormPluginCreator::getPluginName() const
{
return EMB_LAYER_NORM_NAME;
}
const char* EmbLayerNormPluginCreator::getPluginVersion() const
{
return EMB_LAYER_NORM_VERSION;
}
const PluginFieldCollection* EmbLayerNormPluginCreator::getFieldNames()
{
return &mFC;
}
IPluginV2* EmbLayerNormPluginCreator::createPlugin(const char* name, const PluginFieldCollection* fc)
{
gLogVerbose << "Creating EmbLayerNormPlugin...\n";
bool output_fp16 = true;
Weights beta;
Weights gamma;
Weights word_emb;
Weights pos_emb;
Weights tok_emb;
for(int i=0; i< fc->nbFields; i++)
{
std::string field_name(fc->fields[i].name);
if (field_name.compare("bert_embeddings_layernorm_beta")==0)
{
gLogVerbose << "Building bert_embeddings_layernorm_beta...\n";
beta.values = fc->fields[i].data;
beta.count = fc->fields[i].length;
beta.type = static_cast<DataType>(fc->fields[i].type);
}
if (field_name.compare("bert_embeddings_layernorm_gamma")==0)
{
gLogVerbose << "Building bert_embeddings_layernorm_gamma...\n";
gamma.values = fc->fields[i].data;
gamma.count = fc->fields[i].length;
gamma.type = static_cast<DataType>(fc->fields[i].type);
}
if (field_name.compare("bert_embeddings_word_embeddings")==0)
{
gLogVerbose << "Building bert_embeddings_word_embeddings...\n";
word_emb.values = fc->fields[i].data;
word_emb.count = fc->fields[i].length;
word_emb.type = static_cast<DataType>(fc->fields[i].type);
}
if (field_name.compare("bert_embeddings_token_type_embeddings")==0)
{
gLogVerbose << "Building bert_embeddings_token_type_embeddings...\n";
tok_emb.values = fc->fields[i].data;
tok_emb.count = fc->fields[i].length;
tok_emb.type = static_cast<DataType>(fc->fields[i].type);
}
if (field_name.compare("bert_embeddings_position_embeddings")==0)
{
gLogVerbose << "Building bert_embeddings_position_embeddings...\n";
pos_emb.values = fc->fields[i].data;
pos_emb.count = fc->fields[i].length;
pos_emb.type = static_cast<DataType>(fc->fields[i].type);
}
}
gLogVerbose << "Building the Plugin...\n";
EmbLayerNormPlugin* p = new EmbLayerNormPlugin(name, output_fp16, beta, gamma, word_emb, pos_emb, tok_emb);
return p;
}
IPluginV2* EmbLayerNormPluginCreator::deserializePlugin(const char* name, const void* serialData, size_t serialLength)
{
// This object will be deleted when the network is destroyed, which will
// call EmbLayerNormPlugin::destroy()
return new EmbLayerNormPlugin(name, serialData, serialLength);
}
void EmbLayerNormPluginCreator::setPluginNamespace(const char* libNamespace)
{
mNamespace = libNamespace;
}
const char* EmbLayerNormPluginCreator::getPluginNamespace() const
{
return mNamespace.c_str();
}
}
TensorRT Plugin Creator

TensorRT Plugin 如何进行debug
TRT是闭源软件,API相对比较复杂
-
无论是使用APP还是parser构建网络,模型转换完后,结果误差很大要怎么办?
在通过parser转化完了网络之后,使用tensorflow的dump API接口查看网络结构是否正确 -
增加了自定义Plugin实现算子合并,结果对不上,怎么办?
使用了Plugin,同时也要写单元测试代码 -
使用FP16 或者 INT8优化策略之后,算法精确度掉了很多要怎么办?
(1)官方: 将可疑的层输出设置为network output(比较繁琐)
(2) 经验 : 增加一个debug的plugin,可以参考:
六. TensorRT INT8 加速
FP16
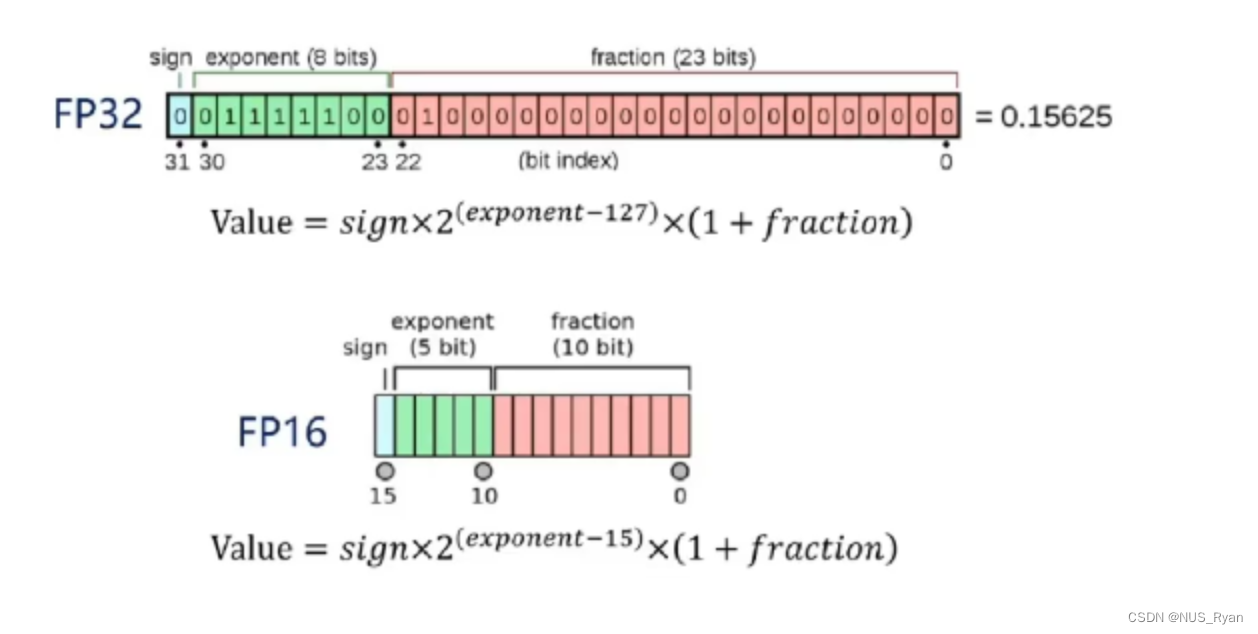
如何在Tensor RT中采用FP16进行优化?当然,首先要调用builder->platformHasFastFp16();查看显卡是否支持FP16.

INT8
INT8量化就是将基于浮点的模型转换成低精度的INT8数值进行计算,以加快推理速度。
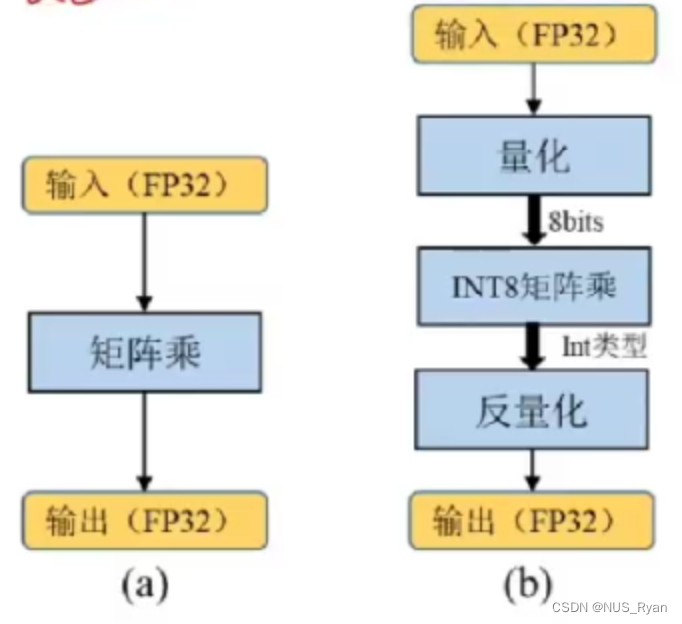
为什么INT8量化会快呢?
(1)对于计算能力大于等于SM_61的显卡,如Tesla P4/P40 GPU,NVIDIA提供了新的INT8点乘运算的指令支持-DP4A。该计算过程可以获得理论上最大4倍的性能提升。
(2)Volta架构中引入了Tensor Core也能加速INT8运算
FP16 和 INT8能加速的本质:
通过指令 或者 硬件技术,在单位时钟周期内,FP16 和 INT8 类型的运算次数 大于 FP32 类型的运算次数。
为什么INT8对于准确度的影响是有限的
神经网络的特性:具有一定的鲁棒性。
原因:训练数据一般都是有噪声的,神经网络的训练过程就是从噪声中识别出有效的信息。
思路:可以将低精度计算造成的损失理解为另一种噪声。
同时,由于训练好的神经网络的权重分布是正态分布的,大多集中于均值附近,所以损失权重的一些边缘值不会影响权重分布的漂移。
动态对称量化算法

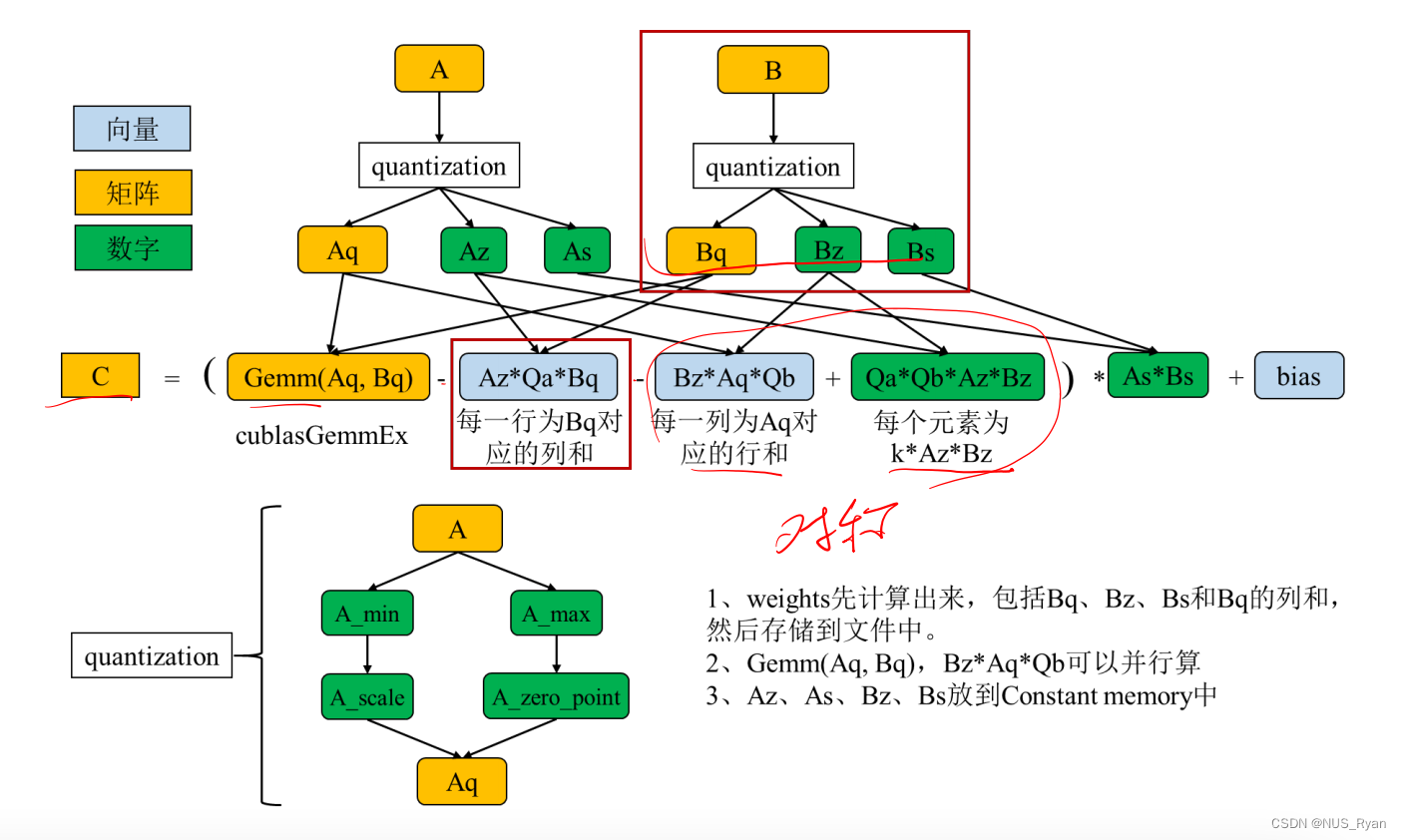
动态非对称量化算法
该
 在并行运算环境下,该算法的实现非常复杂,如下图所示:
在并行运算环境下,该算法的实现非常复杂,如下图所示:
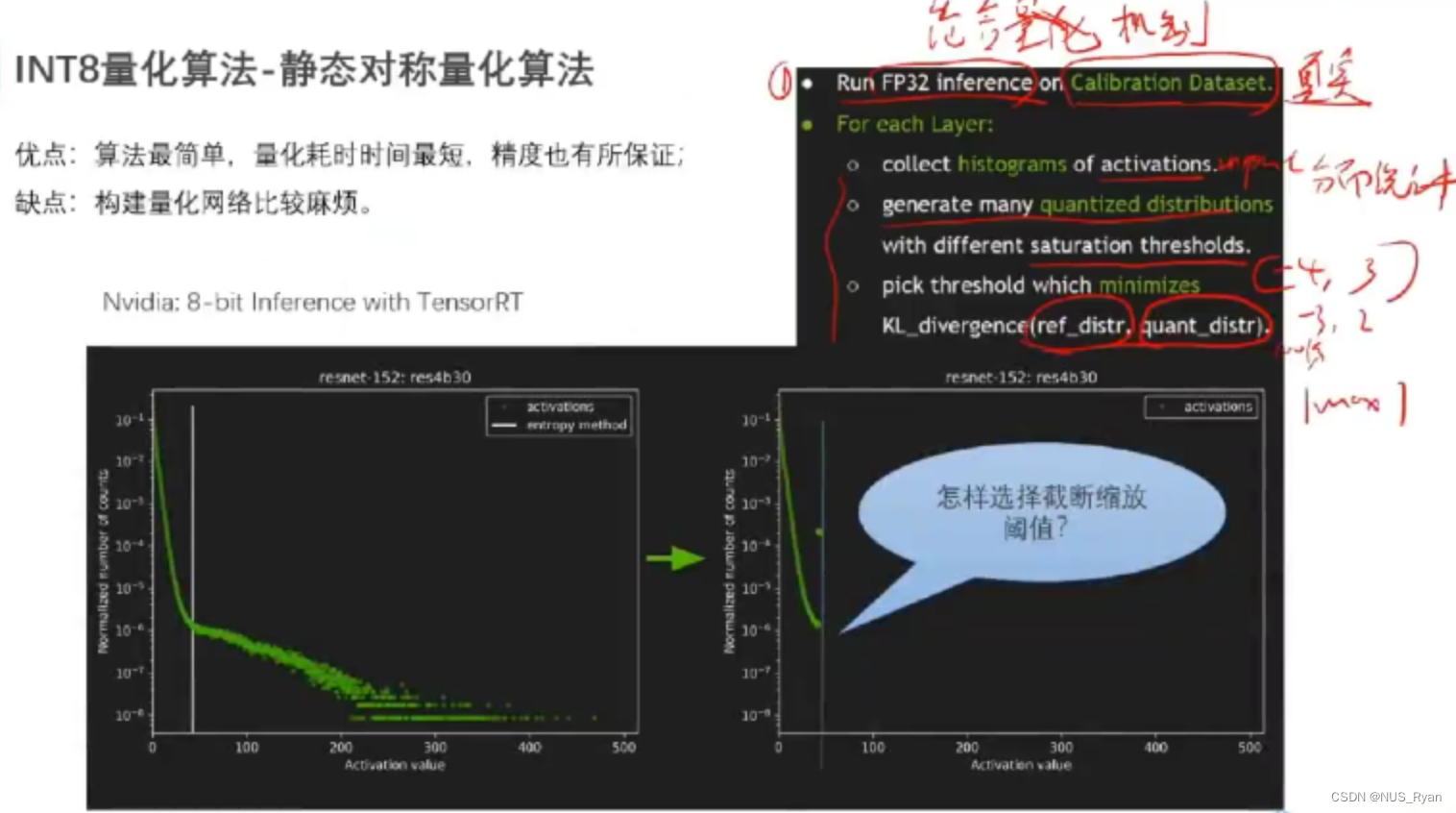
静态对称量化算法
静态对称量化算法的优点是算法简单,量化耗时较短,且精度也有所保证,缺点是构建量化网络比较麻烦
假设我们有一个预训练的简单卷积神经网络,包括一个卷积层、ReLU激活函数和一个全连接层。我们将使用TensorRT对这个网络进行INT8量化。
准备数据:为了进行量化,我们需要准备一组表示神经网络输入分布的校准数据。这些数据可以是训练数据集的一个子集或验证数据集。
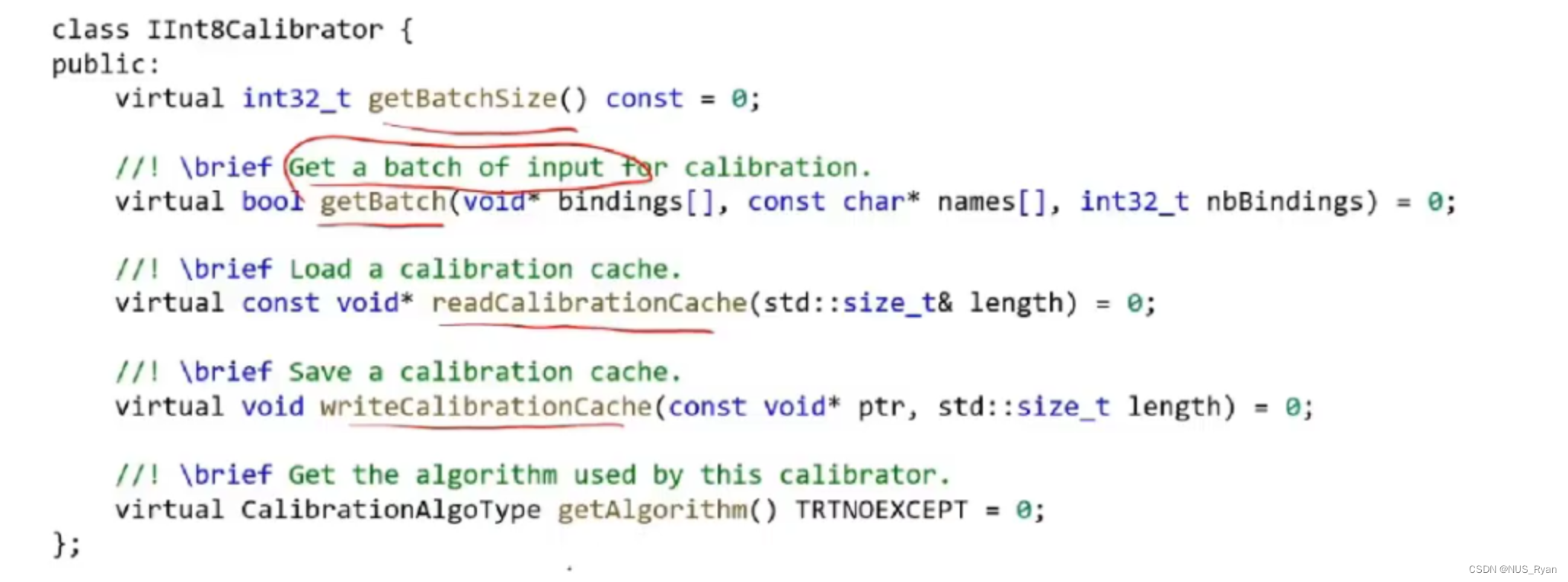
创建校准表:创建一个继承自nvinfer1::IInt8EntropyCalibrator2的类。在这个类中,我们需要实现getBatch()、readCalibrationCache()和writeCalibrationCache()三个方法。getBatch()用于从校准数据集中获取一个批次的数据,readCalibrationCache()和writeCalibrationCache()分别用于从文件中读取和写入校准缓存。
创建TensorRT网络:加载预训练模型并创建一个对应的TensorRT网络。设置BuilderFlag::kINT8标志以启用INT8量化。
创建校准器:实例化我们在第2步创建的校准器类,并将其传递给TensorRT的IBuilder。在网络构建过程中,TensorRT将使用校准器来计算权重和激活值的缩放因子。
构建引擎:调用IBuilder::buildEngineWithConfig()构建量化后的神经网络引擎。TensorRT会将网络中的权重和激活值转换为INT8,并计算相应的缩放因子。
推理:使用构建好的量化引擎执行推理。输入数据需要根据计算出的缩放因子进行量化,输出数据需要根据缩放因子进行反量化。
#include <NvInfer.h>
#include <NvInferRuntime.h>
// 自定义校准器
class MyInt8Calibrator : public nvinfer1::IInt8EntropyCalibrator2
{
public:
// 构造函数
MyInt8Calibrator(/*...*/) { /*...*/ }
// 从校准数据集中获取一个批次的数据
bool getBatch(void* bindings[], const char* names[], int nbBindings) override
{
// 加载一个批次的数据到bindings中
// ...
return true;
}
// 从文件中读取校准缓存
const void* readCalibrationCache(size_t& length) override { /*...*/ }
// 将校准缓存写入文件
void writeCalibrationCache(const void* ptr, size_t length) override { /*...*/ }
// ...
};
int main()
{
// 1. 创建TensorRT构建器和网络
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(/.../);
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(/.../);
// 2. 加载预训练模型并创建TensorRT网络
// 注意:这里仅展示了一个简化的示例。在实际应用中,还需要根据具体的模型格式加载预训练模型。
// ...
nvinfer1::ITensor* input = network->addInput(/*...*/);
nvinfer1::IConvolutionLayer* conv = network->addConvolution(/*...*/);
nvinfer1::IActivationLayer* relu = network->addActivation(/*...*/);
nvinfer1::IFullyConnectedLayer* fc = network->addFullyConnected(/*...*/);
network->markOutput(/*...*/);
// 3. 设置构建器选项以启用INT8量化
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
config->setMaxWorkspaceSize(/*...*/);
config->setFlag(nvinfer1::BuilderFlag::kINT8);
// 4. 创建校准器并将其传递给TensorRT构建器
MyInt8Calibrator calibrator(/*...*/);
config->setInt8Calibrator(&calibrator);
// 5. 构建量化引擎
nvinfer1::ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
// 6. 使用量化引擎执行推理
nvinfer1::IExecutionContext* context = engine->createExecutionContext();
// 注意:在实际应用中,还需要将输入数据量化并将输出数据反量化。
// ...
// 7. 释放资源
context->destroy();
engine->destroy();
config->destroy();
network->destroy();
builder->destroy();
return 0;
}
上述代码中最为核心的就是两句话:
1.config->setFlag(nvinfer1::BuilderFlag::kINT8);
2.config->setInt8Calibrator(&calibrator);
IInt8Calibrator主要负责输送Calibrator的数据:
进阶讨论:INT8量化算法的实际收益
在实际生产环境中,我们计FP32的运算时间为Tfp,INT8的运算时间为Tint8,量化和反量化的运算时间分别为Ta和Tb,则INT8量化算法带来的时间收益为:Tfp - Tint8 - Ta -Tb. 根据经验,权值越大,输入越小,加速比越大;输入越大,收益越小;甚至是负收益。
进阶讨论:如何使用TensorRT进行大规模上线
一种有效的方法是面向多种输入尺度的多Engine定制策略,具体如下:
- 面向Dynamic Shape输入:
在实际应用中,输入数据的形状可能是可变的。例如,图像分类和目标检测任务中的输入图像可能有不同的分辨率。为了处理可变形状的输入数据,TensorRT引入了Dynamic Shape输入的支持。Dynamic Shape允许用户为某些维度指定最小值、最大值和最优值,从而为不同形状的输入数据生成一个统一的引擎。
要实现Dynamic Shape输入,需要执行以下操作:
在创建TensorRT网络时,使用nvinfer1::INetworkDefinition::addInput()为输入张量指定最小值、最大值和最优值。
在创建nvinfer1::IBuilderConfig对象时,启用nvinfer1::BuilderFlag::kOPT_DYNAMIC_BATCH和/或nvinfer1::BuilderFlag::kOPT_DYNAMIC_SHAPE标志。
在执行推理时,使用nvinfer1::IExecutionContext::setBindingDimensions()为引擎指定当前的输入数据形状。
多Engine定制策略:
尽管Dynamic Shape输入可以处理可变形状的输入数据,但在某些情况下,为不同输入形状创建专门的引擎可能会带来更高的性能。多Engine定制策略允许为特定的输入形状创建专门优化的引擎,从而在推理时获得更高的性能。
- 多Engine定制策略的实现方法如下:
根据不同的输入形状,为每个输入形状创建一个单独的TensorRT引擎。在创建引擎时,使用nvinfer1::IBuilder::setMaxBatchSize()和nvinfer1::IBuilder::setOptimizationProfile()为引擎指定特定的输入形状。
在执行推理时,根据输入数据的实际形状选择合适的引擎。可以使用哈希表或其他数据结构来存储和查找不同输入形状对应的引擎。
总之,在大规模模型上线时,TensorRT提供了面向Dynamic Shape输入和多Engine定制策略等优化方法,以确保高效、灵活的推理。实际应用中,可以根据具体需求和性能要求选择合适的策略。
总结和建议
(1)对于深度神经网络的推理,TRT可以充分发挥GPU计算潜力,以及节省GPU存储单元空间。
(2)对于初学者,建议先从Sample入手,尝试替换掉已有模型,再深入利用网络定义API尝试搭建
网络。
(3)如果需要使用自定义组件,建议至少先了解CUDA基本架构以及常用属性。
(4)推荐使用FP16/INT8计算模式
• FP16只需定义很少变量,明显能提高速度,精度影响不大;
• Int8有更多的潜力,但是可能会导致精度下降。
(5)如果不是非常了解TRT,也可以尝试使用集成了TRT的框架,但是如果不支持的网络层太多,
会导致速度下降明显。
(6)在不同架构的GPU或者不同的软件版本的设备上,引擎不能通用,要重新生成一个。








![[项目实战] 博客系统实现](https://img-blog.csdnimg.cn/bd07206fa54f41fc8778981ed7a34584.png)