目录
- 网页结构分析
- 爬取思路
- 得到所有的文章
- 遍历每个文章得到其中的信息
- 实现代码
- 总结
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中

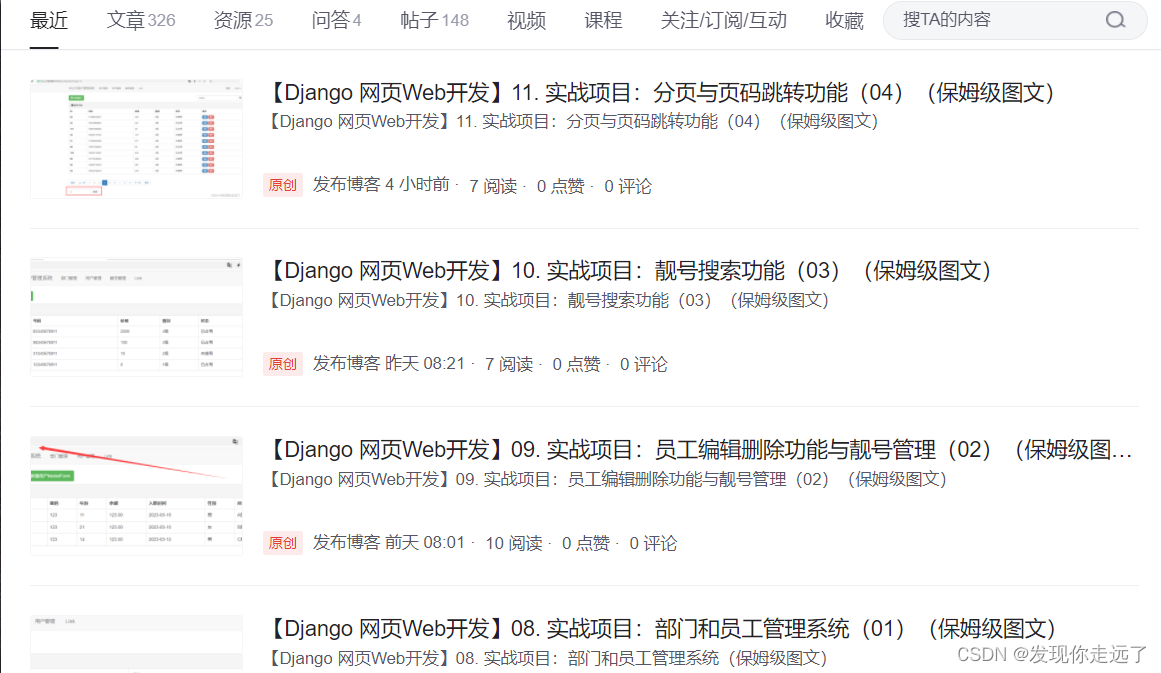
网页结构分析
我的csdn主页
https://blog.csdn.net/u011027547
我们先找一篇文章内容的div,具体操作为逐渐向更大范围的div查找,直到找到包含所有文章的结构体。
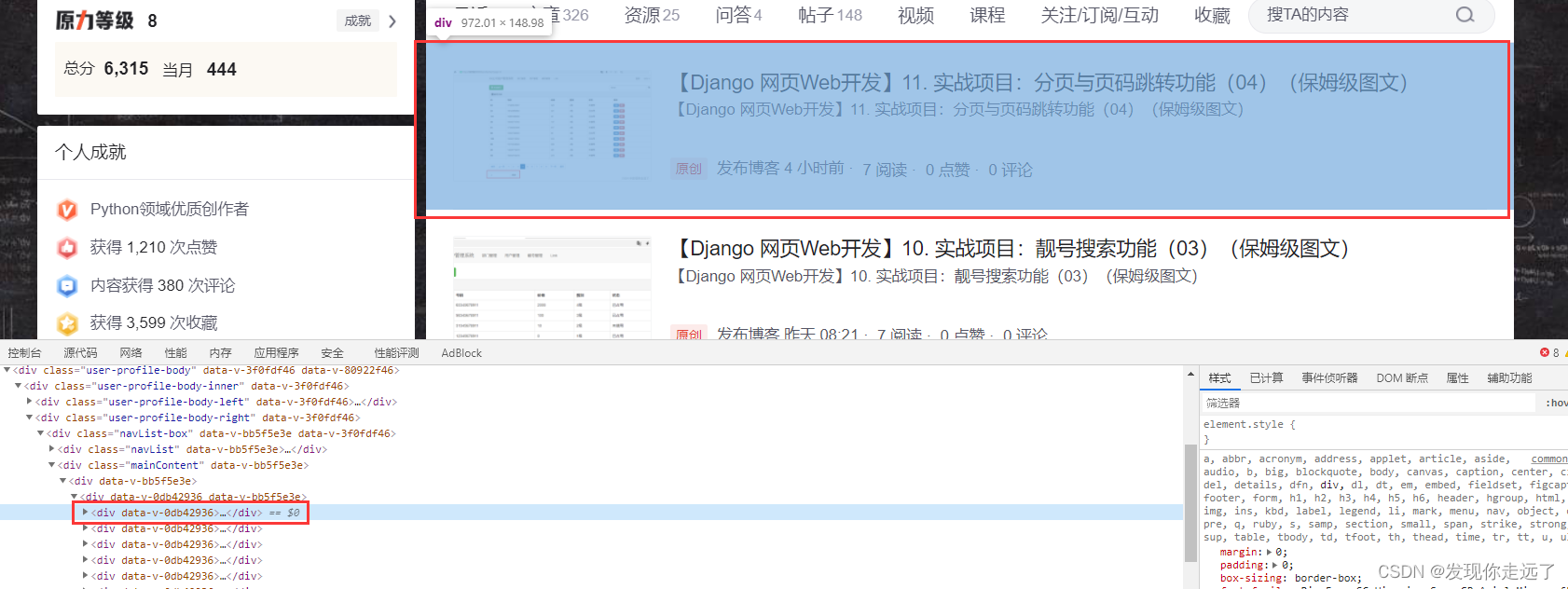
再往上一级就遇到了所有文章的列表结构了,所以我们可以确定上面的内容已经是每篇文章的div单位了
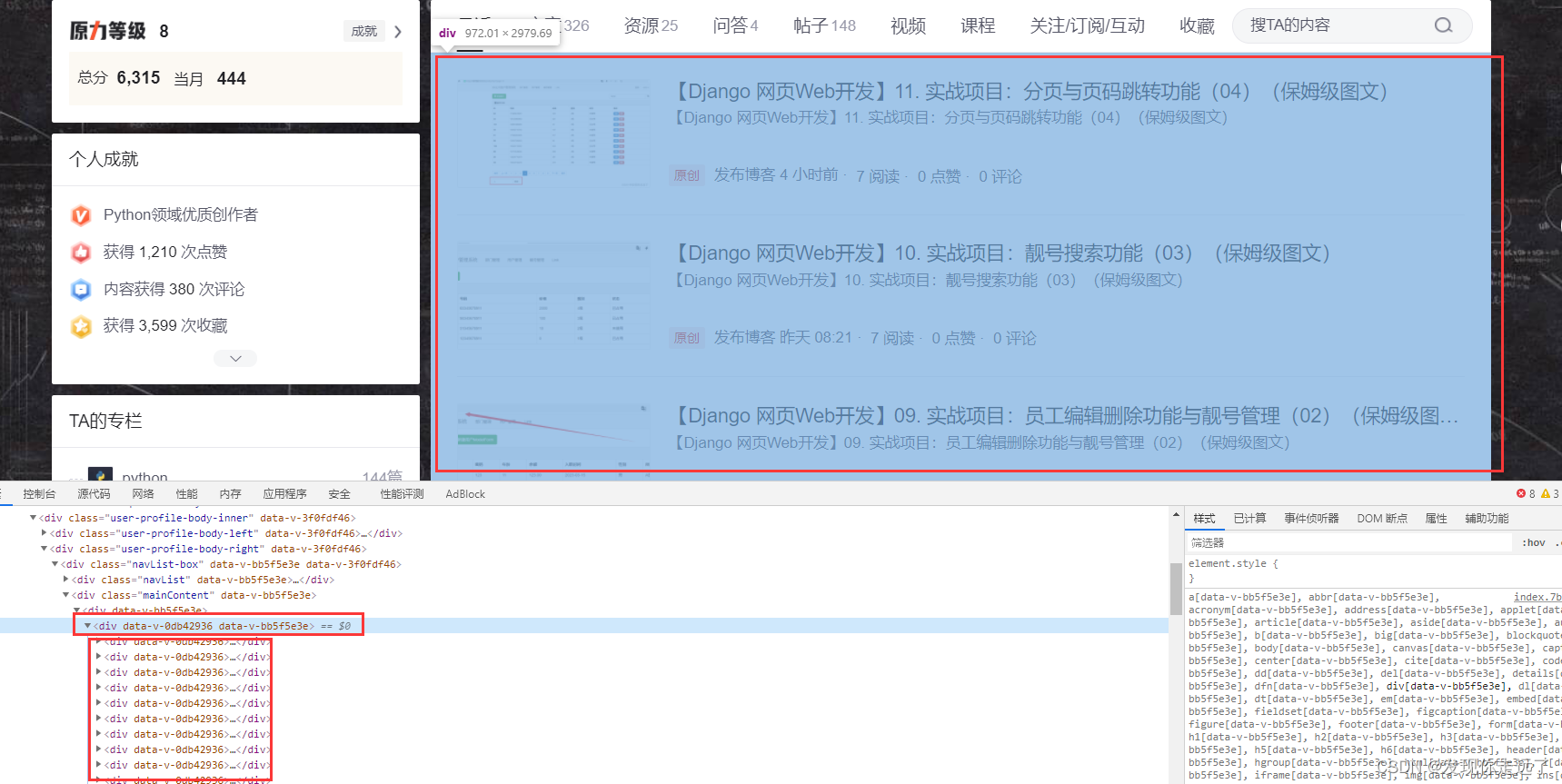
而且在这一级的div下有很多相同结构的div列表,也佐证了我们的结构判断。
爬取思路
xpath 与 full xpath路径在部分网页会出现full xpath无法返回内容的情况,所以为了兼容性建议使用xpath,用full xpath会返回一个空列表。
得到所有的文章
- 第1个文章的div
//*[@id=“userSkin”]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1] - 第2个文章的div
//*[@id=“userSkin”]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[2] - 第3个文章的div
//*[@id=“userSkin”]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[3] - 所以拿到每一个文章div
//*[@id=“userSkin”]/div[2]/div/div[2]/div[1]/div[2]/div/div/div
遍历每个文章得到其中的信息
- 文章与title的相对比较
//[@id=“userSkin”]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1] ./article/a/div[2]/div[2]/div/div[3]/span
//[@id=“userSkin”]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1] /article/a/div[2]/div[2]/div/div[3]/span
所以只需要相对路径./article/a/div[2]/div[2]/div/div[3]/span即可
实现代码
只做了当前展示页面的爬取
import requests
from lxml import etree
url = "https://blog.csdn.net/u011027547"
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;'}
resp = requests.get(url,headers=headers)
print(resp)
# print(resp.text)
# 解析
html = etree.HTML(resp.text)
# 第1个文章的div
# //*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1]
# 第2个文章的div
# //*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[2]
# 第3个文章的div
# //*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[3]
# 所以拿到每一个文章div
# //*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div
# 文章与title的相对比较
# //*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1] ./article/a/div[2]/div[2]/div/div[3]/span
# //*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1] /article/a/div[2]/div[2]/div/div[3]/span
divs = html.xpath('//*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div')# 拿到每一个文章的div
# print(divs)
for div in divs: # 每一个文章信息
# //*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1]/article/a/div[2]/div[1]/div[1]/h4
title = div.xpath("./article/a/div[2]/div[1]/div[1]/h4/text()")[0]
print("文章标题:"+title)
# //*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1]/article/a/div[2]/div[2]/div/div[3]/span
read_number = div.xpath("./article/a/div[2]/div[2]/div/div[3]/span/text()")[0]
print("阅读量:"+read_number)
# //*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1]/article/a/div[2]/div[2]/div/div[4]/span
zan = div.xpath("./article/a/div[2]/div[2]/div/div[4]/span/text()")[0]
print("点赞数:"+zan)
总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
『未完待续』
![[项目实战] 博客系统实现](https://img-blog.csdnimg.cn/bd07206fa54f41fc8778981ed7a34584.png)