参考链接:https://www.cnblogs.com/kingsleylam/p/6014441.html
https://blog.csdn.net/ly0724ok/article/details/117030234/
https://blog.csdn.net/jiayibingdong/article/details/124674922
导致Java线程安全问题最主要的原因:
(1)多线程同时访问共享数据。
(2)多线程操作共享数据的过程中使用的计算方法不具备原子性。
解决线程安全问题的方案:
(1)避免共享数据。
(2)确保使用共享数据的原子性。
避免数据共享:
JAVA虚拟机在内存管理过程中将内存划分为不同区域,其中类成员变量存储在堆内存,方法变量存储在栈内存。堆内存在不同线程之间共享数据,有线程安全问题,而栈内存是线程独占的内存,不存在线程安全线问题。在允许的情况下,不使用成员变量、而是用方法变量、临时变量的话,可以避免共享数据,从而确保数据的线程安全问题。
public class A
{
private int account = 0;
public void cal()
{
for(int i=0;i<100;i++)
{
acount++;
}
}
public int getAccount()
{
return account;
}
}
多线程并发的情况下,account 有线程安全问题,而变量i是线程安全的、没有线程安全问题。
JMM内存模型: 描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存和从内存中读取变量这样的底层细节。
在Java内存模型中:
(1)所有变量都存储在主内存中
(2)每个线程都有自己独立的工作内存,里面保存该线程使用到的变量副本。(主内存中该变量的一份拷贝)
(3)线程对共享变量的所有操作都必须在自己的工作内存中进行,不能直接从主内存中进行读写。
(4)线程之间无法访问其他线程工作内存中的变量,线程间变量值的传递需要通过主内存来完成。
共享变量实现可见性,必须经过如下两个步骤:
(1)线程中工作内存中的共享变量如果更新,需要将更新过后共享变量刷新到主内存中。
(2)主内存将最新的共享变量更新到其他工作内存中。
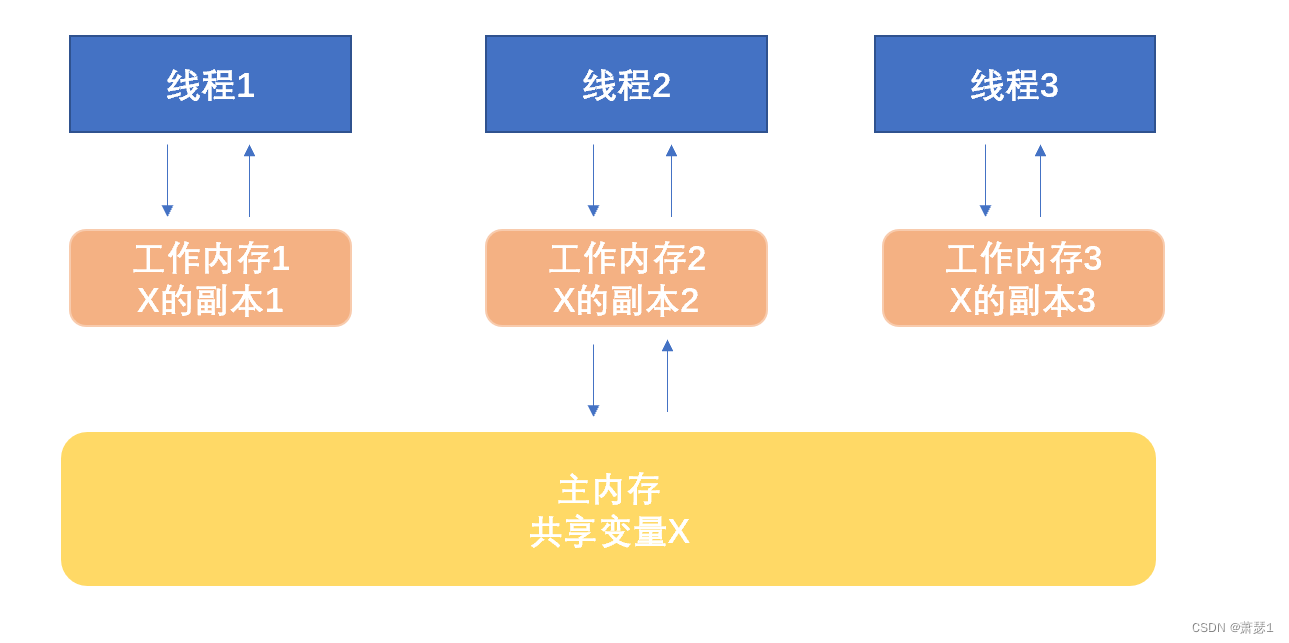
上图体现出线程只能与工作内存交互,不能直接访问主内存。当主内存中有一个共享变量X,则工作内存将X拷贝,线程操作工作内存中的X副本。
共享变量: 一个变量在多个线程的工作内存中都存在副本,那么这个变量就是这几个线程的共享变量。
原子性: 指一个操作不可被中断,要么全部执行成功,要么全部执行失败。同一时刻只能有一个线程对它进行操作。
可见性: 一个线程对共享变量值的修改能够及时被其他线程看到。
指令重排序:处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中的各个语句的执行先后顺序同代码中的顺序一致,但它会保证程序最终执行结果和代码顺序执行的结果是一致的。
内存屏障: 用来禁止指令重排序。内存屏障分为两种:Load Barrier 和 Store Barrier,即读屏障和写屏障。作用: (1)阻止屏障两侧的指令重排序,即屏障下面的代码不能和屏障上面的代码交换顺序。(2)在有内存屏障的地方,线程修改完共享变量以后会马上把该变量从本地内存写回到主内存,并且让其他线程本地内存中该变量副本失效。
对于Load Barrier来说,在指令前插入Load Barrier,可以让高速缓存中的数据失效,强制从新从主内存加载数据;
对于Store Barrier来说,在指令后插入Store Barrier,能让写入缓存中的最新数据更新写入主内存,其他线程程可见
synchrnized
具有 原子性、可见性
对象锁(monitor)机制
进入同步代码块之前首先执行monitorenter指令,退出同步代码块执行monitorexit指令。当线程获得monitor后才能继续往下执行,否则就只能等待。
任何一个对象都有一个自己的monitor,线程执行对象的同步方法或同步块时,执行方法的线程必须获取该对象的monitor才能进入同步块和同步方法,若获取不到,则进入阻塞状态,进入同步队列。线程释放锁的时候会将值刷新到主内存中,其他线程获取锁时会强制从主内存中获取最新的值。——happen-before。类似线程通信。
**锁的重入性:**在同一锁程中,线程不需要再次获取同一把锁。synchrnized先天具有重入性。每个对象拥有一个计数器,当线程获取该对象锁后,计数器就会加1,释放锁后就会将计数器减1。
CAS操作
悲观锁: 假设每一次执行临界区代码都会发生冲突,所以当前线程获取锁的过程会阻塞其他线程获取该锁。
乐观锁: 假设每一次执行临界区代码都不会发生冲突,所以不会阻塞其他线程操作。因此线程就不会出现阻塞停顿的状态。
CAS是用来鉴别乐观锁是否出现冲突,出现冲突就重试当前操作直到没有冲突为止。
CAS操作过程
CAS包含三个值,分别为:V内存地址存放的实际值、O预期的值、N更新的新值。当V和O相同时,表明该值没有被其他线程更改过,可以把新值N赋值给V。相反,V和O不相同,表明该值已经被其他线程改过了,则该旧值不是最新版本的值了,所以不能将新值N赋值给V,返回V即可。当多个线程使用CAS操作一个变量时,只有一个线程会成功,并成功更新,其余会失败。失败的线程会重新尝试,当然也可以选择挂起线程。
CAS的问题
**ABA问题:**因为CAS会检查旧值有没有变化,这里存在这样一个有意思的问题。比如一个旧值A变为了成B,然后再变成A,刚好在做CAS时检查发现旧值并没有变化依然为A,但是实际上的确发生了变化。解决方案可以沿袭数据库中常用的乐观锁方式,添加一个版本号可以解决。原来的变化路径A->B->A就变成了1A->2B->3C。
**自旋时间过长:**使用CAS时非阻塞同步,也就是说不会将线程挂起,会自旋(无非就是一个死循环)进行下一次尝试,如果这里自旋时间过长对性能是很大的消耗。
**只能保证一个共享变量的原子操作:**当对一个共享变量执行操作时CAS能保证其原子性,如果对多个共享变量进行操作,CAS就不能保证其原子性。有一个解决方案是利用对象整合多个共享变量,即一个类中的成员变量就是这几个共享变量。然后将这个对象做CAS操作就可以保证其原子性。atomic中提供了AtomicReference来保证引用对象之间的原子性。
voliate
轻量级同步机制。
voliate 是java中的一个关键字,用于修饰变量,被修饰的变量标记为线程共享,编译与运行时都会检查该变量,不会对其进行重排序。保证可见性和有序性,不保证原子性。
被voliate修饰的变量在编译成字节码时会多个lock前缀指令,该指令在执行过程中生成一个内存屏障,保证充排序后的指令不会越过内存屏障。即volatile之前的代码只会在volatile之前执行,volatile之后的代码只会在volatile之后执行。
满足以下一点,volatile 修饰的共享变量不加锁也能保证线程安全: 运算结果不依赖共享变量的当前值。(i++反例)。
Semaphore
继承关系
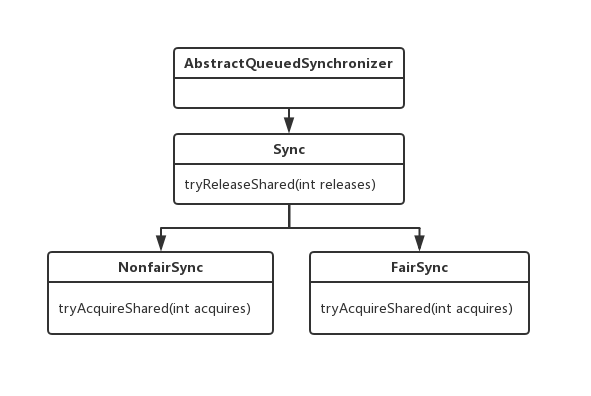
Semaphore用于管理信号量,在并发编程中可以控制访问同步代码的线程数量。
线程池
线程池是一种多线程处理形式,处理过程中可以将任务添加到队列中,然后再创建线程后自动启动这些任务。
熟知的线程池: JDBC、数据库连接池(DataSource)、String(字符串常量池)
线程池的作用
- 降低资源消耗,通过重复利用已创建的线程降低创建和销毁的损耗。
- 提高响应速度,当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
线程池的基本原理
一个池子里面有很多线程,当再次需要执行某个任务时,不需要再创建线程了,而是直接从线程池中取出一个现成的线程供使用,即使该线程完成了任务,也不销毁线程,而是继续呆在线程池里准备迎接下一个任务。
为什么从池子中取要比创建线程快?
创建线程是在操作系统内核中完成的,涉及从用户态向内核态切换的操作,这个操作需要一定的开销。应用程序创建线程的是需要通过系统调用来完成的,进入操作系统内核中执行,也就是说,线程本质上就是PCB,是内核中的数据结构。创建线程是在内核中完成的,需要经历用户态->内核态的转变,而从线程池中取线程,把线程放回线程池,这一套是纯用户态的逻辑。
线程池主要参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
| 参数 | 解释 |
|---|---|
| corePoolSize | 线程池中的核心线程数。即使这些线程处于空闲状态也不会被销毁。任务提交到线程池后,首先会检查当前线程数是否达到了corePoolSIze,如果没有达到的话,会创建一个新线程来处理这个任务。 |
| maximumPoolSize | 线程池允许的最大线程个数;当线程数达到corePoolSize后,如果有任务继续提交到线程池,会将任务缓存到工作队列中。如果队列也已满,则会创建一个新线程来进行处理。线程池不会无限制地去创建新线程,它会有一个最大线程数限制,这个数量由maximumPoolSize限制。 |
| keepAliveTime | 空闲线程存活时间。一个线程如果处于空闲状态,并且当前线程数大于corePoolSize ,那么在keepAliveTime 后,这个空闲线程会被销毁。 |
| unit | 空闲线程存活时间单位,keepAliveTime 的计量单位。 |
| workQueue | 工作队列。新任务被提交后,会先进入到此工作队列中,任务调度时再从队列中取出任务。jdk提供了四种工作队列:ArrayBlockingQueue、LinkedBlockingQuene、SynchronousQuene、PriorityBlockingQueue。 |
| threadFactory | 创建一个新线程时使用的工厂,可以用来设定线程名,是否为daemon线程等等。 |
| headler | 拒绝策略。当工作队列中的任务已经到达最大限制且线程池中的线程数也达到最大限制,这时有新任务再次提交会触发拒绝策略。jdk提供了4种拒绝策略:CallerRunsPolicy、AbortPolicy、DiscardPolicy、DiscardOldestPolicy。 |
**workQueue工作队列 **
- ArrayBlockingQueue 基于数组的有界阻塞队列,按FIFO排序。新任务进来后,会放到该队列的队尾,有界的数组可以防止资源耗尽问题。当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
- LinkedBlockingQuene 基于链表的无界阻塞队列(其实最大容量为Interger.MAX),按照FIFO排序。由于该队列的近似无界性,当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而基本不会去创建新线程直到maxPoolSize(很难达到Interger.MAX这个数),因此使用该工作队列时,参数maxPoolSize其实是不起作用的。
- SynchronousQuene 一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略。
- PriorityBlockingQueue 具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
handler 拒绝策略
- CallerRunsPolicy 该策略下,在调用者线程中直接执行被拒绝任务的run方法,除非线程池已经shutdown,则直接抛弃任务。
- AbortPolicy 该策略下,直接丢弃任务,并抛出RejectedExecutionException异常。
- DiscardPolicy 该策略下,直接丢弃任务,什么都不做。
- DiscardOldestPolicy 该策略下,抛弃进入队列最早的那个任务,然后尝试把这次拒绝的任务放入队列。
线程池如何确定线程数量
在拥有N个处理器的系统上,如何确定线程数量。需要确定任务是CPU密集型应用还是IO密集型应用,还是混合型应用。如果是CPU密集型应用,则线程池大小设置为N+1。如果是IO密集型应用,则线程池大小设置为2N+1。
实际开发处理方案是需要实验验证的。针对自己的程序进行性能测试,对线程池设置不同的数目:0.5N、N、1.5N、2N… 然后分别记录每种情况下程序的一些核心性能指标和系统负载情况,最后选择一个合适的配置。



![[论文分享] VOS: Learning What You Don‘t Know by Virtual Outlier Synthesis](https://img-blog.csdnimg.cn/916709f806c447a0b037abc0063a654e.png)