1.提取出a和b两个数组中的公共项,可以使用numpy库中的哪个函数(A)。
A.np.intersect1d(a,b)
B.np.setdiff1d(a,b)
C.np.where(a == b)
D.np.lexsort((a,b))
解析:
A选项,np.intersect1d用来获取数组a和数组b之间的公共项;
B选项,np.setdiff1d(a,b)用来从a数组中删除存在于b数组中的项;
C选项,np.where(a == b)方法用来获取a数组和b数组元素相匹配的位置;
D选项,是一种排序算法,按键序列对数组进行排序,它返回一个已排序的索引数组;
因此正确答案选择A。
2.python中用Matplotlib画折线图,在下列选项中表示plot线条类型、线条颜色和点的形状是蓝色星形点划线的是哪个(D)。
A.’b×:’
B.’co--’
C.’ks-’
D.’b*-.’
解析:
在ABCD四个字符串中,第一个字节表示颜色,第二个字节表示点的形状,第三个字节表示线条形状。颜色的表示'b':蓝色、'c':青色、'k':黑色;点的形状表示’×’:x号标记、’o’:圆形、’s’:正方形、’*’:星形;线条的形状表示’:’:点线、’--’:虚线、’-’:实线、’-.’:点划线;因此该题选择D选项。
3.如何统计DataFrame数据df的某一列中每种字符串出现的次数(B)。
A.df[].unique()
B.df[].value_counts()
C.df[].nunique()
D.df[].count()
解析:
A. unique():返回NumPy数组ndarray中唯一元素值的列表;
B.value_counts():返回唯一元素的值及其在出现的次数;
C.nunique()以整数int形式返回唯一元素的数量;
D.count()方法用于统计非空字符串数量;
因此正确答案选择B。
4.下列语句能创建下图这个DataFrame表格的是(B)。
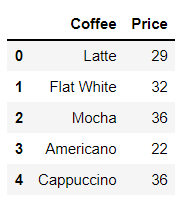
A.
import pandas as pd
import numpy as np
data =
{'Coffee': 'Latte', 'Flat White', 'Mocha', 'Americano', 'Cappuccino'},
{'Price': 29, 32, 36, 22, 36}
df = pd.DataFrame(data)B.
import pandas as pd
import numpy as np
data = {
'Coffee': ['Latte', 'Flat White', 'Mocha', 'Americano', 'Cappuccino'],
'Price': [29, 32, 36, 22, 36]}
df = pd.DataFrame(data)C.
import pandas as pd
import numpy as np
data = [['Latte', 29], ['Flat White', 32], ['Mocha', 36], ['Americano', 22], [ 'Cappuccino', 36]]
df = pd.DataFrame(data)D.
import pandas as pd
import numpy as np
data = {{'Coffee': 'Latte', 'Price': 29}, {'Coffee': 'Flat White', 'Price': 32}, {'Coffee': 'Mocha', 'Price': 36}, {'Coffee': 'Americano', 'Price': 22}, {'Coffee': 'Cappuccino', 'Price': 36}}
df = pd.DataFrame(data)解析:
pandas中创建DataFrame有多种方法,常用的有以下三种:
第一种:用列表来创建。具体语法就是
data = [[第一行的第一列值,第一行的第二列值],[第二行的第一列值,第二行的第二列值]]
df = pd.DataFrame(data, columns=['列名','列名'])
其中中括号里面的子中括号表示每一行数据;然后放入DataFrame函数中。不过记得利用 columns参数来设置DataFrame的列名,不然会默认使用从0开始的数字作为列名。
因此,可以排除C选项,它没设置列名。
第二种:用字典dict来创建。
data = [{key1:value1}, {key2:value2}, {key3:value3}]
df = pd.DataFrame(data)
这里的key就是DataFrame的列名,value就是每一行对应的列值。
因此也可以排除D选项,因为最外围是中括号[],不是大括号{}。
第三种:用ndarrays创建。
data = {'columns_1':[values1], 'columns_2':[values2]}
df = pd.DataFrame(data)
这里columns_1就是每一列的列名;values1就是每一列对应的数值或数据。
因此可以排除A选项,它列名后对应的列值少了中括号[],只有B才是正确的。
5.以下哪个选项是处理缺失值的方法(D)。
①删除遗漏信息的样本 ②对缺失部分进行插补 ③对缺失值的样本不处理
A.①②
B.①③
C.②③
D.①②③
解析:
对于缺失值的处理方式包括:删除样本、插补和保留不处理三种方式。