1. 关于内存可见性的一段代码
import java.util.Scanner;
public class ThreadDemo {
public static int count = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
while (count == 0) {
}
System.out.println("t1 线程结束!");
});
Thread t2 = new Thread(() -> {
Scanner scanner = new Scanner(System.in);
count = scanner.nextInt();
System.out.println("t2 线程结束! count = " + count);
});
t1.start();
t2.start();
}
}此时这段代码相信你们都不难看懂,t1 线程有一个空循环,只要 count 的值等于 0,这个空循环就会一直循环下去,t2 线程则是让我们从键盘输入一个数,用来改变 count 的值,并打印一下修改后 count 的值,如果 count 的值改变了,不等于 0 了,是不是也就意味着 t1 会跳出循环,接着打印 "t1线程结束"。
所以上述代码,我们预期由 t2 线程从键盘读一个数,改变 count 的值,结束 t1 线程的循环!
接下来我们就运行这个代码:

此时发现,count 的值确实被改了,为什么 t1 线程仍然没有结束呢???此时程序也就出现了 BUG!
那么上述这种情况,就是内存可见性问题!一个线程读,一个线程写(线程不安全)
为什么会发生上述的情况呢?这里就需要分析 t1 线程里 while 循环的条件部分了,count == 0,这个操作从汇编的角度上,需要分成两步:
1. load,把内存中的值读到寄存器中(也可能是读到cache)
2. cmp,把寄存器中的值和 0 进行比较,决定下一步往哪走
上述代码的循环执行速度是非常快的!在 t2 线程对 count 进行修改前,这个循环可能已经执行了上千万次了!
每次 load 的操作是比 cmp 慢很多的,因为 load 大概率要从内存中读数据(此处忽略 cache),而 cmp 不需要经过内存,直接用 CPU 进行比较。
由上述两个点:load 速度太慢,t2 改 count 值之前,循环每次 load 的 count 都是0,可能读了上千万次 count 的值都是0,此时 JVM/编译器 就做了一个大胆的决定,不在重复从内存读取 count 的值了!因为发现读了几百万次都没人修改,那我还从内存读这个值干嘛!
所以以至于后续 t2 线程修改了内存中 count 变量的值,但是 t1 线程仍然没有察觉到!
上述这种情况,也是编译器优化的一种!
内存可见性:
一个线程针对一个变量进行读操作,另一个线程针对这个变量进行修改,此时读的线程,不一定能感知到这个变量被改了
2. volatile 关键字
这个关键字从字面意思上理解是 "易变的,不稳定的",如果给变量加上这个关键字,仿佛在告诉 JVM/编译器,这个变量很不稳定,极有可能发生变化,从而不让编译器优化!那么事实是不是这样呢?
于是我们对 count 变量加上 volatile 关键字:
import java.util.Scanner;
public class ThreadDemo {
public static volatile int count = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
while (count == 0) {
}
System.out.println("t1 线程结束!");
});
Thread t2 = new Thread(() -> {
Scanner scanner = new Scanner(System.in);
count = scanner.nextInt();
System.out.println("t2 线程结束! count = " + count);
});
t1.start();
t2.start();
}
}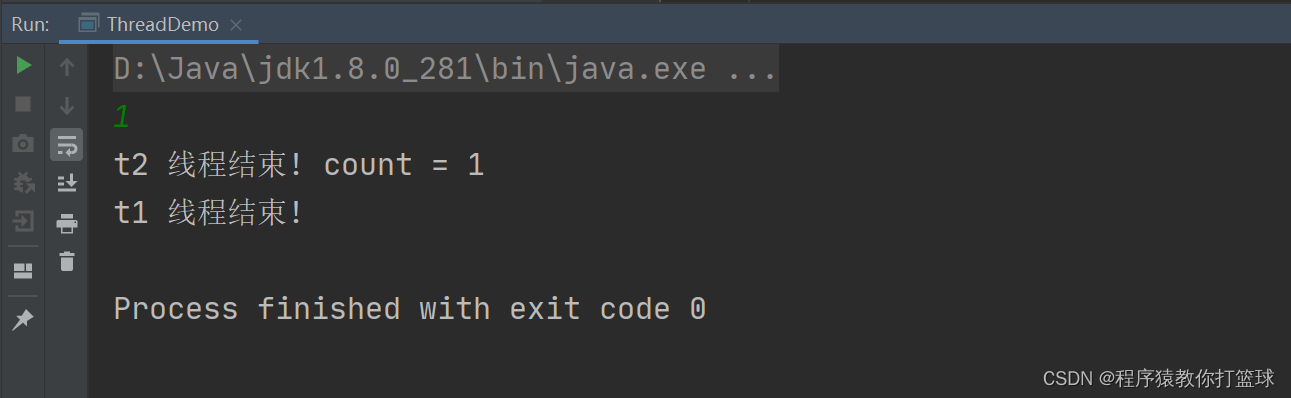
通过程序执行结果,确实发现当给 count 加上 volatile 修饰之后,t1 线程能感知到 count 被 t2 给修改了,那么 volatile 这个关键字的作用就是,告诉 JVM/编译器 这个变量是 "易变" 的,每次都要重新读取这个变量的内容,因为他指不定啥时候就发生变化了,你可不能莽撞的进行优化了啊!
volatile 这个关键字是保证内存可见的!而且还能禁止编译器指令重排序(单例模式讲解)
3. JVM 官方内存模型
大概是说,从 JVM 的角度表述内存可见性的问题:
Java 的主程序中,有一个主内存,每个线程有自己的工作内存(t1 和 t2 有不同的工作内存),当 t1 线程进行读的时候,只是读取了工作内存的值,t2 进行修改的时候,先是修改了工作内存的值,再把工作内存修改后的值,同步到主内存中,但是由于编译器的优化,导致 t1 没有重新从主内存中同步数据到 t1 的工作内存中,所以读到的就是 "修改前" 的结果。
什么是主内存,工作内存?
这里可以简单理解成,主内存 main memory 理解为平时所说的内存,工作内存 work memory 工作存储区 理解成 CPU 的寄存器 + cache 缓存。
由于 CPU 硬件结构复杂,Java 官方为了不区分硬件的细节和差异,就用工作内存代替了 CPU寄存器 + CPU 的 cache。
简单来说,主内存就是内存,工作内存就是 CPU寄存器 + cache 缓存
所以最终就是 t1 没有同步内存中的值到寄存器/cache,从而导致 while 条件判断 count 的值永远都是0。
4. volatile 不保证原子性
这里用一段很简单的代码就能验证出来了:
public class ThreadDemo {
public static volatile int count = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
count++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5_0000; i++) {
count++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("count = " + count);
}
}
// 第一次执行结果:count = 77038
// 第二次执行结果:count = 74220
// 第三次执行结果:count = 77001如果你是使用 IDEA 编译器,当你把鼠标放在 count++ 这条代码上,就能发现有一个警告:
Non-atomic operation on volatile field 'count'
易失性字段“count”上的非原子操作
通过这个和上述代码的执行结果,很容易得出 volatile 关键字不保证原子性。
小结:
synchronized 和 volatile 都是保证线程安全的,但是他俩的功能是不一样的,synchronized 是能够保证原子性,而 volatile 是保证内存可见性,至于网上也有的人说 synchronized 也能保证原子性,也有的人说不能保证原子性,这个有待考证,这里我们就不杠,如果后面写代码的时候,既要考虑原子性,又要考虑内存可见性,直接把 synchronized 和 volatile 都加上即可。
下期预告:【多线程】wait 和 notify


![【LeetCode】每日一题:移除链表元素 [C语言实现]](https://img-blog.csdnimg.cn/7e419c98587d48cd894219e9be4c3971.png)