了解更多关注中南林业科技大学软件协会官网:https://www.csuftsap.cn/
来自软件协会编辑,注册会员即可获取全部开源.md资源,请勿转载,归软件协会所有。
任何问题联系软件协会。
文章目录
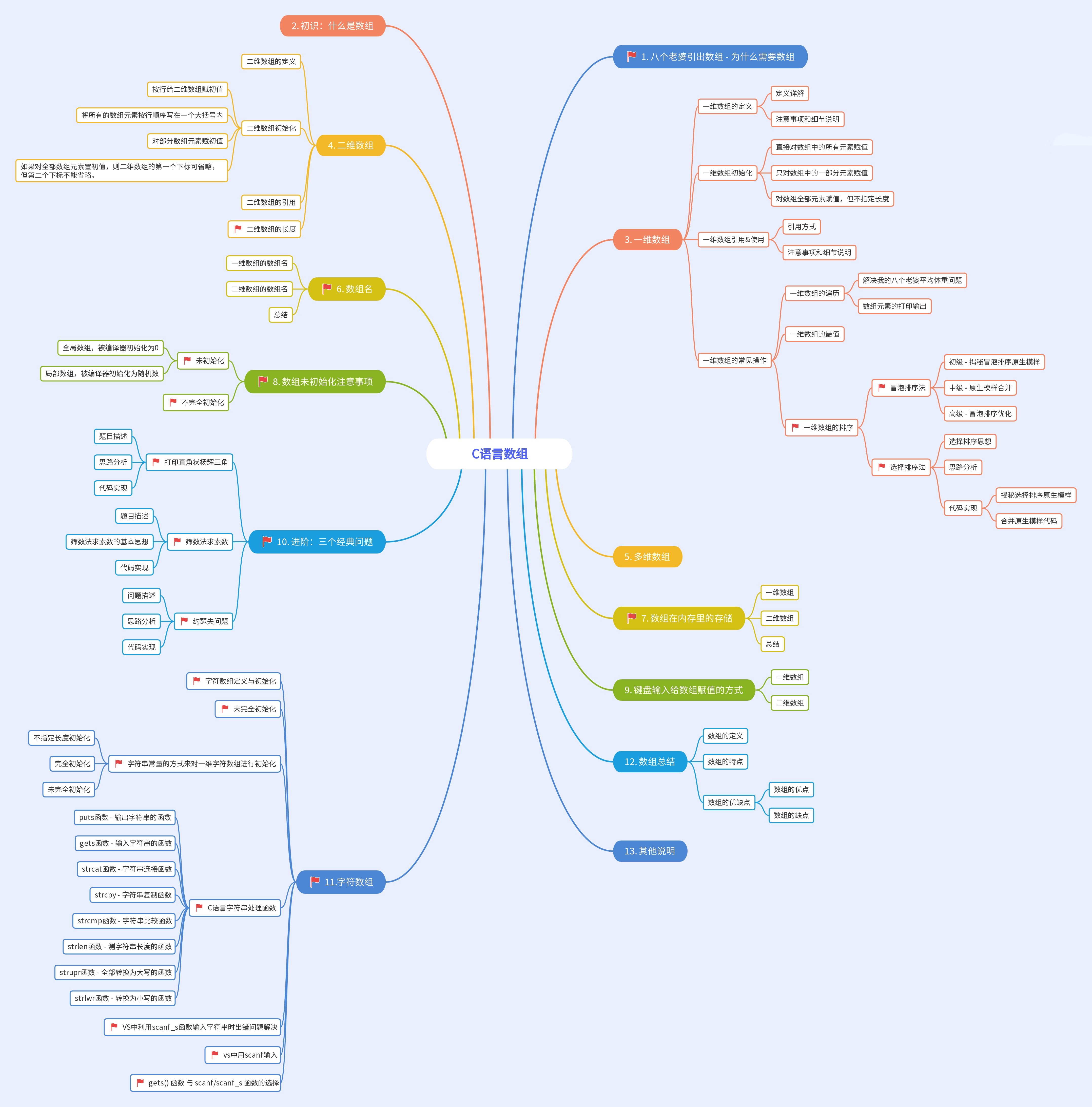
- :star: 数组
- 1.八个老婆引出数组 - 为什么需要数组
- 2.初识:什么是数组
- 3.一维数组
- 3.1 一维数组的定义
- 3.1.1 定义详解
- 3.1.2 注意事项和细节说明
- 3.2 一维数组初始化
- 3.2.1 直接对数组中的所有元素赋值
- 3.2.2 只对数组中的一部分元素赋值
- 3.2.3 对数组全部元素赋值,但不指定长度
- 3.3 一维数组引用&使用
- 3.3.1 引用方式
- 3.3.2 注意事项和细节说明
- 3.4 一维数组的常见操作
- 3.4.1 一维数组的遍历
- 3.4.1.1 解决我的八个老婆平均体重问题
- 3.4.1.2 数组元素的打印输出
- 3.4.2 一维数组的最值
- 3.4.3 一维数组的排序
- 3.4.3.1 冒泡排序法
- 3.4.3.1.1 初级 - 揭秘冒泡排序原生模样
- 3.4.3.1.2 中级 - 原生模样合并
- 3.4.3.1.3 高级 - 冒泡排序优化
- 3.4.3.2 选择排序法
- 3.4.3.2.1 基本介绍
- 3.4.3.2.2 选择排序思想
- 3.4.3.2.3 思路分析
- 3.4.3.2.4 代码实现
- 3.4.3.2.4.1 揭秘选择排序原生模样
- 3.4.3.2.4.2 合并原生模样代码
- 4.二维数组
- 4.1 二维数组的定义
- 4.2 二维数组初始化
- 4.2.1 按行给二维数组赋初值
- 4.2.2 将所有的数组元素按行顺序写在一个大括号内
- 4.2.3 对部分数组元素赋初值
- 4.2.4 如果对全部数组元素置初值,则二维数组的第一个下标可省略,但第二个下标不能省略
- 4.3 二维数组的引用
- 4.4 二维数组的长度
- 5.多维数组
- 6.数组名
- 6.1 一维数组的数组名
- 6.2 二维数组的数组名
- 6.3 总结
- 7.数组在内存里的存储
- 7.1 一维数组
- 7.2 二维数组
- 7.3 总结
- 8.数组未初始化注意事项
- 8.1 未初始化
- 8.1.1 全局数组,被编译器初始化为0
- 8.1.2 局部数组,被编译器初始化为随机数
- 8.2 不完全初始化
- 9.键盘输入给数组赋值的方式
- 9.1 一维数组
- 9.2 二维数组
- 10.进阶:三个经典问题
- 10.1 打印直角状杨辉三角
- 10.1.1 题目描述
- 10.1.2 思路分析
- 10.1.3 代码实现
- 10.2 筛数法求素数
- 10.2.1 题目描述
- 10.2.2 筛数法求素数的基本思想
- 10.2.3 代码实现
- 10.3 约瑟夫问题
- 10.3.1 问题描述
- 10.3.2 思路分析
- 10.3.3 代码实现
- 11.字符数组
- 11.1 字符数组定义与初始化
- 11.2 未完全初始化
- 11.3 字符串常量的方式来对一维字符数组进行初始化
- 11.3.1 不指定长度初始化
- 11.3.2 完全初始化
- 11.3.3 未完全初始化
- 11.4 C语言字符串处理函数
- 11.4.1 puts函数 - 输出字符串的函数
- 11.4.2 gets函数 - 输入字符串的函数
- 11.4.3 strcat函数 - 字符串连接函数
- 11.4.4 strcpy - 字符串复制函数
- 11.4.5 strcmp函数 - 字符串比较函数
- 11.4.6 strlen函数 - 测字符串长度的函数
- 11.4.7 strupr函数 - 全部转换为大写的函数
- 11.4.8 strlwr函数 - 转换为小写的函数
- 11.5 VS中利用scanf_s函数输入字符串时出错问题解决
- 11.6 vs中用scanf输入
- 11.7 gets() 函数 与 scanf/scanf_s 函数的选择
- 12.数组总结
- 12.1 数组的定义
- 12.2 数组的特点
- 12.3 数组的优缺点
- 12.3.1 数组的优点
- 12.3.2 数组的缺点
- 13.其他说明
⭐️ 数组
📍 来自:中南林业科技大学软件协会学术部:谢添
⏲ 时间:2022 - 11 - 08 至 2022 - 11 - 10
🏠 官网:https://www.csuftsap.cn/
✏️ 本章所有提供代码均已测试,读万卷书不如行万里路,一定要把代码都自己敲一遍并测试
💬 努力战胜自己,比赢了任何人都可贵。每个人的成长,都需要时间沉淀。不要因为短时间看不到回报,就拒绝付出。最艰难的成功,不是超越别人,而是战胜自己。

【在本篇文章中,你会学习到的内容如下】
1.八个老婆引出数组 - 为什么需要数组
我们都知道,爱岳绮罗的张显宗有八个老婆,她们的体重分别是50kg,49kg,40kg,55kg,60kg,48kg,49kg,46kg,那请问她们的平均体重是多少呢?请用程序来计算。
按照我们之前学过的知识,应当如此来:
#include<stdio.h>
int main()
{
double a1 = 50;
double a2 = 49;
double a3 = 40;
double a4 = 55;
double a5 = 60;
double a6 = 48;
double a7 = 49;
double a8 = 46;
double avg = (a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8) / 8;
printf("八个老婆的平均体重是:%.3lf",avg);
return 0;
}
❗️ 其实你会发现有这样几个问题:
- 起名很麻烦且我们不建议在给变量名取名是带有数字。
- 定义变量是个繁琐的过程,在这里我们需要定义八个毫无技术含量的变量,浪费时间。
- 在做求平均时要从a1加到a8,也是一个很繁琐的过程。
其实现在还好,张显宗只有八个老婆,我们还只需要定义八个变量,从a1加到a8。如果我们现在需要计算班级所有学生的平均体重,那我们得定义几十个变量,求总体重的过程也会很繁琐,那怎么办呢?
这就引出了我们现在要讲的知识 —— 用数组来解决该类问题。
2.初识:什么是数组
除了基本数据类型,C语言还提供了构造类型的数据,构造类型的数据包括数组类型、结构体类型和共用体类型。
在程序中,经常需要对一批数据进行操作,例如,统计某个公司100个员工的平均工资。如果使用变量来存放这些数据,就需要定义100个变量,显然这样做很麻烦,而且很容易出错。这时,可以使用x[0]、x[1]、x[2]……x[99]表示这100个变量,并通过方括号中的数字来对这100个变量进行区分。
在程序设计中,使用x[0]、x[1]、x[2]……x[n]表示的一组具有相同数据类型的变量集合称为数组x,数组中的每一项称为数组的元素,每个元素都有对应的下标(n),用于表示元素在数组中的位置序号,该下标是从0开始的。
为了大家更好地理解数组,我们通过一张图来描述数组x[10]的元素分配情况:

从图中可以看出,数组x包含10个元素,并且这些元素是按照下标的顺序进行排列的。由于数组元素的下标是从0开始的,因此,数组x的最后一个元素为x[9]。
需要注意的是,根据数据的复杂度,数组下标的个数是不确定的。通常情况下,数组元素下标的个数也称为维数,根据维数的不同,可将数组分为一维数组、二维数组、三维数组、四维数组等。通常情况下,我们将二维及以上的数组称为多维数组。
📍 一句话说明什么是数组:
数组可以存放多个同一类型的数据。数组也是一种数据类型,是构造类型。即:数(数据)组(一组)就是一组数据。
💬 也可以这样理解:数组相当于一个班级,数组中的每一个元素相当于班级中的每一个学生。
3.一维数组
3.1 一维数组的定义
3.1.1 定义详解
一维数组指的是只有一个下标的数组,它用来表示一组具有相同类型的数据。
📍 定义:
类型说明符 数组名[常量表达式];
- 类型说明符:表示数组中所有元素的类型
- 常量表达式:指的是数组的长度,也就是数组中最多可以存放元素的个数。方括号中必须是常量,不能是变量。
📝 示例:
/*
定义了一个数组:
- int 是数组的类型,即数组中每一个元素的类型都是int类型。
- arr 是数组的名称,方括号中的5是数组的长度。
- []中的数字 10 就是数组的 长度,表示该arr数组中最多可以存放10个int类型的数据放在10个位置上
*/
int arr[10];
char brr1[10];
float brr2[1];
double brr3[20];
3.1.2 注意事项和细节说明
-
数组的下标是用
方括号括起来的,而不是圆括号。 -
数组名的命名同变量名的命名规则相同。
-
数组定义中,数组从长度必须是常量表达式,常量表达式的值可以是符号常量,例如下面的定义是合法的:
//预编译命令,定义一个常量LENGTH,常量值为4 #define LENGTH 4 //定义一个数组 a ,数组长度为常量LENGTH,即长度为4 int a[LENGTH];❗️ 反例:
/* 错误定义 */ int count = 10; int arr1[count];//数组不可以正常创建
3.2 一维数组初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理的初始值(初始化)
初始化是与数组定义是放在一条语句的。
完成数组的定义后,只是对数组中的元素开辟了一块内存空间,数组中还未存放任何数据。这时,如果想使用数组操作数据,还需要对数组进行初始化。数组初始化的常见的方式有三种,具体如下:
3.2.1 直接对数组中的所有元素赋值
int arr[5]={1,2,3,4,5};
上述代码定义了一个长度为5的数组arr,并且数组中元素的值依次为1、2、3、4、5。
📝 更多示例:
char arr1[3] = {'a',98,'c'};
3.2.2 只对数组中的一部分元素赋值
int brr[5]={1,2,3};
在上述代码中,定义了一个int类型的数组,但在初始化时,只对数组中的前三个元素进行了赋值,其它元素的值会被默认设置为0。
📝 更多示例:
char brr1[4] = {'a','b','c'}; //不完全初始化,剩余元素初始化为0
char brr2[10] = "abcdef"; //不完全初始化,剩余元素初始化为0,注意第一个剩余元素是'\0',表现形式为0。
3.2.3 对数组全部元素赋值,但不指定长度
int crr[]={1,2,3,4};
在上述代码中,等式右侧括号内有4个元素,在等式左侧的 [] 内并未指定元素个数,但编译器是很聪明的,系统会根据给定初始化元素的个数定义数组的长度,因此数组crr的长度为4。
📝 更多示例:
char crr1[] = "abcdef";
📝 扩展(后面再讲):
strlen和sizeof没有任何关系- strlen:求字符串长度,只能针对字符串求长度,属于【库函数】,使用需要引头文件。
- sizeof:计算变量、数组、类型的大小,单位是字节,属于【操作符】,可直接使用。
char crr1[] = "abcdef";
/*
sizeof 计算 arr所占空间的大小
crr1一共有7个元素:abcdef这六个元素加上一个字符串结束符 '\0'
所以占用空间: sizeof(char) * 7 = 1 * 7 = 7
*/
printf("%d", sizeof(arr1);
/*
strlen求字符串的有效长度(长度就是个数,不是占用空间大小),即'\0'之前的字符个数 —— 6
*/
printf("%d", strlen(arr1));
3.3 一维数组引用&使用
3.3.1 引用方式
下标引用操作符:
[]。它其实就是数组访问的操作符。
在程序中,经常需要访问数组中的一些元素,这时可以通过数组名 + 下标引用操作符 + 下标(下标也叫做索引) 来引用数组中的元素。一维数组元素的引用方式如下所示:
数组名[下标];
在上述方式中,下标指的是数组元素的位置,数组元素的下标是从0开始的。例如,引用数组x的第三个元素的方式x[2]。
3.3.2 注意事项和细节说明
-
数组是使用
下标/索引来访问的,下标是从0开始。 -
对于一个数组而言,数组中的每一个元素占用的空间大小都是相同的。
-
数组的大小可以通过计算得到。
int arr[10]; /* 对于一个数组而言,数组中的每一个元素占用的空间大小都是相同的 sizeof(arr):求得 arr 的内存空间,即十个元素占用的总空间大小 sizeof(arr[0]):求得 arr[0] 的内存空间,即一个元素占用的空间大小 */ int sz = sizeof(arr)/sizeof(arr[0]); -
数组的下标都有一个范围,即 0~[数组长度-1],假设数组的长度为6,其下标范围为0~5。当访问数组中的元素时,下标不能超出这个范围,否则程序会报错。
3.4 一维数组的常见操作
数组在编写程序时应用非常广泛,如经常需要对数组进行遍历、获取最值、排序等操作,灵活地使用数组对实际开发很重要。接下来针对一维数组的常见操作进行详细地讲解。
3.4.1 一维数组的遍历
操作数组时,经常需要依次访问数组中的每个元素,这种操作称作数组的遍历。
3.4.1.1 解决我的八个老婆平均体重问题
接下来使用for循环依次遍历数组中的元素来解决计算我八个老婆平均体重的问题。
#include<stdio.h>
int main()
{
/*
数组定义:
- 数组名为 arr
- 数组中元素类型都是double
- 数组长度为8
- 下标/索引 范围是 [0,7]
数组初始化:
- 由于在定义时规定了数组长度为8
- 即可以容纳的最多元素个数为8
- 因此初始化时写的元素的个数必须小于8(全部初始化)或 等于8(部分初始化)
注意:
- 可以看到我们写的元素都是整型
- 但定义数组时规定类型是double
- 这是没有问题的
- 这里就存在了一个 自动类型转换
- 将每一个int类型的元素转为 double 类型
*/
double arr[8] = { 50,49,40,55,60,48,49,46 };
//求全部体重
double sum = 0;
for (int i = 0; i < 8; i++)
{
//这里使用了复合赋值运算法,依次加上数组的每一元素的值
sum += arr[i];
}
//求平均体重
printf("我的八个老婆的平均体重为:%.3lf", sum / 8);
return 0;
}
这样的话,如果是求一个班级的平均体重,是不是也就只用一个 for 循环就能搞定累加的问题了呢?✌️我真棒!
3.4.1.2 数组元素的打印输出
一维数组的打印输出方式和普通元素打印输出的方式是一样的。
#include<stdio.h>
int main()
{
int x[5] = { 1, 2, 3, 4, 5 };
int i = 0;
for (i = 0; i < 5; i++)
{
printf("x[%d]:%d\n", i, x[i]);
}
return 0;
}
3.4.2 一维数组的最值
在操作数组时,经常需要获取数组中元素的最值。接下来通过一个案例来演示如何获得数组中的最大值。
#include <stdio.h>
int main()
{
//定义一个数组并初始化
int x[5] = { 1,2,3,4,5 };
//先假设最大值为数组的第一个元素
int nMax = x[0];
//再拿数组的每一个元素去与这个最大值进行比较
for (int i = 1; i < 5; i++)
{
//如果该元素值大于我们当前的最大值nMax
if (x[i] > nMax)
{
//就将最大值nMax设置为这个元素的值
nMax = x[i];
}
}
//这样就能得到最大值了
printf("max:%d\n", nMax);
return 0;
}
3.4.3 一维数组的排序
在操作数组时,经常需要对数组中的元素进行排序。
3.4.3.1 冒泡排序法
冒泡排序(Bubble Sorting)的基本思想是:通过对待排序序列从前向后(从下标较小的元素开始),依次比较相邻元素的值,若发现逆序则交换,使值较大的元素逐渐从前移向后部,就像水底下的气泡一样逐渐向上冒。
3.4.3.1.1 初级 - 揭秘冒泡排序原生模样
在冒泡排序的过程中,不断地比较数组中相邻的两个元素,较小者向上浮,较大者往下沉,整个过程和水中气泡上升的原理相似,接下来,分步骤讲解冒泡排序的整个过程,具体如下:
- 第一步,从第一个元素开始,将相邻的两个元素依次进行比较,直到最后两个元素完成比较。如果前一个元素比后一个元素大,则交换它们的位置。整个过程完成后,数组中最后一个元素自然就是最大值,这样也就完成了第一轮的比较。
- 第二步,除了最后一个元素,将剩余的元素继续进行两两比较,过程与第一步相似,这样就可以将数组中第二大的数放在倒数第二个位置。
- 第三步,依次类推,持续对越来越少的元素重复上面的步骤,直到没有任何一对元素需要比较为止。
#include <stdio.h>
int main()
{
/*
要求:将arr数组的元素排列顺序变为由小到大排序
*/
//定义一个数组并初始化
int arr[5] = { 8,9,6,7,5 };
int temp;
/*
第一轮排序:将最大的元素值放到arr[4]即最后一个位置上
涉及到比较的是该数组前五个元素
*/
for (int i = 0; i < 4; i++)
{
//发现下标小的元素值大于下标大的元素值
if (arr[i] > arr[i + 1])
{
//则交换两个元素位置
temp = arr[i];
arr[i] = arr[i+1];
arr[i + 1] = temp;
}
}
//打印第一轮排序后的结果
printf("第一轮排序后的结果:");
for (int j = 0; j < 5; j++)
{
printf("%d ", arr[j]);
}
//第一轮排序后的结果:8 6 7 5 9
printf("\n\n");
/*
第二轮排序:将第二大的元素值放到arr[3]即倒数第二个位置上
涉及到比较的是该数组前四个元素
*/
for (int i = 0; i < 3; i++)
{
//发现下标小的元素值大于下标大的元素值
if (arr[i] > arr[i + 1])
{
//则交换两个元素位置
temp = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = temp;
}
}
//打印第二轮排序后的结果
printf("第二轮排序后的结果:");
for (int j = 0; j < 5; j++)
{
printf("%d ", arr[j]);
}
//第二轮排序后的结果:6 7 5 8 9
printf("\n\n");
/*
第三轮排序:将第三大的元素值放到arr[2]即倒数第三个位置上
涉及到比较的是该数组前三个元素
*/
for (int i = 0; i < 2; i++)
{
//发现下标小的元素值大于下标大的元素值
if (arr[i] > arr[i + 1])
{
//则交换两个元素位置
temp = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = temp;
}
}
//打印第三轮排序后的结果
printf("第三轮排序后的结果:");
for (int j = 0; j < 5; j++)
{
printf("%d ", arr[j]);
}
//第三轮排序后的结果:6 5 7 8 9
printf("\n\n");
/*
第四轮排序:将第四大的元素值放到arr[1]即倒数第四个位置上
涉及到比较的是该数组前两个元素
*/
for (int i = 0; i < 1; i++)
{
//发现下标小的元素值大于下标大的元素值
if (arr[i] > arr[i + 1])
{
//则交换两个元素位置
temp = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = temp;
}
}
//打印第四轮排序后的结果
printf("第四轮排序后的结果:");
for (int j = 0; j < 5; j++)
{
printf("%d ", arr[j]);
}
//第四轮排序后的结果:5 6 7 8 9
printf("\n\n");
//到这里其实就结束了,因为一共只有五个元素,我们已经对四个大的元素进行了排序,那最小的肯定也就在arr[0]的位置上了
return 0;
}
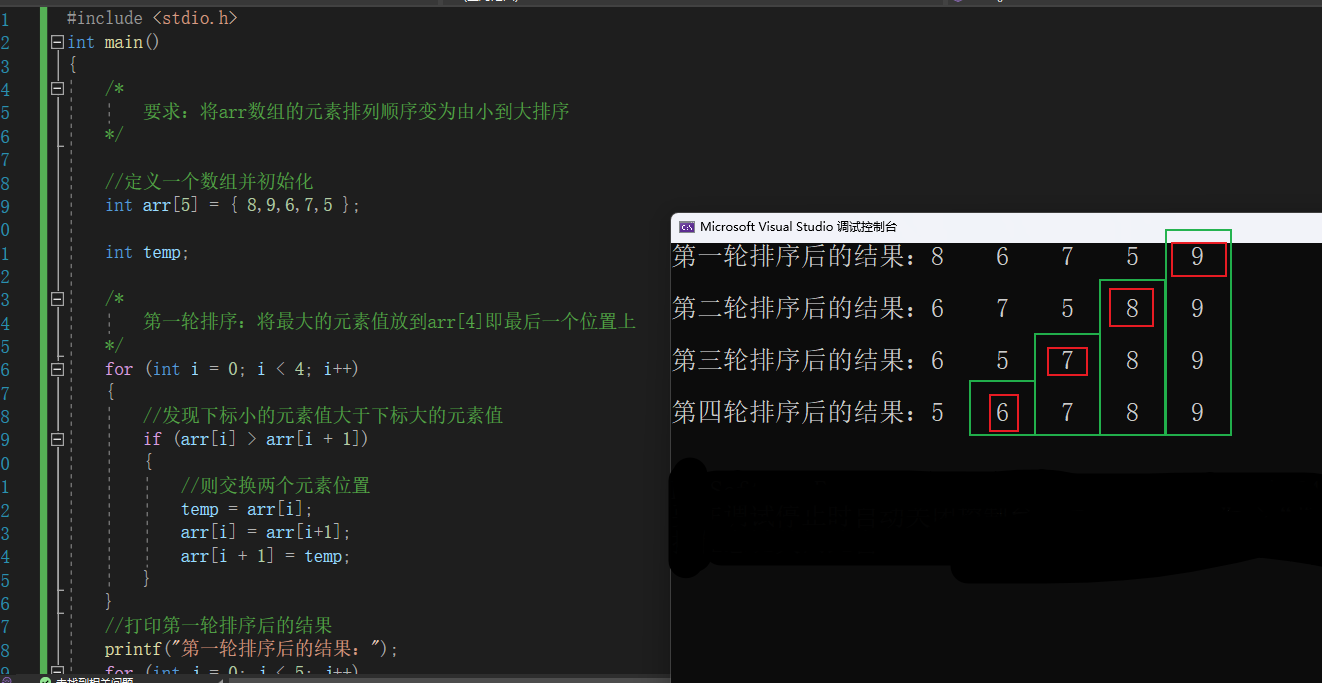
3.4.3.1.2 中级 - 原生模样合并
原生模样的代码,我们一共进行了四轮排序,而该数组一共有五个元素,因此 排序轮数 = 数组元素个数 - 1
仔细看原生模样的代码,其实可以发现,每一次for循环排序的结构都是差不多的,只不过是在for循环的循环条件判断 上是递减趋势,即:
- 第一轮排序:i < 4
- 第二轮排序:i < 3
- 第三轮排序:i < 2
- 第四轮排序:i < 1
这个 i 需要小于的数我们设为 num ,分别取了4、3、2、1。
这也很容易可以出来,num = 数组元素个数 - 当前轮数
因此我们可以:
- 以 排序轮数 作为 外层循环,循环
数组元素个数 - 1次 - 以 相邻元素比较 内层循环,循环
数组元素个数 - 当前轮次次
综上,总结一下:通过嵌套for循环实现了冒泡排序。其中,外层循环用来控制进行多少轮比较,每一轮比较都可以确定一个元素的位置,由于最后一个元素不需要进行比较,因此,外层循环的次数为数组的长度-1,内层循环的循环变量用于控制每轮比较的次数,在每次比较时,如果前者小于后者,就交换两个元素的位置。
#include <stdio.h>
int main()
{
/*
要求:将arr数组的元素排列顺序变为由小到大排序
*/
//定义一个数组并初始化
int arr[5] = { 8,9,6,7,5 };
int temp;
//数组长度
int length = sizeof(arr) / sizeof(arr[0]);
// j+1 表示当前排序轮数
// j < length-1 说明会循环 (数组元素个数 - 1) 次
for (int j = 0; j < length - 1; j++) {
// j+1 表示当前排序轮数
// i < length - (j+1) 说明会 相邻元素比较 循环 (数组元素个数-当前排序轮数) 次
for (int i = 0; i < length - (j+1); i++)
{
//发现下标小的元素值大于下标大的元素值
if (arr[i] > arr[i + 1])
{
//则交换两个元素位置
temp = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = temp;
}
}
}
//打印结果
for (int t = 0; t < 5; t++)
{
printf("%d ", arr[t]);
}
return 0;
}
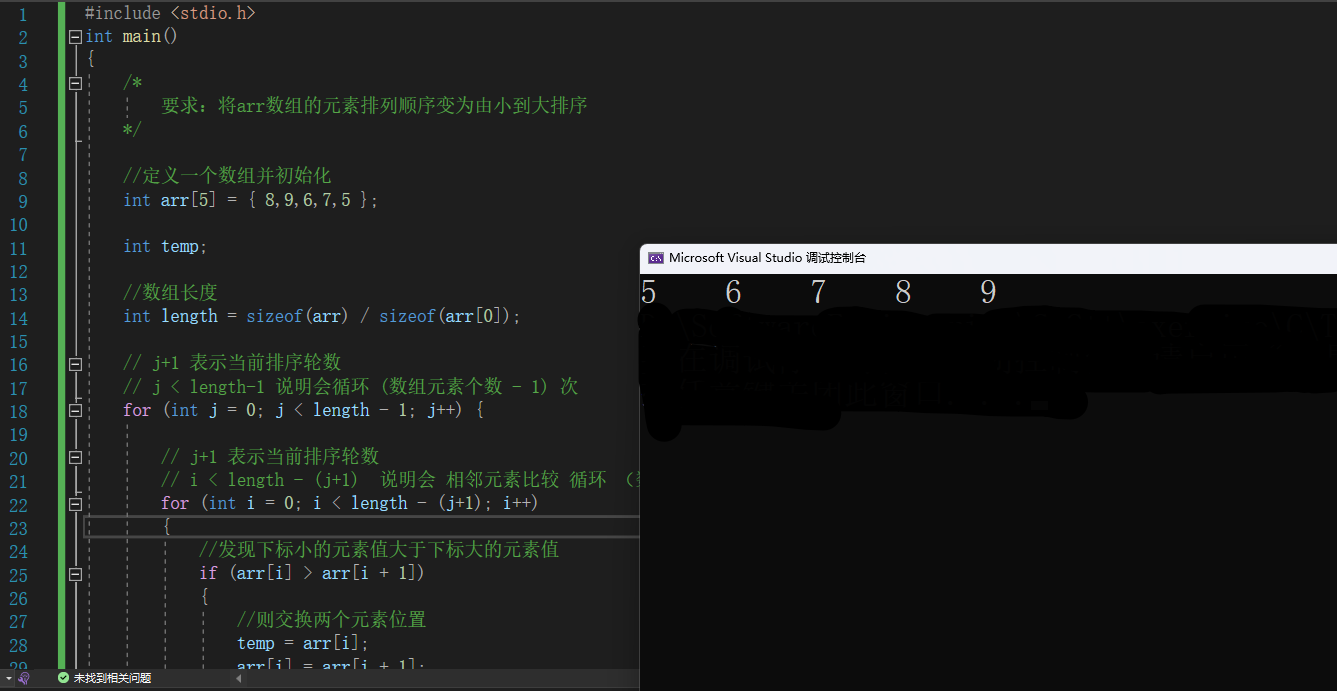
3.4.3.1.3 高级 - 冒泡排序优化
因为排序的过程中,各元素不断接近自己的位置,如果一趟比较下来没有进行过交换,就说明序列有序,
因此要在排序过程中设置一个标志 flag 判断元素是否进行过交换。从而减少不必要的比较。
#include <stdio.h>
int main()
{
/*
要求:将arr数组的元素排列顺序变为由小到大排序
*/
//定义一个数组并初始化
int arr[5] = { 8,9,6,7,5 };
int temp;
//设置一个标志 flag 判断元素是否进行过交换
//0表示没有交换,1表示发生交换
//默认为没有交换
int flag;
//数组长度
int length = sizeof(arr) / sizeof(arr[0]);
// j+1 表示当前排序轮数
// j < length-1 说明会循环 (数组元素个数 - 1) 次
for (int j = 0; j < length - 1; j++) {
//在每一轮排序,即元素比较前,默认为没有交换
flag = 0;
// j+1 表示当前排序轮数
// i < length - (j+1) 说明会 相邻元素比较 循环 (数组元素个数-当前排序轮数) 次
for (int i = 0; i < length - (j+1); i++)
{
//发现下标小的元素值大于下标大的元素值
if (arr[i] > arr[i + 1])
{
//说明是发生交换的,则设置flag为1
flag = 1;
//则交换两个元素位置
temp = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = temp;
}
}
/*
该轮排序完毕,判断是否发生过交换
如果该轮发生过交换,则说明我们还需要进行下一轮排序
如果该轮没有发生过交换,则说明全部元素已经按照从小到大排列好了,那我们就不进行下轮排序了
*/
if (!flag) {
//说明没有发生过交换,则直接跳出外层循环即不进行下轮排序
break;
}
}
//打印结果
for (int t = 0; t < 5; t++)
{
printf("%d ", arr[t]);
}
return 0;
}
3.4.3.2 选择排序法
3.4.3.2.1 基本介绍
选择式排序也属于内部排序法,是从欲排序的数据中,按指定的规则选出某一元素,再依规定交换位置后达到 排序的目的。
3.4.3.2.2 选择排序思想
选择排序(select sorting)也是一种简单的排序方法。它的基本思想是:第一次从 arr[0]~arr[n-1]中选取最小值, 与 arr[0]交换,第二次从 arr[1]~arr[n-1]中选取最小值,与 arr[1]交换,第三次从 arr[2]~arr[n-1]中选取最小值,与 arr[2] 交换,…,第 i 次从 arr[i-1]~arr[n-1]中选取最小值,与 arr[i-1]交换,…, 第 n-1 次从 arr[n-2]~arr[n-1]中选取最小值, 与 arr[n-2]交换,总共通过 n-1 次,得到一个按排序码从小到大排列的有序序列。
3.4.3.2.3 思路分析
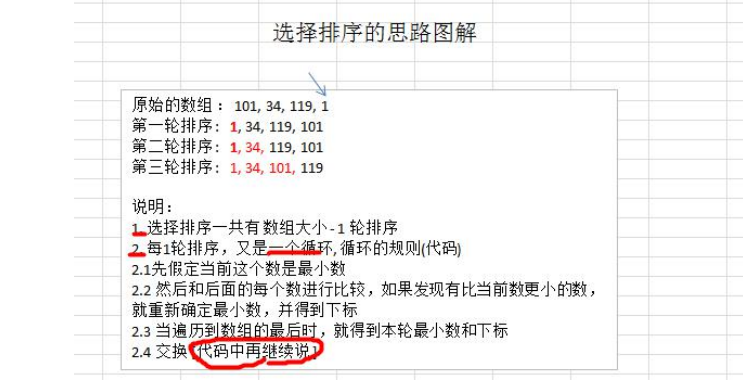
3.4.3.2.4 代码实现
3.4.3.2.4.1 揭秘选择排序原生模样
#include<stdio.h>
int main()
{
//不指定长度的初始化赋值 --> 数组长度由参与赋值的元素个数决定
int arr[] = { 101,115,119,1 };
//最小值
int minValue;
//最小值的那个元素的索引/下标
int minValueIndex;
//数组的长度
int length = sizeof(arr) / sizeof(arr[0]);
/*
第一轮循环:搜索索引在[0,length-1]即[0,3]内的最小元素值及其索引
*/
//假定最小值为 arr[0]
minValue = arr[0];
//并标记一下当前索引 - 0
minValueIndex = 0;
//将minValue与该索引后面的元素进行遍历比较
for (int j = 0 + 1; j < length; j++) {
//发现更小的元素值
if (arr[j] < minValue) {
//则将当前最小值minValue设置为该元素值
minValue = arr[j];
//并标记好改元素的索引值
minValueIndex = j;
}
}
//遍历完毕,如果当前最小值标记的索引不是 0
//则将索引为 0 的元素与当前最小值的索引的元素值进行交换
//将最小值放到了 索引为 0 的位置上
if (minValueIndex != 0) {
arr[minValueIndex] = arr[0];
arr[0] = minValue;
}
//打印结果
printf("第一轮循环的结果:");
for (int t = 0; t < length; t++)
{
printf("%d ", arr[t]);
}
//第一轮排序后的结果:1 115 119 101
printf("\n\n");
/*
第二轮循环:搜索索引在[1,length-1]即[1,3]内的最小元素值及其索引
*/
//假定最小值为 arr[1]
minValue = arr[1];
//并标记一下当前索引 - 1
minValueIndex = 1;
//将minValue与该索引后面的元素进行遍历比较
for (int j = 1 + 1; j < length; j++) {
//发现更小的元素值
if (arr[j] < minValue) {
//则将当前最小值minValue设置为该元素值
minValue = arr[j];
//并标记好改元素的索引值
minValueIndex = j;
}
}
//遍历完毕,如果当前最小值标记的索引不是 1
//则将索引为 1 的元素与当前最小值的索引的元素值进行交换
//将最小值放到了 索引为 1 的位置上
if (minValueIndex != 1) {
arr[minValueIndex] = arr[1];
arr[1] = minValue;
}
//打印结果
printf("第二轮循环的结果:");
for (int t = 0; t < length; t++)
{
printf("%d ", arr[t]);
}
//第二轮排序后的结果:1 101 119 115
printf("\n\n");
/*
第三轮循环:搜索索引在[2,length-1]即[2,3]内的最小元素值及其索引
*/
//假定最小值为 arr[2]
minValue = arr[2];
//并标记一下当前索引 - 2
minValueIndex = 2;
//将minValue与该索引后面的元素进行遍历比较
for (int j = 2 + 1; j < length; j++) {
//发现更小的元素值
if (arr[j] < minValue) {
//则将当前最小值minValue设置为该元素值
minValue = arr[j];
//并标记好改元素的索引值
minValueIndex = j;
}
}
//遍历完毕,如果当前最小值标记的索引不是 2
//则将索引为 2 的元素与当前最小值的索引的元素值进行交换
//将最小值放到了 索引为 2 的位置上
if (minValueIndex != 2) {
arr[minValueIndex] = arr[2];
arr[2] = minValue;
}
//打印结果
printf("第三轮循环的结果:");
for (int t = 0; t < length; t++)
{
printf("%d ", arr[t]);
}
//第三轮排序后的结果:1 101 115 119
printf("\n\n");
//这里就没必要进行第四次循环了,
//因为一共四个元素,我们通过三次循环求出了三个对应范围内的最小值
//因此第四个元素也就到了应到的位置了
return 0;
}
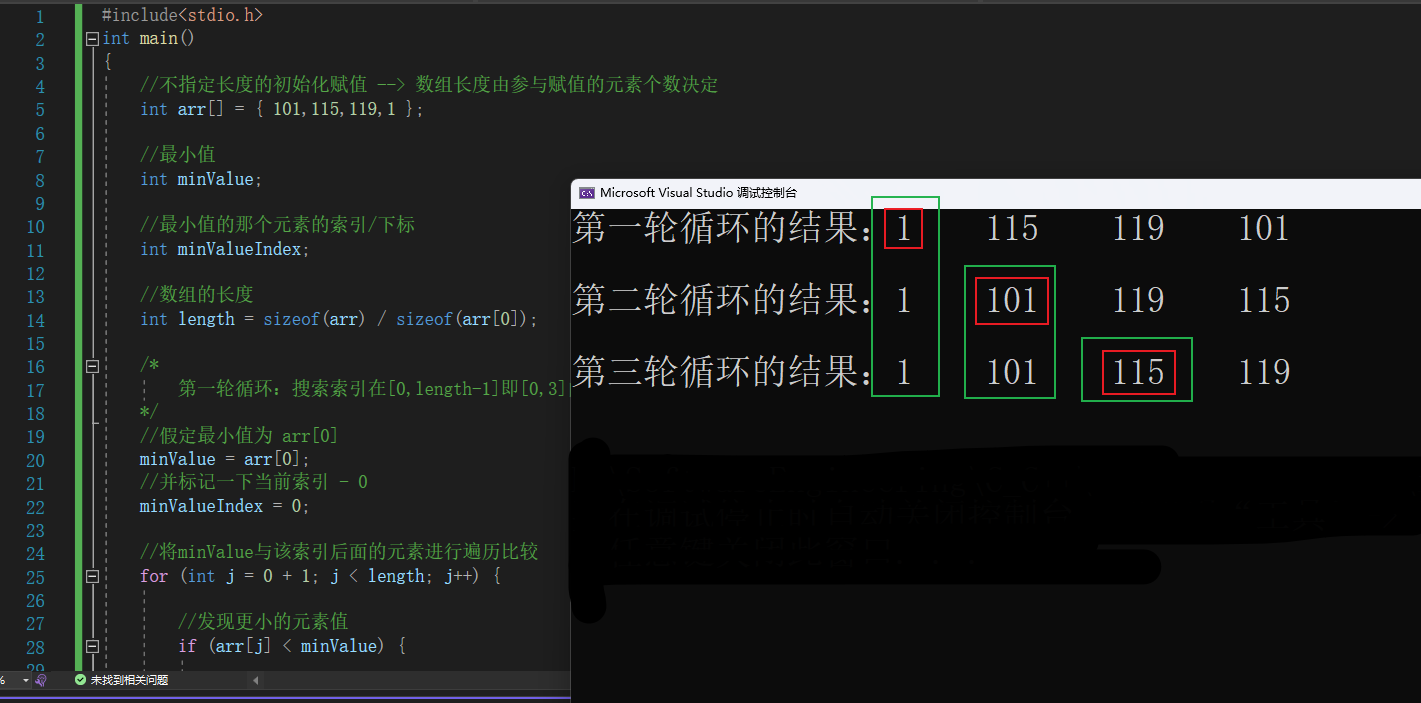
3.4.3.2.4.2 合并原生模样代码
原生模样的代码,我们一共进行了三轮排序,而该数组一共有四个元素,因此 排序轮数 = 数组元素个数 - 1
仔细看原生模样的代码,其实可以发现,每一次for循环排序的结构都是差不多的,只不过是比较范围在缩小,即:
- 第一轮排序:起始假定 minIndex = 0 ,与索引范围在[1,3]的元素比较
- 第二轮排序:起始假定 minIndex = 1 ,与索引范围在[2,3]的元素比较
- 第三轮排序:起始假定 minIndex = 2 ,与索引范围在[3,3]的元素比较
这也很容易可以出来:
- minIndex = 当前轮数 - 1
- 比较索引开始值 = minIndex + 1
#include<stdio.h>
int main()
{
//不指定长度的初始化赋值 --> 数组长度由参与赋值的元素个数决定
int arr[] = { 101,34,119,1 };
//最小值
int minValue;
//最小值的那个元素的索引/下标
int minValueIndex;
//数组的长度
int length = sizeof(arr) / sizeof(arr[0]);
//循环 length-1 次,对应 (length-1) 个不同范围的最小值
for (int i = 0; i < length - 1; i++) {
//最小值为当前索引的值
minValue = arr[i];
//并标记一下当前索引
minValueIndex = i;
//将minValue与该索引后面的元素进行遍历比较
for (int j = i + 1; j < length; j++) {
//发现更小的元素值
if (arr[j] < minValue) {
//则将当前最小值minValue设置为该元素值
minValue = arr[j];
//并标记好改元素的索引值
minValueIndex = j;
}
}
//遍历完毕,如果当前最小值标记的索引不是i
//则将索引为 i 的元素与当前最小值的索引的元素值进行交换
if (minValueIndex != i) {
arr[minValueIndex] = arr[i];
arr[i] = minValue;
}
}
//打印结果
for (int t = 0; t < length; t++)
{
printf("%d ", arr[t]);
}
return 0;
}
4.二维数组
4.1 二维数组的定义
在实际的工作中,仅仅使用一维数组是远远不够的,例如,一个学习小组有5个人,每个人有三门课的考试成绩,如果使用一维数组解决是很麻烦的。又比如说你有三个女朋友,每个女朋友有自己的三维,如果使用一维数组解决也很麻烦。这时,可以使用二维数组,二维数组的定义方式与一维数组类似,其语法格式如下:
类型说明符 数组名[常量表达式1][常量表达式2];
- 类型说明符:数组中每一个元素的数据类型
- 常量表达式1:被称为行下标
- 常量表达式2:被称为列下标。
📝 定义一个3行4列的二维数组:
int a[3][4];
在上述定义的二维数组中,共包含3*4个元素,即12个元素。接下来,通过一张图来描述二维数组a的元素分布情况:
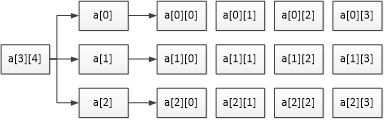
可以看出,二维数组a是按行进行存放的,先存放a[0]行,再存放a[1]行、a[2]行,并且每行有四个元素,也是依次存放的。
4.2 二维数组初始化
完成二维数组的定义后,需要对二维数组进行初始化,初始化二维数组的方式有四种,具体如下:
4.2.1 按行给二维数组赋初值
int a[2][3] = {{1,2,3},{4,5,6}};
//我们也可以写成格式比较清晰的形式
int a[2][3] = {
{1,2,3},
{4,5,6}
};
在上述代码中,等号后面有一对大括号,大括号中的第一对括号代表的是第一行的数组元素,第二对括号代表的是第二行的数组元素。
4.2.2 将所有的数组元素按行顺序写在一个大括号内
int a[2][3] = {1,2,3,4,5,6};
在上述代码中,二维数组a共有两行,每行有三个元素,其中,第一行的元素依次为1、2、3,第二行元素依次为4、5、6。这是由编译器自动区分判断的。
4.2.3 对部分数组元素赋初值
int b[3][4] = {{1},{4,3},{2,1,2}};
//我们也可以写成格式比较清晰的形式
int a[3][4] = {
{1},
{4,3},
{2,1,2}
};
在上述代码中,只为数组b中的部分元素进行了赋值,对于没有赋值的元素,系统会自动赋值为0,数组b中元素的存储方式如图所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-huowvBAI-1668092325247)(D:/typora-image/wps3.png)]
4.2.4 如果对全部数组元素置初值,则二维数组的第一个下标可省略,但第二个下标不能省略
int a[2][3] = {1,2,3,4,5,6};
可以写为
int a[][3] = {1,2,3,4,5,6};
系统会根据固定的列数,将后边的数值进行划分,自动将行数定为 2。
4.3 二维数组的引用
二维数组的引用方式同一维数组的引用方式一样,也是通过数组名和下标的方式来引用数组元素,其语法格式如下:
数组名[下标][下标];
在上述语法格式中,下标值应该在已定义的数组的大小范围内,例如下面这种情况是错误的。
int a[3][4]; // 定义a为3行4列的二维数组
a[3][4]=3; // 对数组a第3行第4列元素赋值,出错
在上述代码中,数组a可用的行下标范围是[0,2],列下标是[0,3],a[3][4]超出了数组的下标范围。
📝 示例演示
#include<stdio.h>
int main()
{
//声明并初始化数组
int array[3][4] = { {1,2,3,4 }, {5,6,7,8}, {9,10,11,12} };
for (int i = 0; i < 3; i++) //循环遍历行
{
for (int j = 0; j < 4; j++) //循环遍历列
{
printf("[%d][%d]: %d ", i, j, array[i][j]);
}
printf("\n");//每一行的末尾添加换行符
}
}
4.4 二维数组的长度
二维数组的长度是 数组定义时的行下标,例如 int arr[4][5],该二维数组的长度是 4,准确来说,二维数组的每一个元素都是一个一维数组。
无论是几维数组,数组的长度都可以通过 sizeof(arr)/sizeof(arr[0]) 得到。
5.多维数组
在计算机中,除一维数组和二维数组外,还有三维,四维,……等多维数组,它们用在某些特定程序开发中,多维数组的定义与二维数组类似,其语法格式具体如下:
数组类型修饰符 数组名 [n1][n2]…[nn];
定义一个三维数组的示例代码如下:
int x[3][4][5];
上面的这个例子,定义了一个三维数组,数组的名字是x,数组的长度为3,每个数组的元素又是一个二维数组,这个二维数组的长度是4,并且这个二维数组中的每个元素又是一个一维数组,这个一维数组的长度是5,元素类型是int。
多维数组在实际的工作中使用不多,并且使用方法与二维数组相似,这里不再做详细地讲解,有兴趣的可以自己学习。
6.数组名
6.1 一维数组的数组名
#include <stdio.h>
int main()
{
int arr[] = { 1,2,3,4,5,6,7 };
printf("%p", arr); // %p:求 arr 在内存中的地址
printf("\n\n");
printf("%p", &arr[0]); // 求数组第一个元素在内存中的地址
return 0;
}
数据的地址以16进制形式存放于内存中。

说明一维数组中:数组名的值是数组首元素的地址
6.2 二维数组的数组名
#include <stdio.h>
int main()
{
int arr[3][4];
printf("%p", arr); // %p:求 arr 在内存中的地址
printf("\n\n");
printf("%p", arr[0]); // 求数组第一个元素在内存中的地址
return 0;
}
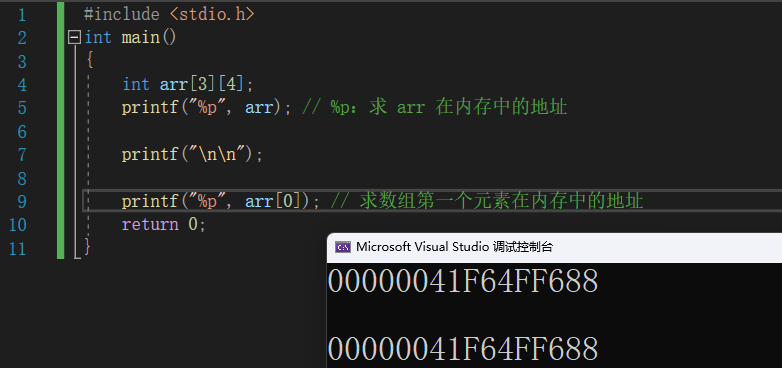
说明二维数组中:数组名的值是数组首元素的地址
6.3 总结
同理,在多维数组也是如此 —— 数组名是数组首元素的地址。
7.数组在内存里的存储
7.1 一维数组
#include <stdio.h>
int main()
{
int arr[10] = { 0 };
int i = 0;
for (i = 0; i < sizeof(arr) / sizeof(arr[0]); ++i)
{
printf("&arr[%d] = %p\n", i, &arr[i]);
}
return 0;
}
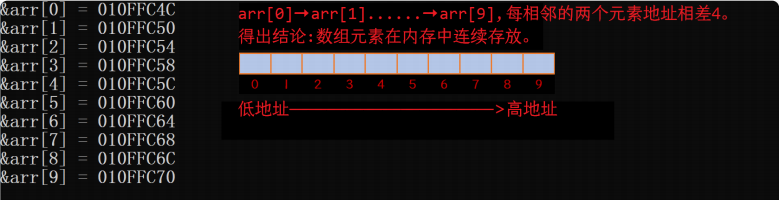
为什么差4位呢?
原因:因为是int类型的数组,一个int类型的数据占4个字节。
7.2 二维数组
#include <stdio.h>
int main()
{
int arr[3][4];
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 4; j++)
{
printf("&arr[%d][%d] = %p\n", i, j, &arr[i][j]);
}
}
return 0;
}
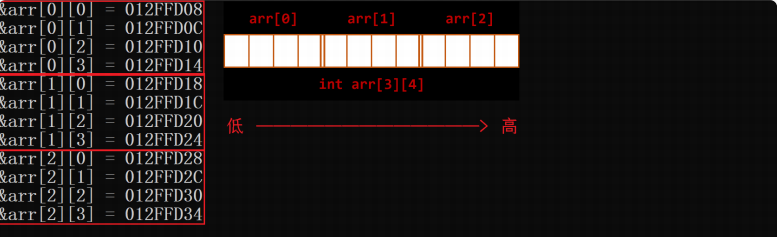
7.3 总结
- 数组在内存中是连续存放的。因为数组是连续的,知道了首元素的地址,就知道了数组每一个元素的地址,数组名就是首元素的地址,这也就解释了为什么我们有了数组名,就可以得到和操作该数组的每一个元素。同理,我们知道每一个数据的内存地址,可以直接找到给定地址的数据。
- 随着数组下标的增长,地址是由低到高变化的。
8.数组未初始化注意事项
8.1 未初始化
8.1.1 全局数组,被编译器初始化为0
#include <stdio.h>
int arr[5];//全局数组
int main()
{
for (int i = 0; i < 5; i++)
{
printf("arr[%d] = %d\n", i, arr[i]);
}
return 0;
}
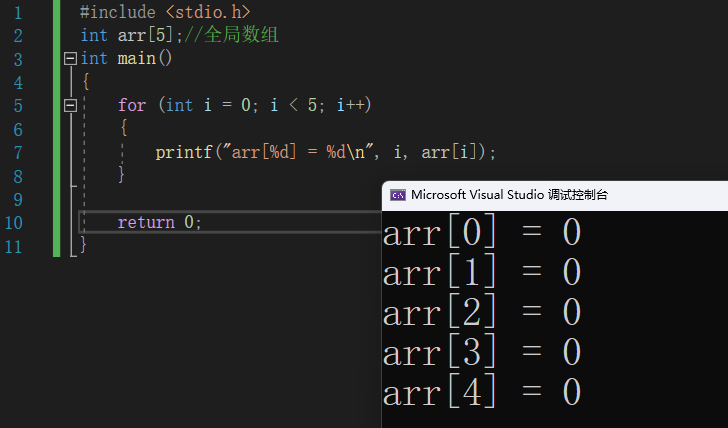
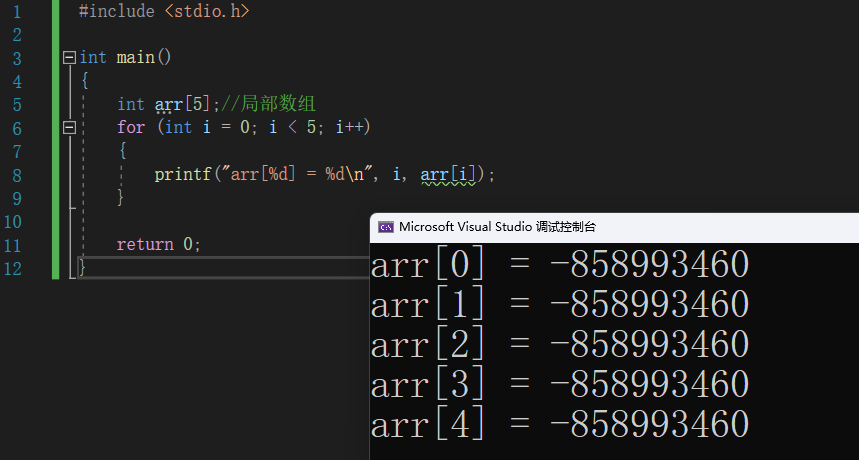
8.1.2 局部数组,被编译器初始化为随机数
#include <stdio.h>
int main()
{
int arr[5];//局部数组
for (int i = 0; i < 5; i++)
{
printf("arr[%d] = %d\n", i, arr[i]);
}
return 0;
}
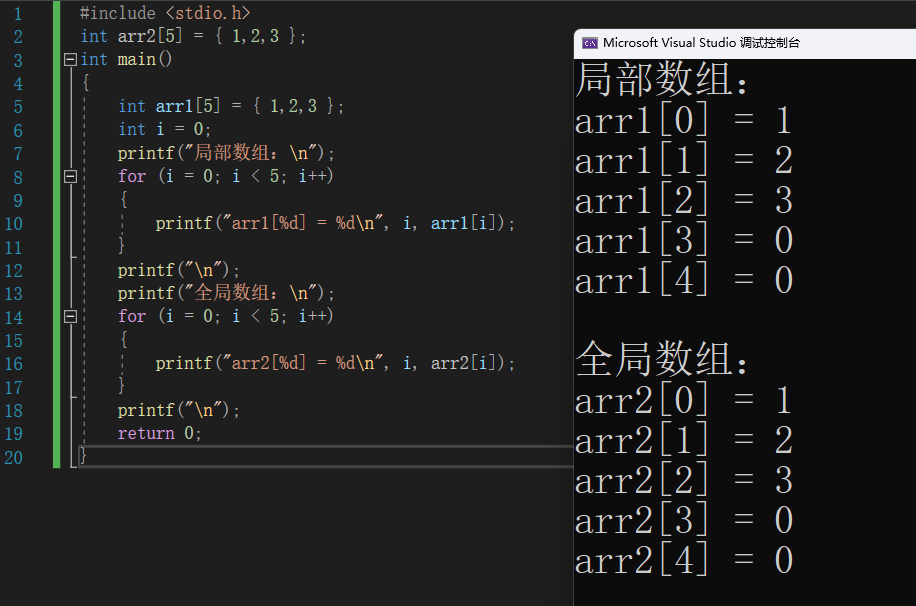
8.2 不完全初始化
局部数组和全局数组中未赋值的数组元素都会被赋值为0。
#include <stdio.h>
int arr2[5] = { 1,2,3 };
int main()
{
int arr1[5] = { 1,2,3 };
int i = 0;
printf("局部数组:\n");
for (i = 0; i < 5; i++)
{
printf("arr1[%d] = %d\n", i, arr1[i]);
}
printf("\n");
printf("全局数组:\n");
for (i = 0; i < 5; i++)
{
printf("arr2[%d] = %d\n", i, arr2[i]);
}
printf("\n");
return 0;
}
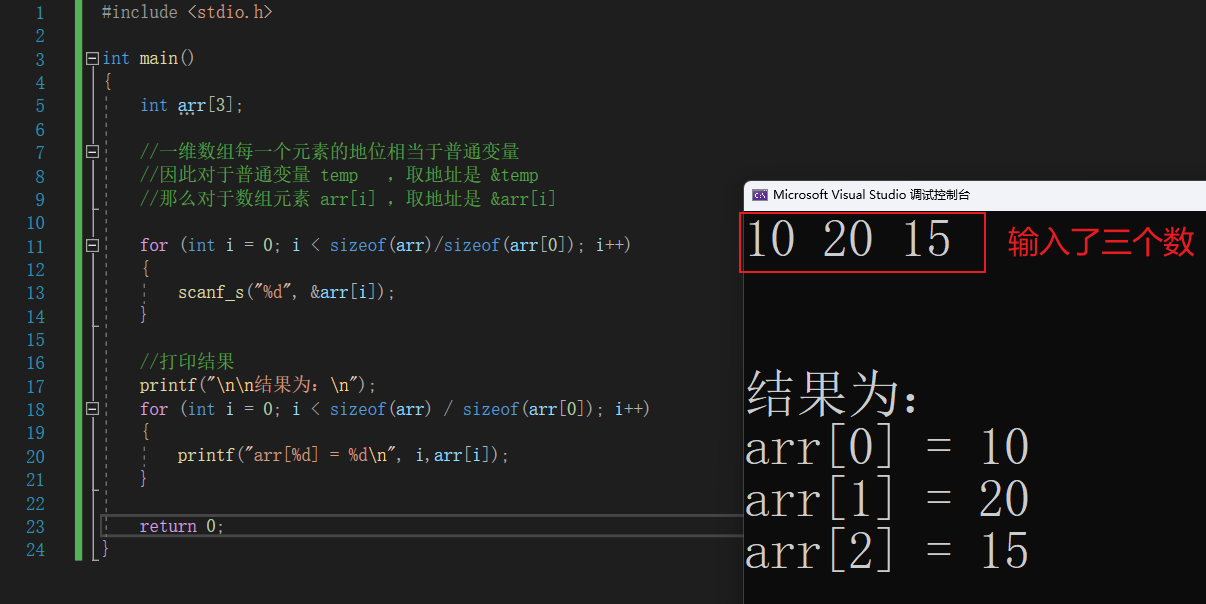
9.键盘输入给数组赋值的方式
9.1 一维数组
#include <stdio.h>
int main()
{
int arr[3];
//一维数组每一个元素的地位相当于普通变量
//即 temp 与 arr[i] 地位 相当
//因此对于普通变量 temp ,取地址是 &temp
//那么对于数组元素 arr[i] ,取地址是 &arr[i]
for (int i = 0; i < sizeof(arr)/sizeof(arr[0]); i++)
{
scanf_s("%d", &arr[i]);
}
//打印结果
printf("\n\n结果为:\n");
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("arr[%d] = %d\n", i,arr[i]);
}
return 0;
}
9.2 二维数组
#include <stdio.h>
int main()
{
int arr[2][3];
//二维数组每一个元素是一维数组,一维数组的每一个元素的地位相当于普通变量
//即 temp 与 arr[i][j] 地位 相同
//因此对于普通变量 temp ,取地址是 &temp
//那么对于数组元素 arr[i][j] ,取地址是 &arr[i][j]
for (int i = 0; i < sizeof(arr)/sizeof(arr[0]); i++)
{
for (int j = 0; j < sizeof(arr[0])/sizeof(arr[0][0]); j++)
{
scanf_s("%d", &arr[i][j]);
}
}
//打印结果
printf("\n\n结果为:\n");
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
for (int j = 0; j < sizeof(arr[0]) / sizeof(arr[0][0]); j++)
{
printf("arr[%d][%d] = %d\n", i,j, arr[i][j]);
}
}
return 0;
}
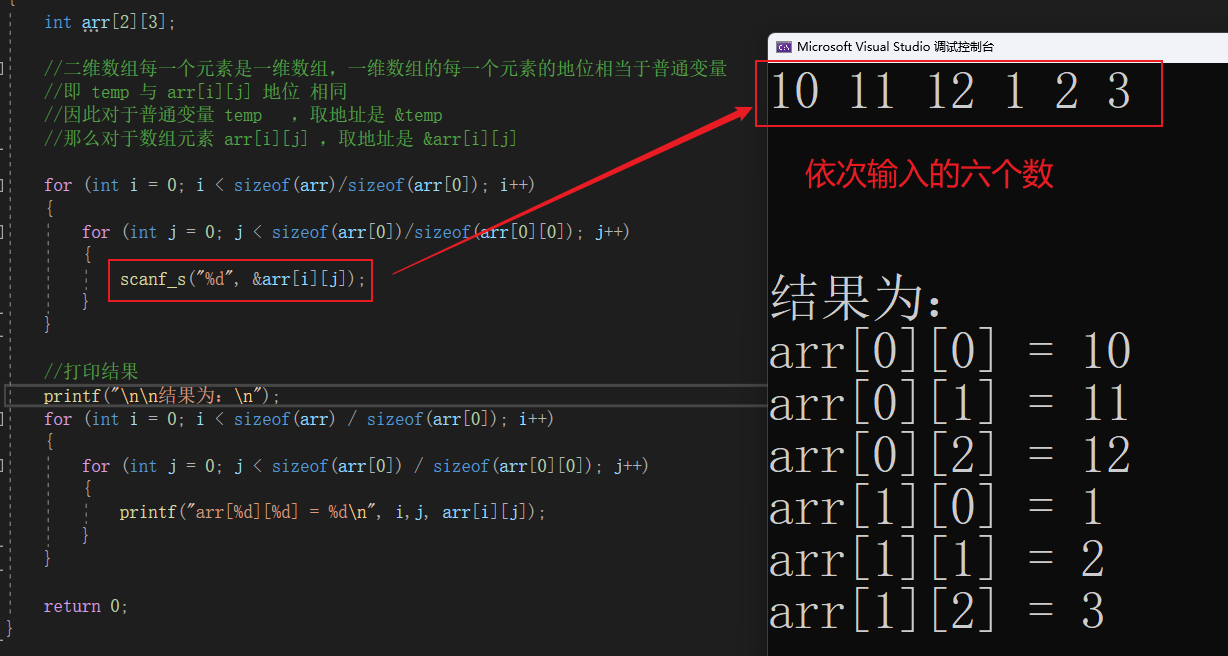
同理,多维数组也是同样的方式。
10.进阶:三个经典问题
10.1 打印直角状杨辉三角
10.1.1 题目描述

目标打印结果:
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
10.1.2 思路分析
-
建立一个二维数组,初始化每一个元素值为0
-
可以很容易观察到,每一行第一个元素的值总是为1,因此我们可以先给每一行的第一个元素赋值为1
-
然后其它位置的每一个元素
arr[i][j]的值总是等于该元素位置的上一行同一列位置值+上一行同一列左边一个位置值的和。即 arr[ i ][ j ] = arr[ i-1 ][ j ] + arr[ i-1 ][ j-1 ]
-
我们就可以从第二行开始按此规律进行赋值
10.1.3 代码实现
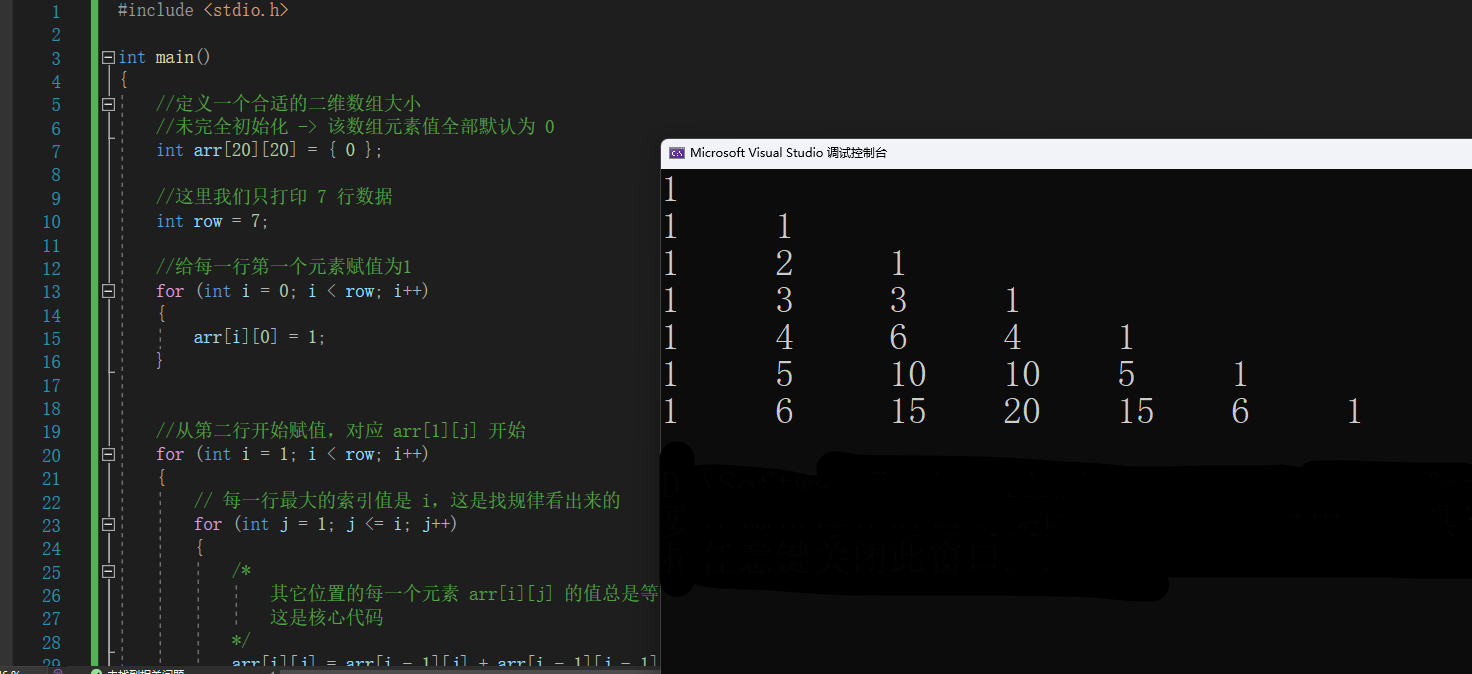
#include <stdio.h>
int main()
{
//定义一个合适的二维数组大小
//未完全初始化 -> 该数组元素值全部默认为 0
int arr[20][20] = { 0 };
//这里我们只打印 7 行数据
int row = 7;
//给每一行第一个元素赋值为1
for (int i = 0; i < row; i++)
{
arr[i][0] = 1;
}
//从第二行开始赋值,对应 arr[1][j] 开始
for (int i = 1; i < row; i++)
{
// 每一行最大的索引值是 i,这是找规律看出来的
for (int j = 1; j <= i; j++)
{
/*
其它位置的每一个元素 arr[i][j] 的值总是等于该元素位置的 上一行同一列位置值 + 上一行同一列左边一个位置值 的和。
这是核心代码
*/
arr[i][j] = arr[i - 1][j] + arr[i - 1][j - 1];
}
}
//打印结果
for (int i = 0; i < row; i++)
{
// 每一行最大的索引值是 i,这是找规律看出来的
for (int j = 0; j <= i; j++)
{
printf("%-6d", arr[i][j]);
}
printf("\n");
}
return 0;
}
10.2 筛数法求素数
10.2.1 题目描述
求 2 ~ 10000内的素数有哪些
10.2.2 筛数法求素数的基本思想
把从1开始的、某一范围内的正整数从小到大顺序排列, 1不是素数,首先把它筛掉。剩下的数中选择最小的数是素数,然后去掉它的倍数。依次类推,直到筛子为空时结束。
10.2.3 代码实现
#include<stdio.h>
//定义一个常量 N
#define N 10001
int main()
{
/*
建立一个数组,每个索引 Index 就代表一个数 num
规定 arr[num] 的值为 0 或 1
如果 arr[num] 为 0,则表示 num 是素数
如果 arr[num] 为 1,则表示 num 是非素数
*/
int arr[N] = { 0 };
int temp;
//从 2 开始依次遍历 [2,10000] 范围内的所有数
for (int num = 2; num < N; num++)
{
//C语言中 0 表示 false,非0数表示true
if(!arr[num])
{
//说明 arr[num] = 0,则表明arr[num]是素数
//那么num的倍数均不为素数,我们就 num所有的倍数 对应数组索引位置的元素值 设置为 1
for (temp = 2 * num; temp < N; temp += num)
{
// num为素数,我们将它的倍数设置为1,不为素数
arr[temp] = 1;
}
}
}
//输出素数,就是取出数组中索引对应值为 0 的数据
for (int num = 2; num < N; num++)
{
if (!arr[num])
{
printf("%d\n", num);
}
}
return;
}
上述代码其实还可以再做优化,比如说2的倍数和3的倍数肯定有重复,那就会进行重复的赋值操作。那我们应该怎么去优化呢?这个问题就交给小伙伴们自己去认真思考一下。因为我们都是这世上孤独的灵魂,没有人会永远的陪你与疼你,这让我想起遗憾的是她只是我的一个朋友。
10.3 约瑟夫问题
10.3.1 问题描述
设编号为 1,2,… n 的 n 个人围坐一圈,约定编号为 k(1<=k<=n)的人从 1 开始报数,数 到 m 的那个人出列,它的下一位又从 1 开始报数,数到 m 的那个人又出列,依次类推,直到所有人出列为止,由 此产生一个出队编号的序列。
10.3.2 思路分析
- 假设 10 个人参与游戏,对应数组索引 [1,10],从编号为3的人开始从1报数,报到 4 的人出局,下一个未出局的人重新从1开始报数,直到全部出局。
- 数组 每一个元素值为 0 或 1, 0代表未出局,1代表出局。游戏刚开始默认值都为0。
- 每次报数前先判断编号k对应的数组索引的元素值 arr[k] 是否为0:
- 为0说明未出局,则判断此人是否报数报到 4
- 报到4则将对应数组索引的元素值 arr[k] 置为 1,表示出局 ,当前游戏剩余人数 count --,并将 报数 num 置为 1 ,表示下一个人从1开始报数。
- 没有报到 4 则将 num++,得到下一个人应该报的数。
- 为1说明出局,不进行处理
- 为0说明未出局,则判断此人是否报数报到 4
- 无论是否出局,报数还得继续,则移至下一个人
- 如果当前编号已经是10,即已经到了最后一个编号,则将 k = 1 ,表示从头开始,回到
步骤3 - 如果当前编号不是10,那就直接 k++ ,移动到下一个人,回到
步骤3
- 如果当前编号已经是10,即已经到了最后一个编号,则将 k = 1 ,表示从头开始,回到
- 直到 count 为 0游戏结束
10.3.3 代码实现
#include<stdio.h>
//参与游戏的总人数
#define N 10
int main()
{
/*
这里举一个具体例子:
n:总人数 - 10
k:从该编号开始报数 - 3
m:数到 m 的人淘汰出局 - 4
*/
/*
数组索引[1, 10] 对应编号[1, 10]的人
使用不完全初始化,则数组元素值均为0
0 表示未出局
1 表示已出局
则默认都是还未出局
*/
int arr[N+1] = { 0 };
//当前游戏剩余人数初始值为 10
int count = N;
//从编号为 3 的人从1开始报数
int k = 3;
//记录当前数到的数为 num,默认从1开始报数
int num = 1;
//数到4的人淘汰出局
int m = 4;
//count为0即为false,while循环结束代表游戏结束
while (count)
{
//如果出局则arr[k]为 1 则 !arr[k] 为false,不会进入if,就不用管了,直接忽略
if (!arr[k]) {
//说明未出局,则进行判断编号为k的人是否数到了m
if (num != m)
{
//说明没有数到m,则得到下一个人应该报的数:num++ 即可
num++;
}
else
{
//如果报到了这个数 num,则将该人编号对应数组索引的元素值置为 1 表示出局
arr[k] = 1;
//并保证下一个人从1重新开始报数
num = 1;
//打印一下出局人的编号
printf("出局人编号:%d\n", k);
}
}
//无论有没有出局,我们在处理完上述后都应该移动该编号的下一个位置
if (k != N)
{
//如果没有到 最后一个人,直接 往后移动
k++;
}
else
{
//如果到了最后一个人,则从编号为1的人开始报数,这样就构成了一群人围成一个圈进行报数的模式
k = 1;
}
}
return 0;
}
11.字符数组
11.1 字符数组定义与初始化
字符数组是数组的元素类型为字符型的数组。特殊之处在于它是数组元素为字符的数组。其定义与初始化的一般形式和注意事项与之前讲解的一般数组类似,只是其中的类型说明符是char。当然,并不是说类型说明符只能是char,也可以是long、int等,但是由于char型只占用一个字节的大小,使用long型和int型来定义字符数组会造成资源的浪费,因此一般选择使用char型来定义字符数组。
//字符数组定义 - 这些都是一维数组,因此初始化的方式和一维数组是一样的
char chars1[10];
int chars2[10];
long chars3[10];
我们来比较一下占用的空间大小:
#include<stdio.h>
int main()
{
/*
这里使用的一维数组初始化方式:
对数组全部元素赋值,但不指定长度
*/
char arr[] = { 'g','i','r','l' };
/*
这里使用的一维数组初始化方式:
直接对数组中的全部元素赋值
*/
int brr[4] = { 'g','i','r','l' };
/*
比较一下数组内存大小:
char类型占一个字节,int类型占4个字节
因此sizeof(arr)的值是 1 * 4 = 4
因此sizeof(brr)的值是 4 * 4 = 16
*/
printf("char类型数组占用内存:%lld\n" ,sizeof(arr));
printf("int 类型数组占用内存:%lld" ,sizeof(brr));
return 0;
}

在上面的代码中定义了不同类型的字符数组来存放相同的字符,可以看出,它们占用的内存大小相差很大,int型字符数组所占用内存大小是char型数组占用内存大小的4倍。从这点可以看出,选用char型作为字符数组类型避免了内存空间的浪费。
11.2 未完全初始化
#include<stdio.h>
int main() {
int i;
char arr[20] = { 'm','y',' ','g','i','r','l' };
// sizeof(arr)/sizeof(arr[0] 的值为数组的长度 - 20
for (i = 0; i < sizeof(arr)/sizeof(arr[0]); i++)
{
printf("%c", arr[i]);
}
return 0;
}
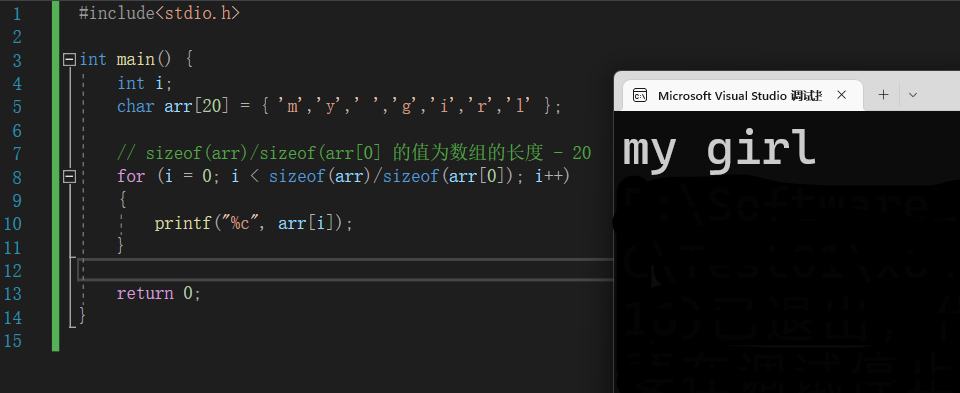
运行结果为“my girl”,其中有一些空字符。看看上面代码中定义的arr数组,其数组长度为20,而初始化的字符元素的个数为7,初始化的字符元素个数小于数组长度,编译器在编译过程中将后面没有初始化的数组元素赋值为‘\0’,这也正是打印输出中含有空字符的原因。
⚠️ 注意这个空字符不是空格符号。而是指的什么也不输出打印。
‘\0’代表ASCII码为0的字符,从ASCII码表中可以查到,ASCII码为0的字符不是一个可以显示的字符,而是一个“空操作符”,即它什么也不做。
#include<stdio.h> int main() { int i; char arr[20] = { 'm','y',' ','g','i','r','l' }; // sizeof(arr)/sizeof(arr[0] 的值为数组的长度 - 20 for (i = 0; i < sizeof(arr)/sizeof(arr[0]); i++) { printf("%c", arr[i]); } printf("我爱过你"); return 0; }

我们看下上述代码对数组字符的打印次数:
#include<stdio.h>
int main() {
int i;
char arr[20] = { 'm','y',' ','g','i','r','l' };
// sizeof(arr)/sizeof(arr[0] 的值为数组的长度 - 20
for (i = 0; i < sizeof(arr)/sizeof(arr[0]); i++)
{
printf("打印第%d个字符:%c\n", i+1,arr[i]);
}
return 0;
}

但很明显,我们并不需要打印那些为’\0’的字符。因此,在打印的时候也可以将数组中的元素‘\0’视为数组结束的标志,例如:
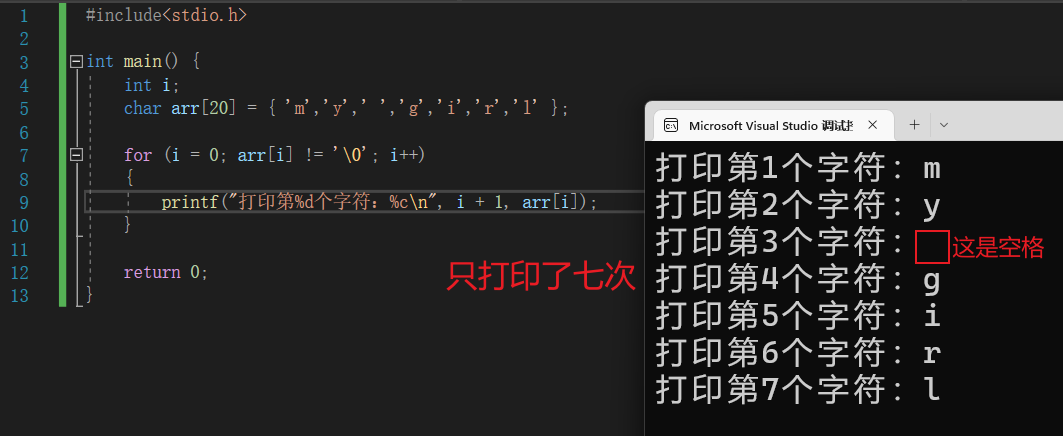
#include<stdio.h>
int main() {
int i;
char arr[20] = { 'm','y',' ','g','i','r','l' };
for (i = 0; arr[i]!='\0'; i++)
{
printf("打印第%d个字符:%c\n", i+1,arr[i]);
}
return 0;
}
11.3 字符串常量的方式来对一维字符数组进行初始化
在C语言中没有专门的数据类型来定义 字符串 ,因此我们是将字符串作为字符数组来处理的,字符串中的字符是逐个存放到数组元素中的。
11.3.1 不指定长度初始化
在对一维字符数组进行定义和初始化的过程中,可以不指定其长度:
#include<stdio.h>
int main() {
int i;
/*
这里使用的一维数组初始化方式:
对数组全部元素赋值,但不指定长度,
但注意的是这是数组的长度不是3,而是4,
因为我们在将字符串存入数组的时候会默认在末尾加上一个 \0 字符
即以这种初始化方式对字符串进行存储会以 \0 作为数组的结束标志
*/
char arr[] = "abc";
// sizeof(arr) / sizeof(arr[0] 结果是 4
for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("打印第%d个字符:%c\n", i + 1, arr[i]);
}
return 0;
}

为了测定字符串的实际长度,C语言规定了一个“字符串结束标志”,以字符‘\0’作为结束标志。
我们可以进行一个对比:
#include<stdio.h>
int main()
{
/*
这里使用的一维数组初始化方式:
对数组全部元素赋值,但不指定长度
*/
char arr[] = { 'g','i','r','l' };
/*
1.char brr[] = { "girl" };
2.char brr[] = "girl";
加不加括号都可以,一样的
*/
char brr[] = { "girl" };
/*
比较一下数组内存大小:
1. sizeof(arr)的值是 1 * 4 = 4
2.在将 "girl" 赋值给 brr 时会将这四个字母因此存入数组,
同时在末尾还会追加一个 \0 字符,作为该数组结束的标志
因此 sizeof(brr)的值是 1 * (4 + 1) = 5
*/
printf("arr 数组占用内存:%lld\n", sizeof(arr));
printf("brr 数组占用内存:%lld", sizeof(brr));
return 0;
}
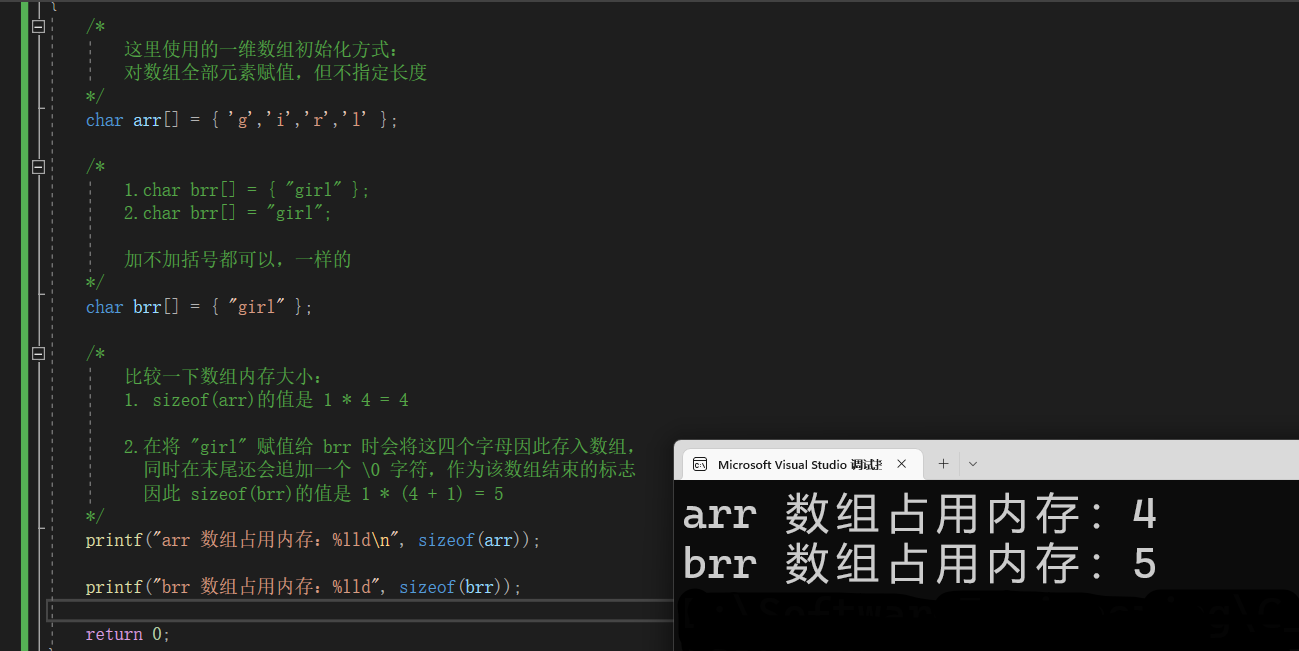
💬 采用这两种方式得到的数组长度并不相同,在采用字符串常量对字符数组进行初始化的过程中,在内存中进行存储时会自动在字符串的后面添加一个结束符‘\0’,所以得到的字符数组长度是字符串常量的长度加1;而采用字符常量列表的方式对字符数组进行初始化就不会在最后添加一个结束符,所以利用这种方式定义的字符数组的长度就是字符常量列表中字符的个数。
11.3.2 完全初始化
#include<stdio.h>
int main() {
int i;
/*
数组的长度是4,
由于规定了arr数组的长度为4,并且字符串常量的长度也是4,
因此数组就没有空间在字符串最后追加 \0 了
*/
char arr[4] = "girl";
// sizeof(arr) / sizeof(arr[0] 结果是 4
for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("打印第%d个字符:%c\n", i + 1, arr[i]);
}
return 0;
}

11.3.3 未完全初始化
#include<stdio.h>
int main() {
int i;
/*
数组的长度是10,
由于规定了arr数组的长度为10,而字符串常量的长度也是4,
因此数组其它部分都为 \0
*/
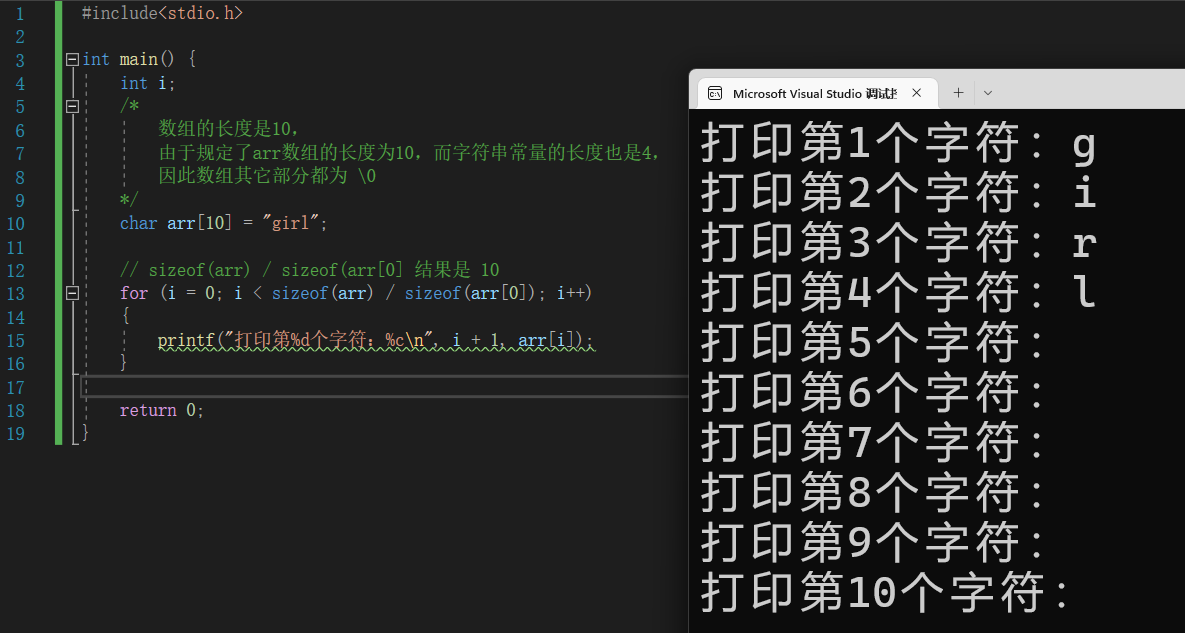
char arr[10] = "girl";
// sizeof(arr) / sizeof(arr[0] 结果是 10
for (i = 0; i < sizeof(arr) / sizeof(arr[0]); i++)
{
printf("打印第%d个字符:%c\n", i + 1, arr[i]);
}
return 0;
}
11.4 C语言字符串处理函数
这些函数都是来自与 <stdio.h> 标准输入输出库,因此在使用这些函数的时候必须引入该库。
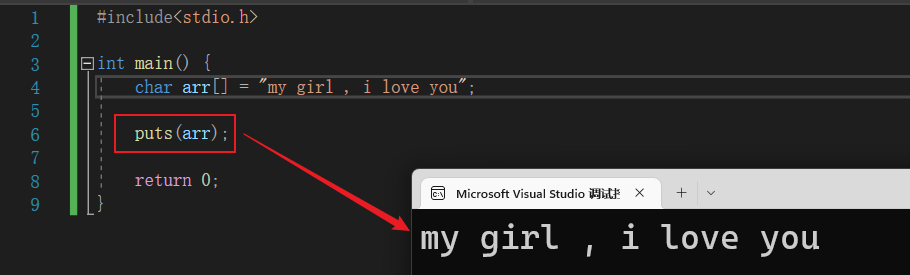
11.4.1 puts函数 - 输出字符串的函数
📍 将一个字符串输出到终端。基本语法:
puts(字符数组)
📝 演示:
#include<stdio.h>
int main() {
char arr[] = "my girl , i love you";
puts(arr);
return 0;
}
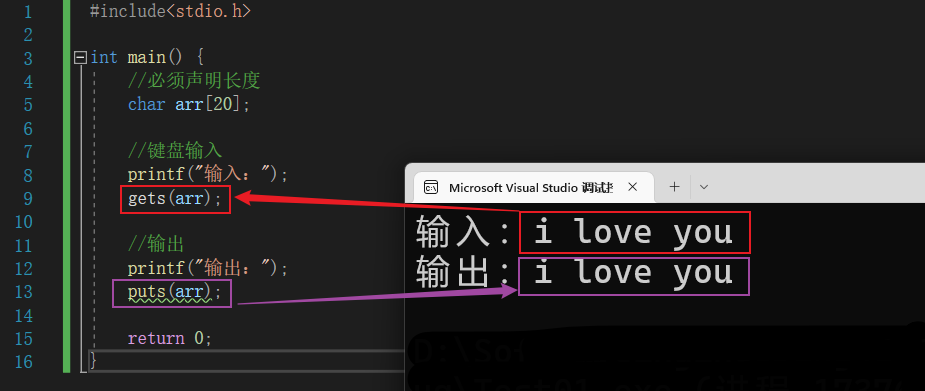
11.4.2 gets函数 - 输入字符串的函数
📍 从终端输入一个字符串到字符数组,并且得到一个函数值。基本语法:
gets(字符数组)
📝 演示:
#include<stdio.h>
int main() {
//必须声明长度
char arr[20];
//键盘输入
printf("输入:");
gets(arr);
//输出
printf("输出:");
puts(arr);
return 0;
}
⚠️ 关于使用 gets() 函数需要注意:使用 gets() 时,系统会将最后“敲”的换行符从缓冲区中取出来,然后丢弃,所以缓冲区中不会遗留换行符。这就意味着,如果前面使用过 gets(),而后面又要从键盘给字符变量赋值的话就不需要吸收回车清空缓冲区了,因为缓冲区的回车已经被 gets() 取出来扔掉了。
11.4.3 strcat函数 - 字符串连接函数
📍 把两个字符数组中的字符串连接起来,把字符串2接到字符串1的后面,结果放在字符数组1中,函数调用后得到一个函数值——字符数组1的地址。基本语法:
strcat(字符数组1,字符数组2)
📝 演示:
#include<stdio.h>
int main() {
//设置arr的长度为40,保证追加时有足够空间
char arr[40] = "my girl ";
char brr[] = "i love you";
//将brr的字符追加到arr数组中
strcat(arr, brr);
puts(arr);
return 0;
}

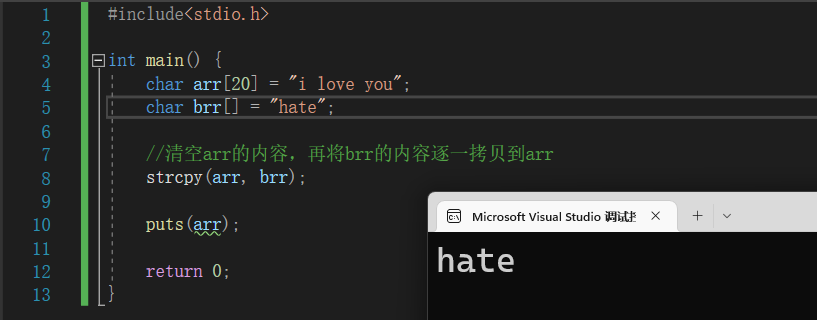
11.4.4 strcpy - 字符串复制函数
📍 将字符数组1拷贝到字符数组2中。基本语法:
strcpy(字符数组1,字符串2)
📝 演示:
#include<stdio.h>
int main() {
char arr[20] = "i love you";
char brr[] = "hate";
//清空arr的内容,再将brr的内容逐一拷贝到arr
strcpy(arr, brr);
puts(arr);
return 0;
}
11.4.5 strcmp函数 - 字符串比较函数
📍 比较字符串1和字符串2,将两个字符串自左向右逐个字符相比,直到出现不同的字符或遇到“\0”为止。如果全部字符相同,则认为两个字符串相等:若出现不相同的字符,则以第1对不相同的字符的比较结果为准。基本语法:
strcmp(字符串1,字符串2)
📝 演示:
#include<stdio.h>
int main() {
char arr[] = "abc";
char brr[] = "aaa";
//两个数组的第二个字符一个为b,一个为a,
//由于b的ASCII码值大于 a,因此此时结束比较,
//对于 strcmp(字符串1,字符串2),
//如果是 字符串1 大,则返回数字 1
//如果是 字符串2 大,则返回数字 -1
//如果完全相等,返回 0
printf("%d\n\n",strcmp(arr, brr));
printf("%d\n\n", strcmp(brr, arr));
printf("%d\n\n", strcmp(arr, "abc"));
return 0;
}

11.4.6 strlen函数 - 测字符串长度的函数
📍 测试字符串长度的函数。函数的值为字符串中的实际(有效)长度,即在遇到 \0 以前的字符个数。基本语法:
strlen(字符数组)
📝 演示:
#include<stdio.h>
int main() {
char arr[20] = "love";
//有效长度,在 \0 之前的内容
printf("数组有效长度:%d\n\n", strlen(arr));
//数组的内存大小
printf("数组内存大小:%lld", sizeof(arr));
return 0;
}

11.4.7 strupr函数 - 全部转换为大写的函数
📍 将字符串中小写字母换成大写字母。基本语法:
strupr(字符串)
📝 演示:
#include<stdio.h>
int main() {
char arr[20] = "Love";
strupr(arr);
puts(arr);
return 0;
}
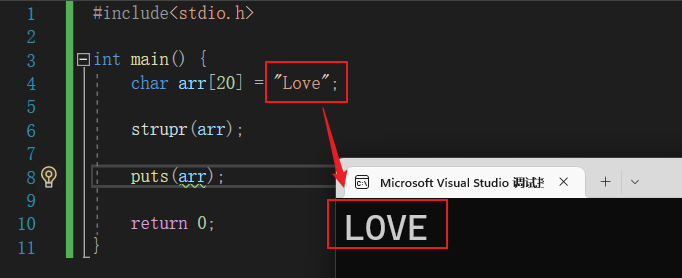
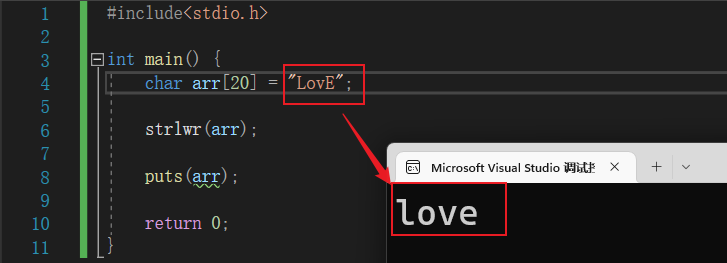
11.4.8 strlwr函数 - 转换为小写的函数
📍 将字符串中小写字母换成小写字母。基本语法:
strlwr(字符串)
📝 演示:
#include<stdio.h>
int main() {
char arr[20] = "LovE";
strlwr(arr);
puts(arr);
return 0;
}
11.5 VS中利用scanf_s函数输入字符串时出错问题解决
在vs中直接使用 scanf_s 输入函数会报错:
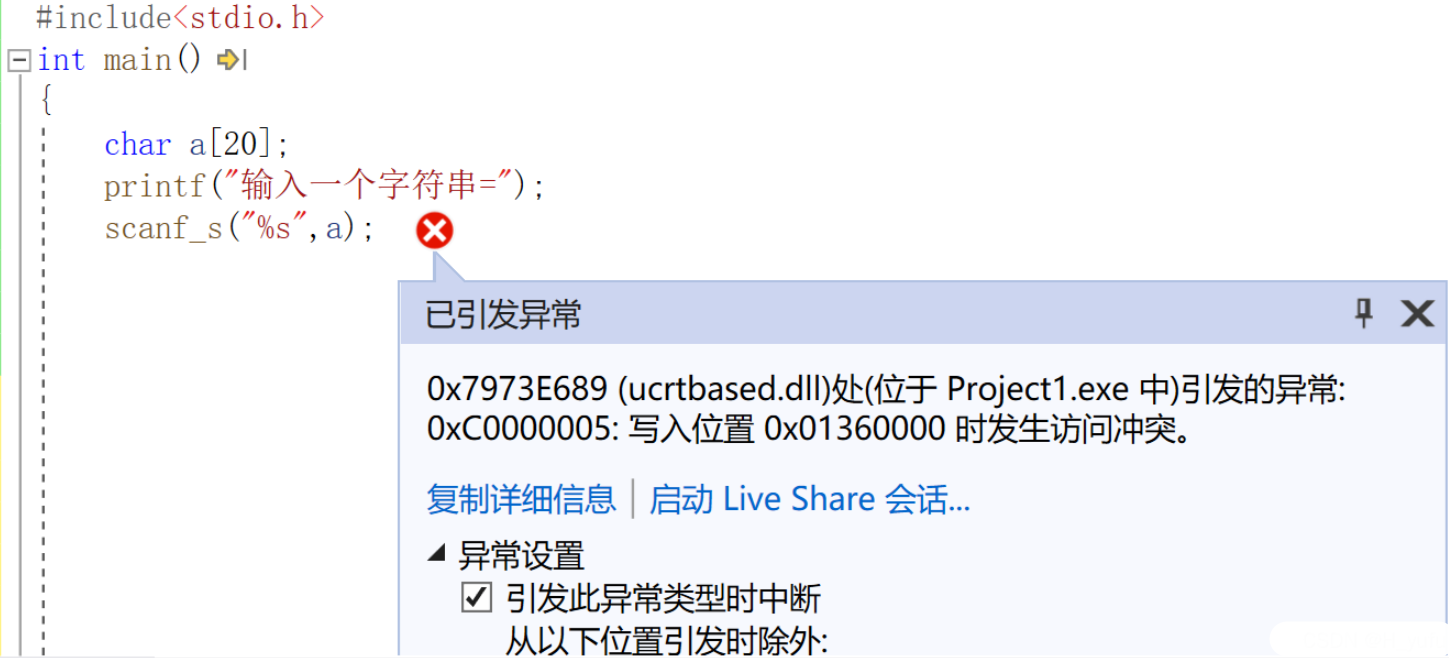
scanf_s函数还需加一个参数 :length参数,限定字符串的长度。若超过length参数将无法输入。
#include<stdio.h>
int main() {
char arr[5];
printf("输入:");
// %s 是字符数组的格式占位符
// sizeof(arr)是告诉编译器应当在缓冲区预留 sizeof(arr) 即5个字节大小的空间输入到arr
// 同时由于这里会默认以 \0 作为字符串的结果,因此我们最多可以输入四个字符,否则报错
scanf_s("%s", arr, sizeof(arr));
printf("\n输出:");
puts(arr);
return 0;
}

11.6 vs中用scanf输入
在代码第一行加入预处理指令:#define _CRT_SECURE_NO_WARNINGS 1
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int main() {
char arr[5];
printf("输入:");
scanf("%s", arr);
printf("\n输出:");
puts(arr);
return 0;
}

11.7 gets() 函数 与 scanf/scanf_s 函数的选择
gets() 函数不仅比 scanf 简洁,而且,就算输入的字符串中有空格也可以直接输入,不用像 scanf 那样要定义多个字符数组。我们来演示一下这个问题:
📝 使用 gets():
#include<stdio.h>
int main() {
char arr[20];
printf("输入:");
gets(arr);
printf("\n输出:");
puts(arr);
return 0;
}
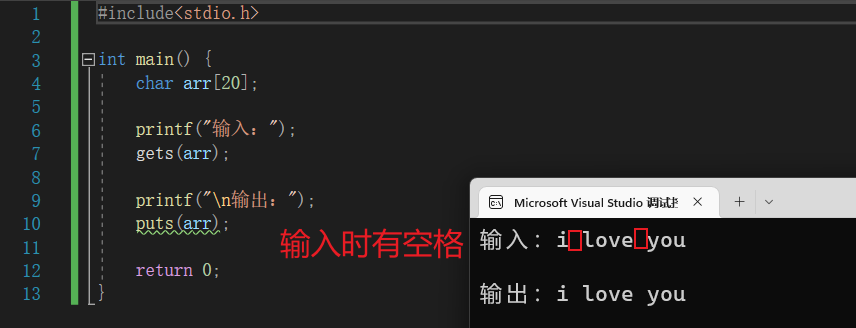
📝 使用 scanf或者scanf_s:
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
int main() {
char arr[20];
printf("输入:");
scanf("%s", arr);
printf("\n输出:");
puts(arr);
return 0;
}

12.数组总结
12.1 数组的定义
元素类型相同,大小相等。
12.2 数组的特点
- 在内存中,数组是一块连续的区域。
- 数组需要预留空间,在使用前要先申请占内存的大小,可能会浪费内存空间。
- 插入数据和删除数据效率低,插入数据时,这个位置后面的数据在内存中都要向后移。
- 随机读取效率很高。因为数组是连续的,知道每一个数据的内存地址,可以直接找到给定地址的数据。
- 并且不利于扩展,数组定义的空间不够时要重新定义数组。
12.3 数组的优缺点
12.3.1 数组的优点
- 随机访问性强
- 查找速度快
12.3.2 数组的缺点
- 插入和删除效率低
- 可能浪费内存
- 内存空间要求高,必须有足够的连续内存空间。
- 数组大小固定,不能动态拓展
13.其他说明
愿你善待自己年轻的皮囊,也愿你拥有不会腐朽的有趣灵魂。我们每个人,不管是否肤白貌美,腰缠万贯,都值得有个人来好好爱你。所以你要加油,等到他或她来的时候,抱紧ta,告诉ta说,等了你好久好久,来了,就别再走了。❤️





![[附源码]计算机毕业设计JAVAjsp医院网上预约系统](https://img-blog.csdnimg.cn/cfb6f48506a04485802299e5b06ed10d.png)
![[Spring MVC6]事务管理与缓存机制](https://img-blog.csdnimg.cn/5ebe162df49141e98c7a455eb8fcfe4f.png)