CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
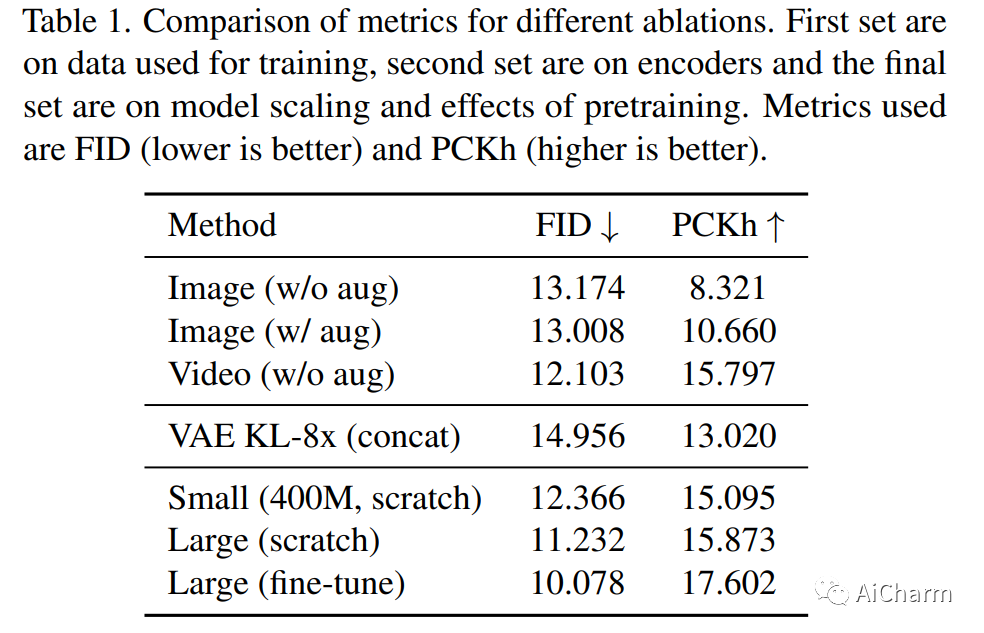
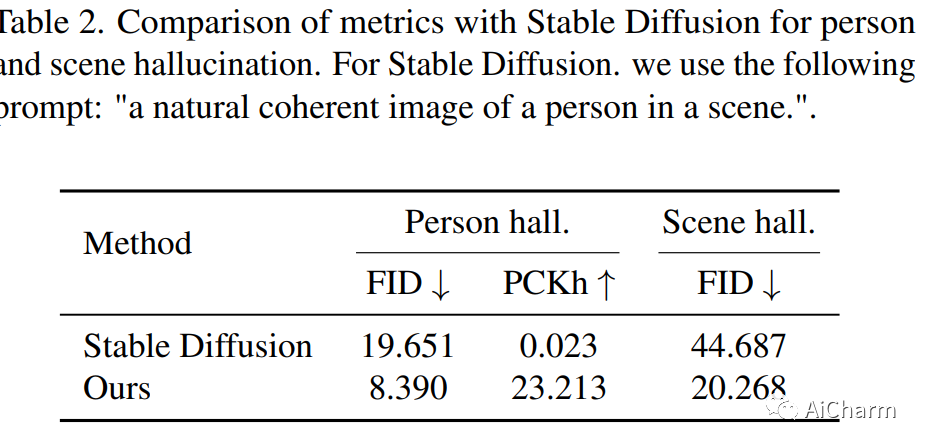
1.Putting People in Their Place: Affordance-Aware Human Insertion into Scenes

标题:把人放在他们的位置:可供感知的人类插入场景
作者:Sumith Kulal, Tim Brooks, Alex Aiken, Jiajun Wu, Jimei Yang, Jingwan Lu, Alexei A. Efros, Krishna Kumar Singh
文章链接:https://arxiv.org/abs/2304.14406
项目代码:https://sumith1896.github.io/affordance-insertion/

摘要:
我们通过提出一种将人物实际插入场景的方法来研究推断场景可供性的问题。给定一个带有标记区域的场景图像和一个人的图像,我们将人插入到场景中,同时尊重场景可供性。我们的模型可以在给定场景上下文的情况下推断出一组逼真的姿势,重新摆出参考人物的姿势,并协调构图。我们通过学习在视频剪辑中重新摆姿势,以自我监督的方式设置任务。我们在 240 万个视频片段的数据集上训练了一个大规模扩散模型,该模型在尊重场景上下文的同时产生不同的合理姿势。鉴于学习到的人景组合,我们的模型还可以在没有条件的情况下在提示时产生真实的人物和场景的幻觉,并且还可以进行交互式编辑。定量评估表明,与之前的工作相比,我们的方法合成了更逼真的人类外观和更自然的人景交互。
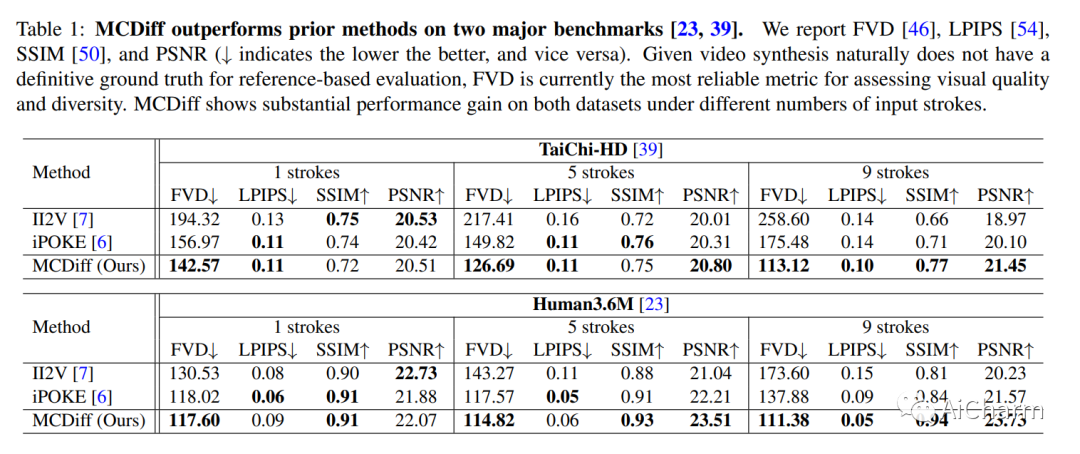
2.Motion-Conditioned Diffusion Model for Controllable Video Synthesis

标题:用于可控视频合成的运动条件扩散模型
作者:Chung-Ching Lin, Jiang Wang, Kun Luo, Kevin Lin, Linjie Li, Lijuan Wang, Zicheng Liu
文章链接:https://arxiv.org/abs/2304.14404
项目代码:https://tsaishien-chen.github.io/MCDiff/



摘要:
扩散模型的最新进展极大地提高了合成内容的质量和多样性。为了利用扩散模型的表达能力,研究人员探索了各种可控机制,使用户能够直观地指导内容合成过程。尽管最近的努力主要集中在视频合成上,但一直缺乏有效的方法来控制和描述所需的内容和动作。为了应对这一差距,我们引入了 MCDiff,这是一种条件扩散模型,它从起始图像帧和一组笔画生成视频,允许用户指定合成的预期内容和动态。为了解决稀疏运动输入的歧义并获得更好的合成质量,MCDiff 首先利用流完成模型基于视频帧的语义理解和稀疏运动控制来预测密集视频运动。然后,扩散模型合成高质量的未来帧以形成输出视频。我们定性和定量地表明,MCDiff 在笔触引导的可控视频合成中实现了最先进的视觉质量。MPII Human Pose 的额外实验进一步展示了我们的模型在不同内容和运动合成方面的能力。
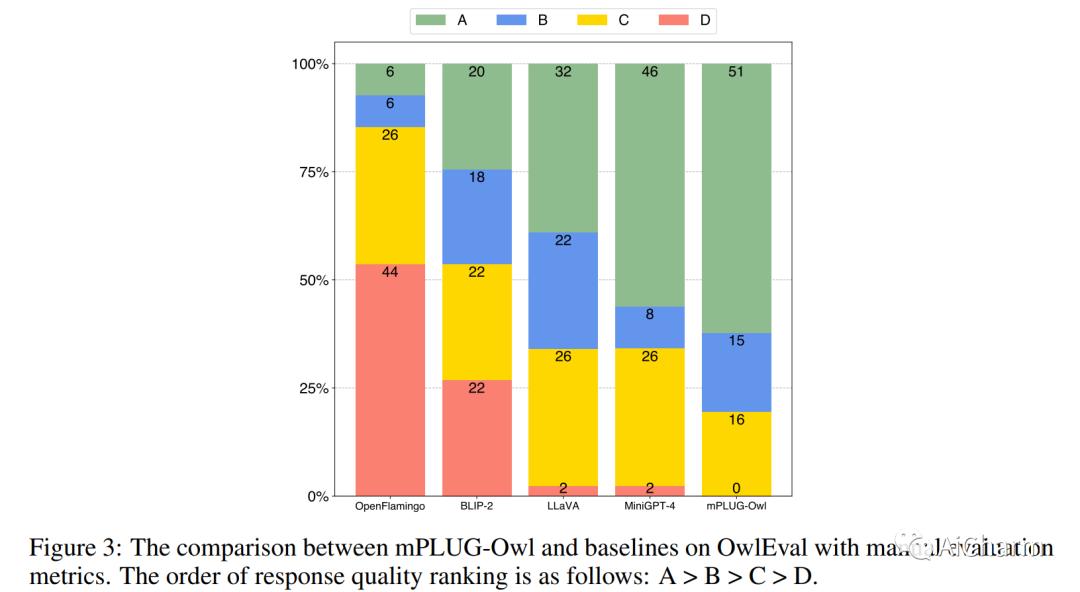
3.mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality

标题:mPLUG-Owl:模块化赋予大型语言模型多模态能力
作者:Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi
文章链接:https://arxiv.org/abs/2304.14178
项目代码:https://www.modelscope.cn/studios/damo/mPLUG-Owl



摘要:
大型语言模型 (LLM) 在各种开放式任务中展示了令人印象深刻的零样本能力,而最近的研究还探索了使用 LLM 进行多模态生成。在这项研究中,我们介绍了 mPLUG-Owl,这是一种新颖的训练范式,通过基础 LLM、视觉知识模块和视觉抽象模块的模块化学习,为 LLM 配备多模态能力。这种方法可以支持多种模态,并通过模态协作促进多样化的单模态和多模态能力。mPLUG-Owl 的训练范式涉及图像和文本对齐的两阶段方法,它在 LLM 的帮助下学习视觉知识,同时保持甚至提高 LLM 的生成能力。在第一阶段,视觉知识模块和抽象模块使用冻结的 LLM 模块进行训练,以对齐图像和文本。在第二阶段,使用纯语言和多模态监督数据集通过冻结视觉知识模块联合微调 LLM 上的低秩适应 (LoRA) 模块和抽象模块。我们精心构建了一个视觉相关的指令评估集 OwlEval。实验结果表明,我们的模型优于现有的多模态模型,展示了 mPLUG-Owl 令人印象深刻的指令和视觉理解能力、多轮对话能力和知识推理能力。此外,我们观察到一些意想不到且令人兴奋的能力,例如多图像关联和场景文本理解,这使得将其用于更难的真实场景(例如仅视觉文档理解)成为可能。我们的代码、预训练模型、指令调整模型和评估集可在这个 https URL 获得。此 https URL 提供在线演示。
更多Ai资讯:公主号AiCharm










![[Gitops--9]微服务项目sangomall代码配置修改及资源清单文件](https://img-blog.csdnimg.cn/99dbb63b55bc47f5ad0a8305568364fe.png)



