本节将编写一个病毒原型,本病毒原型主要由C语言编写,少部分无法由C语言来完成的底层操作采取GCC内嵌汇编的方式实现。
01、原型病毒实现
现在开始介绍实现的细节,提供原型病毒的伪代码以及流程图,并介绍编译感染过程。以实践的方式方便大家了解Linux ELF病毒的原理与概念。
1)设计思想
通过先前一系列的研究分析,得到一个制造实现Linux下感染ELF病毒的方案,逐步分析实现一个具有感染ELF文件能力的Linux病毒原型,并对该病毒进行演示测试研究。
本病毒原型主要由C语言编写,少部分无法由C语言来完成的底层操作采取GCC内嵌汇编的方式实现。
在本次病毒实例的实现程序中,结合了两种常见的传染技术:文本段之后填充区感染和数据段之后感染。选择这两种感染方法是由于它们各有所长,因此必须结合实际的可执行文件来判断使用那种感染方法进行感染才能够优势互补并且消除每种感染方法的缺陷。
目前实现的病毒对两种方法的选择规则是,首先优先使用文本段填充区感染的方法,如果填充区比病毒的体积小,则自动切换到使用数据段之后填充病毒的方法。
关于病毒的架构,该病毒包含两部分,病毒体代码部分以及传染器部分,要在编译完后使用感染器将病毒注入第一个宿主文件,然后执行这个被感染的宿主文件时便会进行文件感染。这个病毒包含的文件有如下几个。
● get_patch.sh:用来修订文件中两个宏定义的bash脚本文件。
● infector.c:感染器程序。
● infector.h:感染器程序的头文件。
● Makefile:Makefile文件。
● virus.c:病毒体的源文件。
● virus.h:病毒体头文件。
设计的大致思想就是先把病毒体编译成目标文件,再编译感染器使其与病毒体链接并包含病毒体,然后用get_patch.sh脚本获取跳转位置和病毒体积来修订每个头文件中的两个宏。再次编译后便是具有感染能力的含有病毒体的感染器了,第一次感染是利用感染器来将病毒体以使用者选择的方式注入到指定的ELF文件中去的。然后执行文件,病毒体先于原宿主代码执行,执行过程中会读取当前目录中的一个合适的可执行文件,然后判断这个文件的文本段和数据段之间是否有足够的填充空间来容纳病毒体,如果有就用文本段填充的方法进行感染,如果没有就利用数据段后面填充病毒的原理进行感染。
总的来说,病毒的设计思路是很简单的,两种感染方法的算法在第三章的内容中有详细的讲述。这里只把最终算法列举一下,病毒体和感染器都可以使用这两种算法进行病毒感染。
2)实现过程
可将本病毒演示分为几个大的模块,首先是第一个宿主感染,即利用感染器的模块,第二个模块是病毒体模块。感染器模块和病毒体模块分别实现,并且利用感染器的头文件里的两个函数声明链接在一起。
在算法实现过程上,可以分为感染算法、目标选择算法和传染方法选择算法。
感染算法有两种,分别是文本段填充感染算法和数据段之后填充感染算法,两种算法的具体介绍可以参考第三章的相关内容,这里只列举两种算法的最终描述。
第一种算法是文本段后填充感染,具体步骤如下。
(1) 增加"ELF header"中的 e_shoff增大PAGESIZE大小。
(2) 修正插入代码使其能够跳转到原主体代码的入口点。
(3) 定位文本段程序头:
修改ELF头的入口点地址指向新的入口点(p_vaddr+p_filesz);
增加p_filesz 包含新代码;
增加 p_memsz 包含新代码。
(4) 对于文本段最后一节的shdr:
增大sh_size加上寄生代码的大小。
(5) 对于文本段之后的phdr:
增加 p_offset 加上PAGESIZE大小。
(6) 对于那些因插入寄生代码而影响偏移的每个节的shdr:
增加 sh_offset 加上PAGESIZE大小。
(7) 在文件中物理的插入寄生代码,并且填充到一个页大小。位置处于文本段的p_offset 加上原来的p_filesz的偏移位置。
第二种算法是数据段后填充病毒感染,具体步骤如下。
(1) 修改病毒代码,使病毒代码执行后能够跳转到原来的入口点。
(2) 定位数据段:
修改ELF头中的入口点,指向新的代码,即数据段末尾处(p_vaddr+p_memsz);
修改e_shoff字段指向新的节头表偏移量,即原来的加上加入的病毒大小和bss段大小。
(3) 对于数据段程序头:
增加p_filesz用来包括新的代码和.bss节;
增加p_memsz包含新的代码;
计算.bss节的大小(p_memsz-p_filesz)。
(4) 对于任何一个插入点之后节的节头shdr:
增加sh_offset,增加数值为病毒大小与.bss节大小的和。
(5) 物理地插入病毒代码到文件中:
移动节头表以及其他两个不属于任何段的节。
目标选择算法很简单,就是读取当前目录,然后读取第一个未被感染的可执行ELF文件来感染,没有用到随机算法,这将是本病毒未来的扩展。
▍病毒体流程图
感染方法选择算法也是很简单的,在感染器执行中,对第一个宿主进行感染可以进行手工选择,在病毒体执行过程中,目前实现的病毒对两种方法的选择规则是,首先优先使用文本段填充区感染的方法,如果填充区比病毒的体积小,则自动切换到使用数据段之后填充病毒的方法。可以在以后的设计中增加一个随机函数来随机确定使用哪一种方法进行感染,这样更能提高病毒的隐蔽性和查杀病毒的难度。
3)流程图
这里只介绍病毒体程序的流程图,感染器程序流程图与病毒体流程图类似,只是可以自定义感染方法而已,在此不做介绍。
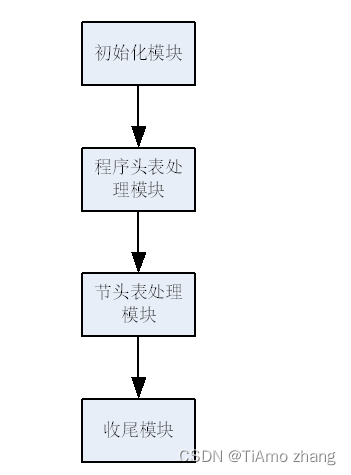
病毒体程序实现可以分为四个模块,分别为初始化模块、程序头表处理模块、节头表处理模块以及收尾模块。如下图所示。
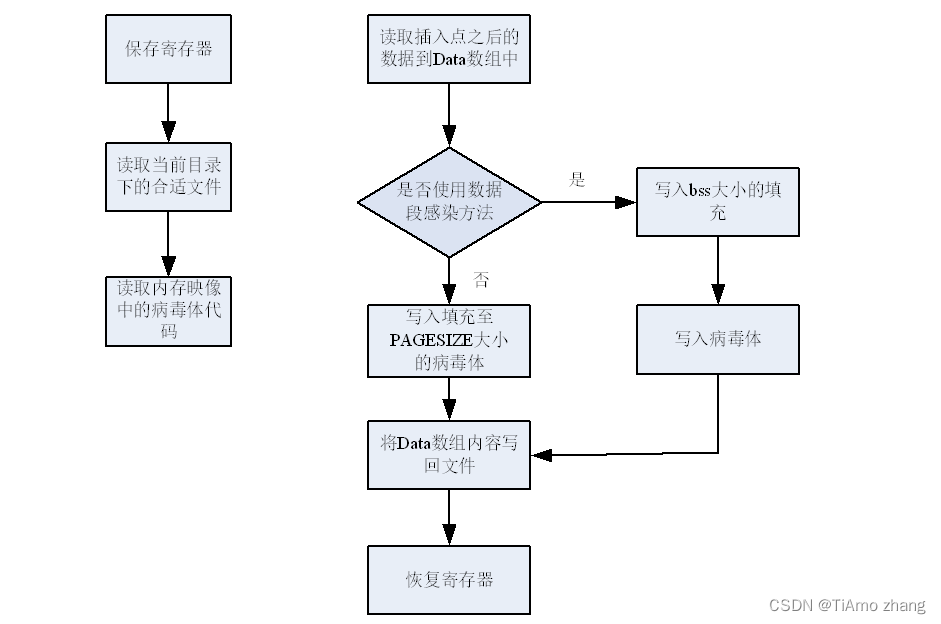
▍初始模块和收尾模块流程图
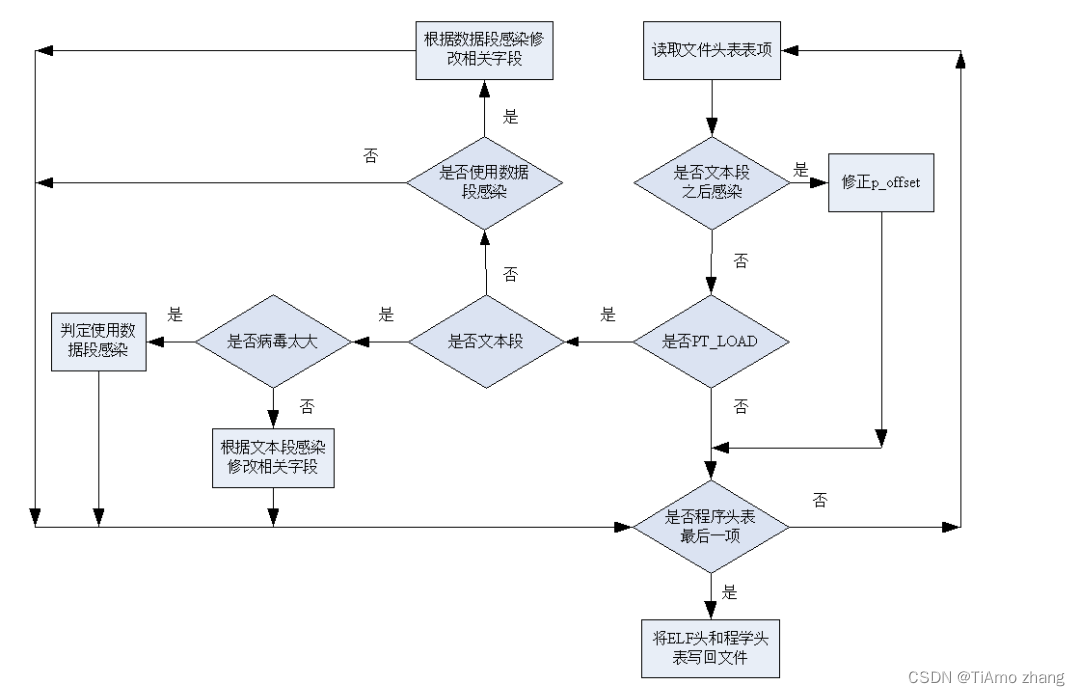
▍程序头表处理模块流程图
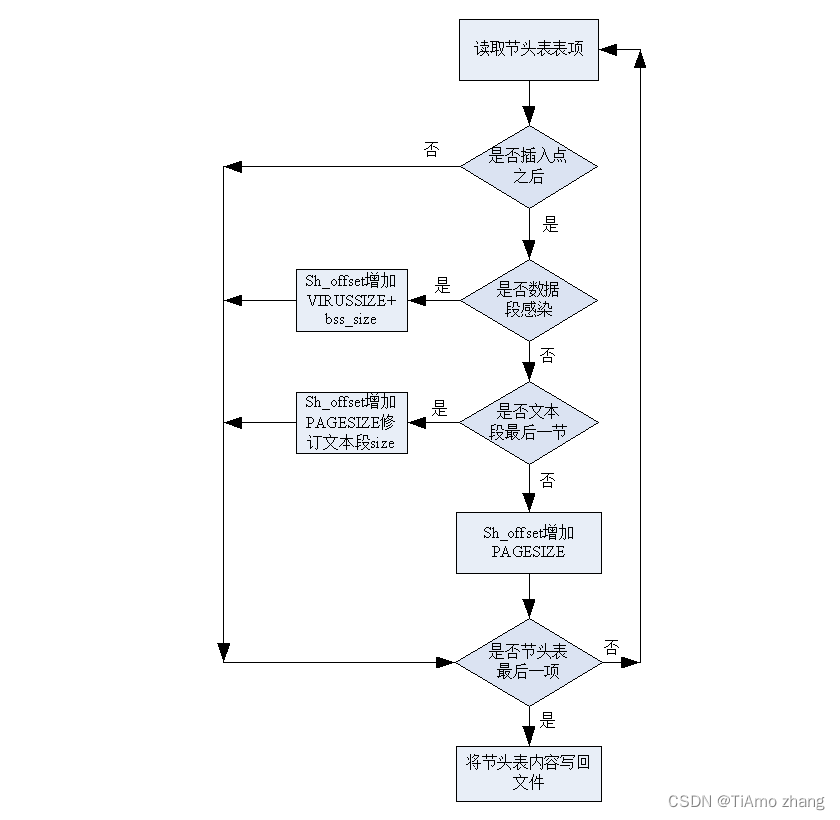
▍节头表处理模块流程图
4)实现过程的伪代码说明
void virus(void)
{
__asm__ volatile ( 保存寄存器信息,即保存除去esp以外其他7个通用寄存器);
打开当前目录“.”,准备读取当前目录下文件信息
__asm__ volatile (获取病毒体的起始虚拟地址);
读取当前目录第一个文件
while(循环检查当前文件是否为未被感染的可执行ELF文件)
{
if(是) break;
else
读取下一个文件信息
}
<病毒体演示打印的内容>
读取文件ELF头
char Virus[PAGESIZE];
利用memcpy获得病毒,存入数组Virus中
修订病毒体使其能够跳转到原来的入口点
处理程序头表
for(循环读取程序头表中表项)
{
if(如果为文本段之后的段并且使用文本段后填充方法感染)
{
p_offset增大PAGESIZE大小;
}
else if(类型为PT_LOAD)
{
if(是数据段且使用数据段之后插入方法感染)
{
根据该感染算法修改ELF头以及数据段程序头中的各种相关信息
}
else if(为文本段)
{
if (病毒体太大了超过可填充大小)
{
使用数据段感染方法
}
else
{
使用文本段后填充感染方法
根据该感染算法修改ELF头以及文本段程序头中的各种相关信息
}
}
}
读取下一个段的程序头
}
分别将ELF头和程序头表写回文件
处理节头表
for(循环读取节头表中表项)
{
if (插入点之后各节)
{
if(使用数据段感染)
{
sh_offset增大(VIRUS_SIZE+bss_size);
}
else if(使用文本段填充感染)
{
if(文本段最后一节)
{
修订该节头字段sh_size
}
else
sh_offset 增大PAGESIZE大小;
}
}
读取下一个节头表项;
}
节头表写回文件
获取文件大小
读取插入点之后内容到Data数组中
if(使用数据段感染方法)
{
写入.bss大小的填充,然后写入病毒体
}
else
{
写入病毒体并填充至PAGESIZE大小
}
将Data数组内容写回文件
out: __asm__ volatile (恢复寄存器内容并设置跳转指令);
}
void virus_end(void){virus();}标志病毒体结束的函数,用来修复VIRUS_SIZE宏定义。
5)感染过程实例
完成了所有编程工作后就需要对病毒体进行实例测试了,看是否完成预期的目标。
在一个新的环境中,编译病毒体的过程是很简单的,基本上需要修订的工作都由bash脚本完成。
在病毒体源码所在工作目录下,编译过程如下。
(1) 执行命令make all。
(2) 执行命令chmod a+x ./get_patch.sh。
(3) 执行命令./get_patch.sh。
(4) 执行命令make clean && make all。
上述一系列命令都被写入脚本install.sh,所以可以选择执行./install.sh就可以得到含有病毒体的感染器ELF可执行文件infect。关于get_patch.sh脚本中完成的工作主要是对两个宏定义进行修订,因为不同的环境不同的编译器会导致这两个宏定义不同的,所以需要每次单独修订,然后再重新编译。进行编译过程如下图所示。

▍编译过程
测试过程:由于本病毒并没有什么实际危害,只是一个演示版本,所以感染后的宿主表现为在打印自身的输出结果前先打印ELF三个字母。
宿主文件病毒首先使用infect进行感染,复制/bin/df 到当前的目录,并进行两个复制,分别复制为text1和data1两个文件,分别进行对文本段填充感染和数据段后感染。
可以发现两个文件text1和data1都已经被成功感染。注意当执行这两个被感染文件时,当前目录将会有文件被感染。有可能是文件text1,要视当前目录内可执行文件名称而定。
创建测试目录test1,并向test1目录中复制/bin/df,以及text1文件,执行text1,并观察df是否被文本段填充方式感染。
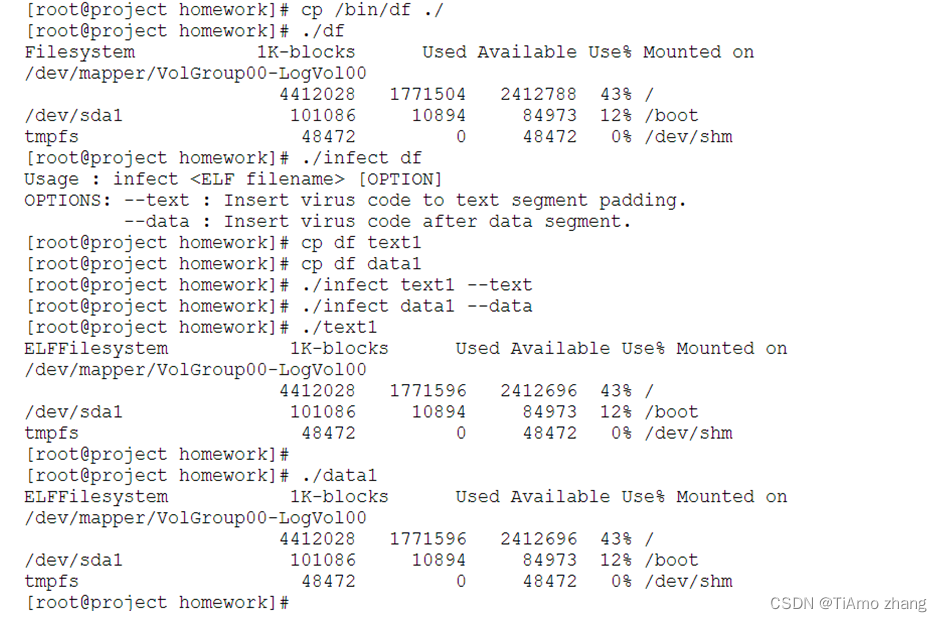
▍感染器测试
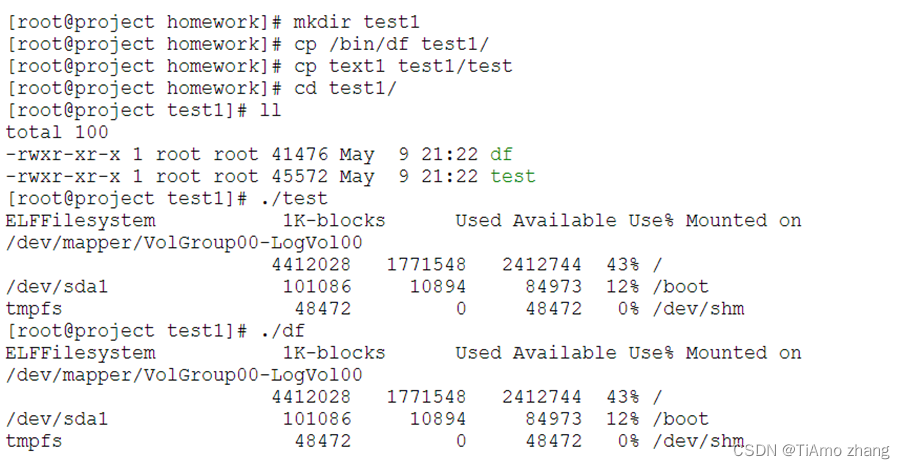
▍文本段感染测试
发现df已经被感染,对比df感染前后的数据段信息,可以发现数据段的偏移量增大了0x1000大小,说明感染方法是文本段后填充感染。

▍验证文本段感染
创建测试目录test2,并向test2目录中复制/bin/ls,以及data1文件,执行data1,并观察文本段后填充不足以包含病毒体的ls文件是否被数据段后感染方式感染。
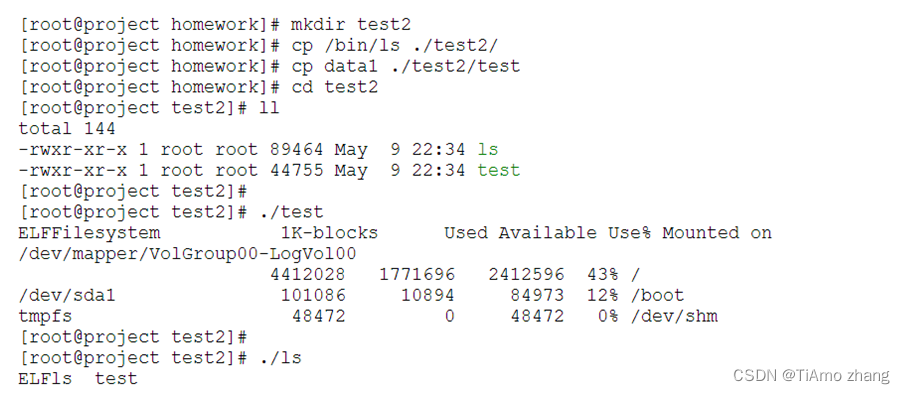
▍数据段感染测试
如果说明ls已经被感染了,对比ls文件感染前后数据段和文本段信息,发现数据段偏移并没有改变,只是数据段的大小改变了,所以说明是数据段后填充方法进行的感染。
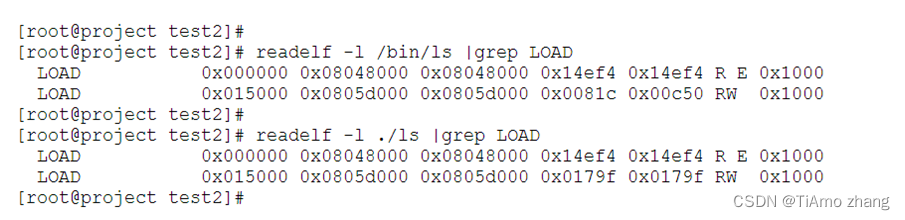
▍验证数据段感染
02、病毒源码
链接: https://pan.baidu.com/s/1Xnqrhljw_1OOKnreAtCTqQ?pwd=x249 提取码: x249
温馨提示:本文章代码仅作为学习使用,无传播网络病毒之意,望周知!



![windows下Ubuntu保姆级安装教程 [附VMware资源]](https://img-blog.csdnimg.cn/45d82d890f154f76b51780f8d6524666.png)