【图像分割】【深度学习】SAM官方Pytorch代码-各功能模块解析
Segment Anything:建立了迄今为止最大的分割数据集,在1100万张图像上有超过1亿个掩码,模型的设计和训练是灵活的,其重要的特点是Zero-shot(零样本迁移性)转移到新的图像分布和任务,一个图像分割新的任务、模型和数据集。SAM由三个部分组成:一个强大的图像编码器(Image encoder)计算图像嵌入,一个提示编码器(Prompt encoder)嵌入提示,然后将两个信息源组合在一个轻量级掩码解码器(Mask decoder)中来预测分割掩码。本博客将大致讲解SAM各模块的功能。
文章目录
- 【图像分割】【深度学习】SAM官方Pytorch代码-各功能模块解析
- 前言
- 模型加载
- SamPredictor类
- __init__
- reset_image
- set_image
- set_torch_image
- predict
- predict_torch
- get_image_embedding
- device
- ResizeLongestSide类
- __init__
- apply_image
- apply_coords
- apply_boxes
- get_preprocess_shape
- 总结
前言
在详细解析SAM代码之前,首要任务是成功运行SAM代码【win10下参考教程】,后续学习才有意义。本博客将大致讲解各个子模块的功能代码,暂时不会详细讲解神经网络的代码部分。
模型加载
博主以【SAM官方代码示例】为例,源码提供了3种不同大小的模型。
# 选择合适的模型以及加载对应权重
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
sam_model_registry函数在segment_anything/build_sam.py文件内定义
SAM的3种模型通过字典形式保存。
sam_model_registry = {
"default": build_sam_vit_h,
"vit_h": build_sam_vit_h,
"vit_l": build_sam_vit_l,
"vit_b": build_sam_vit_b,
}
sam_model_registry中的3种模型结构是一致的,部分参数不同导致模型的大小有别。
def build_sam_vit_h(checkpoint=None):
return _build_sam(
encoder_embed_dim=1280,
encoder_depth=32,
encoder_num_heads=16,
encoder_global_attn_indexes=[7, 15, 23, 31],
checkpoint=checkpoint,
)
def build_sam_vit_l(checkpoint=None):
return _build_sam(
encoder_embed_dim=1024,
encoder_depth=24,
encoder_num_heads=16,
encoder_global_attn_indexes=[5, 11, 17, 23],
checkpoint=checkpoint,
)
def build_sam_vit_b(checkpoint=None):
return _build_sam(
encoder_embed_dim=768,
encoder_depth=12,
encoder_num_heads=12,
encoder_global_attn_indexes=[2, 5, 8, 11],
checkpoint=checkpoint,
)
最后是_build_sam方法,完成了sam模型的初始化以及权重的加载,这里可以注意到sam模型由三个神经网络模块组成:ImageEncoderViT(Image encoder)、PromptEncoder和MaskDecoder。具体的参数的作用和意义在后续的神经网络的具体的学习中讲解。
def _build_sam(
encoder_embed_dim,
encoder_depth,
encoder_num_heads,
encoder_global_attn_indexes,
checkpoint=None,
):
prompt_embed_dim = 256
image_size = 1024
vit_patch_size = 16
image_embedding_size = image_size // vit_patch_size
sam = Sam(
image_encoder=ImageEncoderViT(
depth=encoder_depth,
embed_dim=encoder_embed_dim,
img_size=image_size,
mlp_ratio=4,
norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
num_heads=encoder_num_heads,
patch_size=vit_patch_size,
qkv_bias=True,
use_rel_pos=True,
global_attn_indexes=encoder_global_attn_indexes,
window_size=14,
out_chans=prompt_embed_dim,
),
prompt_encoder=PromptEncoder(
embed_dim=prompt_embed_dim,
image_embedding_size=(image_embedding_size, image_embedding_size),
input_image_size=(image_size, image_size),
mask_in_chans=16,
),
mask_decoder=MaskDecoder(
num_multimask_outputs=3,
transformer=TwoWayTransformer(
depth=2,
embedding_dim=prompt_embed_dim,
mlp_dim=2048,
num_heads=8,
),
transformer_dim=prompt_embed_dim,
iou_head_depth=3,
iou_head_hidden_dim=256,
),
pixel_mean=[123.675, 116.28, 103.53],
pixel_std=[58.395, 57.12, 57.375],
)
sam.eval()
if checkpoint is not None:
with open(checkpoint, "rb") as f:
state_dict = torch.load(f)
sam.load_state_dict(state_dict)
return sam
论文中SAM的结构示意图:

SamPredictor类
sam模型被封装在SamPredictor类的对象中,方便使用。
predictor = SamPredictor(sam)
predictor.set_image(image)
image_encoder操作在set_image时就已经执行了,而不是在predic时
SamPredictor类在segment_anything/predictor.py文件:
init
初始化了mask预测模型sam,以及数据处理工具对象,重置了图片相关数据信息(ResizeLongestSide)。
def __init__(
self,
sam_model: Sam,
) -> None:
super().__init__()
# sam mask预测模型
self.model = sam_model
# 用于数据预处理
self.transform = ResizeLongestSide(sam_model.image_encoder.img_size)
# 图片相关数据信息
self.reset_image()
reset_image
self.is_image_set与 self.features息息相关,self.features保存图片经过Image encoder后的特征数据,self.is_image_set是一个信号信息,用来表示self.features是否已经保存了特征数据,在刚初始化时,self.features是none,self.is_image_set便是false。
def reset_image(self) -> None:
# 图像设置flag
self.is_image_set = False
# 图像编码特征
self.features = None
self.orig_h = None
self.orig_w = None
self.input_h = None
self.input_w = None
set_image
首先确认输入是否是RGB或BGR三通道图像,将BGR图像统一为RGB,而后并对图像尺寸(apply_image)和channel顺序作出调整满足神经网络的输入要求。
def set_image(
self,
image: np.ndarray,
image_format: str = "RGB",
) -> None:
# 图像不是['RGB', 'BGR']格式则报错
assert image_format in [
"RGB",
"BGR",
], f"image_format must be in ['RGB', 'BGR'], is {image_format}."
# H,W,C
if image_format != self.model.image_format:
image = image[..., ::-1] # H,W,C中 C通道的逆序RGB-->BGR
# Transform the image to the form expected by the model 改变图像尺寸
input_image = self.transform.apply_image(image)
# torch 浅拷贝 转tensor
input_image_torch = torch.as_tensor(input_image, device=self.device)
# permute H,W,C-->C,H,W
# contiguous 连续内存
# [None, :, :, :] C,H,W -->1,C,H,W
input_image_torch = input_image_torch.permute(2, 0, 1).contiguous()[None, :, :, :]
self.set_torch_image(input_image_torch, image.shape[:2])
set_torch_image
用padding填补缩放后的图片,在H和W满足神经网络需要的标准尺寸,而后通过image_encoder模型获得图像特征数据并保存在self.features中,同时self.is_image_set设为true。
注意image_encoder过程不是在predict_torch时与Prompt encoder过程和Mask decoder过程一同执行的,而是在set_image时就已经执行了。
def set_torch_image(
self,
transformed_image: torch.Tensor,
original_image_size: Tuple[int, ...],
) -> None:
# 满足输入是四个维度且为B,C,H,W
assert (
len(transformed_image.shape) == 4
and transformed_image.shape[1] == 3
and max(*transformed_image.shape[2:]) == self.model.image_encoder.img_size
), f"set_torch_image input must be BCHW with long side {self.model.image_encoder.img_size}."
self.reset_image()
# 原始图像的尺寸
self.original_size = original_image_size
# torch图像的尺寸
self.input_size = tuple(transformed_image.shape[-2:])
# torch图像进行padding
input_image = self.model.preprocess(transformed_image)
# image_encoder网络模块对图像进行编码
self.features = self.model.image_encoder(input_image)
# 图像设置flag
self.is_image_set = True
这里可以暂时不考虑image_encoder模型的代码细节。
predict
predict对输入到模型中进行预测的数据(标记点apply_coords和标记框apply_boxes)进行一个预处理,并接受和处理模型返回的预测结果。
def predict(
self,
# 标记点的坐标
point_coords: Optional[np.ndarray] = None,
# 标记点的标签
point_labels: Optional[np.ndarray] = None,
# 标记框的坐标
box: Optional[np.ndarray] = None,
# 输入的mask
mask_input: Optional[np.ndarray] = None,
# 输出多个mask供选择
multimask_output: bool = True,
# ture 返回掩码logits, false返回阈值处理的二进制掩码。
return_logits: bool = False,
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
# 假设没有设置图像,报错
if not self.is_image_set:
raise RuntimeError("An image must be set with .set_image(...) before mask prediction.")
# Transform input prompts
# 输入提示转换为torch
coords_torch, labels_torch, box_torch, mask_input_torch = None, None, None, None
if point_coords is not None:
# 标记点坐标对应的标记点标签不能为空
assert (
point_labels is not None
), "point_labels must be supplied if point_coords is supplied."
# 图像改变了原始尺寸,所以对应的点位置也会发生改变
point_coords = self.transform.apply_coords(point_coords, self.original_size)
# 标记点坐标和标记点标签 np-->tensor
coords_torch = torch.as_tensor(point_coords, dtype=torch.float, device=self.device)
labels_torch = torch.as_tensor(point_labels, dtype=torch.int, device=self.device)
# 增加维度
# coords_torch:N,2-->1,N,2
# labels_torch: N-->1,N
coords_torch, labels_torch = coords_torch[None, :, :], labels_torch[None, :]
if box is not None:
# 图像改变了原始尺寸,所以对应的框坐标位置也会发生改变
box = self.transform.apply_boxes(box, self.original_size)
# 标记框坐标 np-->tensor
box_torch = torch.as_tensor(box, dtype=torch.float, device=self.device)
# 增加维度 N,4-->1,N,4
box_torch = box_torch[None, :]
if mask_input is not None:
# mask np-->tensor
mask_input_torch = torch.as_tensor(mask_input, dtype=torch.float, device=self.device)
# 增加维度 1,H,W-->B,1,H,W
mask_input_torch = mask_input_torch[None, :, :, :]
# 输入数据预处理完毕,可以输入到网络中
masks, iou_predictions, low_res_masks = self.predict_torch(
coords_torch,
labels_torch,
box_torch,
mask_input_torch,
multimask_output,
return_logits=return_logits,
)
# 因为batchsize为1,压缩维度
# mask
masks = masks[0].detach().cpu().numpy()
# score
iou_predictions = iou_predictions[0].detach().cpu().numpy()
low_res_masks = low_res_masks[0].detach().cpu().numpy()
return masks, iou_predictions, low_res_masks
源码在segment_anything/modeling/sam.py内
def postprocess_masks(
self,
masks: torch.Tensor,
input_size: Tuple[int, ...],
original_size: Tuple[int, ...],
) -> torch.Tensor:
# mask上采样到与输入到模型中的图片尺寸一致
masks = F.interpolate(
masks,
(self.image_encoder.img_size, self.image_encoder.img_size),
mode="bilinear",
align_corners=False,
)
masks = masks[..., : input_size[0], : input_size[1]]
# mask resize 到与未做处理的原始图片尺寸一致
masks = F.interpolate(masks, original_size, mode="bilinear", align_corners=False)
return masks
predict_torch
输入数据经过预处理后输入到模型中预测结果。
Prompt encoder过程和Mask decoder过程是在predict_torch时执行的。
def predict_torch(
self,
point_coords: Optional[torch.Tensor],
point_labels: Optional[torch.Tensor],
boxes: Optional[torch.Tensor] = None,
mask_input: Optional[torch.Tensor] = None,
multimask_output: bool = True,
return_logits: bool = False,
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
# 假设没有设置图像,报错
if not self.is_image_set:
raise RuntimeError("An image must be set with .set_image(...) before mask prediction.")
# 绑定标记点和标记点标签
if point_coords is not None:
points = (point_coords, point_labels)
else:
points = None
# ----- EPrompt encoder -----
sparse_embeddings, dense_embeddings = self.model.prompt_encoder(
points=points,
boxes=boxes,
masks=mask_input,
)
# ----- Prompt encoder -----
# ----- Mask decoder -----
low_res_masks, iou_predictions = self.model.mask_decoder(
image_embeddings=self.features,
image_pe=self.model.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
# ----- Mask decoder -----
# 上采样mask掩膜到原始图片尺寸
# Upscale the masks to the original image resolution
masks = self.model.postprocess_masks(low_res_masks, self.input_size, self.original_size)
if not return_logits:
masks = masks > self.model.mask_threshold
return masks, iou_predictions, low_res_masks
这里可以暂时不考虑Prompt encoder和Mask decoder模型的代码细节。
get_image_embedding
获得图像image_encoder的特征。
def get_image_embedding(self) -> torch.Tensor:
if not self.is_image_set:
raise RuntimeError(
"An image must be set with .set_image(...) to generate an embedding."
)
assert self.features is not None, "Features must exist if an image has been set."
return self.features
device
获得模型所使用的设备
def device(self) -> torch.device:
return self.model.device
ResizeLongestSide类
ResizeLongestSide是专门用来处理图片、标记点和标记框的工具类。
ResizeLongestSide类在segment_anything/utils/transforms.py文件:
init
设置了所有输入到神经网络的标准图片尺寸
def __init__(self, target_length: int) -> None:
self.target_length = target_length
apply_image
原图尺寸根据标准尺寸计算调整(get_preprocess_shape)得新尺寸。
def apply_image(self, image: np.ndarray) -> np.ndarray:
target_size = self.get_preprocess_shape(image.shape[0], image.shape[1], self.target_length)
# to_pil_image将numpy装变为PIL.Image,而后resize
return np.array(resize(to_pil_image(image), target_size))
一个简单的示意图,通过计算获得与标准尺寸对应的缩放比例并缩放图片,后续通过padding补零操作(虚线部分),将所有图片的尺寸都变成标准尺寸。
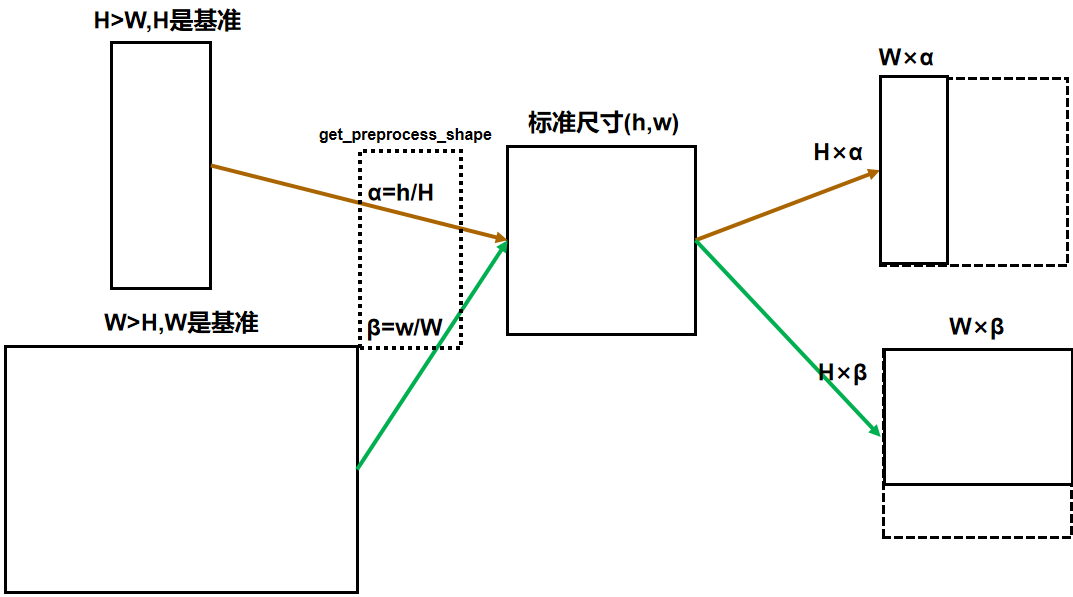
不直接使用resize的目的是为了不破坏原图片中各个物体的比例关系。
apply_coords
图像改变了原始尺寸,对应的标记点坐标位置也要改变([get_preprocess_shape](#get_preprocess_shape))。
def apply_coords(self, coords: np.ndarray, original_size: Tuple[int, ...]) -> np.ndarray:
old_h, old_w = original_size
# 图像改变了原始尺寸,所以对应的标记点坐标位置也会发生改变
new_h, new_w = self.get_preprocess_shape(
original_size[0], original_size[1], self.target_length
)
# 深拷贝coords
coords = deepcopy(coords).astype(float)
# 改变对应标记点坐标
coords[..., 0] = coords[..., 0] * (new_w / old_w)
coords[..., 1] = coords[..., 1] * (new_h / old_h)
return coords
apply_boxes
图像改变了原始尺寸,对应的标记框坐标位置也要改变([get_preprocess_shape](#get_preprocess_shape))。
def apply_boxes(self, boxes: np.ndarray, original_size: Tuple[int, ...]) -> np.ndarray:
# 图像改变了原始尺寸,所以对应的框坐标位置也会发生改变
# reshape: N,4-->N,2,2
boxes = self.apply_coords(boxes.reshape(-1, 2, 2), original_size)
# reshape: N,2,2-->N,4
return boxes.reshape(-1, 4)
get_preprocess_shape
def get_preprocess_shape(oldh: int, oldw: int, long_side_length: int) -> Tuple[int, int]:
# H和W的长边(大值)作为基准,计算比例,缩放H W的大小
scale = long_side_length * 1.0 / max(oldh, oldw)
newh, neww = oldh * scale, oldw * scale
# 四舍五入
neww = int(neww + 0.5)
newh = int(newh + 0.5)
return (newh, neww)
总结
尽可能简单、详细的介绍SAM中各个子模块的功能代码,后续会讲解SAM中三个深度学习网络模块的代码。
强调一点,在预测过程中sam模型是被封装在SamPredictor类中,将sam的forward预测的流程分别拆解到SamPredictor类的不同方法中、分不同阶段进行。
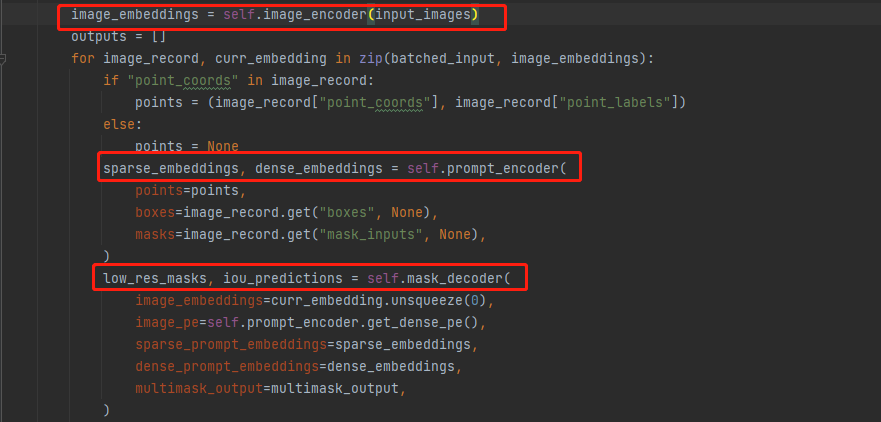
sam中forward函数对Image encoder、Prompt encoder和Mask decoder三个操作是连续的,如下图所示:
源码暂未开源这部分,因此个人自觉forward只是训练过程中使用的,预测过程并未涉及,希望大家不要被搞晕,最后有大佬自己写train部分的代码话可以踢我一下。






![[LeetCode周赛复盘] 第 343 场周赛20230430](https://img-blog.csdnimg.cn/46ea90ad5f0f409e8ae4b116f78b6c80.png)