🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
介绍
循环神经网络
RNN 的应用
RNN 是如何工作的?
序列数据的输入和目标
练习 6.01:为序列数据问题创建输入变量和目标变量
PyTorch 中的循环神经网络
活动 6.01:使用简单的 RNN 进行时间序列预测
长短期记忆网络
LSTM 网络的应用
LSTM 网络如何工作?
PyTorch 中的 LSTM 网络
预处理输入数据
编号标签
生成批次
One-Hot编码
练习 6.02:预处理输入数据并创建一个单热矩阵
构建架构
训练模型
执行预测
活动6.02:文字生成与 LSTM 网络
自然语言处理
情绪分析
PyTorch 中的情感分析
预处理输入数据
构建架构
训练模型
活动 6.03:执行用于情感分析的 NLP
概括
本章扩展了递归神经网络的概念。您将了解循环神经网络( RNN ) 的学习过程以及它们如何存储记忆。本章将介绍长短期记忆( LSTM ) 网络架构,它使用短期和长期记忆来解决使用数据序列的数据问题。到本章结束时,您将牢牢掌握 RNN 以及如何解决自然语言处理( NLP ) 数据问题。
介绍
在前面的章节中,解释了不同的网络架构——从可以同时解决分类和回归问题的传统 ANN,到主要用于通过执行对象分类、定位、检测和分割任务来解决计算机视觉问题的 CNN .
在最后一章中,我们将探讨 RNN 的概念并解决时序数据问题。这些网络架构能够处理上下文至关重要的顺序数据,这要归功于它们能够保存来自先前预测的信息,这称为记忆。这意味着,例如,当逐字分析句子时,RNN 能够在处理最后一个单词时保留有关句子第一个单词的信息。
本章将探讨 LSTM 网络架构,这是一种可以同时保存长期和短期记忆的 RNN,特别适用于处理长序列数据,例如视频剪辑。
本章还将探讨 NLP 的概念。NLP 是指计算机与人类语言的交互,由于提供定制客户服务的虚拟助手的兴起,这是当今的热门话题。本章将使用 NLP 进行情感分析,包括分析句子背后的含义。这有助于根据客户评论了解客户对产品或服务的看法。
循环神经网络
正如人类不会每秒钟都重新设置他们的思维一样,旨在理解人类语言的神经网络也不应该这样做。这意味着为了理解段落甚至整本书中的每个词,您或模型需要理解前面的词,这有助于为可能具有不同含义的词提供上下文。
正如我们目前所讨论的,传统的神经网络无法执行此类任务——因此产生了 RNN 的概念和网络架构。正如我们之前简要解释的那样,这些网络架构包含不同节点之间的循环。这允许信息在模型中保留更长时间。因此,模型的输出既是预测又是记忆,当下一位序列文本通过模型时将使用它们。
这个概念可以追溯到 1980 年代,尽管它最近才流行起来,这要归功于技术的进步导致机器计算能力的提高,并允许重新收集数据,以及概念的发展1990 年代的 LSTM RNN,增加了它们的应用。RNN 是最有前途的网络架构之一,这要归功于它们存储内部记忆的能力,这使它们能够有效地处理数据序列并解决各种各样的数据问题。
RNN 的应用
虽然我们已经非常清楚地表明 RNN 最适合处理文本、音频剪辑和视频等数据序列,但仍然有必要解释 RNN 在实际问题中的不同应用。
以下是对可以通过使用 RNN 执行的不同任务的一些简要说明:
- NLP:这是指机器代表人类语言的能力。这可能是深度学习中探索最多的领域之一,并且无疑是使用 RNN 时首选的数据问题。这个想法是使用文本作为输入数据(例如诗歌和书籍等)来训练网络,目的是创建一个能够生成此类文本的模型。
NLP 通常用于创建聊天机器人(虚拟助手)。通过从以前的人类对话中学习,NLP 模型能够帮助人们解决常见问题或疑问。据此,他们造句的能力仅限于他们在训练过程中学到的东西,这意味着他们只能回答他们所学的内容。
当您尝试通过在线聊天系统联系银行时,您可能会遇到这种情况,通常,在查询超出常规范围的那一刻,您就会被转移到人工操作员那里。现实生活中聊天机器人的另一个常见示例是通过 Facebook Messenger 接受查询的餐厅:

图 6.1:Facebook 的 Messenger 聊天机器人
- 语音识别:与 NLP 类似,语音识别试图理解和表示人类语言。然而,这里的区别在于前者(NLP)以文本形式进行训练并产生输出,而后者(语音识别)使用音频片段。随着该领域发展的激增和大公司的兴趣,这些模型能够理解不同的语言,甚至不同的口音和发音。
语音识别设备的一个流行示例是 Alexa——来自亚马逊的声控虚拟助手模型:

图 6.2:亚马逊的 Alexa
- 机器翻译:这是指机器有效翻译人类语言的能力。据此,输入是源语言(例如西班牙语),输出是目标语言(例如英语)。NLP 和机器翻译之间的主要区别在于,在后者中,输出是在将整个输入输入到模型后构建的。
随着当今全球化的兴起和休闲旅游的流行,人们需要使用一种以上的语言。因此,出现了能够在不同语言之间进行翻译的设备激增。这一领域的最新成果之一是谷歌的 Pixel Buds,它可以实时进行翻译:

图 6.3:Google 的 Pixel Buds
- 时间序列预测:RNN 不太流行的应用是根据历史数据预测未来的一系列数据点。RNN 特别擅长这项任务,因为它们能够保留内部记忆,这使得时间序列分析可以考虑过去的不同时间步长,以执行一个预测或对未来的一系列预测。
这通常用于预测未来的收入或需求,这有助于公司为不同的情况做好准备。下图显示了每月销售额的预测:
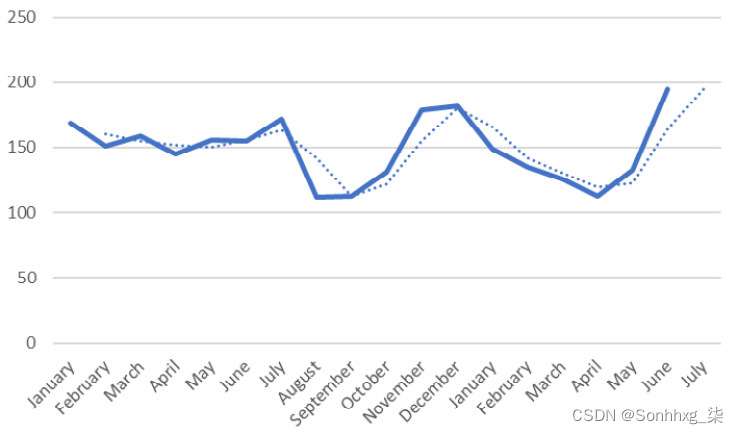
图 6.4:每月销售额(数量)的预测
例如,如果通过预测几种保健产品的需求,确定其中一种产品的需求将增加而另一种产品的需求将减少,公司可能会决定生产更多该产品,并且少了另一个。
- 图像识别:与 CNN 相结合,RNN 可以为图像提供标题或描述。这种模型组合允许您检测图像中的所有对象,从而确定图像的主要成分。输出可以是图像中存在的对象的一组标签、图像的描述或图像中相关对象的标题,如下图所示:

图 6.5:使用 RNN 进行图像识别
RNN 是如何工作的?
简而言之,RNN 接受输入 (x) 并返回输出 (y)。在这里,输出不仅受输入的影响,还受过去输入的整个历史记录的影响。这种输入历史通常被称为模型的内部状态或记忆,它们是遵循顺序并相互关联的数据序列——例如时间序列,它是一系列数据点(例如,销售) 按顺序列出(例如,按月)。
笔记
请记住,RNN 的一般结构可能会有所不同,具体取决于手头的问题。例如,它们可以是一对多类型或多对一类型,正如我们在第 2 章神经网络的构建块中提到的那样。
要理解 RNN 的概念,重要的是要了解 RNN 与传统神经网络之间的区别。传统的神经网络通常被称为前馈神经网络,因为信息只在一个方向上移动(即从输入到输出),而不会经过一个节点两次来进行预测。这些网络对过去输入的内容没有任何记忆,这就是为什么它们不擅长预测序列中接下来会发生什么。
另一方面,在 RNN 中,信息在循环中循环,因此每次预测都是通过考虑先前预测的输入和记忆来做出的。它的工作原理是复制每个预测的输出并将其传回网络以进行后续预测。这样,RNN 有两个输入——现值和过去的信息:

图 6.6:网络的图形表示,其中 A 显示前馈神经网络,B 显示 RNN
笔记
传统 RNN 的内部记忆只是短期的。但是,稍后我们将探索一种能够存储长期和短期记忆的架构。
通过使用来自先前预测的信息,网络使用一系列有序数据进行训练,使其能够预测后续步骤。这是通过将当前信息和上一步的输出组合成一个操作来实现的。这可以在下图中看到。此操作的输出将成为预测,以及后续预测的部分输入:

图 6.7:每个预测的 RNN 计算
如您所见,节点内部发生的操作与任何其他神经网络的操作相同;最初,数据通过线性函数传递。权重和偏差是训练过程中要更新的参数。接下来,使用激活函数打破此输出的线性。在这种情况下,这是tanh函数,因为多项研究表明它对大多数排序数据问题都取得了更好的结果:
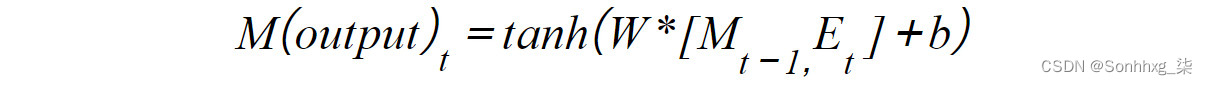
图 6.8:传统 RNN 的数学计算
这里,M t-1是指从之前的预测中导出的记忆,W和b是权重和偏差,E t是指当前事件。
记住这个学习过程,让我们考虑一下过去 2 年的产品销售数据。RNN 能够预测下个月的销售额,因为通过存储过去几个月的信息,它们能够检查销售额是在增加还是在减少。
使用图 6.7,下个月的预测可以通过获取上个月的销售额(即当前事件)和短期记忆(这是过去几个月的数据表示)并结合来处理他们。该操作的输出将包含下个月的预测和过去几个月的一些相关信息,这些信息将成为后续预测的新短期记忆。
此外,值得一提的是,一些 RNN 架构,例如 LSTM 网络,也将能够考虑 2 年前甚至更早的数据(因为它存储长期记忆)。这将使网络知道特定月份的减少是可能继续减少还是开始增加。稍后我们将更详细地探讨这个主题。
序列数据的输入和目标
考虑到目标是预测序列中的后续元素,目标矩阵通常是与输入数据相同的信息,目标是领先一步。
这意味着输入变量应该包含序列的所有数据点,除了最后一个值,而目标变量应该包含序列的所有数据点,除了第一个值——也就是第一个值目标变量应该是输入变量的第二个,以此类推,如下图所示:
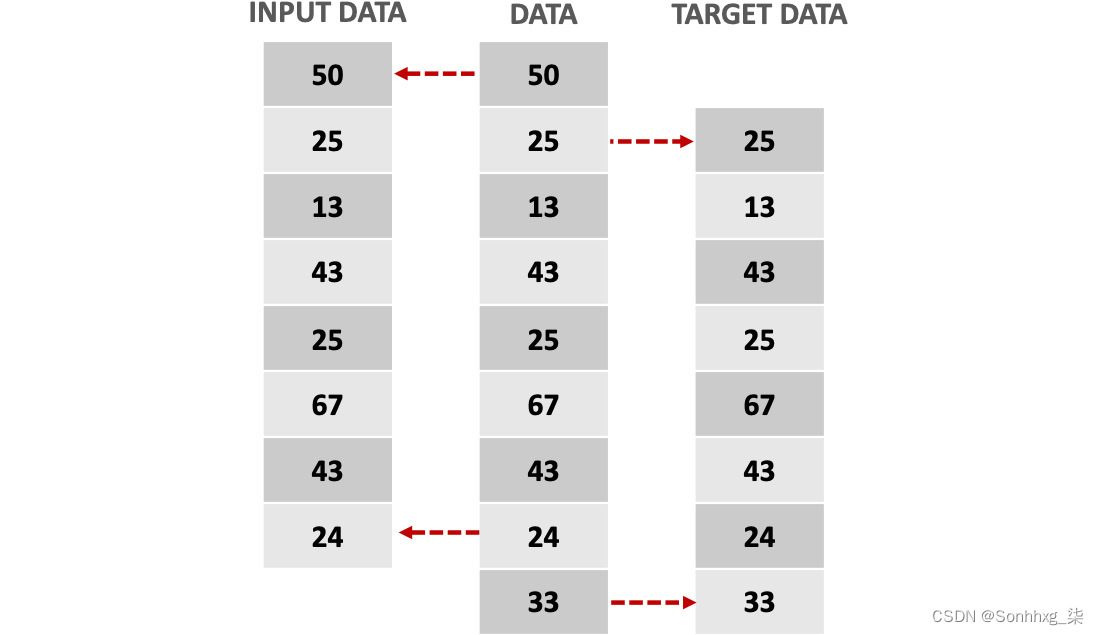
图 6.9:序列数据问题的输入和目标变量
练习 6.01:为序列数据问题创建输入变量和目标变量
在本练习中,您将使用虚拟数据集学习如何创建可用于解决序列数据问题的输入和目标变量。请按照以下步骤完成此练习:
笔记
对于本章中的练习和活动,您需要在本地计算机上安装 Python 3.7、Jupyter 6.0、Matplotlib 3.1、NumPy 1.17、Pandas 0.25 和 PyTorch 1.3+(最好是 PyTorch 1.4)。
- 导入以下库:
import pandas as pd import numpy as np import torch - 创建一个大小为 10 x 5 的 Pandas DataFrame,填充 0 到 100 之间的随机数。将五列命名如下:["Week1", "Week2", "Week3", "Week4", "Week5"]。
确保将随机种子设置为0,以便能够重现本书中显示的结果:
np.random.seed(0) data = pd.DataFrame(np.random.randint(0,100,size=(10, 5)), columns=['Week1','Week2','Week3',\ 'Week4','Week5']) data笔记
提醒一下,在 Jupyter Notebooks 中可以打印变量的值而不需要 print 函数。在其他编程平台上,您可能需要使用打印功能。
生成的 DataFrame 如下:
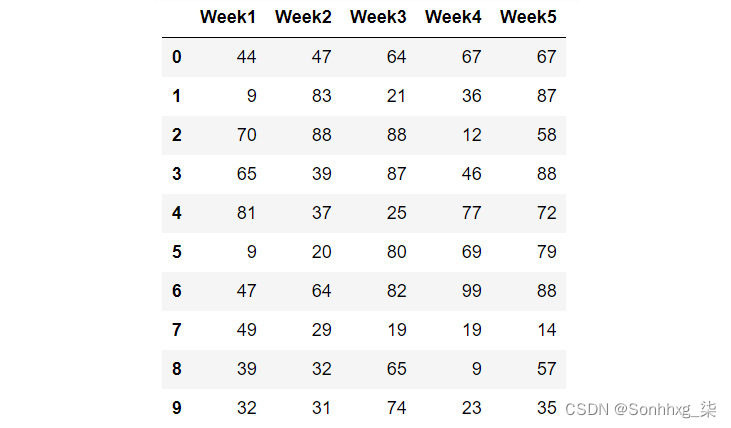
图 6.10:创建的 DataFrame
- 创建一个输入变量和一个目标变量,考虑到输入变量应该包含所有实例的所有值,除了最后一列数据。目标变量应包含所有实例的所有值,第一列除外:
inputs = data.iloc[:,:-1] targets = inputs.shift(-1, axis="columns", \ fill_value=data.iloc[:,-1:]) - 打印输入变量以验证其内容,如下所示:
inputs输入变量应如下所示:

图 6.11:输入变量
- 使用以下代码打印生成的目标变量:
targets运行前面的代码将显示以下输出:
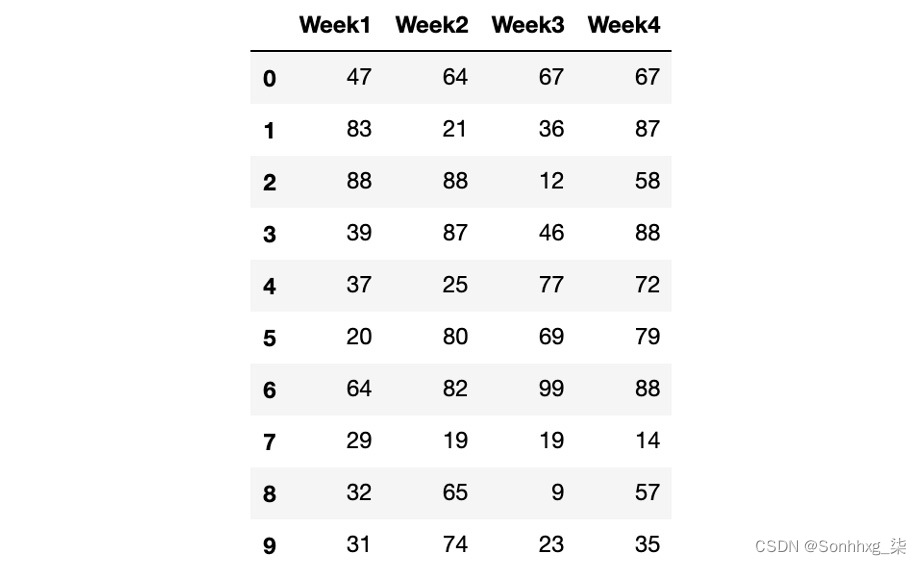
图 6.12:目标变量
PyTorch 中的循环神经网络
在 PyTorch 中,与任何其他层类似,循环层是在一行代码中定义的。这将在网络的转发功能内部调用,如以下代码所示:
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super().__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size, num_layers,\
batch_first=True)
self.output = nn.Linear(hidden_size, 1)
def forward(self, x, hidden):
out, hidden = self.rnn(x, hidden)
out = out.view(-1, self.hidden_size)
out = self.output(out)
return out, hidden在这里,循环层必须定义为接受输入中预期特征数量的参数(input_size);隐藏状态下的特征数量,由用户定义(hidden_size);以及循环层数 ( num_layers )。
笔记
与任何其他神经网络类似,隐藏大小指的是该层中的节点(神经元)数量。
batch_first参数设置为True以定义输入和输出张量采用批次、序列和特征的形式。
在前向函数中,输入通过循环层传递,这些层的输出被拉平,以便可以通过全连接层传递。值得一提的是,信息是通过 RNN 层传递的,还有一个隐藏状态(记忆)。
此外,这种网络的训练可以按如下方式处理:
for i in range(1, epochs+1):
hidden = None
for inputs, targets in batches:
pred, hidden = model(inputs, hidden)
loss = loss_function(pred, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()对于每个时期,隐藏状态都被初始化为none。这是因为,在每个时期,网络将尝试将输入映射到目标(当给定一组参数时)。这种映射应该在没有任何偏见(隐藏状态)的情况下发生,这与之前通过数据集运行的结果无关。
接下来,使用for循环遍历不同批次的数据。在这个循环中,进行了预测并保存了一个隐藏状态,它将用作下一批次的输入。
最后计算损失函数,用于更新网络的参数。然后,该过程再次开始,直到达到所需的纪元数。
活动 6.01:使用简单的 RNN 进行时间序列预测
对于本活动,您将使用简单的 RNN 来解决时间序列问题。让我们考虑以下场景:您的公司希望能够提前预测其所有产品的需求。这是因为生产每件产品都需要相当长的时间,而且这个过程要花很多钱。因此,他们不希望在生产上花费金钱和时间,除非产品很可能被出售。为了预测未来的需求,他们为您提供了一个数据集,其中包含去年销售的所有产品的每周需求(在销售交易中)。按照以下步骤完成此活动:
笔记
可以在https://packt.live/2K5pQQK找到包含将在本活动中使用的数据集的 CSV 文件。它也可以在UCI Machine Learning Repository: Sales_Transactions_Dataset_Weekly Data Set在线获得。
数据集和相关分析首次发布于此处:Tan SC, Lau JPS (2014) Time Series Clustering: A Superior Alternative for Market Basket Analysis。载于:Herawan T.、Deris M.、Abawajy J.(编)第一届高级数据和信息工程国际会议论文集 (DaEng-2013)。电气工程讲义,第 285 卷。Springer,新加坡。
- 导入所需的库。
- 加载数据集并将其切片,使其包含所有行,但仅包含从索引 1 到 52 的列。
- 绘制从整个数据集中随机选择的五种产品的每周销售交易。在进行随机抽样时使用随机种子0以获得与当前活动相同的结果。
- 创建输入和目标变量,这些变量将被馈送到网络以创建模型。这些变量应该具有相同的形状并转换为 PyTorch 张量。
输入变量应包含除上周以外所有周内所有产品的数据,因为该模型的想法是预测最后一周。
targets变量应该比inputs变量早一步;也就是说,targets变量的第一个值应该是 inputs 变量的第二个值,依此类推,直到targets变量的最后一个值(应该是留在inputs变量之外的最后一周)。
- 创建一个包含网络架构的类;请注意,全连接层的输出大小应为 1。
- 实例化包含模型的类函数。提供输入大小、每个循环层中的神经元数 (10) 和循环层数 (1)。
- 定义损失函数、优化算法和训练网络的时期数。为此使用均方误差损失函数、Adam 优化器和 10,000 个 epoch。
- 使用for循环遍历所有时期来执行训练过程。在每个时期,必须进行预测,以及随后的损失函数计算和网络参数的优化。然后,保存每个时期的损失。
- 绘制所有时期的损失。
- 使用散点图,显示在训练过程的最后一个时期获得的预测与真实值(即上周的销售交易)的对比。
笔记
可以通过此链接找到此活动的解决方案。
长短期记忆网络
正如我们之前提到的,RNN 仅存储短期记忆。这是处理长数据序列时的一个问题,在这种情况下,网络将难以将信息从较早的步骤传送到最终的步骤。
例如,以著名诗人埃德加·艾伦·坡 (Edgar Alan Poe) 的诗《乌鸦》为例,该诗超过 1,000 字。尝试使用传统的 RNN 来处理它,目的是创作一首类似的相关诗歌,这将导致模型遗漏前几段中的关键信息。反过来,这可能会导致与诗歌的初始主题无关的输出。例如,它可以忽略事件发生在晚上,从而使新诗不那么可怕。
之所以无法保持长期记忆,是因为传统的 RNN 存在梯度消失问题。当用于更新网络参数以最小化损失函数的梯度变得极小以至于它们不再有助于网络的学习过程时,就会发生这种情况。这通常发生在网络的前几层,使网络忘记它刚才看到的内容。
因此,开发了LSTM网络。LSTM 网络可以长时间记住信息,因为它们以类似于计算机的方式存储其内部存储器;也就是说,它们根据需要读取、写入和删除信息,这是通过使用门来实现的。
这些门帮助网络根据它分配给每一位信息的重要性来决定保留哪些信息以及从内存中删除哪些信息(是否打开门)。这是非常有用的,因为它不仅允许存储更多信息(作为长期记忆),而且还有助于丢弃可能改变预测结果的无用信息,例如句子中的冠词。
LSTM 网络的应用
除了我们之前解释的应用之外,LSTM 网络存储长期信息的能力使数据科学家能够处理使用大量数据序列作为输入的复杂数据问题,其中一些将在此处解释:
- 文本生成:生成任何文本,例如您在这里阅读的文本,都可以转换为 LSTM 网络的任务。这是通过根据所有先前的字母选择每个字母来实现的。执行此任务的网络使用大量文本进行训练,例如名著中的文本。这是因为最终模型将创建一个文本,该文本类似于它所训练的文本的写作风格。例如,根据一首诗训练的模型的叙述与您在与邻居对话时所期望的叙述不同。
- 音乐生成:正如可以将文本序列输入网络以生成相似的新文本一样,也可以将音符序列输入网络以生成新的音符序列。跟踪之前的音符将有助于获得和谐的旋律,而不仅仅是一系列随机的音符。例如,将甲壳虫乐队的一首流行歌曲输入一个音频文件将产生一系列类似于乐队和声的音符。
- 手写生成和识别:在这里,每个字母也是所有前面字母的产物,这反过来又会产生一组有意义的手写字母。同样,LSTM 网络也可用于识别手写文本,其中一个字母的预测将取决于之前预测的所有字母。例如,在考虑前面的字母以及整个段落时,识别出难看的手写字母会更容易,因为它有助于根据上下文缩小预测范围。
LSTM 网络如何工作?
到目前为止,已经很清楚 LSTM 网络与传统 RNN 的区别在于它们具有长期记忆的能力。然而,值得一提的是,随着时间的推移,非常旧的信息不太可能影响下一个输出。考虑到这一点,LSTM 网络还能够考虑数据位与底层上下文之间的距离,以便也做出忘记一些不再相关的信息的决定。
那么,LSTM 网络是如何决定什么时候记住什么时候忘记的呢?不同于传统的 RNN,每个节点只执行一次计算,LSTM 网络执行四种不同的计算,允许网络的不同输入(即当前事件、短期记忆和长期记忆)之间进行交互。术语记忆)以得出结果。
要了解 LSTM 网络背后的过程,请考虑用于管理网络中信息的四个门,如下图所示:

图 6.13:LSTM 网络门
上图中每个门的功能可以解释如下:
- 学习门:短期记忆(也称为隐藏状态)和当前事件都进入学习门,在那里分析信息,忽略任何不需要的信息。从数学上讲,这是通过使用线性函数和激活函数 ( tanh )组合短期记忆和当前事件来实现的。其输出乘以一个忽略因子,它会删除所有不相关的信息。为了计算忽略因子,短期记忆和当前事件通过线性函数传递。然后,它们被sigmoid激活函数挤压在一起:
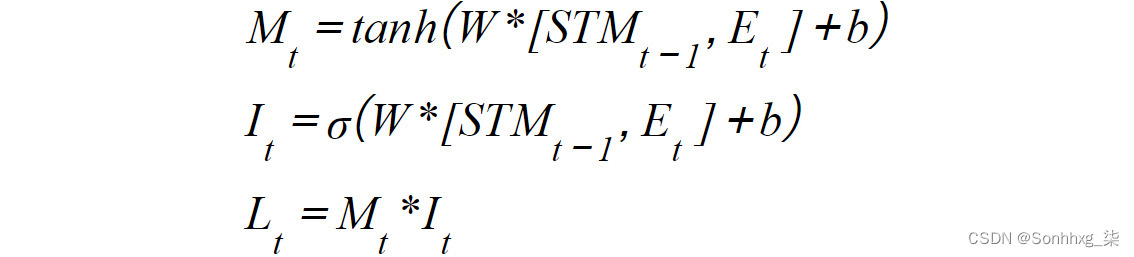
图 6.14:学习门中发生的数学计算
这里,STM t-1是指从先前的预测中导出的短期记忆,W和b是权重和偏差,E t是指当前事件。
- 遗忘门:长期记忆(也称为细胞状态)进入遗忘门,其中一些信息被删除。这是通过将长期记忆和遗忘因子相乘来实现的。为了计算遗忘因子,短期记忆和当前事件通过线性函数和激活函数 ( sigmoid ) 传递:

图 6.15:发生在遗忘门中的数学计算
这里,STM t-1指的是从之前的预测中推导出来的短期记忆,LTM t-1是从之前的预测中推导出来的长期记忆,W和b是权重和偏置,E t指的是当前事件。
- Remember gate:遗忘门中没有被遗忘的长时记忆和learn gate中保留的信息在remember gate中拼接在一起,成为新的长时记忆。从数学上讲,这是通过对学习门和遗忘门的输出求和来实现的:

图 6.16:记忆门中发生的数学计算
这里,L t指的是学习门的输出,而F t指的是遗忘门的输出。
- 使用门:这也称为输出门。在这里,来自学习门和遗忘门的信息在使用门中结合在一起。这个门利用所有相关信息进行预测,这也成为新的短期记忆。
这是通过三个步骤实现的。首先,它将线性函数和激活函数 ( tanh ) 应用于遗忘门的输出。其次,它将线性函数和激活函数 ( sigmoid ) 应用于短期记忆和当前事件。第三,它将前面步骤的输出相乘。第三步的输出将是新的短期记忆和当前步骤的预测:
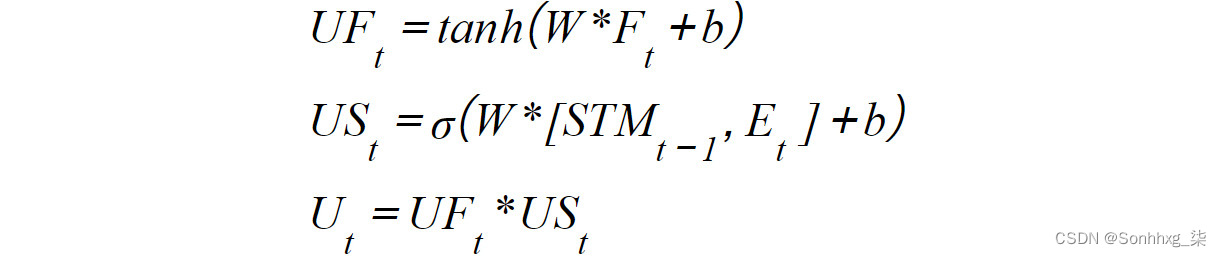
图 6.17:使用门中发生的数学计算
这里,STM t-1是指从先前的预测中导出的短期记忆,W和b是权重和偏差,E t是指当前事件。
笔记
虽然使用不同的激活函数和数学运算符看起来很随意,但这样做是因为它已被证明适用于处理大量数据序列的大多数数据问题。
针对模型执行的每个单独预测完成上述过程。例如,对于为创建文学作品而构建的模型,学习、遗忘、记忆和使用信息的过程是针对模型将产生的每个字母执行的,如下图所示:

图 6.18:一个 LSTM 网络随时间变化的过程
PyTorch 中的 LSTM 网络
在 PyTorch 中定义 LSTM 网络架构的过程类似于我们目前讨论的任何其他神经网络。然而,重要的是要注意,在处理不同于数字序列的数据序列时,需要进行一些预处理,以便为网络提供它可以理解和处理的数据。
考虑到这一点,我们需要解释训练模型以能够将文本数据作为输入并检索新文本数据的一般步骤。值得一提的是,并非此处解释的所有步骤都是严格要求的,但作为一个整体,它们为将 LSTM 与文本数据结合使用提供了干净且可重用的代码。
预处理输入数据
第一步是将文本文件加载到代码中。这些数据将经过一系列转换,以便正确地输入模型。这是必要的,因为神经网络执行一系列数学计算以获得输出,这意味着所有输入都必须是数字。此外,将数据分批提供给模型也是一种很好的做法,而不是一次全部提供,因为它有助于减少训练时间,尤其是对于长数据集。这些转换将在以下小节中解释。
编号标签
首先,从输入数据中获得一个不重复的字符列表。这些字符中的每一个都分配了一个数字。然后,考虑到相同的字母必须始终由相同的数字表示,通过用分配的数字替换每个字符来对输入数据进行编码。例如,给定以下字符和数字映射,单词“hello”将被编码为 12334:
图 6.19:字符与数字的映射
可以通过以下代码片段实现上述输出:
text = "this is a test text!"
chars = list(set(text))
indexer = {char: index for (index, char) \
in enumerate(chars)}
indexed_data = []
for c in text:
indexed_data.append(indexer[c])第二行代码创建一个包含文本字母表(即文本序列中的字母和字符)的列表。接下来,使用每个字母或字符作为键并将与其关联的数字表示作为值来创建字典。最后,通过对文本执行for循环,可以用其数字表示替换每个字母或字符,从而将文本转换为数字矩阵。
生成批次
对于 RNN,使用两个变量创建批次:每批次的序列数和每个序列的长度。这些值用于将数据划分为矩阵,这将有助于加快计算速度。
使用 24 个整数的数据集,每批次的序列数设置为 2,序列长度等于 4,除法工作如下:
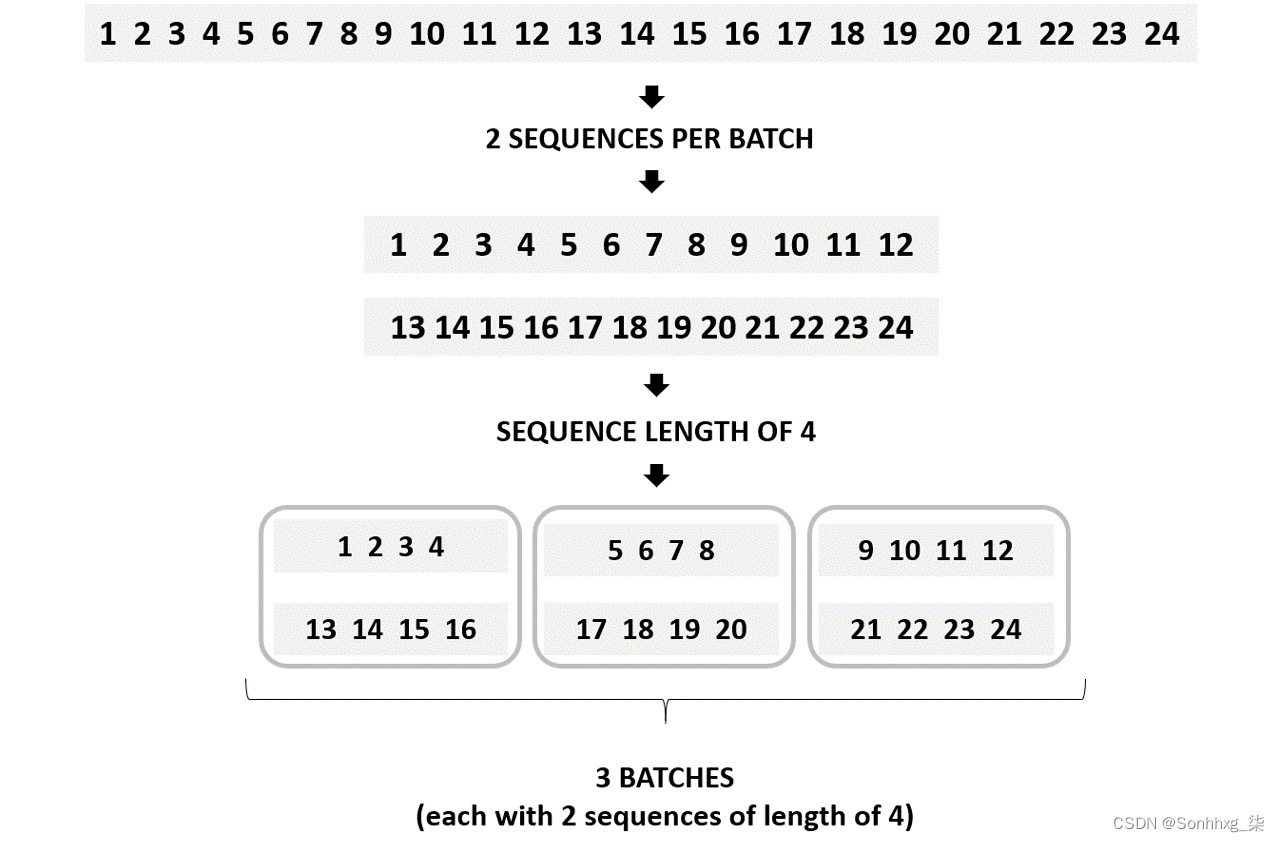
图 6.20:RNN 的批量生成
如上图所示,创建了三个批次——每个批次都包含两个长度为 4 的序列。
这个批量生成过程应该为x和y完成,其中前者是网络的输入,后者代表目标。据此,网络的想法是找到一种方法来映射x和y之间的关系,考虑到y会比x领先一步。
x的批次是按照上图中解释的方法创建的。然后,将创建y的批次,以便它们与x的批次长度相同。这是因为y的第一个元素将是x的第二个元素,依此类推,直到y的最后一个元素(这将是x的第一个元素):
笔记
您可以使用多种不同的方法来填充y的最后一个元素,这里提到的是最常用的方法。方法的选择通常是一个偏好问题,尽管某些数据问题可能从某种方法中比从其他方法中获益更多。

图 6.21:x 和 y 批次的表示
批处理的生成可以通过以下代码片段实现:
x = np.array(indexed_data).reshape((2,-1))
for b in range(0, x.shape[1], 5):
batch = x[:,b:b+5]
print(batch)首先,数字矩阵被分成序列(任意多)。接下来,使用for循环,可以将排序后的数据分成指定长度的批次。通过打印批处理变量,可以观察结果。
笔记
尽管生成批次被认为是数据预处理的一部分,但它通常在训练过程的for循环中进行编程。
One-Hot编码
将所有字符转换为数字不足以将它们输入模型。这是因为这种近似会给您的模型带来一些偏差,因为转换为更高数值的字符将被评估为更重要。为避免这种情况,将不同的批次编码为单热矩阵是一种很好的做法。这包括创建一个包含 0 和 1 的三维矩阵,其中 0 表示不存在事件,1 表示存在事件。矩阵的最终形状应该是one hot = [number of sequences, sequence length, number of characters]。
这意味着,对于批处理中的每个元素,它将创建一个长度等于整个文本中字符总数的值序列。对于每个字符,它都会放置一个零,除了那个位置出现的那个(它会放置一个)。
笔记
您可以在https://www.geeksforgeeks.org/ml-one-hot-encoding-of-datasets-in-python/找到有关单热编码的更多信息。
这可以通过以下代码片段实现:
batch = np.array([[2 4 7 6 5]
[2 1 6 2 5]])
batch_flatten = batch.flatten()
onehot_flat = np.zeros((batch.shape[0] \
* batch.shape[1],len(indexer)))
onehot_flat[range(len(batch_flatten)), batch_flatten] = 1
onehot = onehot_flat.reshape((batch.shape[0],\
batch.shape[1], -1))首先,二维批次被展平。接下来,创建一个矩阵并用零填充。当我们需要在给定位置表示正确的字符时,零被替换为一。最后,再次展开扁平化维度。
练习 6.02:预处理输入数据并创建一个单热矩阵
在本练习中,您将预处理一段文本片段,然后将其转换为单热矩阵。请按照以下步骤完成此练习:
- 导入 NumPy:
import numpy as np - 创建一个名为text的变量,其中将包含文本示例“Hello World!” :
text = "Hello World!" - 通过将每个字母映射到一个数字来创建一个字典:
chars = list(set(text)) indexer = {char: index for (index, char) \ in enumerate(chars)} print(indexer)运行前面的代码将产生以下输出:
{'d': 0, 'o': 1, 'H': 2, ' ': 3, 'e': 4, 'W': 5, '!': 6, 'l': 7, 'r': 8} - 使用我们在上一步中定义的数字对您的文本样本进行编码:
encoded = [] for c in text: encoded.append(indexer[c]) - 将编码变量转换为 NumPy 数组并对其进行整形,以便将句子分成两个大小相同的序列:
encoded = np.array(encoded).reshape(2,-1) encoded运行前面的代码将产生以下输出:
array([[2, 4, 7, 7, 1, 3], [5, 1, 8, 7, 0, 6]]) - 定义一个函数,它接受一个数字数组并创建一个One-hot 矩阵:
def index2onehot(batch): batch_flatten = batch.flatten() onehot_flat = np.zeros((batch.shape[0] \ * batch.shape[1], len(indexer))) onehot_flat[range(len(batch_flatten)), \ batch_flatten] = 1 onehot = onehot_flat.reshape((batch.shape[0], \ batch.shape[1], -1)) return onehot - 通过将编码数组传递给先前定义的函数,将其转换为单热矩阵:
one_hot = index2onehot(encoded) one_hot输出应如下所示:

图 6.22:示例文本的One-hot 表示
您已成功将一些示例文本转换为单热矩阵。
构建架构
与其他神经网络类似,LSTM 层很容易在一行代码中定义。尽管如此,包含网络体系结构的类必须包含一个函数,该函数允许初始化隐藏状态和单元状态(即网络的两个存储器)。一个LSTM网络架构的例子如下:
class LSTM(nn.Module):
def __init__(self, char_length, hidden_size, n_layers):
super().__init__()
self.hidden_size = hidden_size
self.n_layers = n_layers
self.lstm = nn.LSTM(char_length, hidden_size, \
n_layers, batch_first=True)
self.output = nn.Linear(hidden_size, char_length)
def forward(self, x, states):
out, states = self.lstm(x, states)
out = out.contiguous().view(-1, self.hidden_size)
out = self.output(out)
return out, states
def init_states(self, batch_size):
hidden = next(self.parameters()).data.new(self.n_layers, \
batch_size, self.hidden_size).zero_()
cell = next(self.parameters()).data.new(self.n_layers, \
batch_size, self.hidden_size).zero_()
states = (hidden, cell)
return states笔记
同样,当输入和输出张量采用批次、序列和特征的形式时, batch_first参数设置为True 。否则,无需定义它,因为它的默认值为False。
正如我们所见,LSTM 层是在一行中定义的,将以下参数作为参数:
- 输入数据中的特征个数(即不重复的字符个数)
- 隐藏维度(神经元)的数量
- LSTM层数
与任何其他网络一样,前向功能定义了数据在前向传递中通过各层的方式。
最后,定义了一个函数来在每个时期将隐藏状态和单元状态初始化为零。这是通过next(self.parameters()).data.new()实现的,它获取模型的第一个参数并创建一个相同类型的新张量,在括号内具有指定的维度,然后用零填充. 隐藏状态和单元状态都作为元组输入到模型中。
训练模型
一旦定义了损失函数和优化算法,就可以训练模型了。这是通过遵循与用于其他神经网络架构的方法非常相似的方法来实现的,如以下代码片段所示:
# 第一步:for through epochs
for e in range(1, epochs+1):
# 第二步: 内存初始化
states = model.init_states(n_seq)
# 第三步: for循环批量拆分数据。
for b in range(0, x.shape[1], seq_length):
x_batch = x[:,b:b+seq_length]
if b == x.shape[1] - seq_length:
y_batch = x[:,b+1:b+seq_length]
y_batch = np.hstack((y_batch, indexer["."] \
* np.ones((y_batch.shape[0],1))))
else:
y_batch = x[:,b+1:b+seq_length+1]
"""
第四步:将输入数据转换为one-hot矩阵。
输入和目标被转换为张量。
"""
x_onehot = torch.Tensor(index2onehot(x_batch))
y = torch.Tensor(y_batch).view(n_seq * seq_length)
"""
第 5 步:获得预测并执行
反向传播
"""
pred, states = model(x_onehot, states)
loss = loss_function(pred, y.long())
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()如上述代码所示,步骤如下:
- 为了得到更好的模型,有必要多次检查数据——因此,有必要设置多个时期。
- 在每个 epoch 中,必须初始化隐藏状态和单元状态。这是通过调用先前在类中创建的函数来实现的。
- 使用for循环将数据分批输入模型。if语句用于判断是否是最后一批,以便在句末添加一个点,用于表示句号。
- 输入数据被转换成一个单热矩阵。输入和目标都转换为 PyTorch 张量。
- 网络的输出是通过对一批数据调用模型获得的。然后计算损失函数,优化参数。
执行预测
为训练模型提供前几个字符以执行具有某种目的的预测(例如,一段以“从前”一词开头的段落)是一种很好的做法。这些初始字符应该被馈送到模型而不执行任何预测,但目的是生成记忆。接下来,将前一个字符和内存输入网络,并将输出传递给softmax函数,以计算每个字符成为序列中下一个字符的概率。最后从概率较高的字符中随机抽取一个。
这可以通过以下代码片段实现:
# Step 1
starter = "This is the starter text"
states = None
# Step 2
for ch in starter:
x = np.array([[indexer[ch]]])
x = index2onehot(x)
x = torch.Tensor(x)
pred, states = model(x, states)
# Step 3
counter = 0
while starter[-1] != "." and counter < 50:
counter += 1
x = np.array([[indexer[starter[-1]]]])
x = index2onehot(x)
x = torch.Tensor(x)
pred, states = model(x, states)
pred = F.softmax(pred, dim=1)
p, top = pred.topk(10)
p = p.detach().numpy()[0]
top = top.numpy()[0]
index = np.random.choice(top, p=p/p.sum())
# Step 4
starter += chars[index]
print(starter)前面的代码片段中发生了以下步骤:
- 定义了起始句。
- for循环用于将起始句子的每个字符输入模型,以便在进行预测之前更新模型的记忆。
- while循环用于预测新字符,只要字符数不超过 50,直到新字符为句点。
- 每个新字符都添加到起始句子中以形成新的文本序列。
活动6.02:文字生成与 LSTM 网络
笔记
将在本活动中使用的文本数据可以在 Internet 上免费访问,尽管您也可以在本书的 GitHub 存储库中找到它。本章介绍中提到了存储库的 URL。
在此活动中,我们将使用《爱丽丝梦游仙境》一书训练 LSTM 网络,以便我们可以将起始句子输入模型并让它完成句子。考虑以下场景:您喜欢让生活更轻松的事物,并决定构建一个模型来帮助您在撰写电子邮件时完成句子。为此,您决定使用一本流行的儿童读物来训练网络。按照以下步骤完成此活动:
笔记
值得一提的是,虽然此活动中的网络经过足够多的迭代训练以显示不错的结果,但并未对其进行训练和配置以实现最佳性能。我们鼓励您使用它来提高性能。
- 导入所需的库。
- 打开并阅读爱丽丝梦游仙境中的文字到笔记本中。打印前 50 个字符的摘录和文本文件的总长度。
- 创建一个变量,其中包含数据集中未重复字符的列表。然后,创建一个将每个字符映射到一个整数的字典,其中字符将是键,整数将是值。
- 将数据集中的每个字母编码为成对的整数。打印数据集的前 50 个编码字符和编码版本的总长度。
- 创建一个接收批处理并将其编码为单热矩阵的函数。
- 创建一个定义网络架构的类。该类应该包含一个额外的函数来初始化 LSTM 层的状态。
- 确定要从数据集中创建的批次数量,请记住每个批次应包含 100 个序列,每个序列的长度应为 50。接下来,将编码数据拆分为 100 个序列。
- 使用 256 作为总共两个循环层的隐藏单元数来实例化您的模型。
- 定义损失函数和优化算法。使用 Adam 优化器和交叉熵损失。训练网络 20 个时期。
笔记
根据您的资源,训练过程将花费很长时间,这就是为什么建议只运行 20 个 epoch。但是,本书的 GitHub 存储库中提供了可在 GPU 上运行的等效代码版本。这将使您能够运行更多的 epoch 并获得出色的性能。
- 在每个 epoch 中,数据必须被分成序列长度为 50 的批次。这意味着每个 epoch 将有 100 个序列,每个序列的长度为 50。
笔记
- 绘制损失随时间变化的进度。
- 将以下句子开头输入训练模型并完成句子:“So she was considering in her own mind”。
笔记
可以通过此链接找到此活动的解决方案。
最后一句话会有所不同,因为在选择每个字符时都有一个随机因素;但是,它应该看起来像这样:
所以她在自己的脑海里考虑我们,”她说 se the sire。前面的句子没有意义,因为网络没有经过足够的时间训练(损失函数仍然可以最小化)并且它选择一次每个字符,没有对先前创建的单词的长期记忆。尽管如此,我们可以看到,在仅 20 个 epoch 之后,网络已经能够形成一些有意义的单词。
自然语言处理
计算机擅长分析标准化数据,例如财务记录或存储在表格中的数据库。事实上,他们在这方面比人类做得更好,因为他们有能力一次分析数百个变量。另一方面,人类擅长分析非结构化数据,例如语言,这是计算机不擅长的事情,除非他们手头有一套规则来帮助他们理解它。
考虑到这一点,计算机在人类语言方面面临的最大挑战是,即使计算机在非常大的数据集上经过很长时间的训练后可以很好地分析人类语言,但它们仍然无法理解人类语言。句子背后的真正含义,因为它们既不直观也无法从字里行间中读出。
这意味着虽然人类能够理解“He was on fire last night. What a great game!”这样的句子。指的是某项运动的运动员的表现,计算机会从字面意义上理解它——这意味着它会把它解释为某人昨晚真的着火了。
NLP 是人工智能( AI ) 的一个子领域,其工作原理是让计算机能够理解人类语言。虽然人类在这项任务上可能总是做得更好,但 NLP 的主要目标是让计算机理解人类语言,从而使计算机更接近人类。
这个想法是创建专注于特定领域的模型,例如机器翻译和文本摘要。这种任务的专业化帮助计算机开发出一种模型,能够解决现实生活中的数据问题,而不必同时处理人类语言的所有复杂性。
人类语言理解的这些领域之一(如今非常流行)是情感分析。
情绪分析
一般来说,情感分析包括理解输入文本背后的情感。考虑到随着社交媒体平台的激增,公司每天收到的消息和评论数量呈指数级增长,它变得越来越受欢迎。这使得实时手动修改和响应每条消息的任务变得不可能,这可能会损害公司的形象。
情感分析侧重于提取句子的基本成分,而忽略了细节。这有助于解决两个主要需求:
- 确定客户最关心的产品或服务的关键方面。
- 提取每个方面背后的感受,以确定哪些引起了积极和消极的反应,并相应地处理它们:

图 6.23:推文示例
从前面的屏幕截图中获取文本,执行情绪分析的模型可能会获取以下信息:
- “AI”作为推文的对象
- “快乐”作为从中衍生出来的感觉
- “十年”作为对对象的情感时间范围
正如您所看到的,情绪分析的概念对于任何拥有在线业务的公司来说都是关键,因为它能够以惊人的速度对那些需要立即关注的评论做出反应,并且准确度与人类相似.
作为情绪分析的一个示例用例,一些公司可能会选择对他们每天收到的大量消息进行情绪分析,以便优先响应那些包含抱怨或负面情绪的消息。这不仅有助于减轻这些特定客户的负面情绪;它还将帮助公司迅速纠正错误并与客户建立信任关系。
执行 NLP 进行情感分析的过程将在下一节中详细说明。我们将解释词嵌入的概念以及在 PyTorch 中开发此类模型可以执行的不同步骤,这将是本章最后活动的目标。
PyTorch 中的情感分析
在 PyTorch 中构建模型以执行情感分析与我们目前在 RNN 中看到的非常相似。不同的是,在这种情况下,文本数据将逐字处理。本节将提供构建此类模型所需的步骤。
预处理输入数据
与任何其他数据问题一样,您需要将数据加载到代码中,请记住不同的数据类型使用不同的方法。除了将整组单词转换为小写外,数据还会进行一些基本转换,以便您将数据输入网络。最常见的转换如下:
- 消除标点符号:为 NLP 目的逐字处理文本数据时,请删除所有标点符号。这样做是为了避免将同一个词当作两个单独的词,因为其中一个词后跟句点、逗号或任何其他特殊字符。一旦实现了这一点,就可以定义一个包含输入文本的词汇表(即整个单词集)的列表。
这可以通过使用字符串模块的标点符号预初始化字符串来完成,它提供了一个标点字符列表,可用于在文本序列中识别它们,如以下代码片段所示:
test = pd.Series(['Hey! This is example #1.', \ 'Hey! This is example #2.', \ 'Hey! This is example #3.']) for i in punctuation: test = test.str.replace(i,"") - Numbered labels:类似于前面解释的映射字符的过程,词汇表中的每个单词都被映射为一个整数,它将用于替换输入文本中的单词,以便将它们输入网络:

图 6.24:单词和数字的映射
PyTorch 不是执行单热编码,而是允许您将单词嵌入一行代码中,这些代码可以在包含网络架构的类中定义(接下来将对此进行解释)。
构建架构
同样,定义网络架构的过程与我们目前所研究的非常相似。然而,正如我们之前提到的,网络还应该包括一个嵌入层,该层将获取输入数据(已转换为数字表示)并为每个单词分配一定程度的相关性。也就是说,这些值会在训练过程中不断更新,直到最相关的词被赋予更高的权重。
以下是架构示例:
class LSTM(nn.Module):
def __init__(self, vocab_size, embed_dim, \
hidden_size, n_layers):
super().__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.lstm = nn.LSTM(embed_dim, hidden_size, n_layers)
self.output = nn.Linear(hidden_size, 1)
def forward(self, x, states):
out = self.embedding(x)
out, states = self.lstm(out, states)
out = out.contiguous().view(-1, self.hidden_size)
out = self.output(out)
return out, states如您所见,嵌入层将整个词汇表的长度作为参数,以及由用户设置的嵌入维度。这个嵌入维度将是 LSTM 层的输入大小。架构的其余部分将与以前相同。
训练模型
最后,在定义了损失函数和优化算法后,训练模型的过程与任何其他神经网络相同。根据研究的需要和目的,数据可以分成不同的集合。接下来,您必须设置纪元数和将数据分成批次的方法。网络的内存通常在处理每批数据时保留,但随后在每个时期初始化为零。网络的输出是通过对一批数据调用模型获得的。然后计算损失函数,优化参数。
活动 6.03:执行用于情感分析的 NLP
您将用于此活动的数据集称为Sentiment Labeled Sentences Dataset,可从 UC Irvine Machine Learning Repository 获得。
笔记
此活动的数据集可在https://packt.live/2z2LYc5找到。它也可以在UCI Machine Learning Repository: Sentiment Labelled Sentences Data Set在线获得。
数据集和相关分析首次发布于此处:From Group to Individual Labels using Deep Features,Kotzias 等。艾尔,。KDD 2015 [ From Group to Individual Labels Using Deep Features | Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining ]
在此活动中,将使用 LSTM 网络分析一组评论以确定评论背后的情绪。让我们考虑以下场景:您在一家互联网提供商的公共关系部门工作,审查您在公司社交媒体资料上收到的每条查询的过程需要很长时间。最大的问题是遇到服务问题的客户比没有遇到问题的客户没有耐心,因此您需要确定响应的优先级,以便首先解决它们。当您在空闲时间喜欢编程时,您决定尝试构建一个能够确定消息是消极还是积极的神经网络。按照以下步骤完成此活动:
笔记
值得一提的是,此活动中的数据并未分成不同的数据集,以便对模型进行微调和测试。这是因为此活动的主要重点是实施创建能够执行情绪分析的模型的过程。
- 导入所需的库。
- 加载包含来自亚马逊的一组 1,000 条产品评论的数据集,这些评论与标签 0(负面评论)或 1(正面评论)配对。将数据分成两个变量——一个包含评论,另一个包含标签。
- 从评论中删除标点符号。
- 创建一个变量,其中包含整组评论的词汇。此外,创建一个将每个单词映射到一个整数的字典,其中单词将是键,整数将是值。
- 通过用成对的整数替换评论中的每个单词来对评论数据进行编码。
- 创建一个包含网络架构的类。确保包含嵌入层。
笔记
由于在训练过程中不会分批输入数据,因此不需要在forward函数中返回状态。然而,这并不意味着模型没有内存,而是内存用于单独处理每个评论,因为一个评论不依赖于下一个评论。
- 使用 64 个嵌入维度和 128 个神经元为 3 个 LSTM 层实例化模型。
- 定义损失函数、优化算法和要训练的时期数。例如,您可以使用二元交叉熵损失作为损失函数、Adam 优化器并训练 10 个 epoch。
- 创建一个for循环,遍历不同的时期并分别通过每一个评论。对于每个评论,执行预测,计算损失函数,并更新网络参数。此外,计算网络对该训练数据的准确性。
- 绘制损失和准确性随时间变化的进度。
准确度的最终图如下所示:

图 6.25:显示准确度得分进度的图表
笔记
可以通过此链接找到此活动的解决方案。
概括
在本章中,我们讨论了 RNN。开发这种类型的神经网络是为了解决与序列数据相关的问题。这意味着单个实例不包含所有相关信息,因为这取决于先前实例的信息。
有几个应用程序符合这种类型的描述。例如,如果没有文本其余部分的上下文,文本(或语音)的特定部分可能意义不大。然而,尽管 NLP 对 RNN 的探索最多,但在其他应用中,文本的上下文也很重要,例如预测、视频处理或与音乐相关的问题。
RNN 以一种非常聪明的方式工作;网络不仅输出一个结果,还输出一个或多个通常称为记忆的值。此内存值用作未来预测的输入。
在处理涉及非常大序列的数据问题时,传统的 RNN 会出现一个称为消失梯度问题的问题。这是梯度变得极小以至于它们不再有助于网络的学习过程,这通常发生在网络的较早层,导致网络无法具有长期记忆。
为了解决这个问题,开发了LSTM网络。这种网络架构能够存储两种类型的记忆——因此得名。此外,该网络中发生的数学计算允许它通过仅存储过去的相关信息来忘记信息。
最后解释了一个很时髦的NLP任务:情感分析。在此任务中,了解文本提取背后的情感非常重要。这对机器来说是一个非常困难的问题,因为人类可以使用许多不同的词和表达形式(例如讽刺)来描述事件背后的情绪。然而,由于社交媒体使用的增加,需要更快地处理文本数据,这个问题在投入时间和金钱来创建多个近似值以解决它的大公司中变得非常流行,如图所示本章的最后活动。

![[附源码]Python计算机毕业设计Django的花店售卖系统的设计与实现](https://img-blog.csdnimg.cn/b3c9aea1d1074b3893826d8b7c005a17.png)
![[附源码]SSM计算机毕业设计学习资源共享与在线学习系统JAVA](https://img-blog.csdnimg.cn/e45bc202e05a4ccfa8e0d1a93874f2d5.png)








![[附源码]SSM计算机毕业设计医院仪器设备管理系统JAVA](https://img-blog.csdnimg.cn/8a914466953c40bda7057f121eb92829.png)