源码追踪
Class Job
作为使用Java语言编写的MapReduce城西,其入口方法位main方法,在MapReduce Main方法中,整个核心都在围绕着job类,中文称之为作业。
public class WordDriver {
public static void main(String[] args) throws Exception {
//配置文件对象
Configuration conf = new Configuration();
conf.set("mapreduce.framework.name","local");
// 创建作业实例
Job job = Job.getInstance(conf,WordDriver.class.getSimpleName());
//设置作业的驱动
job.setJarByClass(WordDriver.class);
//设置Mapper
job.setMapperClass(WordMapper.class);
// job.setNumReduceTasks();
//设置Reduce
job.setReducerClass(WordReduce.class);
//设置Mapper阶段输出的Key
job.setMapOutputKeyClass(Text.class);
//设置Mapper阶段输出的Value
job.setMapOutputValueClass(LongWritable.class);
//设置Reduce阶段输出的Key的类型
job.setOutputKeyClass(Text.class);
//设置Reduce阶段输出的Value的类型
job.setOutputValueClass(LongWritable.class);
//设置文件的路径 《上级文件夹》
FileInputFormat.addInputPath(job,new Path("E:\\MapReduceTest\\output"));
//设置输出结果的文件夹
FileOutputFormat.setOutputPath(job,new Path("E:\\MapReduceTest\\output"));
//提交任务
boolean b = job.waitForCompletion(true);
//判断任务是否执行成功
if (b){
System.out.println("OK");
}else{
System.out.println("error");
}
}
}
Job类在源码中的注释中,针对Job的作用做了描述:Job类允许用户配置作业、提交作业、控制作业执行以及查询作业状态。
用户创建MapReduce程序,通过Job描述作业的各个方面,然后提交作业并监视其进度。
通常我们把定义描述Job所在的主类(含有main方法的类)称之为MapReduce程序的驱动类
作业提交
submit是作业的提交的一种方式,但是我们通常不使用submit来提交作业,而是使用waitForCompletion方法进行提交,并传递一个值为true布尔值来进行参数的传递
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
// 判断当前作业的状态是不是定义状态,也就是说是不是还没有提交
if (state == JobState.DEFINE) {
//没有提交就调用submit()方法,本质上来讲还是submit方法
submit();
}
//这里就需要传入的verbose 值了,表明是否要详细过程
if (verbose) {
//如果需要详细过程,就执行monitorAndPrintJob方法,这个方法对执行流程进行监视、打印
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
//在这里来获取查询的时间,在默认情况下是5000ms
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
// 在这里判断作业是否已经完成了
while (!isComplete()) {
try {
//没有完成就休眠,默认5000ms
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
// 返回执行结果
return isSuccessful();
}
// submit方法
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
//在这里我们先确保任务是定义状态:也就是说任务还没有提交
ensureState(JobState.DEFINE);
//使用新版本的API
setUseNewAPI();
//和运行环境创建连接
connect();
final JobSubmitter submitter =
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster);
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
// 创建一个连接
private synchronized void connect()
throws IOException, InterruptedException, ClassNotFoundException {
if (cluster == null) {
// 如果为null就会新建一个Cluster实例
cluster =
ugi.doAs(new PrivilegedExceptionAction<Cluster>() {
public Cluster run()
throws IOException, InterruptedException,
ClassNotFoundException {
//创建一个实例
return new Cluster(getConfiguration());
}
});
}
}
//对象创建过程
public Cluster(Configuration conf) throws IOException {
this(null, conf);
}
// InetSocketAddress 是一个比较重要的参数,在Hadoop1.0之前是负责资源调度,相当于后续的yarn
public Cluster(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
this.conf = conf; // 设置新的conf
this.ugi = UserGroupInformation.getCurrentUser(); // 获取当前用户
initialize(jobTrackAddr, conf); // 初始化当前方法
}
此时这个方法必然是在Cluster类中,这里展示一些相应的方法和关键的参数
private ClientProtocolProvider clientProtocolProvider; // 客户端通信协议的提供者
private ClientProtocol client; // 客户端通信协议
private UserGroupInformation ugi; // 用户组信息
private Configuration conf;
private FileSystem fs = null;
private Path sysDir = null;
private Path stagingAreaDir = null; // job资源暂存路径
private Path jobHistoryDir = null; // job历史路径
//查看初始化方法,刚开始
private void initialize(InetSocketAddress jobTrackAddr, Configuration conf)
throws IOException {
initProviderList();
for (ClientProtocolProvider provider : providerList) {
LOG.debug("Trying ClientProtocolProvider : "
+ provider.getClass().getName());
ClientProtocol clientProtocol = null;
try {
if (jobTrackAddr == null) {
// 在这里有个关键点,就是在这里创建了客户端的通信协议,我们在后文中查看详细
clientProtocol = provider.create(conf);
} else {
//如果集群信息不为空,那么久直接
clientProtocol = provider.create(jobTrackAddr, conf);
}
......
} catch (Exception e) {
......
}
}
}
我们进入到ClientProtocolProvider抽象类中,里面存在两个抽象方法,这两个抽象方法都是建立通信协议的,它们存在两个实现方法:

在这里可以看到,底层两个实现,一个是Local本地,一个是Yarn,也就是在我们的Hadoop集群环境上。再往下看就不难发现,这几个方法本质上就是建立RPC协议,而且从底部屏蔽远程和本地直接的差异。
到后续,会调用submitter来进行设置,最后回通过submitter.submitJobInternal方法进行提交。在这里查看这个方法
JobStatus submitJobInternal(Job job, Cluster cluster)
throws ClassNotFoundException, InterruptedException, IOException {
//validate the jobs output specs
//检查输出路径是否配置而且是否存在,在正常情况下应该是已经配置过的且不应该存在
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
// 获取作业准备区的路径,用于作业及相关资源提交的存放,比如说 jar、且pain信息等
//默认情况下是/tmp/hadoop-yarn/staging/提交作业用户名/.staging
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
// 记录提交作业的主机IP、主机名
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
// 与运行集群进行通信,将获取的jobID设置入job 中
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
// 设置作业提的路径
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
//设置job提交的用户名、
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(),
job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate" +
"data spill is enabled");
}
//拷贝一些作业相关的资源到submitJobDir 作业准备区,比如说: -files、-archives
copyAndConfigureFiles(job, submitJobDir);
//创建job.xml,用来保存作业的配置
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
// 生成本次作业的输入切片,并把切片信息协入作业准备区submitJobDir
// 同时,切片也是在此时生成的,通过input.getSplits(job)方法生成切片数组,并按照从大到小进行排序
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
int maxMaps = conf.getInt(MRJobConfig.JOB_MAX_MAP,
MRJobConfig.DEFAULT_JOB_MAX_MAP);
if (maxMaps >= 0 && maxMaps < maps) {
throw new IllegalArgumentException("The number of map tasks " + maps +
" exceeded limit " + maxMaps);
}
// write "queue admins of the queue to which job is being submitted"
// to job file.
//设置队列信息
String queue = conf.get(MRJobConfig.QUEUE_NAME,
JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList<String> trackingIds = new ArrayList<String>();
for (Token<? extends TokenIdentifier> t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// Write job file to submit dir
//在这里进行权限的写入,等于说到现在了文件还没有开始写入,而是处于准备阶段
writeConf(conf, submitJobFile);
//
// Now, actually submit the job (using the submit name)
//
//到现在才开始真正开始准备提交作业
printTokens(jobId, job.getCredentials());
//在这里创建一个客户端提交作业
status = submitClient.submitJob(
jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}
private int writeSplits(org.apache.hadoop.mapreduce.JobContext job,
Path jobSubmitDir) throws IOException,
InterruptedException, ClassNotFoundException {
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
//在这里开始尝试获取文件切片
if (jConf.getUseNewMapper()) {
maps = writeNewSplits(job, jobSubmitDir);
} else {
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}
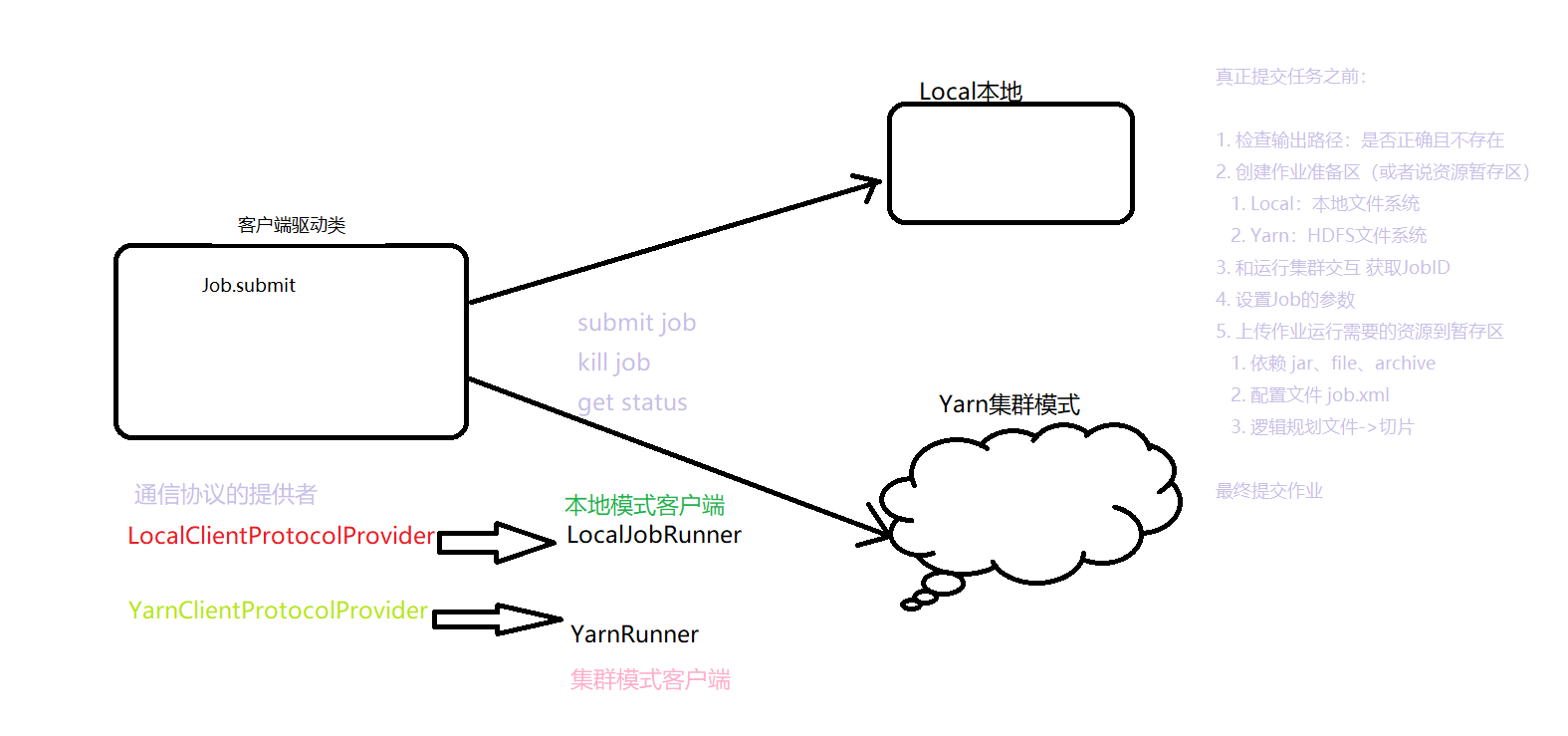
整体流程
真正提交任务之前:
- 检查输出路径:是否正确且不存在
- 创建作业准备区(或者说资源暂存区)
- Local:本地文件系统
- Yarn:HDFS文件系统
- 和运行集群交互 获取JobID
- 设置Job的参数
- 上传作业运行需要的资源到暂存区
- 依赖 jar、file、archive
- 配置文件 job.xml
- 逻辑规划文件->切片
最终提交作业
MapReduce
整体流程图
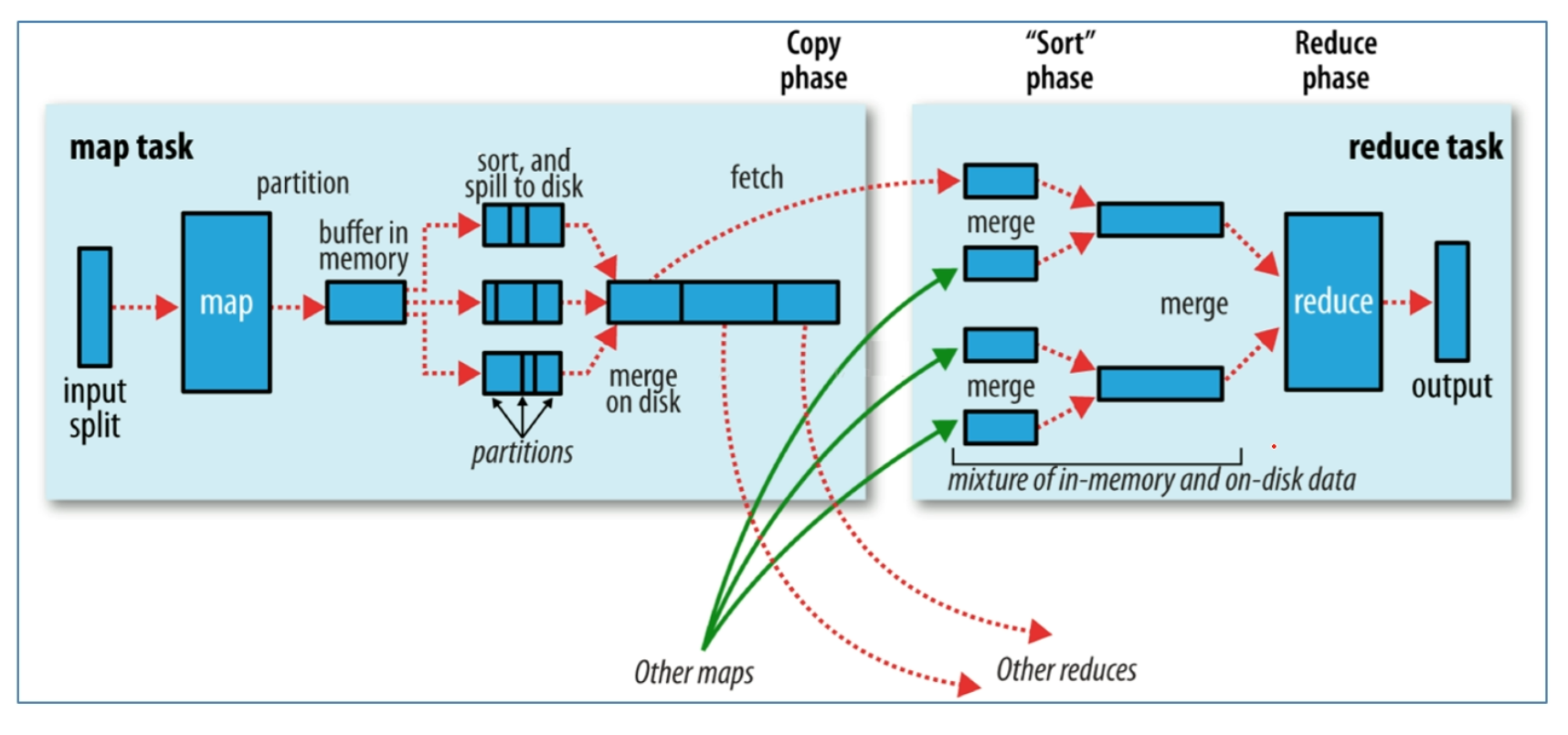
Map阶段流程简述
-
待处理目录下所有文件逻辑上被切分为多个Split文件,一个Split被MapTask处理
-
通过InputFormat按行读取内容返回<Key,Value>键值对,调用map(用户自己实现的)方法进行处理
- InputFormat读一行写一行,将数据写入到Running map task中
-
将结果交给OutPutCollector输出收集器,对输出结果key进行分区Partition,然后写入内存缓冲区
- 如果有Reduce结果,那么就需要先进行一个shuffle操作
- 如果没有Reduce操作,那么就直接调用OutPutCollector
-
当缓冲区快要满的时候,将缓冲区的数据一一个临时文件的方式溢写Spill存放到磁盘,溢写是排序Sort
-
最终对这个MapTask产生的所有临时文件合并Merge,生成最终的Map正式输出文件
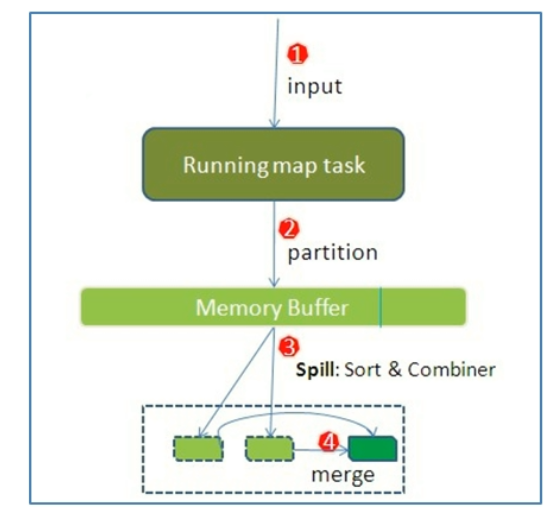
MapTask
在MapReduce程序中,初登场的阶段叫做Map阶段,Map阶段运行的task叫做maptask,MapTask类作为maptask的载体,带哦用的就是类的run方法,开启Map阶段任务.
第一层调用MapTask.run
在MapTask.run方法的第一层调用中,有下面两个重要的代码段
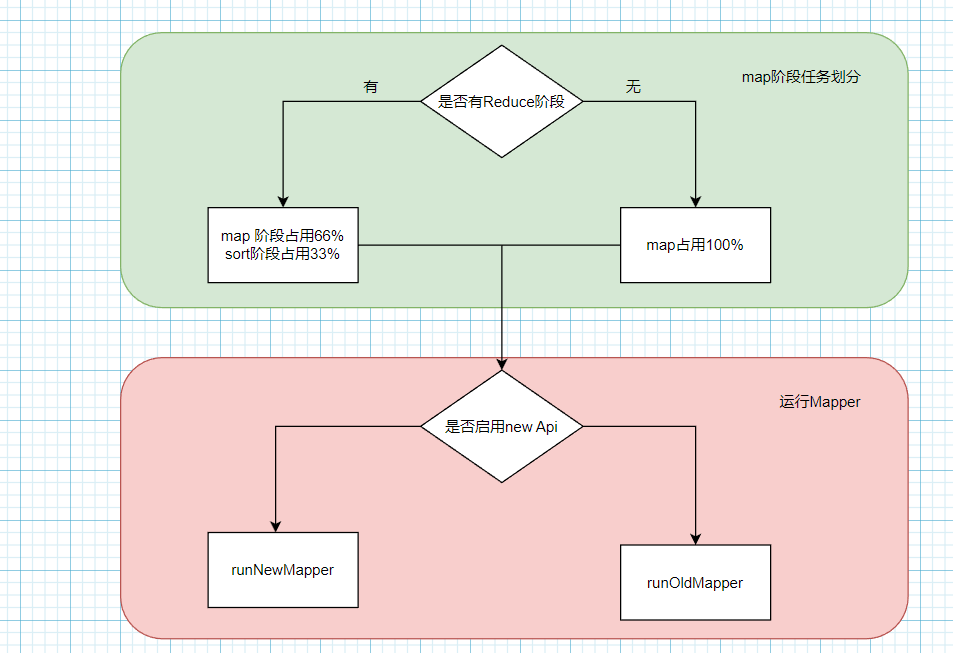
Map阶段任务划分(根据是否有Reduce阶段来决定如何划分)
//判断当前的task是不是MapTask
if (isMapTask()) {
// If there are no reducers then there won't be any sort. Hence the map
// phase will govern the entire attempt's progress.
// 判断ReduceTask的个数,如果是0就意味着没有Reduce阶段,那么mapper阶段输出就是最终的数据
// 这样的话就没有必要进行shuffle了
if (conf.getNumReduceTasks() == 0) {
//没有Reduce阶段,那么mapper阶段占用100%
mapPhase = getProgress().addPhase("map", 1.0f);
} else {
// If there are reducers then the entire attempt's progress will be
// split between the map phase (67%) and the sort phase (33%).
// 存在Reduce阶段,那么设置Map阶段66.7%,sort阶段33.3%
mapPhase = getProgress().addPhase("map", 0.667f);
//为什么要sort?因为要进行shuffle然后发送给ReduceTask
sortPhase = getProgress().addPhase("sort", 0.333f);
}
}
//创建一个TaskReporter并启动通信线程
TaskReporter reporter = startReporter(umbilical);
//是否使用新的API,这个选项在Mapred.mapper.new-api控制,一般不需要用户显示设置
// 但是在提交任务的时候MR框架会自己进行选择
//默认情况下,使用新的API ,除非特别指定了使用old API
boolean useNewApi = job.getUseNewMapper();
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
}
/**
* 再提交任务的时候,MR框架会自动进行选择使用什么API,默认情况下都是newAPI,
* 除非特别指定了使用old API
*/
if (useNewApi) {// 使用新API
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {// 使用旧API
runOldMapper(job, splitMetaInfo, umbilical, reporter);
}
done(umbilical, reporter);
第二层调用(runNewMapper) – 准备阶段
runNewMapper内第一大部分代码为maptask运行的准备部分,其主要逻辑是创建maptask运行时需要的各种对象
- Input Split 切片信息
- InputFormat 读取数据组件,实际上调用的RecordReader类,读取数据大多情况下都是Text形式,这种方式底层调用的是LineRecordReader
- Mapper 处理数据组件 我们创建的Mapper在这里被加载进来,起到真正的作用
- OutputCollector 输出收集器
- taskContext、mapperContext 上下文对象
第二层调用(runNewMapper) – 工作阶段
-
如何从切片读取数据?
initialize核心逻辑:根据切片信息读取数据获得输入流in,判断切片是否压缩、压缩是否可切分,并判断自己是否属于第一个切片,如果不是,舍弃第一行数据不处理,最终读取数据的实现在in.readLine方法中
-
如何调用map方法处理数据
-
如何调用OutputCollector手机map输出的结果
这三个问题采用源码方式进行分析
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
// make a task context so we can get the classes
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(),
reporter);
// make a mapper
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
LOG.info("Processing split: " + split);
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, taskContext);
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
org.apache.hadoop.mapreduce.RecordWriter output = null;
// get an output object
// 创建outputCollector 用于mapTask处理结果的输出
if (job.getNumReduceTasks() == 0) {
output = // 如果没有reducetask 直接调用最终的输出其
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
//如果有reducetask 则需要进行shuffle操作
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
// mapper上下文对象
org.apache.hadoop.mapreduce.MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE>
mapContext =
new MapContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, getTaskID(),
input, output, // 此处的input 就是RecordReader (默认lineRecordReader)
committer,
reporter, split);
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext =
new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(
mapContext);
// maptask工作干活的核心逻辑
try {
// mapTask初始化的时候调用一次,默认是显示LineRecordReader 的initialize方法
// 里面描述了如何从切片中获取数据
input.initialize(split, mapperContext);
// 调用mapper的run方法 开始map阶段处理数据
// 里面描述了每当LineRecordReader读取一行数据返回KV键值对
// 就调用一次用户编写的map方法进行一次业务逻辑处理
mapper.run(mapperContext);
mapPhase.complete();
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
input.close();
input = null;
output.close(mapperContext);
output = null;
} finally {
closeQuietly(input);
closeQuietly(output, mapperContext);
}
}
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
FileSplit split = (FileSplit) genericSplit; // 拿到切片
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);// 一行能够处理的最大长度
start = split.getStart(); // 要处理的切片的第一个字节的位置
end = start + split.getLength(); // 切片结束的位置
final Path file = split.getPath(); // 获取切片的存储位置
// open the file and seek to the start of the split
final FileSystem fs = file.getFileSystem(job);
fileIn = fs.open(file); // 打开切片文件,开始读取数据,返回的是FSDataInputStream输入流
CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file); // 获得文件中的编码器
if (null!=codec) { // 判断是否进行编码压缩,如果不为空,意味着文件被编码了
isCompressedInput = true;
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) { // 判断文件是否可被切分,如果是可切饭的压缩算法
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new CompressedSplitLineReader(cIn, job,
this.recordDelimiterBytes);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn;
} else { // 这里表示压缩的编码算法是不可以被切分的
if (start != 0) {
// So we have a split that is only part of a file stored using
// a Compression codec that cannot be split.
throw new IOException("Cannot seek in " +
codec.getClass().getSimpleName() + " compressed stream");
}
// 不可以被切分的压缩文件整体由SplitLineReader来进行处理
in = new SplitLineReader(codec.createInputStream(fileIn,
decompressor), job, this.recordDelimiterBytes);
filePosition = fileIn;
}
} else {// 来到这里表示文件未进行编码
fileIn.seek(start);
in = new UncompressedSplitLineReader(
fileIn, job, this.recordDelimiterBytes, split.getLength());
filePosition = fileIn;
}
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
// 如果当前处理的不是第一个切片,那么就舍弃第一行记录不处理
if (start != 0) {
// 读取一行数据 读取的时候会判断用户是否制定了换行符,如果指定使用用户指定的,
// 如果没有指定就使用默认的
// 默认的换行符取决于操作系统 Linux: \n windows \r\n Mac:\r
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}
public void run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
// 如果还有下一个输入kv对 继续调用map方法处理,
// 该map方法通常在用户自定义的mapper中被重写,也就是整个mapper阶段业务逻辑实现的地方
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
}
@SuppressWarnings("unchecked")
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext,
JobConf job,
TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
collector = createSortingCollector(job, reporter); // 创建map输出收集器
// 获取分区的个数,即reducetask的个数
partitions = jobContext.getNumReduceTasks();
if (partitions > 1) { // 如果分区数大于1,获取分区实现类 默认HashPartitioner
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
} else {
// 进入到这里表示分区只有一个,即不需要进行分区操作,所有数据分区计算返回 reduce个数-1
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return partitions - 1;
}
};
}
}
// 创建一个collector
private <KEY, VALUE> MapOutputCollector<KEY, VALUE>
createSortingCollector(JobConf job, TaskReporter reporter)
throws IOException, ClassNotFoundException {
MapOutputCollector.Context context =
new MapOutputCollector.Context(this, job, reporter);
// 获取map输出收集器的实现类,如果没有设置,默认实现是MapOutputBuffer
Class<?>[] collectorClasses = job.getClasses(
JobContext.MAP_OUTPUT_COLLECTOR_CLASS_ATTR, MapOutputBuffer.class);
int remainingCollectors = collectorClasses.length;
Exception lastException = null;
for (Class clazz : collectorClasses) {
try {
// 判断收集器是否为MapOutPutCollector的实现类
if (!MapOutputCollector.class.isAssignableFrom(clazz)) {
throw new IOException("Invalid output collector class: " + clazz.getName() +
" (does not implement MapOutputCollector)");
}
// 将收集器转换为MapOutputCollector
Class<? extends MapOutputCollector> subclazz =
clazz.asSubclass(MapOutputCollector.class);
LOG.debug("Trying map output collector class: " + subclazz.getName());
// 通过反射创建出MapOutputColloctor 的对象实例
MapOutputCollector<KEY, VALUE> collector =
ReflectionUtils.newInstance(subclazz, job);
// 数据收集器启动 默认实现:MapperOutputBuffer.init()方法
collector.init(context);
LOG.info("Map output collector class = " + collector.getClass().getName());
return collector;// 返回收集器
} catch (Exception e) {
String msg = "Unable to initialize MapOutputCollector " + clazz.getName();
if (--remainingCollectors > 0) {
msg += " (" + remainingCollectors + " more collector(s) to try)";
}
lastException = e;
LOG.warn(msg, e);
}
}
if (lastException != null) {
throw new IOException("Initialization of all the collectors failed. " +
"Error in last collector was:" + lastException.toString(),
lastException);
} else {
throw new IOException("Initialization of all the collectors failed.");
}
}
思维导图