实现孤立手语词的识别流程如下,在实际研究中,本章将着重研究第三阶段内容,也就是模型的设计与实现过程,目的是提高手语图像的识别准确率。 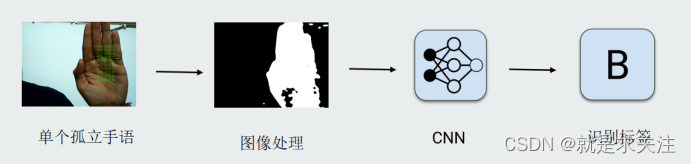
Inception模型实现
Inception模型是谷歌研究人员在2014年提出的一个深度卷积神经网络。它的主要特点是使用了Inception模块,可以提取不同尺度的特征。Inception模块内部使用了多个卷积核来进行不同尺度的卷积,然后将结果结合起来,使网络可以在不同尺度上提取不同的特征,从而提高模型的性能和准确性。该模型在ImageNet大规模视觉识别竞赛中表现出色,成为深度学习领域非常重要的模型之一。Inception模型使用了一个叫做Inception模块的核心组件,它由几个平行的卷积层和冗余层组成。不同大小的卷积核捕捉不同的图像特征,从而更好地适应不同物体的大小和形状。在每个Inception模块中,图像特征被分割成不同的分支,这些分支的输出被聚集起来,形成下一层的输入。除了多维卷积锥和聚合层,Inception模型还使用1x1卷积锥来降低模型的复杂性。这个卷积核减少了输入特征图中的通道数量,从而减少了计算的数量,也提高了模型的准确性。此外,Inception模型中还使用了批量归一化和ReLU等激活函数来进一步提高模型的准确性。"
由于经典inception模型太复杂,在现有计算上跑起来比较吃力,因此,在学习和研究透inception模型原理之后,我们设计了一个简单的inception模型,该模型不仅具有inception模型的优点,还结合具体数据情况做了简单的缩减,其实现代码如下:
| visible = Input(shape=(IMG_SIZE, IMG_SIZE, 3)) layer = inception_module(visible, 2, 2, 2, 2, 2, 2) layer = AveragePooling2D((5, 5), strides=3)(layer) # Average Pooling layer layer = Flatten()(layer) # layer = Dense(200, activation='relu')(layer) # FC layer with 200 layer = Dense(classes, activation='softmax', name='OUTPUT')(layer) # model = Model(inputs=visible, outputs=layer)“ |
其中,个Inception模块为:
| def inception_module(layer_in, f1, f2_in, f2_out, f3_in, f3_out, f4_out): conv1 = Conv2D(f1, (1,1), padding='same', activation='relu')(layer_in) conv3 = Conv2D(f2_in, (1,1), padding='same', activation='relu')(layer_in) conv3 = Conv2D(f2_out, (3,3), padding='same', activation='relu')(conv3) conv5 = Conv2D(f3_in, (1,1), padding='same', activation='relu')(layer_in) conv5 = Conv2D(f3_out, (3,3), padding='same', activation='relu')(conv5) pool = MaxPooling2D((3,3), strides=(1,1), padding='same')(layer_in) pool = Conv2D(f4_out, (1,1), padding='same', activation='relu')(pool) # concatenate filters, assumes filters/channels last print(pool.shape) layer_out = Concatenate()([conv1, conv3, conv5, pool]) return layer_out |
以上代码实现了Inception模块的功能,并通过堆叠Inception模块实现了一个卷积神经网络。该网络的输入层是形状为(IMG_SIZE, IMG_SIZE, 3)的图像,其中IMG_SIZE是图像的尺寸。Inception模块由7个卷积层和一个最大池化层组成,用于提取特征。每个Inception模块的输出被馈送到下一个Inception模块。最后,将所有特征连接到一起,并通过全连接层输出到softmax分类器中。该代码的逻辑是,先定义了Inception模块函数,然后用可见层作为输入,并使用该函数来创建多个Inception模块。在最后一层后添加了全连接层,输出分类器的预测结果。
SE-Inception模型设计与实现
为了进一步提高Inception模型的性能,我们设计实现了SE-Inception模型,SE-Inception模型是对Inception模型的进一步改进,它采用了一种称为SE(Squeeze-and-Excitation)block的结构来增强Inception模型的表示能力。SE-Inception模型与Inception模型的区别在于,它在每个Inception module中添加了SE block,用于对每个分支的特征图进行调整和加权。通过这种方式,SE-Inception模型可以更好地提取和表示输入图像中的特征,从而提高模型的准确性和性能。
SE(Squeeze-and-Excitation)block是一种能够自适应地调节网络中每个通道的重要性的模块。它是由Jie Hu等人在2018年提出的,在Inception模型中进行了应用,有效提高了模型的性能。SE block由两个步骤组成:第一个步骤是通过全局平均池化层将每个特征图压缩为一个单一的值,称为该特征图的通道统计量;第二个步骤是应用一组全连接层来学习每个通道的加权重要性,以重新调整特征图中每个通道的相对权重。SE(Squeeze-and-Excitation)block的实现代码如下:
这段代码定义了一个函数SEBlock,该函数实现了SE(Squeeze-and-Excitation)block。SE block是一种用于卷积神经网络中的模块,可以增强模型对特定通道的响应,从而提高网络的准确性。SE block通过在网络中增加一个squeeze操作和一个excitation操作来实现。该函数的参数包括se_ratio(squeeze和excitation操作中的比例因子,默认为16)、activation(激活函数,默认为relu)、data_format(数据格式,默认为channels_last)和ki(权重初始化方式,默认为he_normal)。
该函数的实现包括以下步骤为,首先,从输入张量中获取通道轴和输入通道数。接着,计算降维后的通道数。接着,进行squeeze操作,即使用全局平均池化层将每个通道的特征压缩为一个值,并通过一个全连接层将这些值映射为一个向量。接着,对squeeze操作的输出进行excitation操作,即通过一个全连接层将向量映射为一个向量,再通过sigmoid激活函数将其归一化到0到1的范围内。接着,将excitation操作的输出与输入张量进行乘法运算,从而增强模型对特定通道的响应。最后,该函数返回增强后的张量。
结合实现的SEBlock函数,我们可以实现SE-Inception模型,其代码如下所示:
| visible = Input(shape=(IMG_SIZE, IMG_SIZE, 3)) # add inception block 1 layer = inception_module(visible, 16, 32, 16, 16, 16, 16) layer = SEBlock(se_ratio=1, activation ="relu", data_format= 'channels_last')(layer ) #se_block layer = AveragePooling2D((3, 3), strides=2)(layer) # Average Pooling layer # layer=attach_attention_module()(layer) layer = Flatten()(layer) # layer = Dense(200, activation='relu')(layer) # FC layer with 200 layer = Dense(classes, activation='softmax', name='OUTPUT')(layer) # # create model model = Model(inputs=visible, outputs=layer) |
上述代码,通过调用inception_module()函数实现了一个Inception模块,并在模块后面添加了一个SE块(通过SEBlock()函数实现),然后加上了一个平均池化层,最后使用Flatten()函数将特征张量展平,并通过Dense()函数实现输出层的分类。