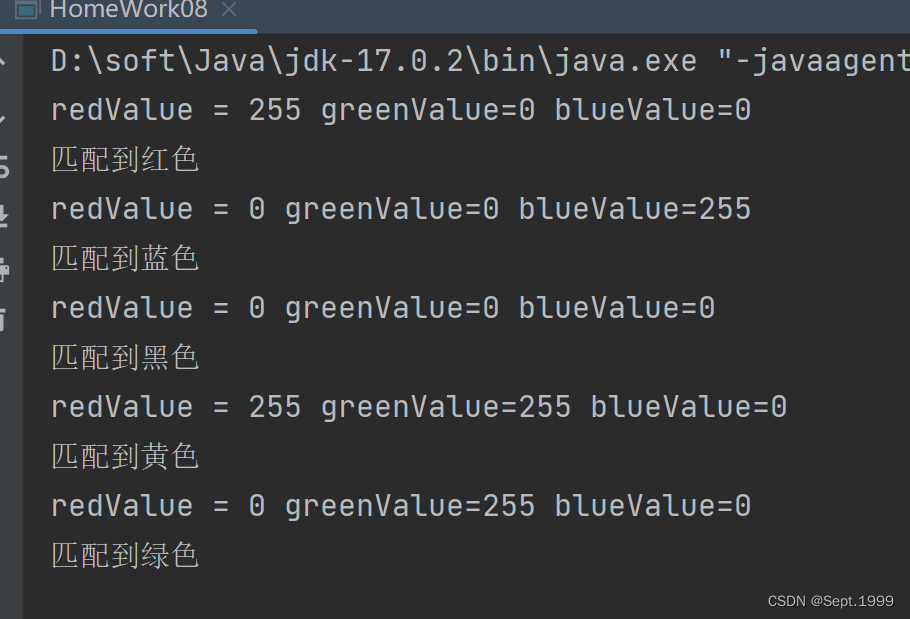
一、背景及问题
在过去两年中,在很多视觉识别任务重,深度卷积网络的表现优于当时最先进的方法。但这些深度卷积网络的发展受限于网络模型的大小以及训练数据集的规模。虽然这个限制有过突破,也是在更深的网络、更大的数据集中产生的更好的性能。
卷积网络的典型使用是在图像分类任务上,即输入一个图像,输入该图像对应的一个标签。在很多视觉任务中,尤其是医学图像任务中,希望得到每个像素对应的类别以及定位,而不是一整个图像的类别。在医学图像分割中,还存在着训练集规模不大的问题。Ciresan基于此提出了通过滑动窗口训练模型,通过环绕像素的局部区域(patch)作为输入,来预测该像素对应的类别。
Ciresan提出的方法的优点有两个,一是网络能定位;二是通过patch的训练集数据比训练图像的数量大很多。该模型还获得了当时的EM分割比赛。该方法的缺点也有两个,一是网络需要训练每个像素对应的patch,导致速度非常慢;而且patches存在重叠,出现很多多余信息,也就是投入网络中的训练数据集存在大量的冗余信息,降低了训练速度,浪费时间以及显存。二是在定位的精确度以及上下文的使用上有一个权衡。较大的patches需要更多的池化层,这样就会导致降低定位的精确度;而使用较小的patches,就会只能使用较小的文本信息,也就是可利用的上下文信息范围太小。于是就提出,同时有较精确的定位、稍大范围文本信息的可能。
二、U-Net的创新点
通过Ciresan的方法的缺点,以及“同时存在好的定位和较大文本信息的可能”的启发,也就有了作者更改扩延FCN结构的想法,目标是:使它用非常少的训练图像,产生更准确的分割。
- 使用连续的层补充contracting网络,用上采样操作替代池化操作,这些层会提高输出分辨率。
- 为了定位,将来自contracting 路径的高分辨率与上采样的输出特征图进行组合。
基于以上两个创新,使得最终的输出结果更加精确。
三、U-Net的结构体
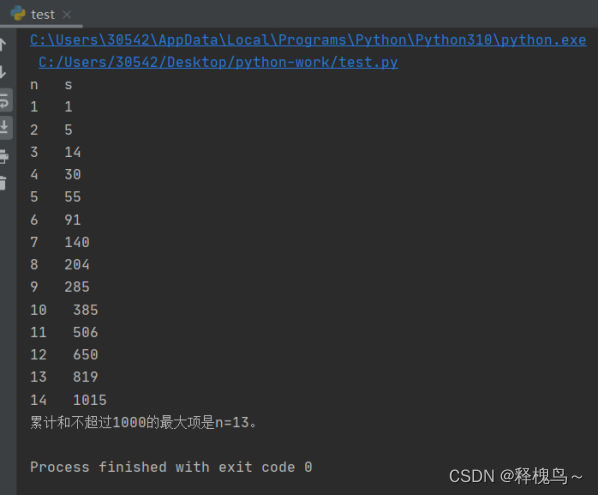
由于the contracting path(也称之为编码层),也就是U-Net结构的左半部分,与the expansive path(也称之为解码层),两部分或多或少是对称的,所以将该模型称之为U型结构。
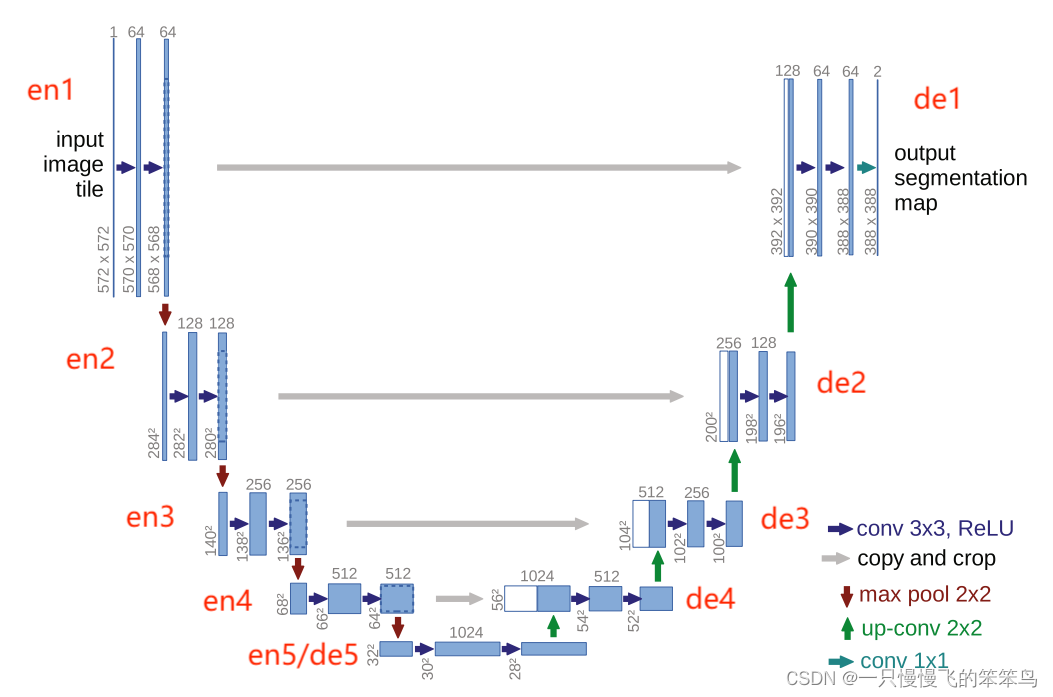
图1 U-Net的网络结构
- the contracting path(编码层)
编码层由5层构成,每层是由两个不填充(padding=0)的conv3*3构成,每个conv3*3后面跟着一个ReLU;然后是下采样,下采样是一个2*2、stride=2的最大池操作,以及将特征图的特征通道变至2倍。最大池用来增大感受野的,此时为原来的2倍感受野(?是否是2倍,此处不是很确定,欢迎交流),特征图的分辨率变为原来的1/2。
具体实现以二分类进行讲解,即输入的图像类别 channels=3,输出类别 num_classes=2. 输入图像分辨率(h, w)= (512, 512).
- encoder1: 两个conv3*3,padding=0,channel由3至64. (h, w)= (512, 512)不变。maxpooling: channel=64,不变;(h, w)= (256, 256),变为一半。
- encoder2: 两个conv3*3,padding=0,channel由64至128. (h, w)= (256, 256)不变。maxpooling: channel=128,不变;(h, w)= (128,128),变为一半。
- encoder3: 两个conv3*3,padding=0,channel由128至256. (h, w)= (128,128)不变。maxpooling: channel=256,不变;(h, w)= (64,64),变为一半。
- encoder4: 两个conv3*3,padding=0,channel由256至512. (h, w)=(64,64)不变。maxpooling: channel=512,不变;(h, w)= (32,32),变为一半。
- encoder5: 两个conv3*3,padding=0,channel由512至1024. (h, w)=(32,32)不变。
2. the expansive path(解码层)
解码层同样由5层构成,主要是将图像特征图的分辨率由(32,32)恢复至原始尺寸(512,512)。与编码层不同的是,将编码层中的下采样改为了上采样,下采样是降低分辨率为原来的1/2,上采样是将分辨率提到至原来的2倍。在每层的卷积模块处,需要先将由下一层上采样得到的特征图与来自同层编码层的特征图进行拼接,然后再进行卷积操作。
- decoder5: 此层就是encoder5层,也称之为decoder5。channel=1024, (h, w)=(32,32)。
- upsampling: conv2*2, 将channel上采样为原来的一半channel=512;分辨率扩大至2倍,(h, w)=(64,64)。
- decoder4:先裁剪来自encoder4的特征图至一样的分辨率(64,64),channel变为2倍,为1024;然后两个conv3*3,channel=512。
- upsampling: conv2*2, 将channel上采样为原来的一半channel=256;分辨率扩大至2倍,(h, w)=(128,128)。
- decoder3:先裁剪来自encoder3的特征图至一样的分辨率(128,128),channel变为2倍,为512;然后两个conv3*3,channel=256。
- upsampling: conv2*2, 将channel上采样为原来的一半channel=128;分辨率扩大至2倍,(h, w)=(256,256)。
- decoder2:先裁剪来自encoder2的特征图至一样的分辨率(256,256),channel变为2倍,为256;然后两个conv3*3,channel=128。
- upsampling: conv2*2, 将channel上采样为原来的一半channel=64;分辨率扩大至2倍,(h, w)=(512,512)。
- decoder1:先裁剪来自encoder2的特征图至一样的分辨率(512,512),channel变为2倍,为128;然后两个conv3*3,channel=64。
- output: 一个1*1卷积,主要是将特征图的通道64卷积为输出通道数,此时为2。
四、U-Net的网络代码
写博客的时候发现代码有点问题,后续添加上。
收获:又一次阅读了U-Net原文,进一步理解了下采样的作用,就是增大了感受野,也就是看到的范围相对宽广了。