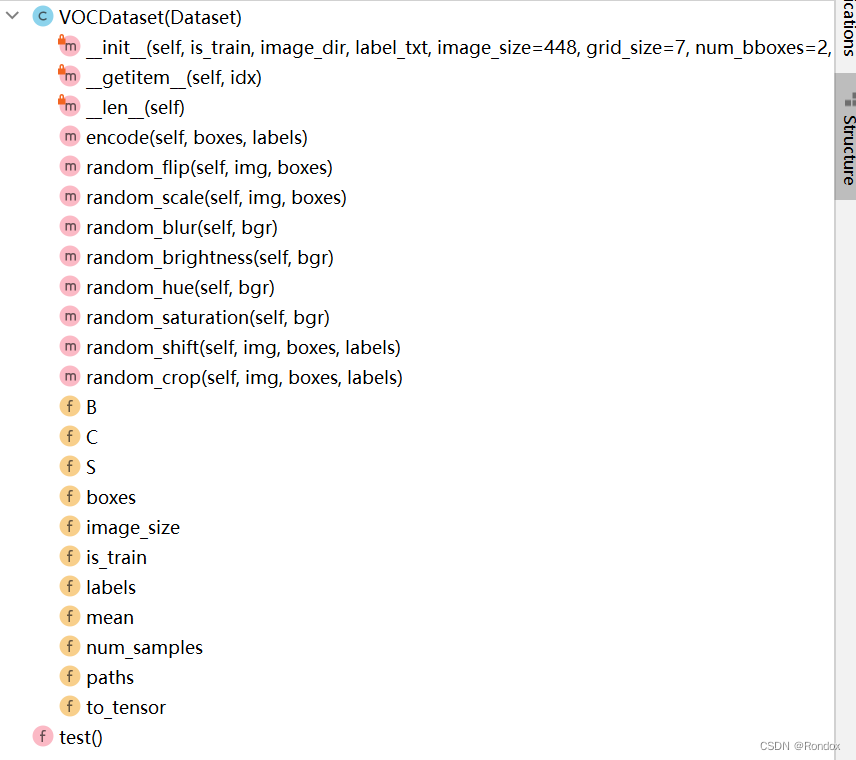
先看结构
1.mean_rgb是voc2007专用的均值
voc2007分别是这样的
坐标格式(X0,Y0,X1,Y1)其中X0,Y0是左上角的坐标,X1,Y1是右下角的坐标。
coco,voc ,yolo数据集中的bbox的坐标格式_coco bbox格式_十二耳环的博客-CSDN博客
读取文本分割内容放进self.paths, self.boxes, self.labels = [], [], [] 读的都是原始内容
self.paths [p1,p2,p3,..]
self.boxes[[x11,y11,x12,xy12],[x21,y21,x22,xy22],[x31,y31,x32,xy32],.......]
self.labels [l1,l2,l3,..]
2.boxes /= torch.Tensor([[w, h, w, h]]).expand_as(boxes) # normalize (x1, y1, x2, y2) w.r.t. image width/height. 相对图片大小归一化
扩展成多少个框,然后相对应最后归一化 torch.Tensor([[w, h, w, h]]).expand_as(boxes)
encode那句下面说 所以传进去的boxes是已经相对图片大小归一化的左上坐标和右下坐标
def __getitem__(self, idx):
path = self.paths[idx]#'C:\\Pro\\pythonProject\\yolov1_pytorch-main_chunsun\\Datasets/VOCdevkit/VOC2007/JPEGImages/003659.jpg'
img = cv2.imread(path)#375*500*3 就是文件大小
boxes = self.boxes[idx].clone() # [n, 4]
labels = self.labels[idx].clone() # [n,]
if self.is_train:
#img, boxes = self.random_flip(img, boxes)
#img, boxes = self.random_scale(img, boxes)
img = self.random_blur(img)
img = self.random_brightness(img)
img = self.random_hue(img)
img = self.random_saturation(img)
img, boxes, labels = self.random_shift(img, boxes, labels)
img, boxes, labels = self.random_crop(img, boxes, labels)
# For debug.
debug_dir = 'tmp/voc_tta'
os.makedirs(debug_dir, exist_ok=True)
img_show = img.copy()
box_show = boxes.numpy().reshape(-1)
n = len(box_show) // 4
for b in range(n):#第几个框 一个框时候 b只有0 这种情况下
pt1 = (int(box_show[4*b + 0]), int(box_show[4*b + 1]))#pt是坐标点
pt2 = (int(box_show[4*b + 2]), int(box_show[4*b + 3]))
cv2.rectangle(img_show, pt1=pt1, pt2=pt2, color=(0,255,0), thickness=1)
cv2.imwrite(os.path.join(debug_dir, 'test_{}.jpg'.format(idx)), img_show)
h, w, _ = img.shape
boxes /= torch.Tensor([[w, h, w, h]]).expand_as(boxes) # normalize (x1, y1, x2, y2) w.r.t. image width/height. 相对图片大小归一化
target = self.encode(boxes, labels) # [S, S, 5 x B + C]
img = cv2.resize(img, dsize=(self.image_size, self.image_size), interpolation=cv2.INTER_LINEAR)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # assuming the model is pretrained with RGB images.
img = (img - self.mean) / 255.0 # normalize from -1.0 to 1.0.
img = self.to_tensor(img)
return img, target3.target = self.encode(boxes, labels) # [S, S, 5 x B + C]
boxes_wh 相对图片归一化的w,h
boxes_xy 真实框中心点的xy 而不是cell中心点的xy 相对图片归一化
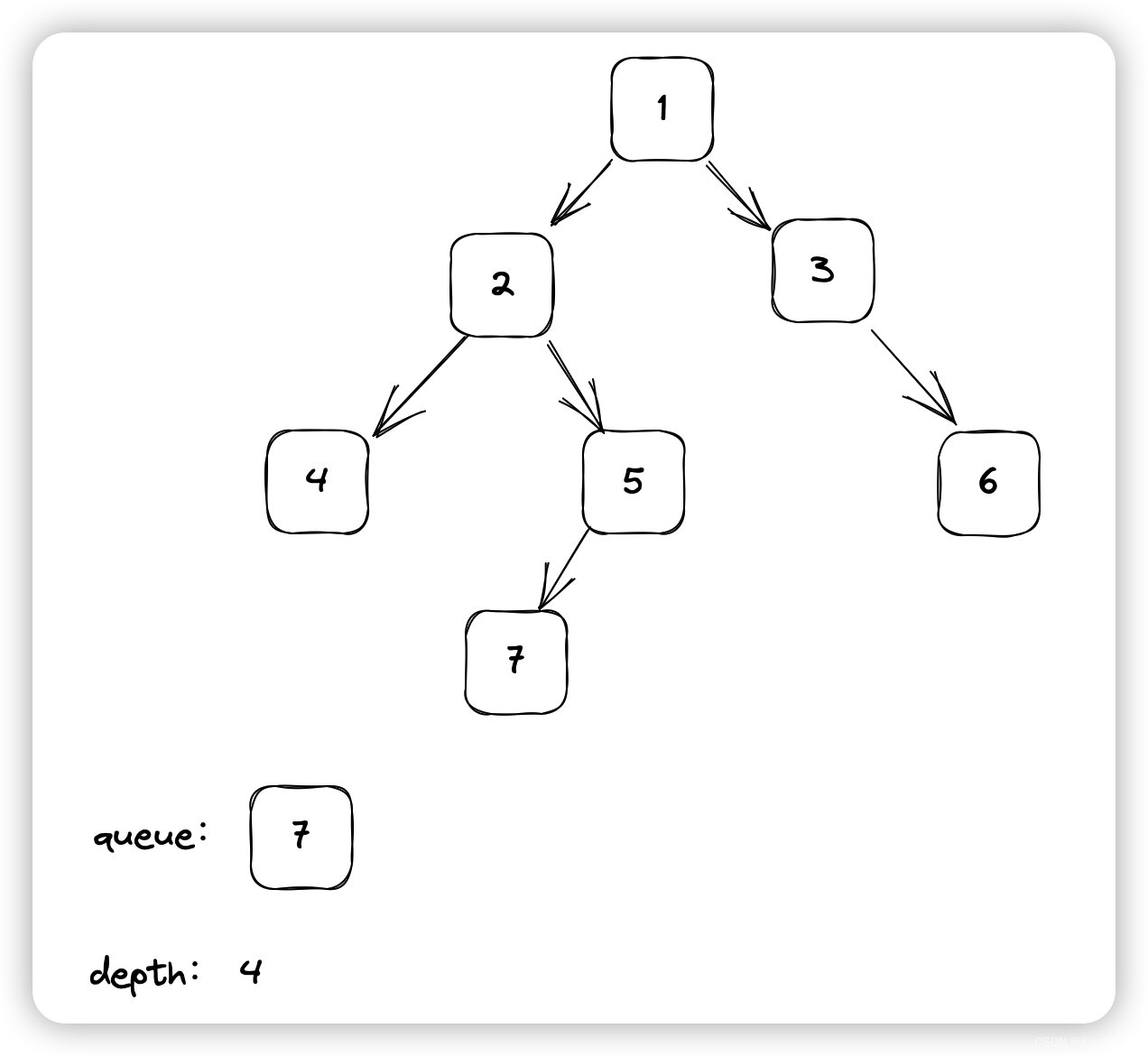
循环中: ceil是向上取整,再-1其实就是向下取整
xy从boxes_xy取对应真实框, 也是相对图片归一化
ij = (xy / cell_size).ceil() - 1.0,获得在哪个cell的行和列的s i,j 从上从左数分别第几个cell
x0y0 cell基准左上坐标 这里是相对图片归一化大小
xy_normalized 此处(xy - x0y0)得到溢出这个cell的值,再/cell_size也就是 相对图片归一化
最后遍历B次 target中所有同一个cell的所有B全是一样的值,也就是yolov1中
target 30维前两个框 值都一样
target构成5+5+20 5是(相对所处的这个cell的x,y相对于图片归一化的偏移量,w,h:是相对于图片归一化的) 20是只有一个类别(某个为1 其他19全为0)
def encode(self, boxes, labels):
""" Encode box coordinates and class labels as one target tensor.
Args:
boxes: (tensor) [[x1, y1, x2, y2]_obj1, ...], normalized from 0.0 to 1.0 w.r.t. image width/height.
labels: (tensor) [c_obj1, c_obj2, ...]
Returns:
An encoded tensor sized [S, S, 5 x B + C], 5=(x, y, w, h, conf)
"""
S, B, C = self.S, self.B, self.C
N = 5 * B + C
target = torch.zeros(S, S, N)
cell_size = 1.0 / float(S)
boxes_wh = boxes[:, 2:] - boxes[:, :2] # width and height for each box, [n, 2]
boxes_xy = (boxes[:, 2:] + boxes[:, :2]) / 2.0 # center x & y for each box, [n, 2]
for b in range(boxes.size(0)):
xy, wh, label = boxes_xy[b], boxes_wh[b], int(labels[b])
ij = (xy / cell_size).ceil() - 1.0
i, j = int(ij[0]), int(ij[1]) # y & x index which represents its location on the grid.
x0y0 = ij * cell_size # x & y of the cell left-top corner.
xy_normalized = (xy - x0y0) / cell_size # x & y of the box on the cell, normalized from 0.0 to 1.0.
# TBM, remove redundant dimensions from target tensor.
# To remove these, loss implementation also has to be modified.
for k in range(B):#两个框都搞一样的
s = 5 * k
target[j, i, s :s+2] = xy_normalized#相对于cell归一化
target[j, i, s+2:s+4] = wh
target[j, i, s+4 ] = 1.0
target[j, i, 5*B + label] = 1.0
return target
剩下是随即裁剪部分 不太需要详细理解
import torch
from torch.utils.data import Dataset
import torchvision.transforms as transforms
import os
import random
import numpy as np
import cv2
class VOCDataset(Dataset):
def __init__(self, is_train, image_dir, label_txt, image_size=448, grid_size=7, num_bboxes=2, num_classes=20):
self.is_train = is_train
self.image_size = image_size
self.S = grid_size
self.B = num_bboxes
self.C = num_classes
mean_rgb = [122.67891434, 116.66876762, 104.00698793]
self.mean = np.array(mean_rgb, dtype=np.float32)
self.to_tensor = transforms.ToTensor()
if isinstance(label_txt, list) or isinstance(label_txt, tuple):
# cat multiple list files together.
# This is useful for VOC2007/VOC2012 combination.
tmp_file = '/tmp/label.txt'
os.system('cat %s > %s' % (' '.join(label_txt), tmp_file))
label_txt = tmp_file
self.paths, self.boxes, self.labels = [], [], []
with open(label_txt) as f:
lines = f.readlines()
for line in lines:
splitted = line.strip().split()
fname = splitted[0]
path = fname
self.paths.append(path)
boxes = np.array([np.array(list(map(int, box.split(',')))) for box in splitted[1:]])
box, label = [], []
for bbox in boxes:
box.append(bbox[:4])
label.append(bbox[4])
self.boxes.append(torch.Tensor(box))
self.labels.append(torch.LongTensor(label))
self.num_samples = len(self.paths)
def __getitem__(self, idx):
path = self.paths[idx]#'C:\\Pro\\pythonProject\\yolov1_pytorch-main_chunsun\\Datasets/VOCdevkit/VOC2007/JPEGImages/003659.jpg'
img = cv2.imread(path)#375*500*3 就是文件大小
boxes = self.boxes[idx].clone() # [n, 4]
labels = self.labels[idx].clone() # [n,]
if self.is_train:
#img, boxes = self.random_flip(img, boxes)
#img, boxes = self.random_scale(img, boxes)
img = self.random_blur(img)
img = self.random_brightness(img)
img = self.random_hue(img)
img = self.random_saturation(img)
img, boxes, labels = self.random_shift(img, boxes, labels)
img, boxes, labels = self.random_crop(img, boxes, labels)
# For debug.
debug_dir = 'tmp/voc_tta'
os.makedirs(debug_dir, exist_ok=True)
img_show = img.copy()
box_show = boxes.numpy().reshape(-1)
n = len(box_show) // 4
for b in range(n):#第几个框 一个框时候 b只有0 这种情况下
pt1 = (int(box_show[4*b + 0]), int(box_show[4*b + 1]))#pt是坐标点
pt2 = (int(box_show[4*b + 2]), int(box_show[4*b + 3]))
cv2.rectangle(img_show, pt1=pt1, pt2=pt2, color=(0,255,0), thickness=1)
cv2.imwrite(os.path.join(debug_dir, 'test_{}.jpg'.format(idx)), img_show)
h, w, _ = img.shape
boxes /= torch.Tensor([[w, h, w, h]]).expand_as(boxes) # normalize (x1, y1, x2, y2) w.r.t. image width/height. 相对图片大小归一化
target = self.encode(boxes, labels) # [S, S, 5 x B + C]
img = cv2.resize(img, dsize=(self.image_size, self.image_size), interpolation=cv2.INTER_LINEAR)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # assuming the model is pretrained with RGB images.
img = (img - self.mean) / 255.0 # normalize from -1.0 to 1.0.
img = self.to_tensor(img)
return img, target
def __len__(self):
return self.num_samples
def encode(self, boxes, labels):
""" Encode box coordinates and class labels as one target tensor.
Args:
boxes: (tensor) [[x1, y1, x2, y2]_obj1, ...], normalized from 0.0 to 1.0 w.r.t. image width/height.
labels: (tensor) [c_obj1, c_obj2, ...]
Returns:
An encoded tensor sized [S, S, 5 x B + C], 5=(x, y, w, h, conf)
"""
S, B, C = self.S, self.B, self.C
N = 5 * B + C
target = torch.zeros(S, S, N)
cell_size = 1.0 / float(S)
boxes_wh = boxes[:, 2:] - boxes[:, :2] # width and height for each box, [n, 2]
boxes_xy = (boxes[:, 2:] + boxes[:, :2]) / 2.0 # center x & y for each box, [n, 2]
for b in range(boxes.size(0)):
xy, wh, label = boxes_xy[b], boxes_wh[b], int(labels[b])
ij = (xy / cell_size).ceil() - 1.0
i, j = int(ij[0]), int(ij[1]) # y & x index which represents its location on the grid.
x0y0 = ij * cell_size # x & y of the cell left-top corner.
xy_normalized = (xy - x0y0) / cell_size # x & y of the box on the cell, normalized from 0.0 to 1.0.
# TBM, remove redundant dimensions from target tensor.
# To remove these, loss implementation also has to be modified.
for k in range(B):#两个框都搞一样的
s = 5 * k
target[j, i, s :s+2] = xy_normalized#相对于cell归一化
target[j, i, s+2:s+4] = wh
target[j, i, s+4 ] = 1.0
target[j, i, 5*B + label] = 1.0
return target
def random_flip(self, img, boxes):
if random.random() < 0.5:
return img, boxes
h, w, _ = img.shape
img = np.fliplr(img)
x1, x2 = boxes[:, 0], boxes[:, 2]
x1_new = w - x2
x2_new = w - x1
boxes[:, 0], boxes[:, 2] = x1_new, x2_new
return img, boxes
def random_scale(self, img, boxes):
if random.random() < 0.5:
return img, boxes
scale = random.uniform(0.8, 1.2)
h, w, _ = img.shape
img = cv2.resize(img, dsize=(int(w * scale), h), interpolation=cv2.INTER_LINEAR)
scale_tensor = torch.FloatTensor([[scale, 1.0, scale, 1.0]]).expand_as(boxes)
boxes = boxes * scale_tensor
return img, boxes
def random_blur(self, bgr):
if random.random() < 0.5:
return bgr
ksize = random.choice([2, 3, 4, 5])
bgr = cv2.blur(bgr, (ksize, ksize))
return bgr
def random_brightness(self, bgr):
if random.random() < 0.5:
return bgr
hsv = cv2.cvtColor(bgr, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
adjust = random.uniform(0.5, 1.5)
v = v * adjust
v = np.clip(v, 0, 255).astype(hsv.dtype)
hsv = cv2.merge((h, s, v))
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
return bgr
def random_hue(self, bgr):
if random.random() < 0.5:
return bgr
hsv = cv2.cvtColor(bgr, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
adjust = random.uniform(0.8, 1.2)
h = h * adjust
h = np.clip(h, 0, 255).astype(hsv.dtype)
hsv = cv2.merge((h, s, v))
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
return bgr
def random_saturation(self, bgr):
if random.random() < 0.5:
return bgr
hsv = cv2.cvtColor(bgr, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(hsv)
adjust = random.uniform(0.5, 1.5)
s = s * adjust
s = np.clip(s, 0, 255).astype(hsv.dtype)
hsv = cv2.merge((h, s, v))
bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)
return bgr
def random_shift(self, img, boxes, labels):
if random.random() < 0.5:
return img, boxes, labels
center = (boxes[:, 2:] + boxes[:, :2]) / 2.0
h, w, c = img.shape
img_out = np.zeros((h, w, c), dtype=img.dtype)
mean_bgr = self.mean[::-1]
img_out[:, :] = mean_bgr
dx = random.uniform(-w*0.2, w*0.2)
dy = random.uniform(-h*0.2, h*0.2)
dx, dy = int(dx), int(dy)
if dx >= 0 and dy >= 0:
img_out[dy:, dx:] = img[:h-dy, :w-dx]
elif dx >= 0 and dy < 0:
img_out[:h+dy, dx:] = img[-dy:, :w-dx]
elif dx < 0 and dy >= 0:
img_out[dy:, :w+dx] = img[:h-dy, -dx:]
elif dx < 0 and dy < 0:
img_out[:h+dy, :w+dx] = img[-dy:, -dx:]
center = center + torch.FloatTensor([[dx, dy]]).expand_as(center) # [n, 2]
mask_x = (center[:, 0] >= 0) & (center[:, 0] < w) # [n,]
mask_y = (center[:, 1] >= 0) & (center[:, 1] < h) # [n,]
mask = (mask_x & mask_y).view(-1, 1) # [n, 1], mask for the boxes within the image after shift.
boxes_out = boxes[mask.expand_as(boxes)].view(-1, 4) # [m, 4]
if len(boxes_out) == 0:
return img, boxes, labels
shift = torch.FloatTensor([[dx, dy, dx, dy]]).expand_as(boxes_out) # [m, 4]
boxes_out = boxes_out + shift
boxes_out[:, 0] = boxes_out[:, 0].clamp_(min=0, max=w)
boxes_out[:, 2] = boxes_out[:, 2].clamp_(min=0, max=w)
boxes_out[:, 1] = boxes_out[:, 1].clamp_(min=0, max=h)
boxes_out[:, 3] = boxes_out[:, 3].clamp_(min=0, max=h)
labels_out = labels[mask.view(-1)]
return img_out, boxes_out, labels_out
def random_crop(self, img, boxes, labels):
if random.random() < 0.5:
return img, boxes, labels
center = (boxes[:, 2:] + boxes[:, :2]) / 2.0
h_orig, w_orig, _ = img.shape
h = random.uniform(0.6 * h_orig, h_orig)
w = random.uniform(0.6 * w_orig, w_orig)
y = random.uniform(0, h_orig - h)
x = random.uniform(0, w_orig - w)
h, w, x, y = int(h), int(w), int(x), int(y)
center = center - torch.FloatTensor([[x, y]]).expand_as(center) # [n, 2]
mask_x = (center[:, 0] >= 0) & (center[:, 0] < w) # [n,]
mask_y = (center[:, 1] >= 0) & (center[:, 1] < h) # [n,]
mask = (mask_x & mask_y).view(-1, 1) # [n, 1], mask for the boxes within the image after crop.
boxes_out = boxes[mask.expand_as(boxes)].view(-1, 4) # [m, 4]
if len(boxes_out) == 0:
return img, boxes, labels
shift = torch.FloatTensor([[x, y, x, y]]).expand_as(boxes_out) # [m, 4]
boxes_out = boxes_out - shift
boxes_out[:, 0] = boxes_out[:, 0].clamp_(min=0, max=w)
boxes_out[:, 2] = boxes_out[:, 2].clamp_(min=0, max=w)
boxes_out[:, 1] = boxes_out[:, 1].clamp_(min=0, max=h)
boxes_out[:, 3] = boxes_out[:, 3].clamp_(min=0, max=h)
labels_out = labels[mask.view(-1)]
img_out = img[y:y+h, x:x+w, :]
return img_out, boxes_out, labels_out
def test():
from torch.utils.data import DataLoader
#image_dir = r'D:\Yolo\yolov1_pytorch-main\Datasets\VOCdevkit\VOC2007\JPEGImages'
image_dir = r'C:\Pro\pythonProject\yolov1_pytorch-main_chunsun\Datasets\VOCdevkit\VOC2007\JPEGImages'
#label_txt = ['data/voc2007.txt']
label_txt = 'data/2007_train.txt'
dataset = VOCDataset(True, image_dir, label_txt)
data_loader = DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0)
data_iter = iter(data_loader)
for i in range(100):
img, target = next(data_iter)
print(img.size(), target.size())
if __name__ == '__main__':
test()