1.NearMiss:
NearMiss 是 Mani 等人根据数据分布特征,基于 KNN 算法提出的欠采样方案, 对多数类样本利用随机欠采样来达到数据平衡。 根据不同数据采样的距离,可以分为三类: NearMiss-1、 NearMiss-2 和 NearMiss-3。
NearMiss-1 对于每个多数类样本,选择与少数类样本最近的k 个并计算这k 个少数类样本的平均距离,保留平均距离最小的多数类样本; NearMiss-2 与 NearMiss-1不同的是选择最远的k 个少数类样本并计算平均距离并进行保留。 NearMiss-3 在上述基础上进行的改进,对数据更加详细的分类。 首先对于每个少数类样本,选择与多数类样本最近的m 个;接着对于保留的多数类样本,选择距离最近的k 个少数类样本并计算这k 个少数类样本的平均距离,保留平均距离最大的多数类样本。
2 SMOTE:
对于不平衡的数据而言,分类器算法结果通常受多数类样本的影响较大,正负样本差距较大时可能会造成过拟合现象,进而忽视少数类样本在其中带来的影响,严重失衡会影响模型的预测性能。 SMOTE 是由 Chawla 等人[60]在 2002 年提出的一对少数类样本采取随机过采样来达到数据平衡的有效方法。该算法可以描述为: 在少类数据集中每一个样本 x ,利用欧式距离计算出每个样本的k 近邻,然后根据少类样本不平衡的比列确定采样倍率为 N ,从每个样本的k 近邻中随机的选择 N 个样本,若选择的近邻为 Xn( n= 1,2,3, , , ) 在少数类样本和 xn之间进行随机线性插值,则新的样本 x_new 为:

其中rand(0,1)表示生成介于 0 和 1 之间的随机数。将构建出新的少类样本集添加到原少类样本数据集中,最终形成一个新的数据集,即与多类样本数量平衡的数据集。
3.Borderline-SMOTE
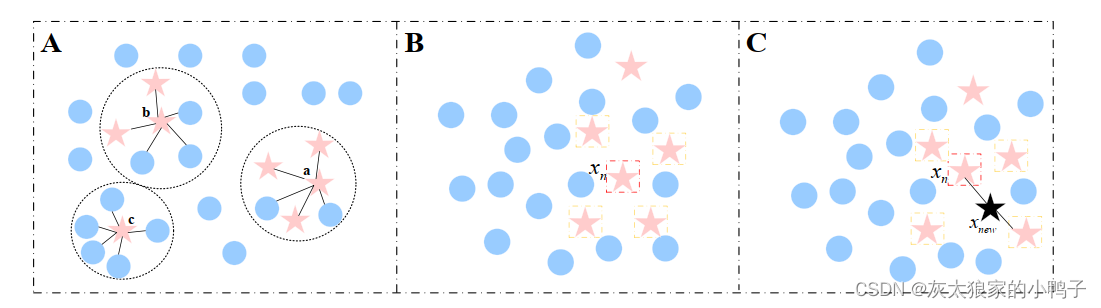
Borderline-SMOTE (Borderline-Synthetic Minority Oversampling Technique) 方法是对SMOTE方法的改进,该算法仅使用边界上的少数类样本来合成新样本。Borderline-SMOTE[60]采样过程是首先将少数类样本分为3类,分别命名为Safe、Danger和Noise。其次,仅对Danger类的少数类样本过采样。具体步骤如下:
Step1:
(1) Safe: 样本周围一半以上均为少数类样本,如图2-1 (A) 中点a。
(2) Danger:样本周围一半以上均为多数类样本,视为在边界上的样本,如图2-1
(A) 中点b。
(3) Noise:样本周围均为多数类样本,视为噪音,如图2-1 (A) 中点c。
Step2:
对b类样本利用SMOTE进行过采样,通过线性插值构建出新的少类样本集添加到原
少类样本数据集中,最终形成一个新的数据集。