还记得在去年,我们曾经发过一篇文章介绍 icefall 中的语言模型使用方法:升点小技巧之—在icefall中巧用语言模型。如今半年过去了,k2 团队又有了一些新进展。今天来给大家做一个小小的总结,再给大家的模型涨涨点(又又又又又可以找老板涨工资了!)。本篇文章将分别介绍 CTC 和 RNN-T 两种模型上的语言模型使用方法,大家可以挑选适合自己的方法使用~
1. CTC
不知道大家还记不记得,在上次的分享中我们介绍了一个叫做 Low-order Density Ratio (LODR) 的解码办法(忘了的同学快去补课!),即在使用 Density Ratio 的时,用一个低阶 n-gram 的分数近似端到端模型的内部语言模型(Internal Language Model, ILM)的分数。在 RNN-T 模型上使用该方法比单纯使用 shallow fusion 更为有效,是升点的不二法门。下图是一个简单的对比:

既然 LODR 在 RNN-T 模型上这么有效,那同样为端到端模型的 CTC 是否也能从 LODR 上受益呢?虽然 CTC 没有一个接受文本信息的 decoder,但作为一个端到端模型, 我们猜测 CTC 和 RNN-T 一样,不可避免地学习了一些 high-level 的语言模型信息,也就是所谓的 ILM 信息。如果能够在解码的时候去除 ILM 的分数,那是不是能够进一步提升 CTC 和语言模型融合的能力?
对此,我们 k2 团队做了一些探索,尝试将 LODR 融入到 CTC 的解码中。我们尝试了同领域 (in-domain)和跨领域(cross-domain)测试的场景,即使用在 LibriSpeech 上训练的模型分别在 LibriSpeech 和 GigaSpeech 的测试集上解码。我们分别在 LS 官方文本训练集和GigaSpeech数据集的文本上训练了两个 4-gram 语言模型,分别作为 LODR 中的Target domain 语言模型。在进行 LODR 时,我们使用了 LS 960小时文本上训练的 2-gram 作为 source-domain 语言模型。解码时,我们抽取 CTC lattice 中的 nbest-list 进行 rescore,公式如下:
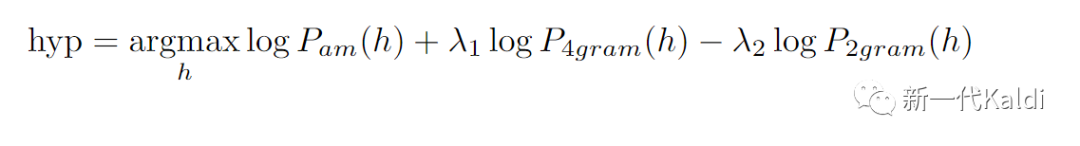
其中![]() 和
和![]() 分别是 4-gram 和 2-gram 的分数。我们选用了zipformer-ctc 模型进行测试,实验结果如下:
分别是 4-gram 和 2-gram 的分数。我们选用了zipformer-ctc 模型进行测试,实验结果如下:

我们发现,在 in-domain 的情境下,LODR 并不能够提升 CTC 模型的准确率,相较于单纯 nbest-rescore,LODR带来的收益非常有限,在 test-clean 和 test-other 上只有0.02和0.01的差距。但是在 cross-domain 的情境下,LODR 能够显著减少 CTC 模型在 target domain 的词错率。这从侧面证明了 CTC 模型在端到端训练时也一定程度上学习了一些语言模型的信息。在现实场景中,ASR 模型的部署环境更接近于 cross-domain,感兴趣的小伙伴不妨试试在 CTC 解码时使用 LODR 吧!该方法我们近期会提交 PR ,还请大家多多关注icefall!
2. RNN-T
说完了 CTC 模型,我们再回来看看 RNN-T 模型。在升点小技巧之—在icefall中巧用语言模型这篇文章中,我们提到 Shallow fusion(SF) 和 LODR 两种都能够显著降低 RNN-T 的词错率的办法。但天下没有免费的午餐,由于需要神经网络语言模型(例如 RNNLM)的前向运算,解码所需要的时间相较单纯 beam search 会明显变长。为了解决这一缺点,我们最近刚刚实现了一版基于 rescore 的 RNN-T 语言模型融合解码办法,能够在仅仅牺牲一点点准确率的前提下,大幅缩短解码时间。
由于 SF 需要在每生成一个新 non-blank token 时进行一次打分,并且要为每个可能的 hypothesis 存储语言模型的状态,所需要的时间和显存都明显比 beam search 多。但如果只是用 RNNLM 对 beam search 的 n-best list 进行rescore,运算量和所需储存的 RNNLM 状态都能明显下降。在 rescore 的基础上,我们可以再加入一个 2-gram 语言模型进行 LODR 的解码。我们使用在LibriSpeech 上训练的 pruned_transducer_stateless7_streaming (流式 zipformer)模型进行测试,比较 shallow fusion,rescore,rescore + LODR 这三种解码办法的 WER。三种办法都使用了同样的 RNNLM,参数量为17M,LODR 使用的 2-gram 是在960h 的文本上训练的。结果如下:
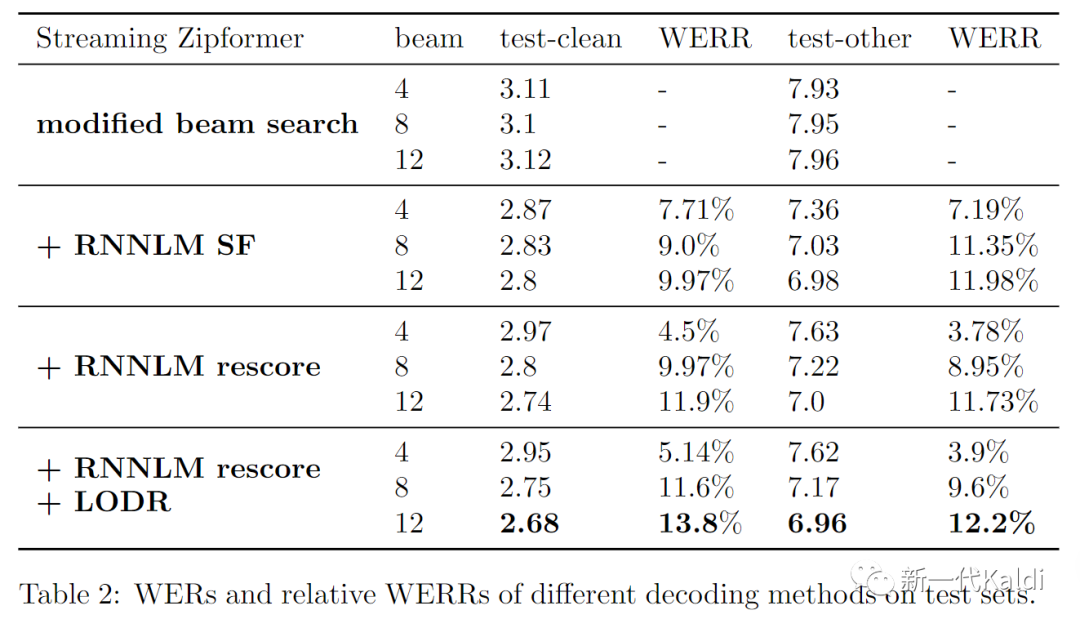
不难发现,三种结合了语言模型的解码办法都能够显著减少 RNN-T 模型的词错率。随着 beam 的增长,rescore 和 SF 的 WER 差距越来越小,当 beam size 为 12 时,rescore 甚至略胜 SF 一筹,在 test-clean 和 test-other 都减少了超过 10% 的相对词错率。在 rescore 的基础上再加入 LODR 能够进一步减小 WER,相对词错率减少达到了 13.8% 和 12.2%。下表展示了上述几种解码办法完成 test-clean 解码所需要的时间:
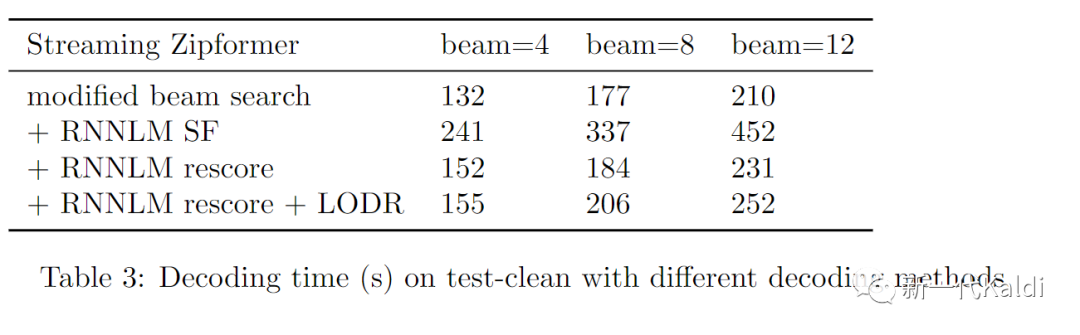
可以看出,在 WER 相近的前提下,rescore 所需要的时间远远小于 SF。在 rescore 的过程中加入 LODR 仅仅让解码时间相较于 beam search 增加了20%,却减少了13.8%的词错率,可谓是又快又准。基于 rescore 的这两个解码办法已经提交在 icefall中,详见这两个 PR:
-
RNNLM rescore[1]
-
RNNLM rescore + LODR[2]
悄悄告诉大家,我们最近也计划在 sherpa-onnx 中加入语言模型的支持[3],初步计划是添加 RNNLM rescore 的解码办法,敬请期待!
3. 总结
本文给大家介绍了如何在 CTC 中的 LODR 解码,该方法在 cross-domain 的测试场景下效果明显。还给大家介绍了基于 RNNLM rescore 的两种 RNN-T 解码办法,又快又准,谁用谁知道!
参考资料
[1]RNNLM rescore: https://github.com/k2-fsa/icefall/pull/1002
[2]RNNLM rescore + LODR: https://github.com/k2-fsa/icefall/pull/1017
[3]支持: https://github.com/k2-fsa/sherpa-onnx/pull/125