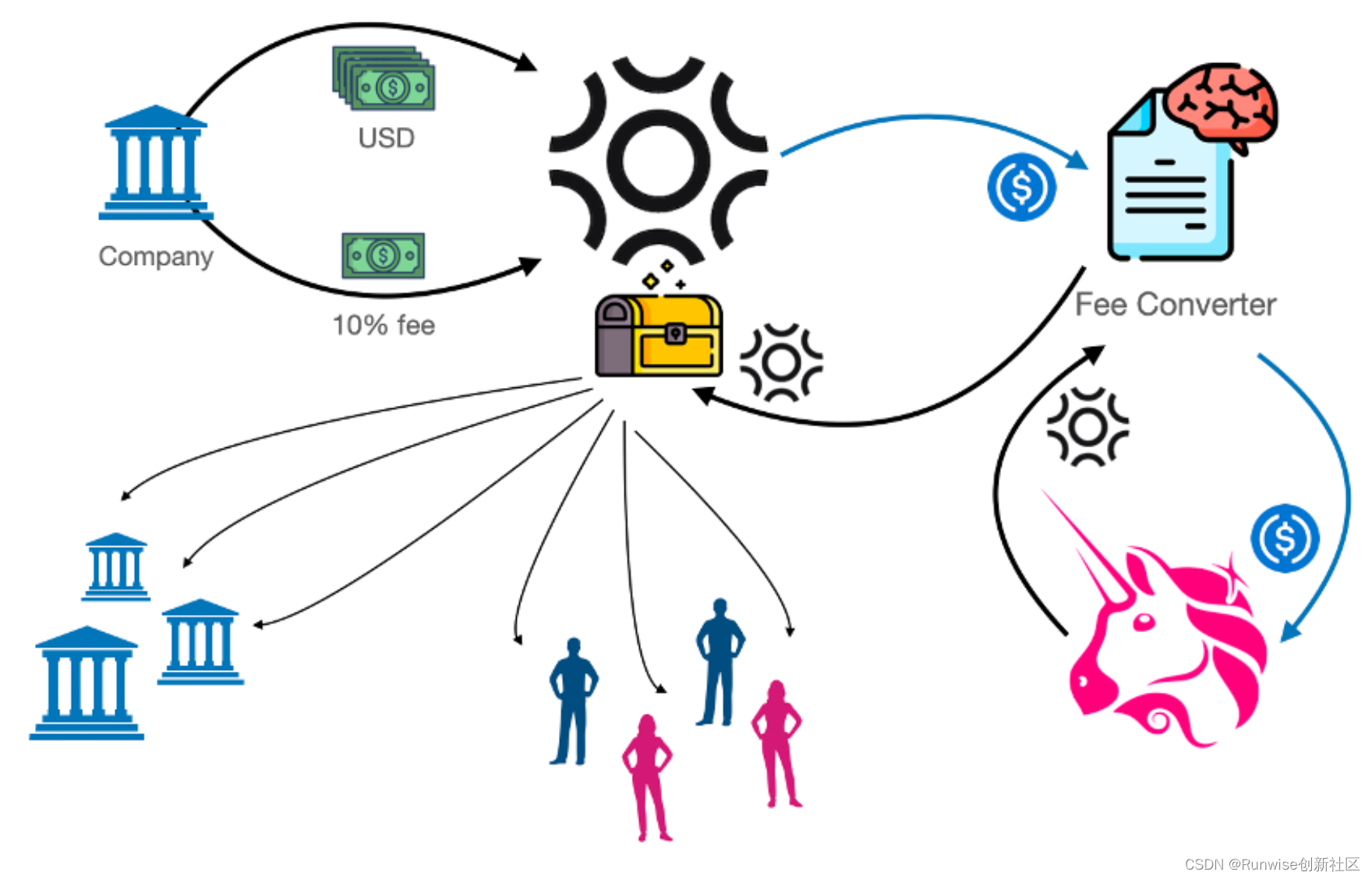
YOLOV1
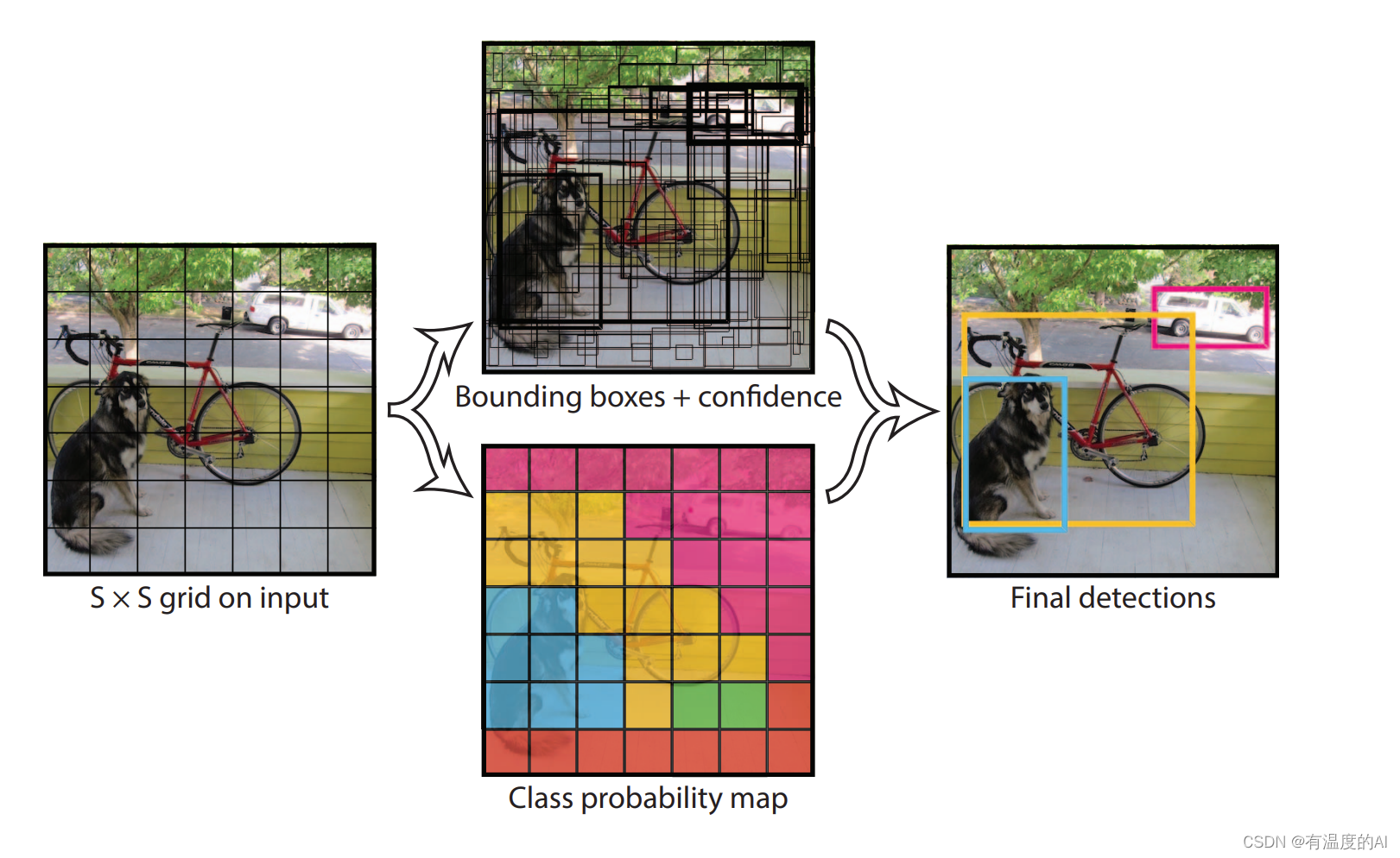
YOLOV1最后生成7×7的网格(grid cell),每个grid cell会产生两个预测框(bounding box),每个grid cell产生的两个预测框只能预测同一种类物体,也就是说YOLOV1最多只能预测49种物体,两个预测框中哪一个与标注框的IOU大就选哪一个(此即正样本),另外一个会被舍弃(负样本);特殊情况(如果有两个相同种类的物体中心点都落在同一个grid cell中,此时这个grid cell的两个预测框有可能都与真实框有最大的IOU,也即两个预测框都为正样本,这也就是说YOLOV1最多能预测49×2个目标)。如果标注框的中心点落在哪一个grid cell中就由这个grid cell产生的两个预测框去负责预测,没有标注框中心点落入的grid cell产生的两个预测框都视为负样本,置信度越小越好。
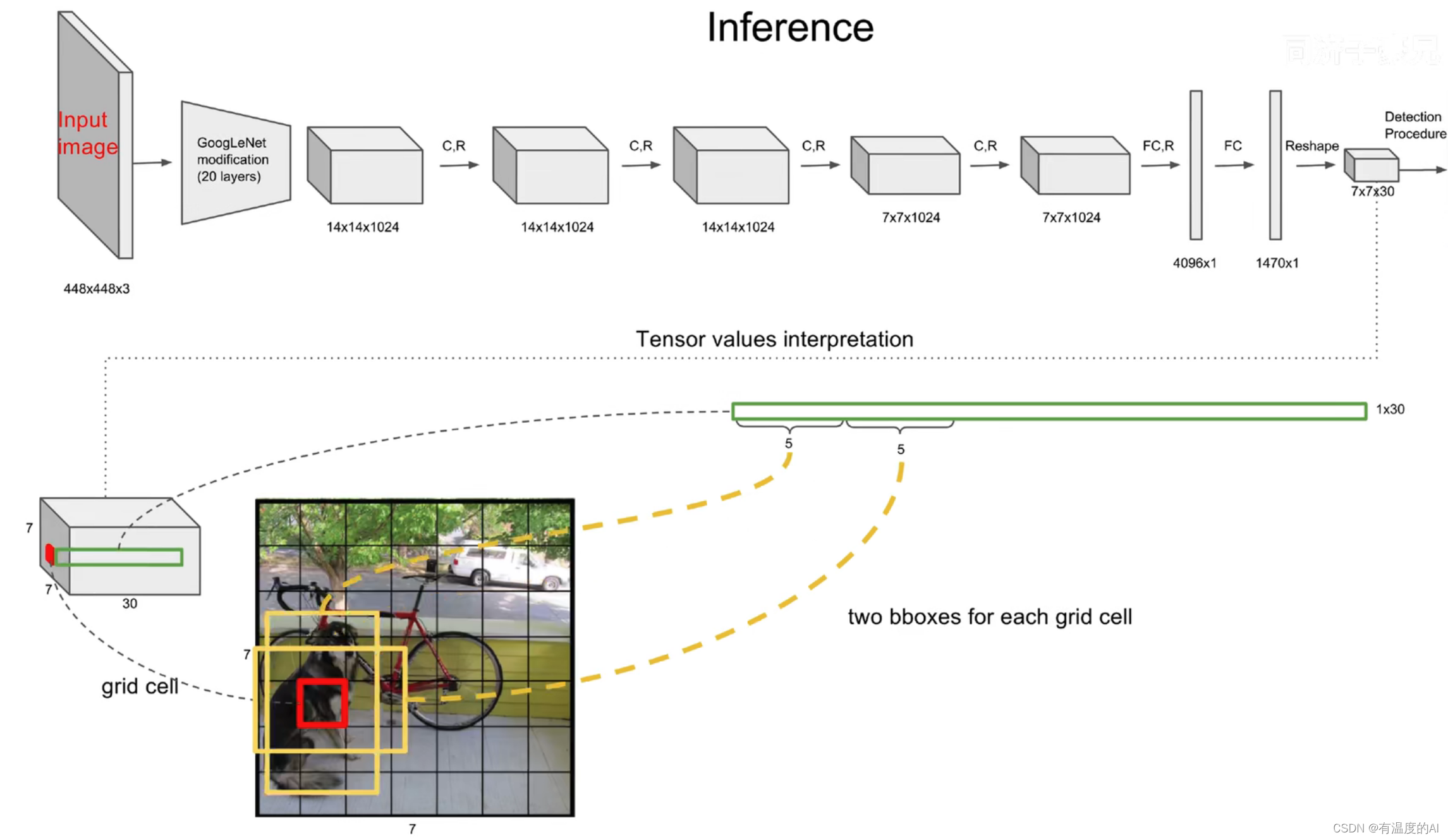
7×7意味着7×7个grid cell,30表示每个grid cell包含30个信息,其中两个预测框,每个预测框包含五个信息(x y w h c),分别为中心点位置坐标,宽高以及置信度,剩下20个是针对VOC数据集的20个种类的预测概率(即假设该grid cell负责预测物体,那么它是某个类别的概率)。
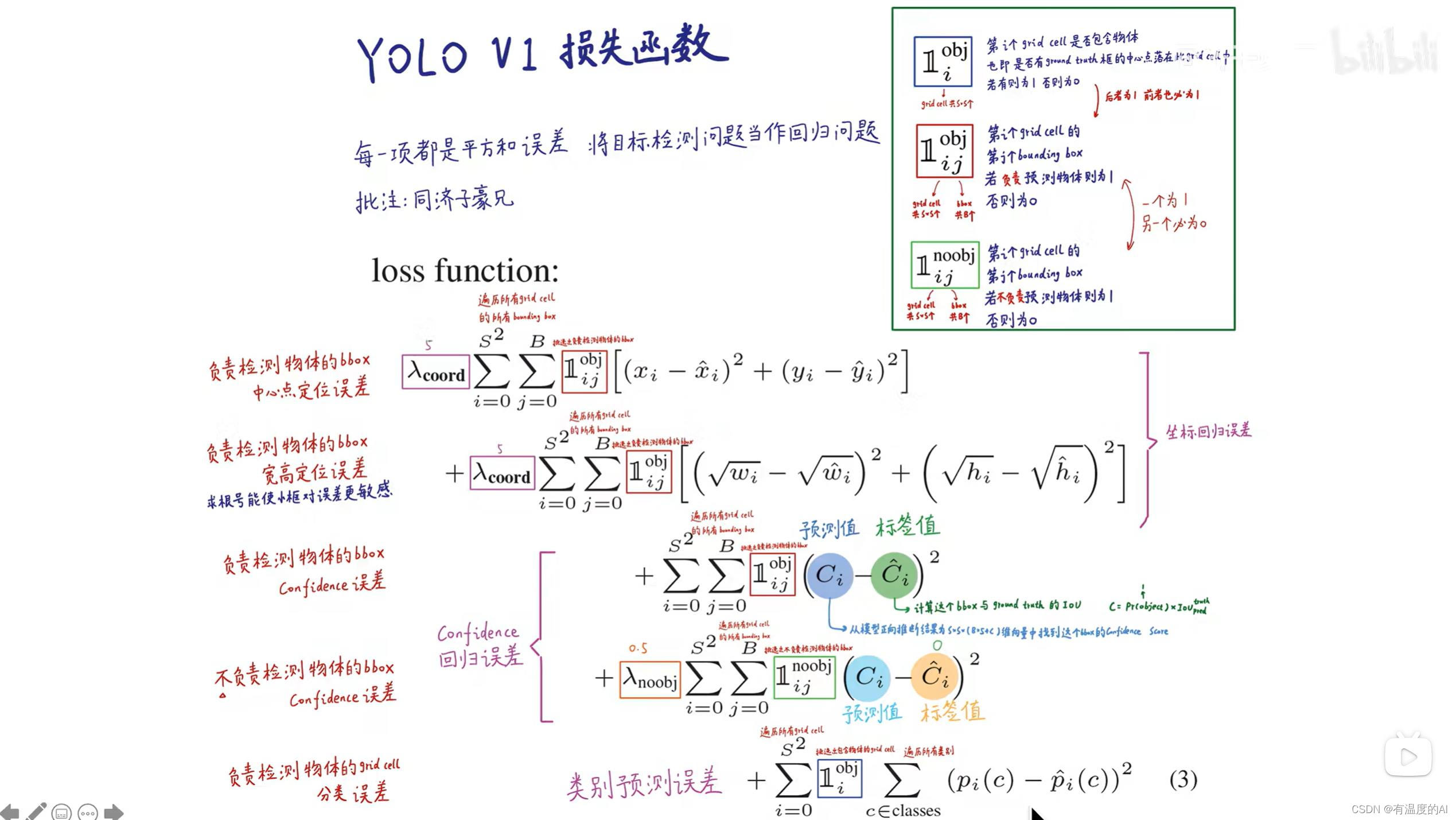
S²表示遍历所有的grid cell,B表示遍历所有的预测框;
对于每一个GTbox只分配一个正样本(预测框),也就是与它IOU最大的那个预测框,其余为负样本;
正样本有定位损失、类别损失和置信度损失;负样本只有置信度损失。
正样本的置信度标签值为预测框与标注框(ground truth)的IOU;
YOLOV1的类别归grid cell管(一个grid cell负责预测一个类别);
YOLOV3的类别归anchor管(一个anchor负责预测一个类别);
YOLOV3
边界框回归
最终产生三个预测特征层,分别预测大、中、小三种类型的物体,每个预测特征层的每个grid cell会产生三个anchor(先验框),预测框是在anchor的基础上调整得到的,下图中黑色虚线框为anchor,蓝色框为实际预测框;tx、ty、tw、th为YOLOV3网络最后预测的回归参数,Cx、Cy为此grid cell左上角的坐标,Pw、Ph为anchor的宽和高。

损失计算


置信度损失:二元交叉熵损失,正负样本都有置信度损失,上图中蓝色框代表anchor,绿色框代表真是标注框,黄色框为预测框,其中Oi(置信度标签)的值有不同的确定方法,一种为设置正样本的Oi值为1,负样本的Oi值为0;另一种为上图所示。

类别损失:二元交叉熵损失,只关注正样本。
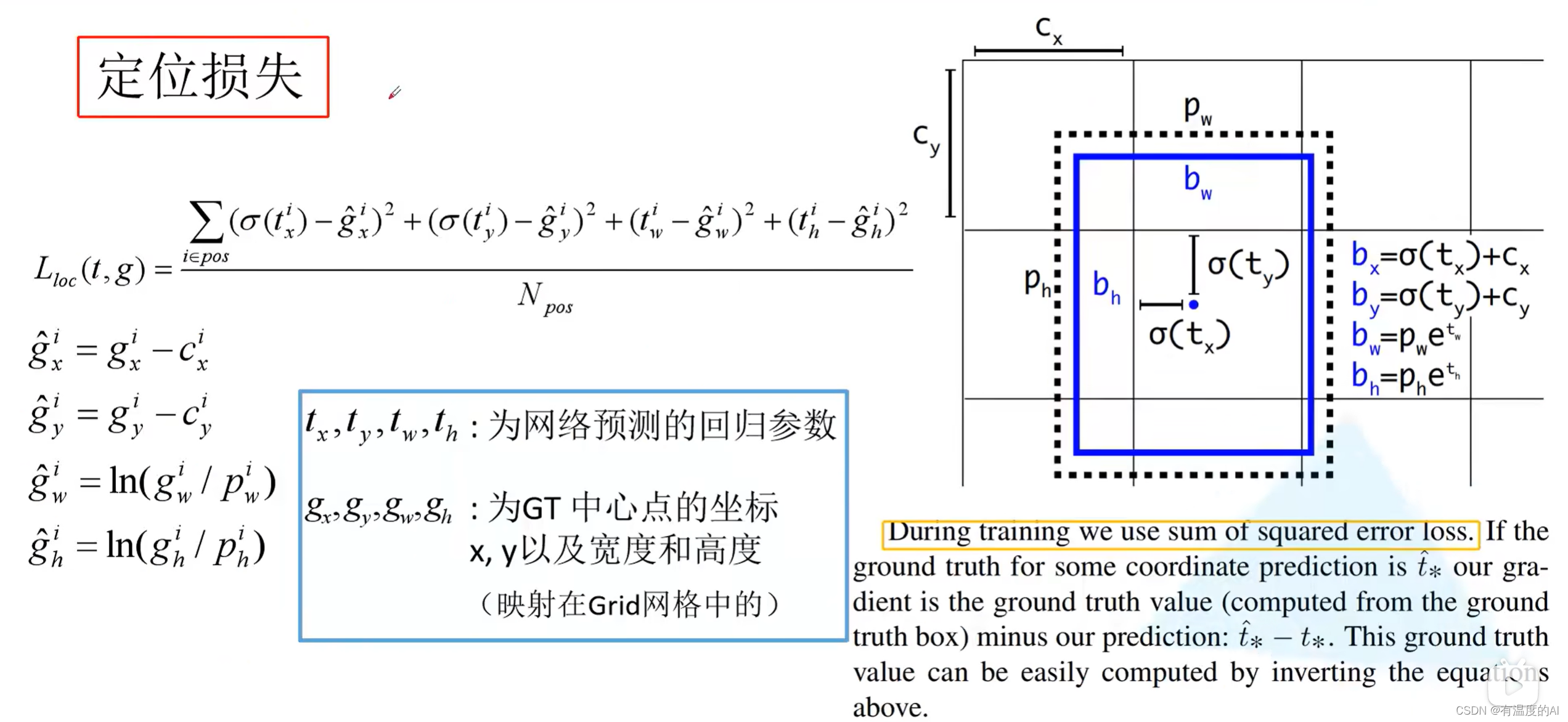
定位损失:只关注正样本,bx、by、bw、bh为预测框的中心点坐标以及宽高值,假设我们用实际标注框的这四个值gx、gy、gw、gh代入式子反求出、
、tw、th,也就是上图中的
、
、
、
,求
、
、
、
与
、
、tw、th的差值的平方和再除上正样本总数就是定位损失。
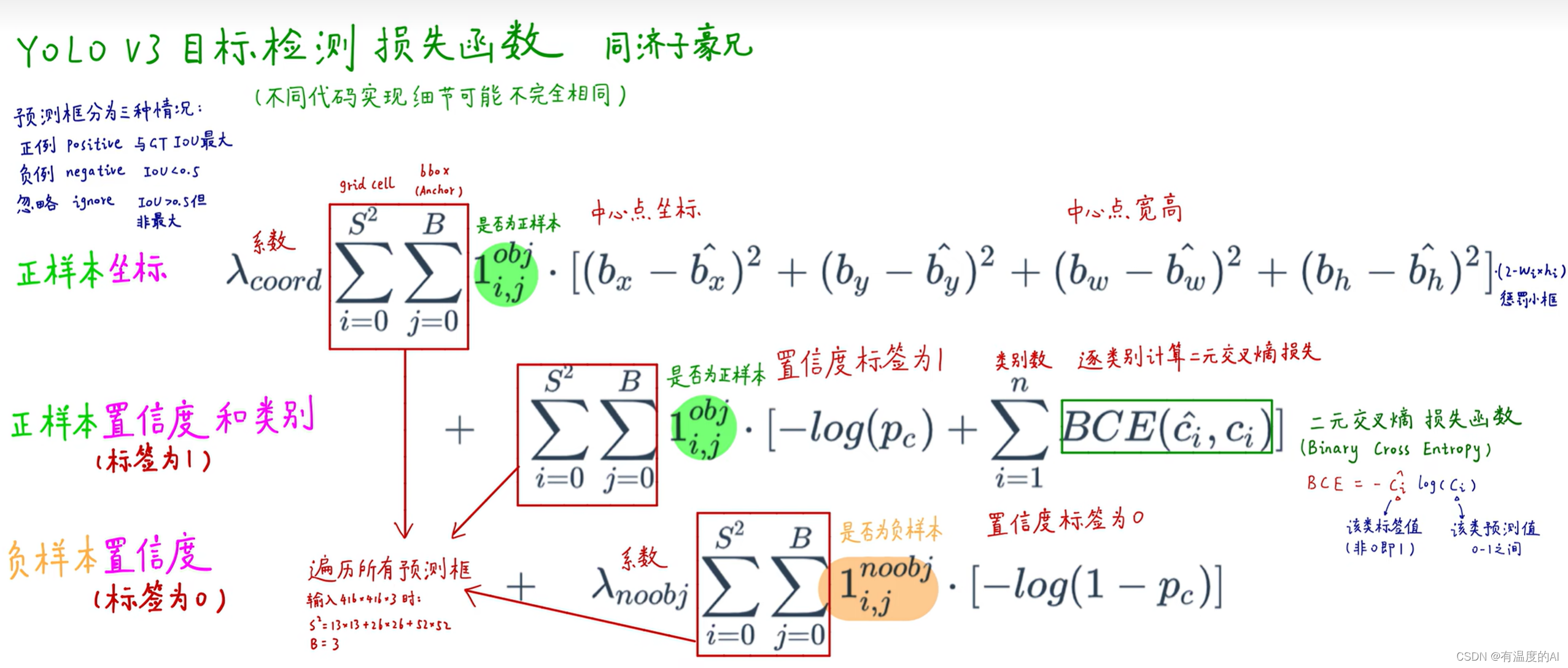
S²表示遍历所有的grid cell,B表示遍历所有的预测框
正负样本匹配
原论文:对于每一个GTbox只分配一个正样本(预测框),也就是与它IOU最大的那个预测框;与GTbox的IOU小于0.5的预测框全都视为负样本;对于IOU大于0.5但不是最大的那部分预测框直接丢弃。
代码实现:一些代码实现中把IOU大于0.5的预测框都视为正样本,这样做是为了提高正样本的数量,这种方法也被证明效果不错。
YOLOV4
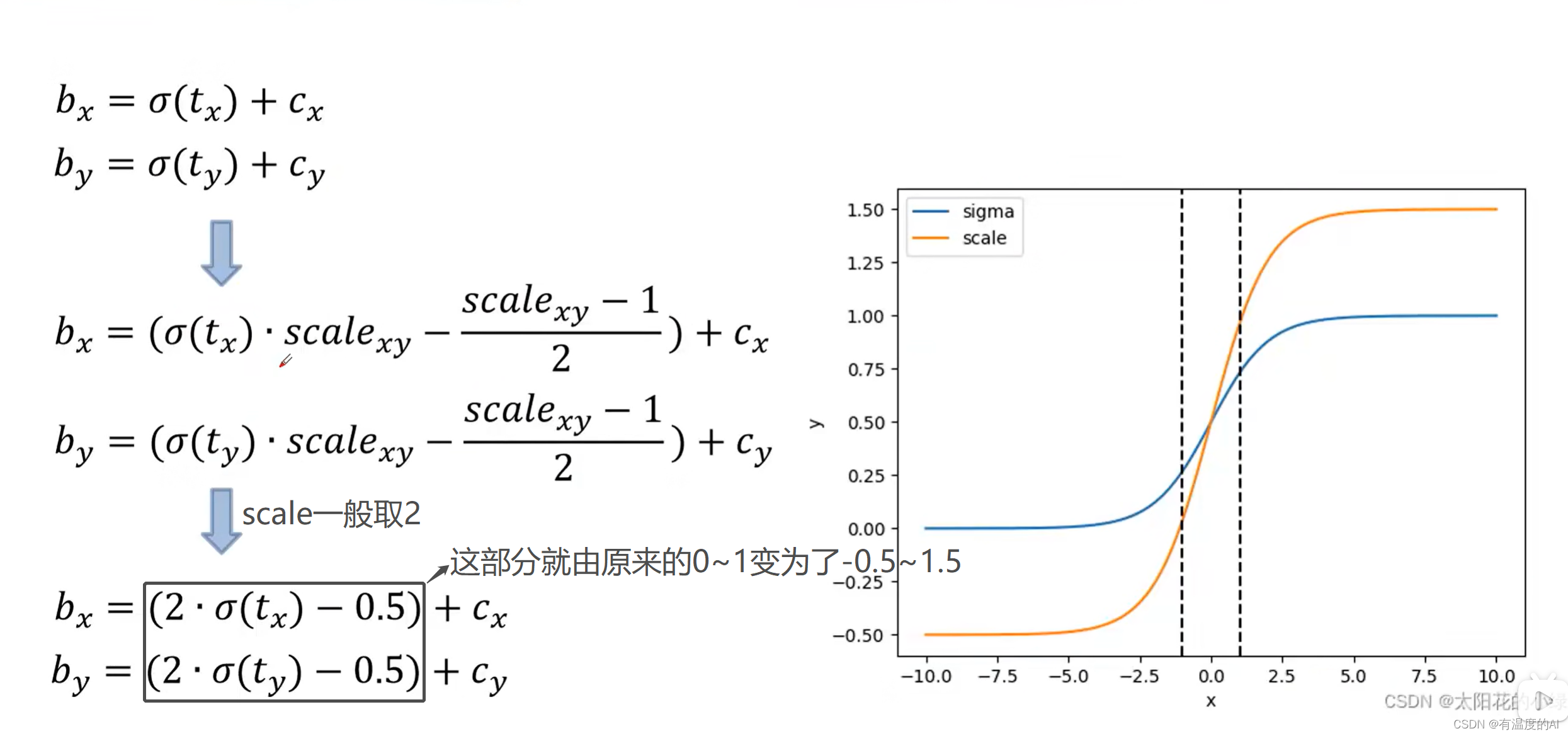
对于一些特殊情况,当GTbox的中心点落在grid cell网格的边界上时, 、
不可能取到0或者1,所以就对其施加了一个缩放因子,将预测框中心点相较于grid cell左上角的偏移量由原来的0~1变为了-0.5~1.5,这样做另一方面也可以增大正样本的数量,也就是说,这个预测框不仅可以由当前中心点所在的grid cell的anchor偏移得到,还可以通过上边或者左边的两个grid cell的anchor通过偏移得到。
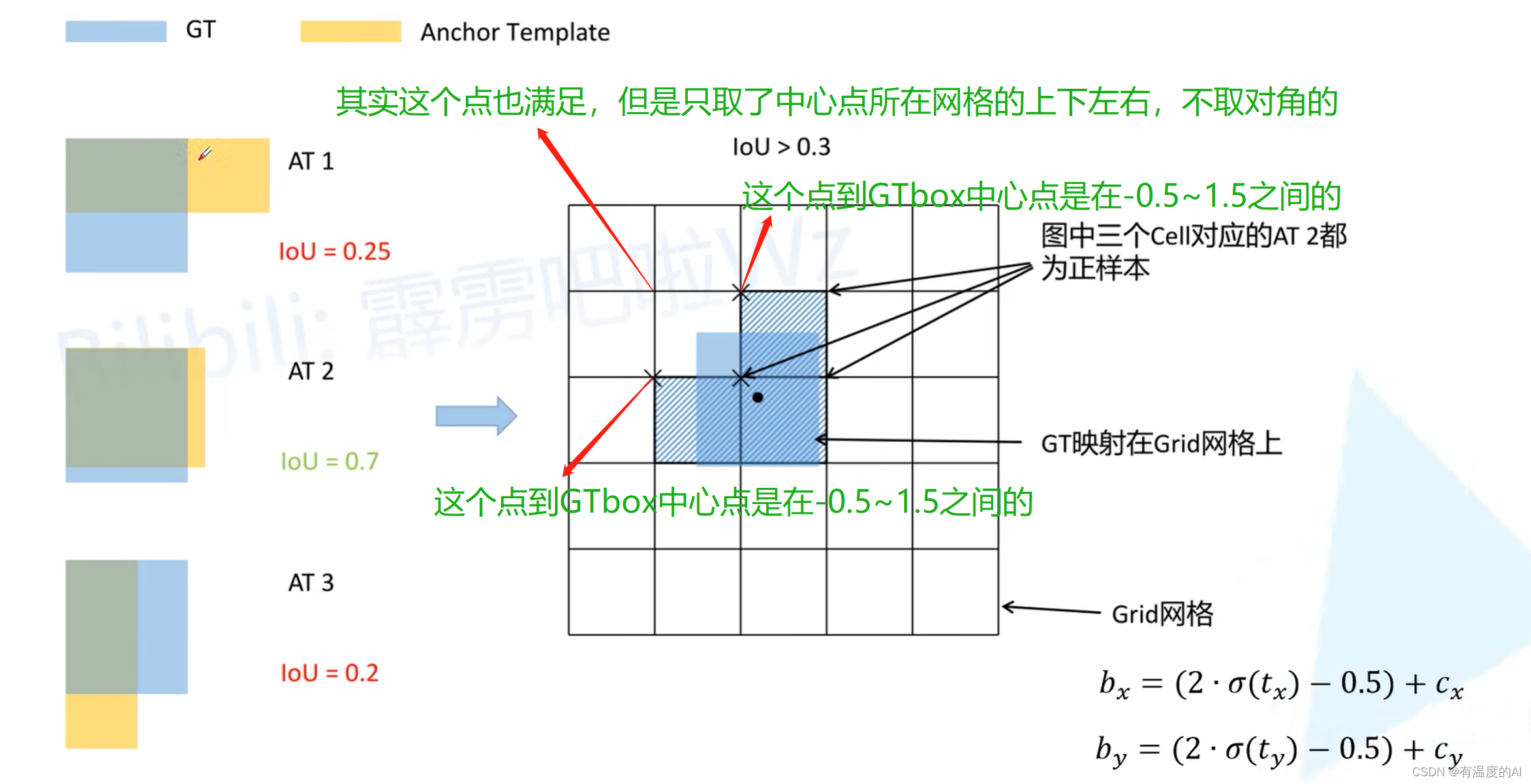
下图对应GTbox中心点落在网格不同位置处所对应的负责预测预测框的grid cell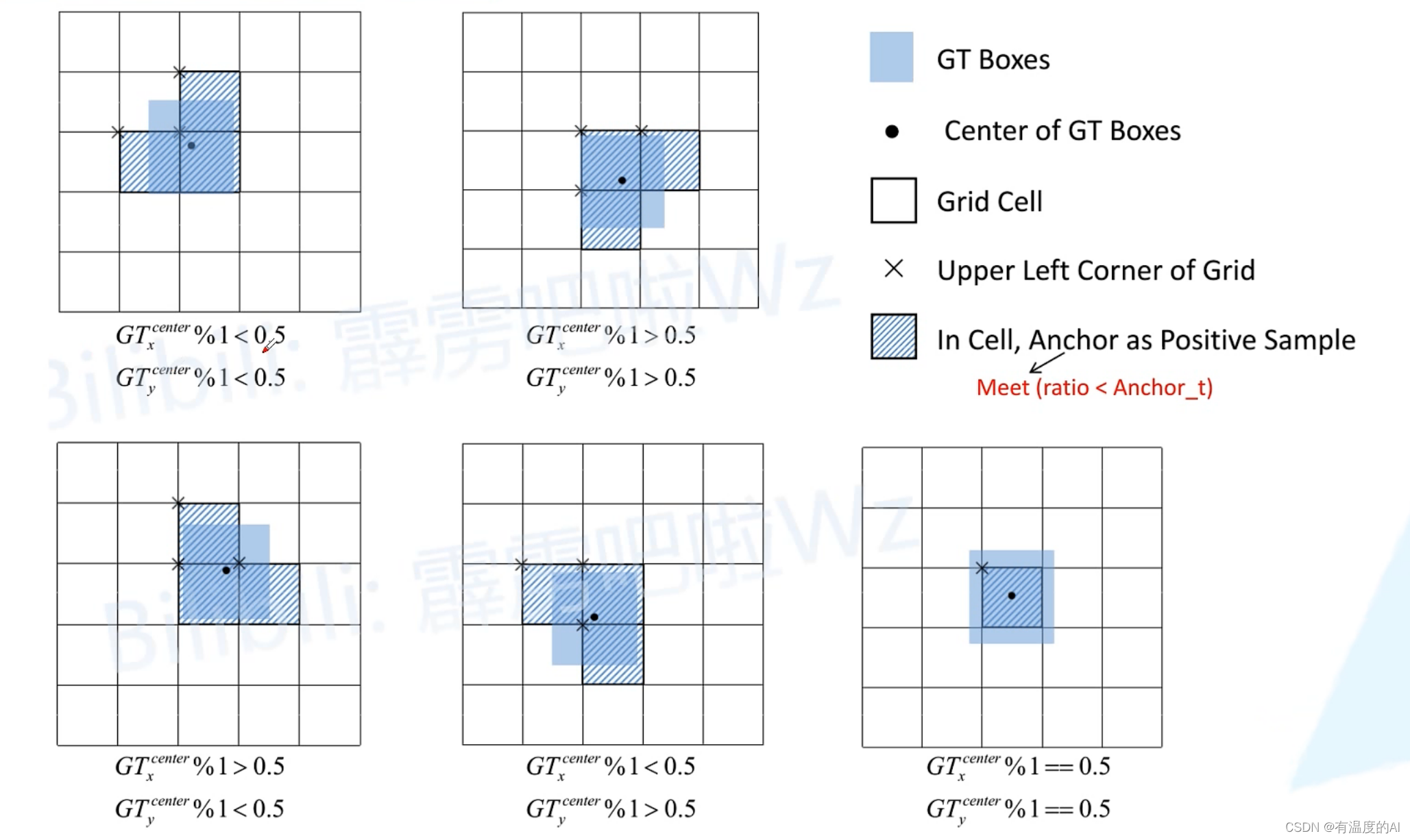
reference
YOLOV1论文精读:You only look once: Unified, real-time object detection_哔哩哔哩_bilibili
【精读AI论文】YOLO V3目标检测(附YOLOV3代码复现)_哔哩哔哩_bilibili
3.1 YOLO系列理论合集(YOLOv1~v3)_哔哩哔哩_bilibili