文章目录
- 1.先来一个简单的示例
- 2.SQLAlchemy 配置(所有的配置都在Flask初始化应用程序之前就执行了)
- 3.声明模型
- 3.1声明模型参数
- 3.2表与表之间的关系(详细介绍)
- 1.一对一关系
- 2.多对一关系
- 3.多对多关系
1.先来一个简单的示例
from flask import Flask
#安装:pip install Flask-SQLAlchemy
from flask_sqlalchemy import SQLAlchemy
#声明一个User模型
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)#主键
username = db.Column(db.String, unique=True, nullable=False)#username不重复,不可为空
email = db.Column(db.String)
# 实例化一个SQLAlchemy对象
db = SQLAlchemy()
# 实例化一个Flask对象
app = Flask(__name__)
# SQLite数据库参数
app.config["SQLALCHEMY_DATABASE_URI"] = "sqlite:///project.db"
# db.create_all()会创建所有的表,如果表已经在数据库中,则不会更新表,db.drop_all()删除所有表
with app.app_context():
# 初始化数据库
db.init_app(app)
#db.drop_all() #删除所有的表
db.create_all() #创建所有的表
#下面创建四个路由视图来使用数据库,完成增删改查操作
#查看
@app.route("/users")
def user_list():
users = db.session.execute(db.select(User).order_by(User.username)).scalars()
return render_template("user/list.html", users=users)
@app.route("/user/<int:id>")
def user_detail(id):
user = db.get_or_404(User, id)
return render_template("user/detail.html", user=user)
#增加
@app.route("/users/create", methods=["GET", "POST"])
def user_create():
if request.method == "POST":
user = User(
username=request.form["username"],
email=request.form["email"],
)
db.session.add(user)
db.session.commit()
return redirect(url_for("user_detail", id=user.id))
return render_template("user/create.html")
#删除
@app.route("/user/<int:id>/delete", methods=["GET", "POST"])
def user_delete(id):
user = db.get_or_404(User, id)
if request.method == "POST":
db.session.delete(user)
db.session.commit()
return redirect(url_for("user_list"))
return render_template("user/delete.html", user=user)
文末有两个我之前练习的示例,均在GitHub上可以自己下载下来运行。
2.SQLAlchemy 配置(所有的配置都在Flask初始化应用程序之前就执行了)
#可以直接放置在Flask配置文件中
#<协议名称>://<⽤户名>:<密码>@<ip地址>:<端⼝>/<数据库名>
#如果使⽤的是mysqldb驱动,协议名: mysql
#如果使⽤的是pymysql驱动,协议名: mysql+pymysql
SQLALCHEMY_DATABASE_URI = "mysql+pymysql://{username}:{password}@{ip_address}:{port}/{database}"
# SQLite, #相对于 Flask 实例路径
SQLALCHEMY_DATABASE_URI = "sqlite:///project.db"
SQLALCHEMY_ECHO = True # 如果设置为True,SQLALchemy会记录所有发给stderr的语句,这对调试有用(会打印sql语句)
SQLALCHEMY_POOL_SIZE #数据库链接池的大小。默认时引擎默认值(通常是5)
SQLALCHEMY_POOL_TIMEOUT#设定链接池的连接超时时间,默认是10
SQLALCHEMY_POOL_RECYCLE #多少秒自动回连连接。对MYsql是必要的。它默认移除闲置多余8小时的连接,注意如果使用了MYSQL, Flask-SQLALchemy自动设定这个值为2小时
3.声明模型
在Flask-SQLAlchemy中,使用模型来表示数据库中的表结构,这些模型通过继承SQLAlchemy中的Base类来创建。下面对Flask-SQLAlchemy定义模型的语法和参数进行总结。
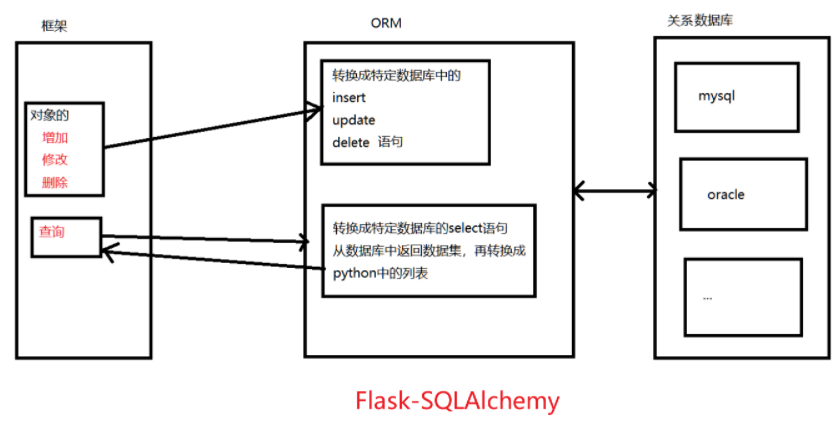
3.1声明模型参数
声明模型示例:
定义了一个名为User的表,它有三个字段:id、username和email。其中id为主键,username和email都是不允许为空且唯一的字符串类型。__repr__方法用于打印对象时显示对象的属性值。
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True, nullable=False)
email = db.Column(db.String(120), unique=True, nullable=False)
def __repr__(self):
return '<User %r>' % self.username
在定义模型时,需要选择合适的列类型来存储不同类型的数据。Flask-SQLAlchemy支持多种列类型,下面对其中常用的列类型进行总结:
| 类型名 | Python类型 | 说明 |
|---|---|---|
Integer | int | 普通整数,一般是 32 位 |
SmallInteger | int | 取值范围小的整数,一般是 16 位 |
Big Integer | int 或 long | 不限制精度的整数 |
Float | float | 浮点数 |
Numeric | decimal.Decimal | 定点数 |
String | str | 变长字符串(其参数有:length:最大长度、nullable:是否允许为空、default:默认值) |
Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
Unicode | unicode | 变长 Unicode 字符串 |
Unicode Text | unicode | 变长 Unicode 字符串,对较长或不限长度的字符串做了优化 |
Boolean | bool | 布尔值 |
Date | datetime.date | 日期 |
Time | datetime.time | 时间 |
DateTime | datetime.datetime | 日期和时间 |
Interval | datetime.timedelta | 时间间隔 |
Enum | str | 一组字符串 |
PickleType | 任何 Python 对象 | 自动使用 Pickle 序列化 |
LargeBinary | str | 二进制文件 |
定义模型时,列类型的参数可以用来指定列的属性。下面对常用的列类型参数进行总结:
| 选项名 | 说明 |
|---|---|
primary_key | primary_key用来指定该列为主键,若一个表中没有主键,则无法使用ORM进行操作。 |
unique | unique用来指定该列的值是否唯一,若设置为True,则该列的值必须在表中唯一。 |
index | index用来指定该列是否需要索引。若设置为True,则该列可以被用来进行查询,加快查询速度。 |
nullable | nullable用来指定该列的值是否允许为空,若设置为True,则该列的值可以为None。 |
default | default用来指定该列的默认值,若该列的值未设置,则使用该默认值。 |
autoincrement | autoincrement用来指定该列是否自动增加。若设置为True,则每次插入新记录时该列的值会自动增加。 |
3.2表与表之间的关系(详细介绍)
在 Flask-SQLAlchemy 中,模型是用来表示数据库中表的类,而模型之间的关系是用来表示表之间的关系。下面介绍 Flask-SQLAlchemy 中声明模型间一对一、多对一和多对多关系的语法和方法。
-
定义关系属性:使用关系函数定义关系属性。关系属性在关系的出发侧定义,即一对多关系的“一”这一侧。relationship()函数的第一个参数为关系另一侧的模型名称,它会告诉SQLAlchemy将Author类和Article类建立关系。当这个关系属性被调用时,SQLAlchemy会找到关系的另一侧(即article表)的外键字段(author_id),然后反向查询article表中所有author_id值为当前表主键值(即author.id)的记录,返回包含这些记录的列表,也就是返回某个作者对应的多篇文章记录。
-
外键
db.ForeignKey():定义关系的第一步是创建外键。外键(foreign key)用来在A表存储B表的主键值,以便和B表建立联系的关联字段。因为外键只能存储单一数据(标量),所以外键总是在“多”这一侧定义,多篇文章属于同一个作者,所以我们需要为每篇文章添加外键存储作者的主键值以指向对应的作者。因此外键是用来在两个表之间建立关联的一种机制,db.ForeignKey函数的参数为关联的模型名称和模型中的字段名称。例如,上面有两个模型Order和Customer,可以使用外键将它们关联起来。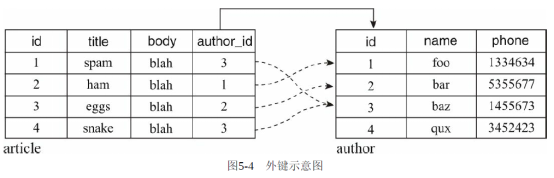
-
backref:backref是用来在两个模型之间建立双向关联的一种机制,上面两个模型Order和Customer,我们可以使用backref参数来声明Customer模型中的orders属性,这样就可以通过customer.orders来访问该客户的订单列表。 -
db.Table():db.Table是用来声明多对多关系中的中间表的一种机制。 -
secondary:用来声明多对多关系中的中间表的一种机制。上面使用secondary参数来指定中间表的名称book_author
1.一对一关系
一对一关系表示两个模型之间存在一个唯一的对应关系。在 Flask-SQLAlchemy 中,可以使用 relationship 函数来声明一对一关系。例如,如果有两个模型 User 和 Address,其中一个用户只有一个地址,可以这样声明一对一关系:
- model.py
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
class User(db.Model):
__tablename__="user"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
address = db.relationship('Address', backref='user',uselist=False)
class Address(db.Model):
__tablename__="address"
id = db.Column(db.Integer, primary_key=True)
street = db.Column(db.String(50))
user_id = db.Column(db.Integer, db.ForeignKey('user.id'))
- app.py
from flask import Flask
from model import *
app = Flask(__name__)
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:123456@{ipaddress}:{port}/{database}".format( ipaddress="",port="3306",database="sql_test")
app.config["SQLALCHEMY_ECHO"]= True
app.config["SECRET_KEY"]= 'dsjjkhkhjsdkjchkj'
# 初始化数据库
with app.app_context():
db.init_app(app)
db.drop_all()
db.create_all()
#测试
@app.route('/')
def hello_world(): # put application's code here
u1 = User(name="yiyi")
add1 = Address(street="street1")
u1.address = add1
db.session.add_all([u1])
db.session.commit()
add2 = Address(street="street2")
#u1.address.append(ad1) #会报错
db.session.commit()
u1name = add1.user.name
print("-------------")
print(u1name) #yiyi
counts = u1.address
print(counts.street) #street1
#换一个地址
u1.address = add2
counts = u1.address
db.session.commit()
print(counts.street) #street2
return "成功"
if __name__ == '__main__':
app.run(debug=True)
在上面的代码中:
-
relationship函数来声明User和Address之间的关系。 -
backref参数表示在 Address 模型中添加一个名为user的属性,该属性引用 User 模型。 -
uselist参数设置为False,表示User和Address之间的关系是一对一的关系。
“多”这一侧本身就是标量关系属性,不用做任何的改动(有外键的是“多”这一侧),而“一”这一侧的集合关系属性,通过将uselist参数设置为False后,将近返回对应的单个记录,而且无法再使用列表语义操作,Address.user.append(‘小明’)就会报错。
2.多对一关系
多对一关系表示一个模型可以对应多个另一个模型,而另一个模型只能对应一个该模型。例如,如果有两个模型 Order 和 Customer,一个订单只能有一个客户,而一个客户可以有多个订单,可以这样声明多对一关系:
- model.py
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
class Order(db.Model):
id = db.Column(db.Integer, primary_key=True)
order_number = db.Column(db.String(50))
#每一个订单都对应了一个用户
user_id = db.Column(db.Integer, db.ForeignKey('customer.id'))
def __repr__(self):
return '<Order id:%r, order_number:%r>' % (self.id, self.order_number)
class Customer(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
orders = db.relationship('Order', backref='customer')
def __repr__(self):
return '<Customer id:%r, name:%r>' % (self.id, self.name)
- app.py
from flask import Flask
from model import *
app = Flask(__name__)
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:123456@{ipaddress}:{port}/{database}".format( ipaddress="",port="3306",database="sql_test")
app.config["SQLALCHEMY_ECHO"]= True
app.config["SECRET_KEY"]= 'dsjjkhkhjsdkjchkj'
# 初始化数据库
with app.app_context():
db.init_app(app)
db.drop_all()
db.create_all()
#测试
@app.route('/')
def hello_world(): # put application's code here
u1 = Customer(name="yiyi")
add1 = Order(order_number="order1")
add2 = Order(order_number="order2")
add3= Order(order_number="order3")
u1.orders.append(add1)
u1.orders.append(add2)
db.session.add_all([u1,add2,add1,add3])
db.session.commit()
u1name = add1.customer.name
print("-------------")
print(u1name) #yiyi
counts = u1.orders
print("-------------")
print(counts) #[<Order id:7, order_number:'order1'>, <Order id:8, order_number:'order2'>]
#移除一个订单
u1.orders.remove(add2)
counts = u1.orders
db.session.commit()
print("-------------")
print(counts) #[<Order id:1, order_number:'order1'>]
return "成功"
if __name__ == '__main__':
app.run(debug=True)
在上面的代码中:
-
relationship函数来声明Order和Customer之间的关系。 -
backref参数表示在 Customer 模型中添加一个名为orders的属性,该属性引用 Order 模型。 -
customer_id字段是一个外键,用于将Order模型与Customer模型关联起来。
3.多对多关系
多对多关系表示两个模型之间存在多个对应关系。
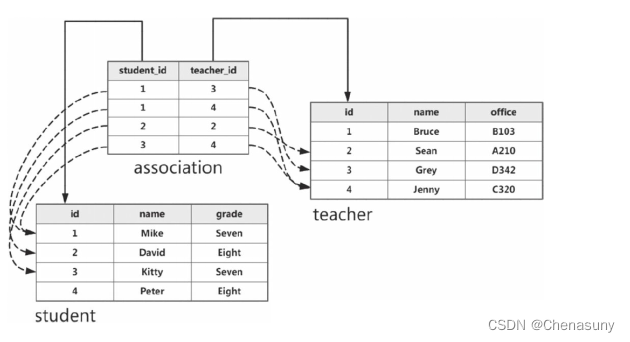
例如,如果有两个模型 Book 和 Author,一个作者可以写多本书,一本书可以有多个作者,可以这样声明多对多关系:
- model.py
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
book_author = db.Table('book_author',
db.Column('book_id', db.Integer, db.ForeignKey('book.id')),
db.Column('author_id', db.Integer, db.ForeignKey('author.id'))
)
class Book(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(50))
authors = db.relationship('Author', secondary=book_author, backref='books')
class Author(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
- app.py
from flask import Flask
from model import *
app = Flask(__name__)
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:123456@{ipaddress}:{port}/{database}".format( ipaddress="",port="3306",database="sql_test")
app.config["SQLALCHEMY_ECHO"]= True
app.config["SECRET_KEY"]= 'dsjjkhkhjsdkjchkj'
# 初始化数据库
with app.app_context():
db.init_app(app)
db.drop_all()
db.create_all()
#测试
@app.route('/')
def hello_world():
B1 = Book(title="yiyi")
B2 = Book(title="eiei")
B3 = Book(title="sisi")
A1 = Author(name="Author1")
A2 = Author(name="Author2")
A3= Author(name="Author3")
db.session.add_all([B1,B2,B3,A1,A2,A3])
db.session.commit()
B1.authors.append(A1)
B1.authors.append(A2)
A3.books.append(B1)
A3.books.append(B2)
db.session.commit()
print("-------------")
print(B1.authors) #yiyi
print(A3.books)
print("-------------")
#输出
#-------------
# [<Author 1>, <Author 2>, <Author 3>]
# [<Book 1>, <Book 2>]
# -------------
return "成功"
if __name__ == '__main__':
app.run(debug=True)
在上面的代码中:
relationship函数和一个名为book_author的中间表来声明Book和Author之间的多对多关系。secondary参数指定了中间表的名称backref参数表示在 Author 模型中添加一个名为books的属性,该属性引用 Book 模型。- 在关联表中,分别指定了
book_id和author_id字段作为外键,用于将Book模型和Author模型关联起来。这样就可以在Book模型中声明authors属性时直接使用secondary='book_author'来引用中间关联表。
Github练习示例:
https://blog.csdn.net/QH2107/article/details/130381365?spm=1001.2014.3001.5502
https://github.com/QHCV/Flask_Book_Manage
参考资料:
https://blog.csdn.net/kongsuhongbaby/article/details/102942673
官方文档:
中文:http://www.pythondoc.com/flask-sqlalchemy/index.html
英文:https://flask-sqlalchemy.palletsprojects.com/en/3.0.x/
水平有限,如果有错误或者建议,可以在评论区交流一下。
希望有所帮助!喜欢就点个赞吧!